
近日,阿里妈妈在国际顶级学术会议 —— 国际万维网大会(International World Wide Web Conference, 简称WWW)上共同主持了计算广告算法技术相关的Tutorial(讲座),介绍了计算广告领域的技术发展脉络,以及阿里妈妈在该领域的最新技术突破,阿里妈妈LMA2广告大模型系列中的通用召回大模型 URM(Universal Recommendation Model)首次重磅亮相。
1. 概述
随着大语言模型(LLM)技术的快速发展,其中的一些关键能力如世界知识、逻辑推理等,也给推荐、广告系统的算法模型带来了新的想象空间。如何利用好这些能力,让推荐、广告模型的精准性与逻辑性进一步提升,是一个很有挑战的命题。过往工作对 LLM 的知识利用多停留在特征提取器或商品相关性判别器,以固定表征抽取的方式注入下游推荐模型,这种两段式的应用方式存在一定的局限性。因此我们考虑直接使用 LLM 进行端到端推荐来充分发挥优势。
LLM 在推荐场景的直接应用主要有2个核心难点:1)LLM 虽然具备丰富的世界知识和推理能力,但缺乏电商领域的专业知识,在直接应用中往往表现欠佳。2)LLM 的交互方式多为文本,而直接将用户历史行为以文本格式描述会导致输入信息冗长、信息密度低等问题,对建模和推理都造成了困扰。
为了解决以上问题,我们提出了一种通用召回大模型 URM,通过知识注入和信息对齐,让 LLM 成为兼顾世界知识和电商知识的专家。得益于对 LLM 基座的直接使用,URM 在通用多任务、原生多模态建模、超长序列理解上具备天然的优势。在召回任务的离线指标上,URM 取得了超越传统召回模型的结果,同时具备根据 Prompt 输入引导召回结果生成的能力。为了在低时延、高QPS要求的实际系统中上线应用,我们设计了一套面向用户行为动态捕捉的异步推理链路。
目前,URM 已经在阿里妈妈展示广告场景上线,带来了大盘消耗+3.1%的显著提升,也用其良好的泛化性帮助长尾广告实现了曝光和成交效率的双涨,大幅提升了广告系统的匹配效率。
2. 通用召回大模型URM
召回的目标是,对于每一次请求,需要从候选集中找到给定价值度量下价值最高的一个子集。
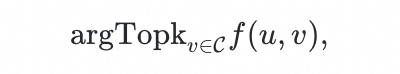
其中函数 为一个针对用户 和候选项 的价值度量函数。线上基线模型输入包括用户侧聚合特征、场景特征、商品侧的各种特征一起 Concat,经过多层全连接网络直接输出 或使用用户和商品向量内积计算 。其中所有的特征都是离散 ID,通过 Embedding Layer 映射到 Embedding 空间。当建模目标不同时,在模型结构上需要针对性地设计。
召回大模型采用完全不同的特征体系和模型结构。用户侧的各种属性、原始行为序列、以及面向不同价值目标的召回任务描述,会以文本+ID 交织的格式输入到大语言模型中,文本 Token 和 ID 会分别通过大模型本身的 EmbeddingTable 和额外的 HashTable+MLP Projection 映射到相同维度。大语言模型经过多层 Transformer 生成最终的用户 Embedding([UM] token)和文本([LM] token),并分别解码出对应的商品 ID 和 预测类目, 其中文本生成任务仅用于训练过程来保留大语言模型的世界知识和文本能力。对于不同的召回目标,只需要调整输入的任务描述 Prompt,即可改变输出的召回集合。
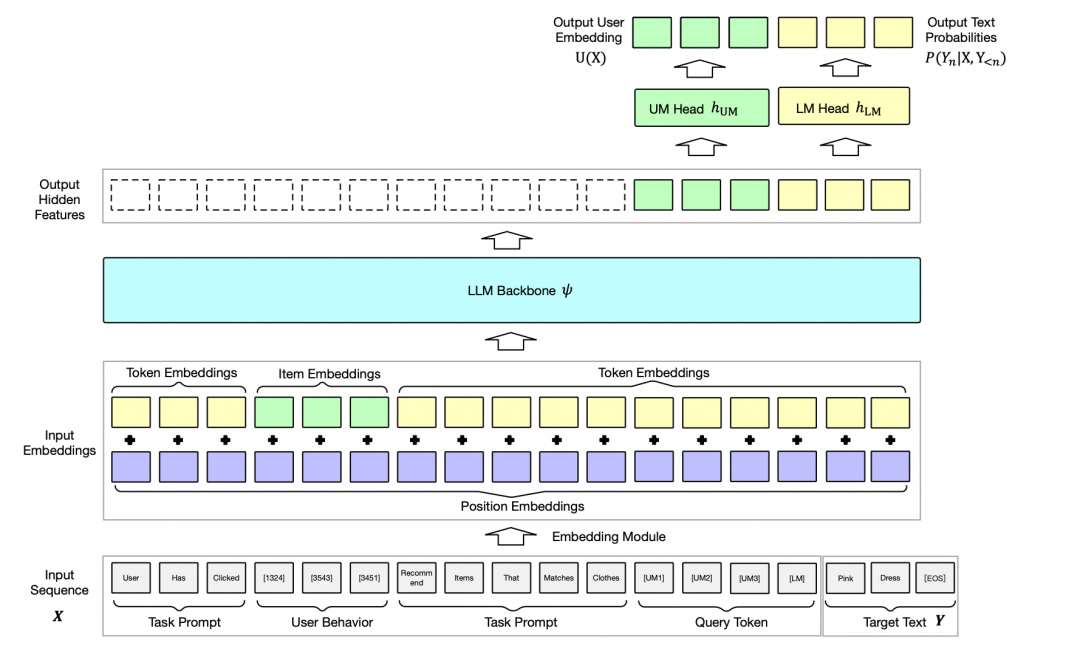
2.1 数据集构建&训练方式:通用的多任务建模能力
借鉴 GPT 的训练方法,我们用自然语言来定义不同的推荐任务,并将输入表示为序列形式。根据不同任务的特点,我们设计了多种文本模板。为了提高长用户行为序列的处理效率,我们将商品 ID 视作一种特殊的 Token,并将用户行为数据对应的 ID 以序列形式组合到模板中。一个经典的 Prompt 输入如下,是由普通文本 Token 和商品 ID Token(如 [7502] )组成的序列:

考虑到推理效率,训练目标是直接生成商品 ID;同时,训练过程中也会面向目标文本进行优化,以对齐语义空间并融合外部文本知识:
我们将不同的推荐任务用不同的 Prompt 描述进行表达,例如:
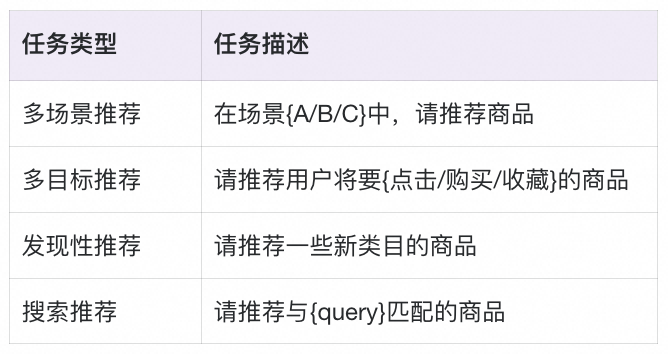
其中,我们将搜索看作是一种带约束的特殊的推荐任务。需要指出的是,为了让 LLM 能够根据不同的 Prompt 生成不同的推荐结果,需要根据不同的约束条件改变正样本的构成。
训练的形式化目标如下。将输入序列表示为 ,目标文本表示为 ,目标商品表示为 。
商品推荐任务通过噪声对比估计(NCE)损失来优化:

其中 是用户建模头 输出的用户表征, 是商品的多模态融合表征。在每个批次中,负样本 是从商品候选基于其出现频率采样得到的。
文本生成任务可以通过目标文本序列的负对数似然来优化:
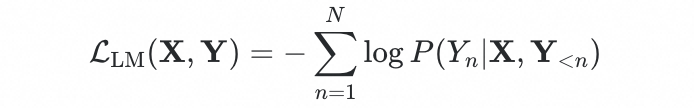
其中 是由语言模型头 输出的概率。
最终的训练目标是: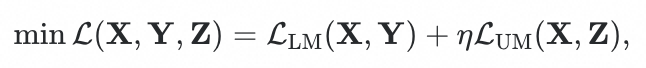 其中 是超参数。
其中 是超参数。
2.2 商品表征:多模态融合表征
为了同时发挥出 ID 特征中蕴含的商品信息和文本模态中的世界知识,我们设计了一个简单高效的多模态特征融合模块。其结构如下图所示,商品的 LLM 表征和 ID 表征首先通过 MLP 层映射到相同空间,然后通过加法结合,再使用 RMSNorm 进行归一化,并通过另一个 MLP 层映射到用户表征空间。
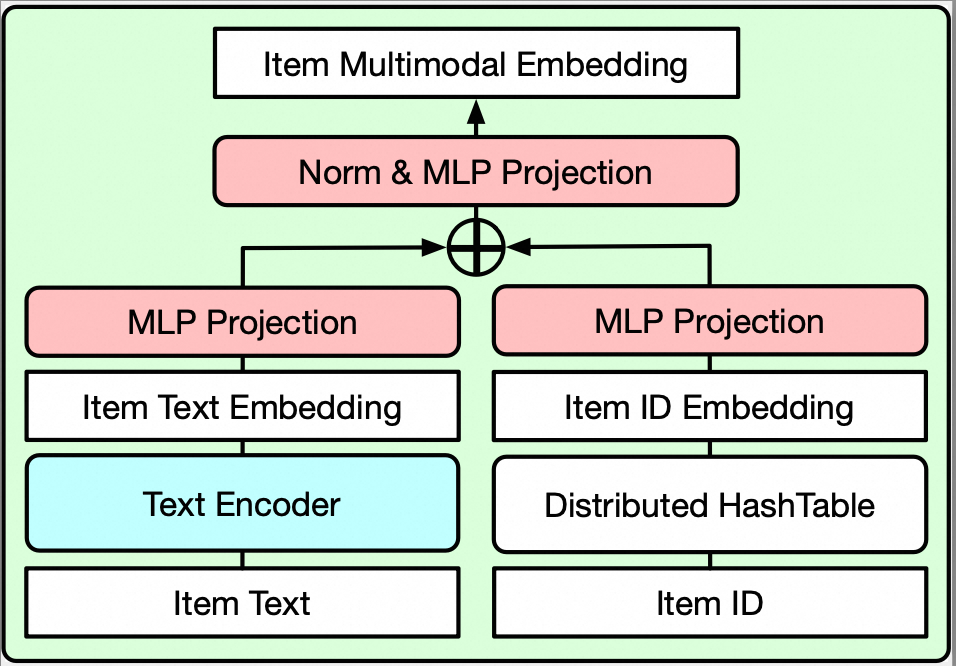
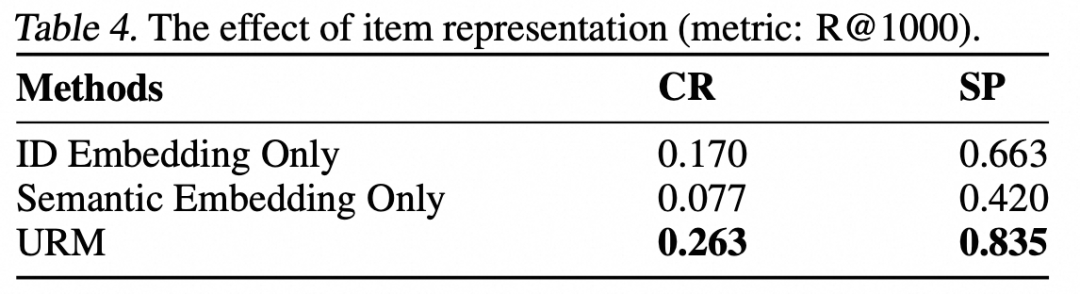
不同表征在大模型召回里的效果如下表所示,可以发现两种模态的特征均对模型效果有显著正向的影响。
2.3 高效商品生成:序列输入集合输出(Sequence-In-Set-Out)
在实际应用中,一个亟需解决的问题是,如何既能保留对用户和商品之间的复杂建模能力,同时又尽可能降低大模型的推理成本?
常见的推荐范式是对用户 和商品 进行打分,然后从候选中选出分数最高的商品。最典型的模型结构是 先计算用户行为序列和目标商品之间的 Target-Attention,然后和用户侧特征、商品侧特征一起输入给多层 MLP 网络得到最终分数。这种模式在推荐的全链路(召回、粗排、精排、重排)都得到了广泛的验证,然而直接推广到大模型上会难以同时兼顾效果和效率:
如果将用户的历史行为和目标商品一起输入大语言模型,对于工业系统而言,需要的计算量是一个天文数字,因此这种模式目前仅仅停留在学术界。
如果只将用户的历史行为输入大语言模型,然后生成目标商品(通常被称为生成式推荐),计算量相对可控,但是其本质是一个双塔模型,建模能力相对较差,因此其他公司往往会将其用于召回阶段。然而阿里妈妈展示广告早在 17 年就摒弃了双塔召回,拥抱了复杂模型召回。在实践中,我们也发现这种方式的效果天花板较低,难以充分发挥大语言模型的价值。
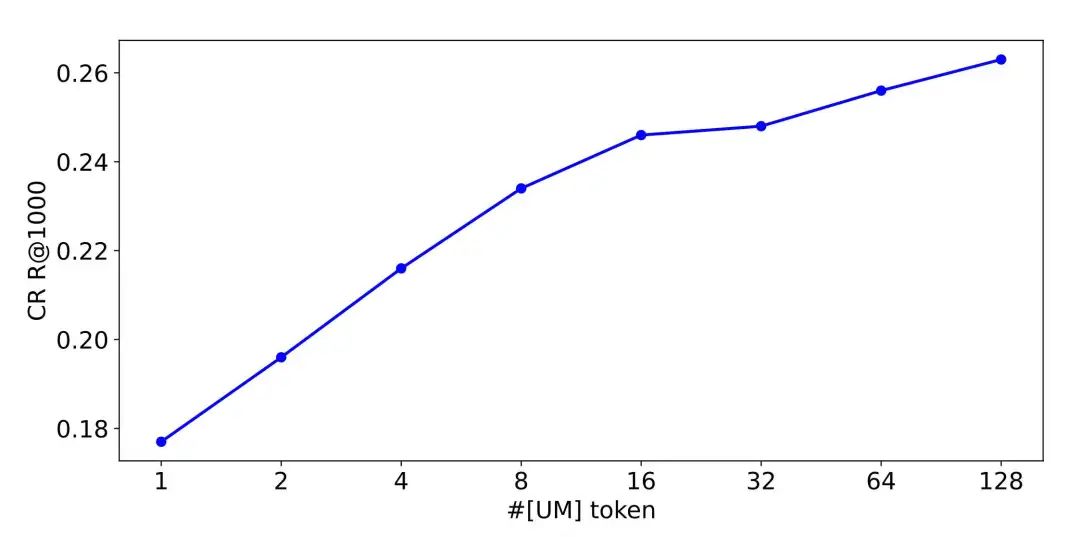
函数逼近理论的一个结论是,特征的多个内积的线性组合可以逼近任意复杂的函数。因此我们想到将用户的历史行为输入到大语言模型,生成 个用户表征,分别和目标商品表征计算内积,然后用它们的线性组合作为最终的分数(实践中发现 max 函数相比 avg 效果更好),这种方式充分保留了用户和商品之间的复杂建模能力,提高了模型能力的上界。下图给出了在表征个数不断增大的过程中,全域推荐召回指标的变化趋势。当 时,URM 在全域召回任务上的效果可以和线上使用 Target-Attention 结构的传统召回模型基本持平。
大语言模型原生的输出方式是自回归地生成下一个 Token,如果直接自回归地生成个用户表征,不论是时延还是资源消耗都是完全无法接受的,因此我们借鉴了 Q-Former 和 Multi-Token Prediction 的想法,在大模型的输入结尾增加了 个 Query Token(图中 [UM] token),经过 LLM 的一次 Forward,同时得到 个不同的用户表征 ,最终用户和商品之间的打分为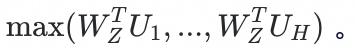
由于前向注意力的存在,不同位置的用户表征可以关注到用户的不同兴趣。下图是模型对某一个用户生成的不同位置的用户表征所对应最终商品的可视化,可以看到用户在信息流推荐场景下的兴趣极其多样。这也解释了双塔结构在推荐场景下的局限性,因为内积难以刻画用户多元化的兴趣。

大模型召回如何高效生成集合?召回的目标是从一个千万级别的候选库中找到价值最大的 个商品,它和语言模型 LM 从十万规模的词表空间中生成语言概率最大的 Token,本质上是相同的问题,因此若不考虑计算成本,我们可以通过下述方式获得召回结果:
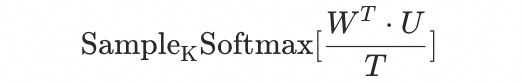
其中 是所有商品的融合表征,类似 LLM 中的最后一层将表征解码到 token 空间的权重参数; 是大语言模型生成的用户表征,对应 LM 中的隐藏层特征(不失一般性,我们这里只考虑生成一个用户表征的情况)。然而商品库的规模过于庞大,使得这个内积计算在实践中无法使用。因此我们将这一步与二向箔 HNSW 检索进行了有机结合。首先对 构建层次化索引结构,接下来每次计算概率的时候,只从 中选取一个子矩阵,进行概率计算,然后根据概率最大的商品生成新的子矩阵。因此理论上,这是一种大模型在千万级规模候选上进行 Next-Token 生成的近似方法。
2.4 离线实验
URM 使用多任务(MTL)融合数据集训练,并在生产数据集上取得了平均 11.0% 的 Recall 提升,在 6 个子任务(共 9 个任务)中都超越了线上使用 Target-Attention 结构的传统召回模型。
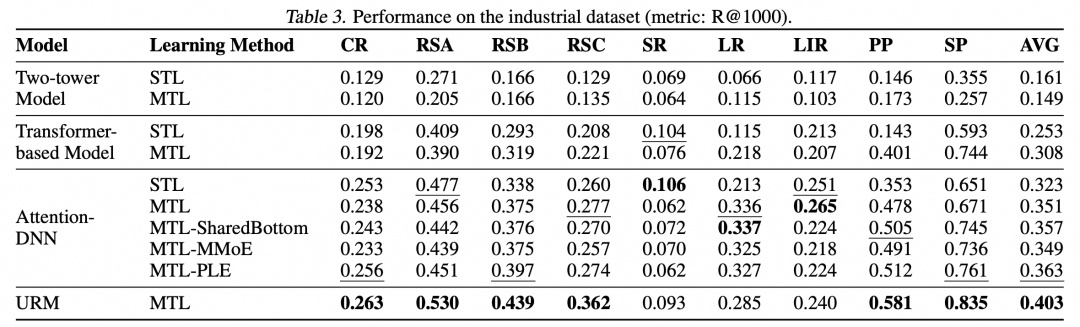
通过进一步的消融实验,我们验证了表征融合模块的有效性,也验证了随 UM Token 数量上涨召回 Recall 呈显著上涨(参见 2.2 和 2.3 节中的结果)。
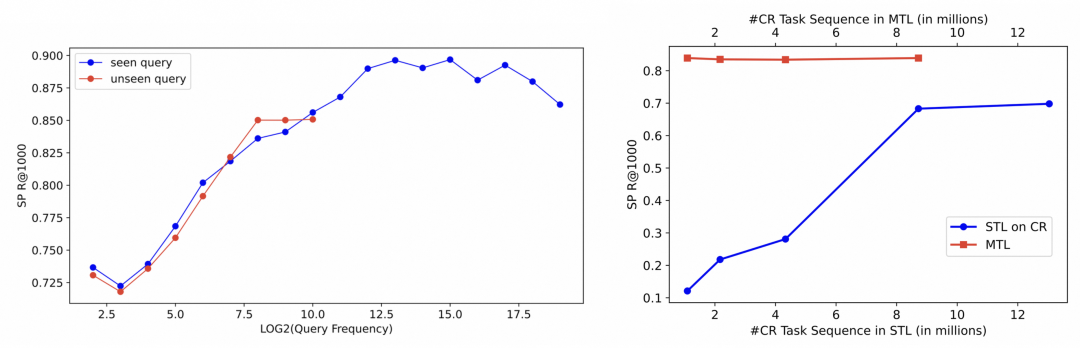
得益于预训练 LLM 模型的引入,URM 具备良好的文本理解能力和泛化能力。下图(左)说明了 URM 在搜索任务(SP)上对已知的 Query 文本和未知的 Query 都有良好的推荐表现。当仅在推荐任务上训练、直接在搜索任务上测试(STL on CR 曲线)时,搜索任务 Recall 相比多任务训练(MTL)有一定下降,但URM 依然具备一定程度的指令跟随能力和结果获取能力,如下图(右)所示。
此外,通过改变 Prompt,如下表(左)所示,URM 能有效建模不同场景下(RSA、RSB、RSC)的商品分布,根据对应的模板调整召回集合。此外,下表(右)体现了 URM 在搜索(SP)和长尾(LIR)任务上训练后,泛化到训练集上未曾见过的 Prompt 模板(SP x LIR 搜索长尾任务)的能力。
3. 高QPS低时延约束下的落地方案
考虑到 LLM 的推理时延较长,无法满足在线请求的时延约束,因为我们建设了一套异步推理的大模型召回链路。如下图所示,在用户有淘系行为时异步触发 URM 推理,并将结果做持久化存储,供在线召回阶段读取使用。
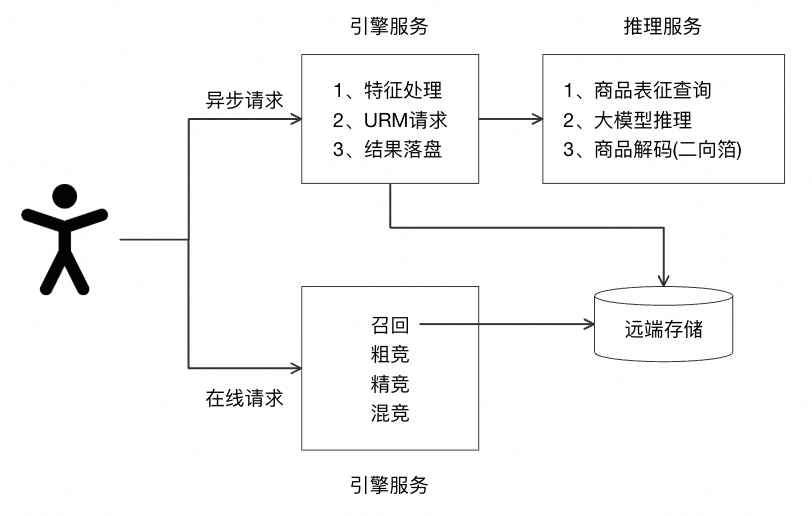
引擎服务主要包括特征处理、URM 请求和结果落盘三部分。为了支持 LLM 推理,我们设计了面向大模型 Prompt 的特征服务,将 Prompt 模板视作一种复杂特征算子,相关逻辑可直接迁移至在线推理链路。
模型推理服务的任务是根据接收到的 Prompt 输入完成完整的打分和检索逻辑,传回最终召回的商品集合,包括亿级商品表征查询模块、大模型推理服务和商品解码模块(HNSW 检索)三部分,并通过集成部署避免版本不一致问题。从推理效率上,新增的亿级商品表征查询模块和商品解码模块(二向箔HNSW)对性能影响较小,相比于传统的大模型推理,可近似认为 URM 的模型推理成本与输出 1 个 Token 相当。大模型推理服务基于阿里妈妈大模型服务框架 HighService 和 vLLM 框架搭建,服务内部通过多进程方式接受 Prompt 和查到的 Embedding,LLM 部分只计算 Perfill 阶段,采用了 Flash Attention 来加速模型推理。考虑到部署单个模型时 GPU 利用率还存在空间,我们通过多 Instance 优化模型推理效率,最优版本可将 QPS 提升 200%。
4. 结语
本文分享阿里妈妈LMA2广告大模型系列中的通用召回大模型 URM 在建模和落地方面的思考和进展。通过结合大模型的通用知识和电商领域的专家知识,URM 能够更加精准地预测用户的潜在兴趣和购物需求,实现消费者、商家和平台的三方共赢。
更多 URM 细节可参考论文:https://arxiv.org/pdf/2502.03041。
🏷 关于我们
我们是阿里妈妈展示&内容广告团队,负责淘系信息流场景的广告投放,作为行业创新标杆,连续产出KDD、NeurIPS、WWW等顶会优秀工作(如DIN、DIEN、TDM、NeuralAuction等)。欢迎感兴趣的同学加入我们,一起参与阿里妈妈展示广告系统架构设计,接触召回/预估/机制策略等全链路技术攻坚项目,实现学术理论与工业级落地的双向突破,助力个人技术影响力跨越式提升。
📮 简历投递邮箱(备注:展示&内容广告):alimama_tech@service.alibaba.com

丨展示广告预估技术最新突破:基于原生图文信息的多模态预估模型
丨WWW'25 | 大模型深度赋能搜索广告:相关性大模型多维知识蒸馏
丨WWW'25 | DAGPrompT:分布感知的图提示微调方法
丨淘天集团全面升级AIGX技术体系,AI赋能电商经营所需全部场景
丨Bidding模型训练新范式:阿里妈妈生成式出价模型(AIGB)详解
丨更真、更像、更美:阿里妈妈重磅升级淘宝星辰视频生成大模型 2.0

喜欢要“分享”,好看要“点赞”哦ღ~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢