


关键词:计算机视觉; 3D人体网格估计; 单阶段方法

导 读
本文是对发表于计算机视觉领域顶级会议 CVPR 2025 的论文 SAT-HMR: Real-Time Multi-Person 3D Mesh Estimation via Scale-Adaptive Tokens 的解读。该论文由北京大学王亦洲课题组完成,第一作者为计算机学院25级博士新生苏驰,合作者为苏嘉俊,通讯作者为计算机学院21级博士生马霄璇和王亦洲教授。
该工作提出了一个实时的单阶段框架 SAT-HMR,用于从单张 RGB 图像中估计多人 3D 网格。尽管现有的单阶段方法在高分辨率输入下能够达到最先进(SOTA)的性能,但我们发现这种性能提升主要体现在图像中尺度较小的个体上,同时也带来了显著的计算开销。为了解决这一问题,该工作引入了尺度自适应令牌(scale-adaptive token),根据图像中每个个体的相对尺度动态调整:尺度较小的个体在较高分辨率下处理,尺度较大的在较低分辨率下处理,背景区域则进一步被提炼。该自适应策略提高了图像特征的编码效率,使模型能够更有效地分配计算资源,聚焦于更难估计的个体。实验结果表明,SAT-HMR 在显著降低计算成本的同时,保留了高分辨率处理带来的精度优势,实现了与当前 SOTA 方法相当的实时推理性能。
论文链接:
https://arxiv.org/abs/2411.19824
项目代码:
https://github.com/ChiSu001/SAT-HMR
项目主页:
https://chisu001.github.io/SAT-HMR/
视频介绍:
https://youtu.be/tqURcr_nCQY

01
背景介绍
单张 RGB 图片的多人 3D 人体网格估计旨在定位场景中的所有个体并且估计他们的 3D 网格(通常借助参数化的人体模型如 SMPL[5]表达)。这一任务具有广泛的应用价值,涵盖社交交互、游戏制作等多个领域。现有方法可分为多阶段与单阶段两类:多阶段方法先完成检测再对检测区域分别估计;单阶段方法在整张图片上完成操作,支持端到端(end-to-end)训练,且更好地保留了图像的全局上下文。近期的单阶段方法[1, 8]采用了 DETR 式[2]的框架,实现了高精度的人体网格估计。然而这些方法采用高分辨率的图像输入,运行效率极低。
为研究分辨率对模型表现的影响,我们首先搭建了基线(baseline)模型来统计了各个模型在 AGORA[7]验证集上不同尺度的个体的估计误差,以及平均运行时间。结果显示,高分辨率输入带来的性能提升主要体现在小尺度人物上;对于大尺度人物,高分辨率提升不大,且人物本身被大量图像令牌(image token)表示,引入额外计算开销,大大限制模型速度。
定 义
尺度在本文中指人物相对于图像的大小,定义为:
尺度 = min(边界框对角线长/图像长边大小, 1)
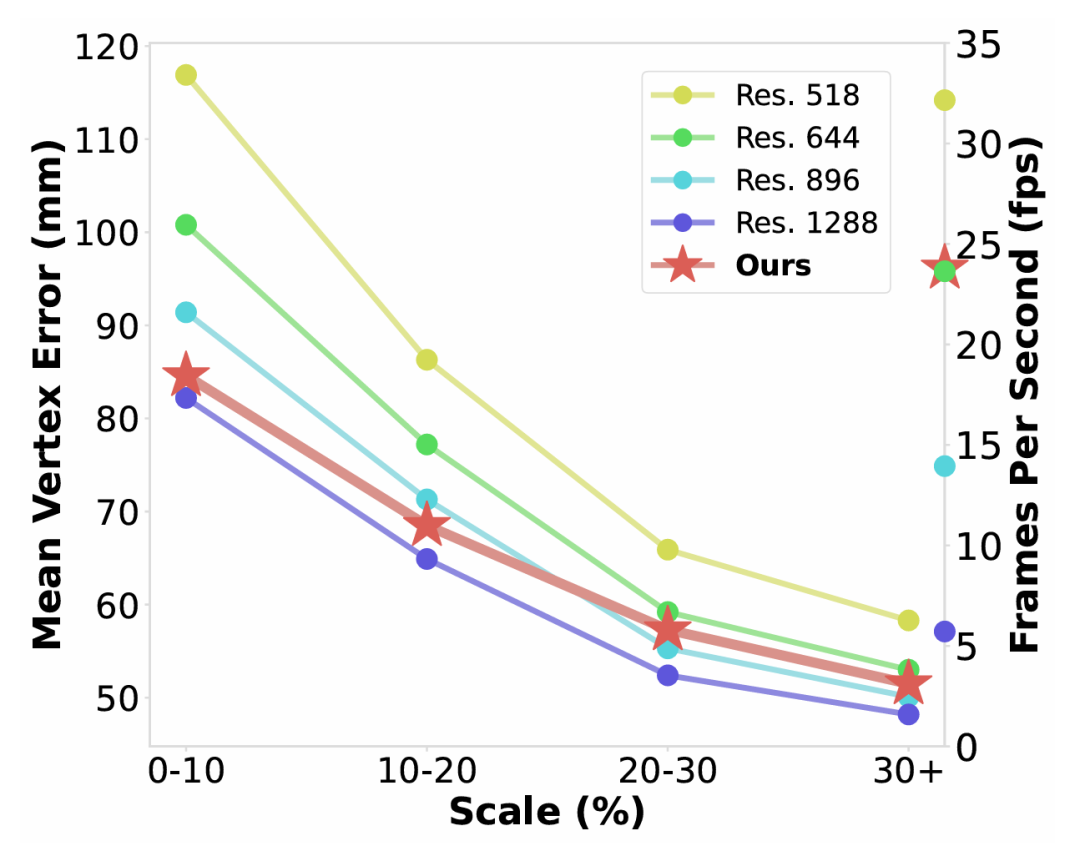
图1. SAT-HMR 与各基线模型的速度-精度比较
02
方法概览
1. 基线模型
基于近期的方法,我们采用了 DETR式[2]的框架,包括 Transformer 编码器、解码器以及用于回归 SMPL[5]参数的预测头。给定一张 RGB 图像,我们将其划分为规则的图像块(patch)进行特征编码,得到一组令牌(token)序列。在解码器中,我们用查询(query)表示待检测个体。解码后,这些查询通过多个预测头,回归 SMPL 参数、边界框以及置信度分数以筛选有效预测。
2. 基于尺度自适应令牌的 SAT-HMR
高分辨输入可以显著提高基线模型的预测精度,但同时带来显著计算开销。为了更高效地编码图像特征,我们引入尺度自适应令牌。
SAT-HMR 先取一张低分辨率图片,通过一个浅层的Transformer编码器得到低分辨率令牌,接着通过一个尺度头网络预测块级别尺度图(patch-level scale map),将这些令牌依据对应图片区域是否有人以及人物尺度大小分为三部分:背景令牌、小尺度令牌和大尺度令牌。小尺度令牌被相应的高分辨率令牌替代,这些令牌用另一个浅层编码器从高分辨率图片编码得到(分辨率为低分辨率的两倍);背景令牌通过每相邻四个一组进行池化以进一步压缩;而大尺度令牌保留不变。我们将这些的令牌重新整合起来,得到尺度自适应令牌(scale-adaptive token)。
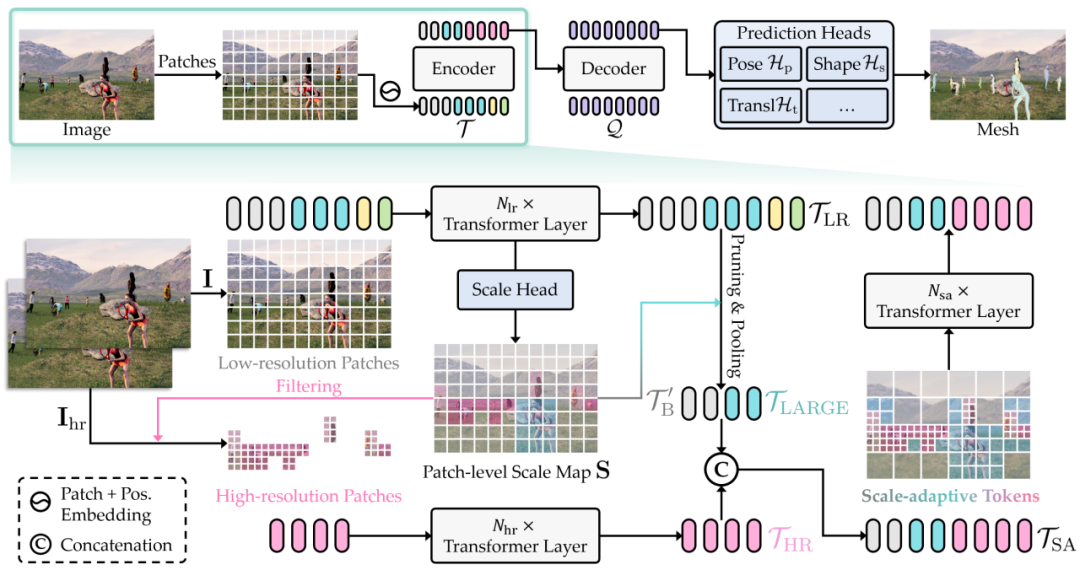
图2. 基线模型(上)以及引入尺度自适应令牌(下)的 SAT-HMR 模型的示意图
与基线模型的规则令牌相比,这个过程更有效地划分特征细粒度,对于不同区域不同尺度的人保留了不同程度的特征。这些尺度自适应令牌由另一个编码器一起继续编码,并进入后续解码阶段。
3. 解码器与预测头
SAT-HMR 的解码器与预测头的设计与基线版本一致。我们基于 DAB-DETR[4],逐层优化更新 SMPL 参数和边界框的预测。在训练时,这些预测通过匈牙利匹配(Hungarian Matching)与真值(GT)一一对应以计算损失。
03
实验结论
1. 与现有方法的对比
我们在 AGORA[7]测试集上对比 SAT-HMR 与现有方法。SOTA 方法[1, 8]使用了更高分辨率的输入,在性能提升的同时也带来了大量的计算开销(MACs 大幅上升、运行速度显著下降),SAT-HMR 采用了基础值为644的混合分辨率(记为644*),保持了实时运行效率和与 SOTA 方法相当的精度,成为了当前最优的实时模型,在速度与精度之间达成了前所未有的平衡。
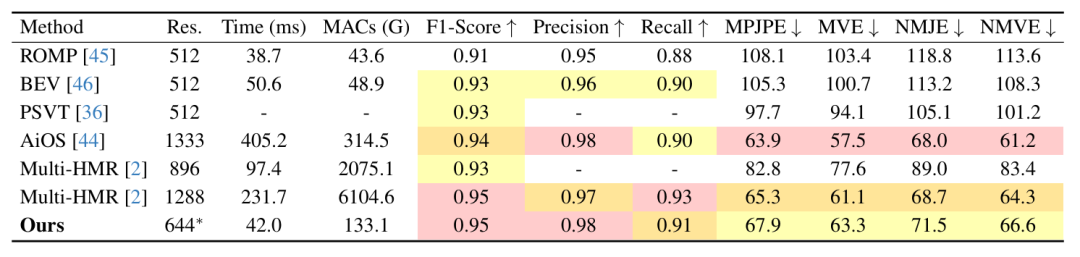
表1. 与现有方法在 AGORA[7]测试集上的对比
我们还在 3DPW[9]、MuPoTS[6]和 CMU Panoptic[3]数据集上评估模型。SAT-HMR 在所有数据集上都取得了最佳结果,展现了出色的泛化能力。
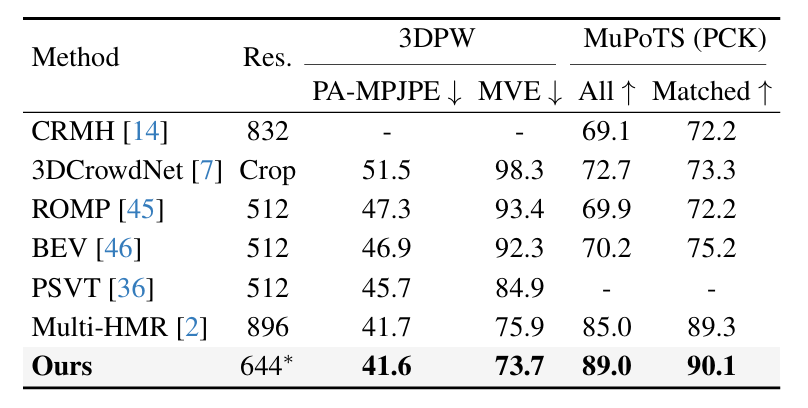
表2. 与现有方法在 3DPW[9]和 MuPoTS[6]上的对比
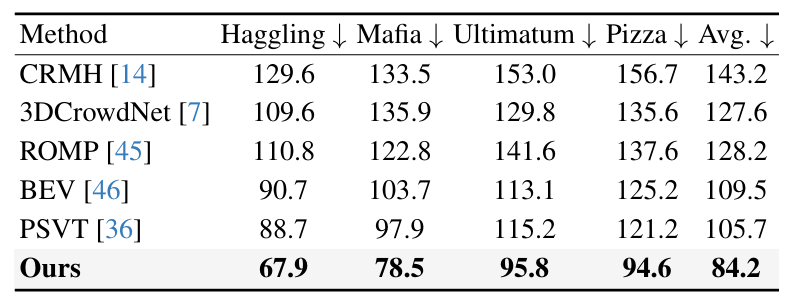
表3. 与现有方法在 CMU Panoptic[3]上的对比
2. 结果可视化
我们将模型预测的块级别尺度图与尺度自适应令牌进行可视化,体现了模型对不同尺度区域的动态调整能力。在尺度图中,从蓝色到红色代表尺度从大到小,无色区域为背景;尺度自适应令牌用不同颜色以及不同大小的块加以区分,低分辨率的块被模糊处理。
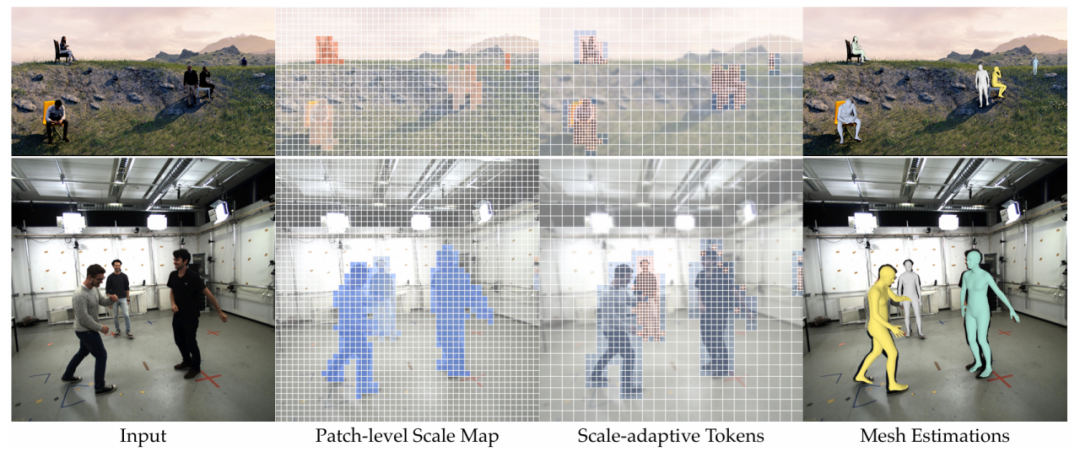
图3. 尺度图与尺度自适应令牌的可视化
下面展示了 SAT-HMR 在一些互联网图片上的预测结果。我们的方法泛化性好,在不同尺度的人物上均能输出准确预测。更多结果及对比详见论文和项目主页。

图4. SAT-HMR 在互联网图片上的表现
04
总 结
本工作提出了新颖的单阶段框架:SAT-HMR,可实现基于单张 RGB 图像的实时多人人体 3D 网格估计。通过引入尺度自适应令牌,根据个体的相对尺度动态调整分辨率的分配,我们的方法在准确性与计算效率之间实现了有效平衡,不仅保留了高分辨率处理带来的性能优势,同时达成了实时推理能力。实验结果表明,SAT-HMR 是当前最优的实时模型,在与现有 SOTA 方法相比时展现出具有竞争力的性能与更强的泛化能力。
目前 SAT-HMR 仅支持身体部分的估计,而人脸与手部这些极具挑战性的区域恰好也依赖于高分辨率的处理,这正好契合我们动态调整分辨率的设计。因此将本文的方法扩展为全身估计是一个值得探索的方向。此外,本文提出的尺度自适应令牌也有扩展至其他采用 DETR 式框架的工作中的潜力,帮助提升效率,应用前景广泛。
视频介绍:
参考文献:
[1] Fabien Baradel, Matthieu Armando, Salma Galaaoui, Romain Brégier, Philippe Weinzaepfel, Grégory Rogez, and Thomas Lucas. Multi-hmr: Multi-person whole-body human mesh recovery in a single shot. In ECCV, 2024.
[2] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, pages 213–229. Springer, 2020.
[3] Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh. Panoptic studio: A massively multiview system for social motion capture. In ICCV, pages 3334–3342, 2015.
[4] Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. DAB-DETR: Dynamic anchor boxes are better queries for DETR. In ICLR, 2022.
[5] Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. ACM TOG, 34(6):1–16, 2015.
[6] Dushyant Mehta, Oleksandr Sotnychenko, Franziska Mueller, Weipeng Xu, Srinath Sridhar, Gerard Pons-Moll, and Christian Theobalt. Single-shot multi-person 3d pose estimation from monocular rgb. In 3DV, pages 120–130, 2018.
[7] Priyanka Patel, Chun-Hao P Huang, Joachim Tesch, David T Hoffmann, Shashank Tripathi, and Michael J Black. Agora: Avatars in geography optimized for regression analysis. In CVPR, pages 13468–13478, 2021.
[8] Qingping Sun, Yanjun Wang, Ailing Zeng, Wanqi Yin, Chen Wei, Wenjia Wang, Haiyi Mei, Chi-Sing Leung, Ziwei Liu, Lei Yang, et al. Aios: All-in-one-stage expressive human pose and shape estimation. In CVPR, pages 1834–1843, 2024.
[9] Timo von Marcard, Roberto Henschel, Michael J Black, Bodo Rosenhahn, and Gerard Pons-Moll. Recovering accurate 3d human pose in the wild using imus and a moving camera. In ECCV, pages 601–617, 2018.

图文 | 苏驰
Computer Vision and Digital Art (CVDA)
About CVDA
The Computer Vision and Digital Art (CVDA) research group was founded in 2007 within the National Engineering Research Center of Visual Technology at Peking University led be Prof. Yizhou Wang. The group focuses on developing computational theories and models to solve challenging computer vision problems in light of biologically plausible evidences of visual perception and cognition. The primary goal of CVDA is to establish a mathematical foundation of understanding the computational aspect of the robust and efficient mechanisms of human visual perception, cognition, learning and even more. We also believe that the marriage of science and art will stimulate exciting inspirations on producing creative expressions of visual patterns.
CVDA近期科研动态


— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

点击“阅读原文”转论文链接
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢