
DRUGAI
尽管信息量巨大,大多数非靶向质谱数据仍未被充分利用;其中的大部分分析物在发表后并未被用于后续解读或再分析。这主要源于现有软件工具在灵活性和可扩展性上的限制。研究人员在此提出了一种新语言——质谱查询语言(MassQL),及其配套软件生态系统,可让用户通过自定义的质谱模式直接查询原始数据。通过多个真实案例展示,MassQL 实现了对公开非靶向代谢组数据的重新分析,为揭示化学多样性提供数据驱动的新定义,使不同领域的研究人员能够发现新的科学线索。MassQL 已广泛集成于多个开源和商业质谱分析工具中,提升了数据挖掘的能力、互操作性与可重复性。

质谱技术的创新推动了生命科学领域的重大进展,随着仪器设备的不断发展,质谱已广泛应用于组学研究,如代谢组学、脂质组学和蛋白质组学等。尽管质谱被广泛用于解析蛋白质、多肽、高分子、小分子和核酸等化合物,但研究人员仍难以灵活地在单个或多个质谱数据集中搜索特定的化学类别。当前对质谱数据中特定化合物或分子类别的检索,通常依赖于质荷峰、同位素特征、特定质量差(MS1)、碎片化模式(MS/MS)、色谱保留时间、碰撞截面等特征的组合。这种搜索方式多为手动检查,不仅效率低下,而且易出错。虽然已有一些专用软件工具用于此类搜索,但它们往往局限于查找特定化合物或少量类别特定的模式。研究人员虽可通过编写定制脚本实现更高的灵活性,但多数生命科学实验室缺乏相关计算能力,难以开发或调整这些工具。这样的技能差距限制了生物学家和化学家有效挖掘质谱数据的能力,可能导致许多重要分子被遗漏。为解决这一问题,研究人员提出了 MassQL——一种开源的质谱查询语言,具备良好的灵活性,并可跨质谱仪厂商使用。MassQL 旨在帮助非计算背景的研究人员无需编程技能即可在 MS1 和 MS/MS 数据中搜索感兴趣的特征模式。本文介绍了 MassQL 的语言设计、配套的计算生态系统,并通过两个应用示例展示了其在公共数据资源(如 GNPS/MassIVE、Metabolomics Workbench 和 MetaboLights)中的使用潜力。
结果
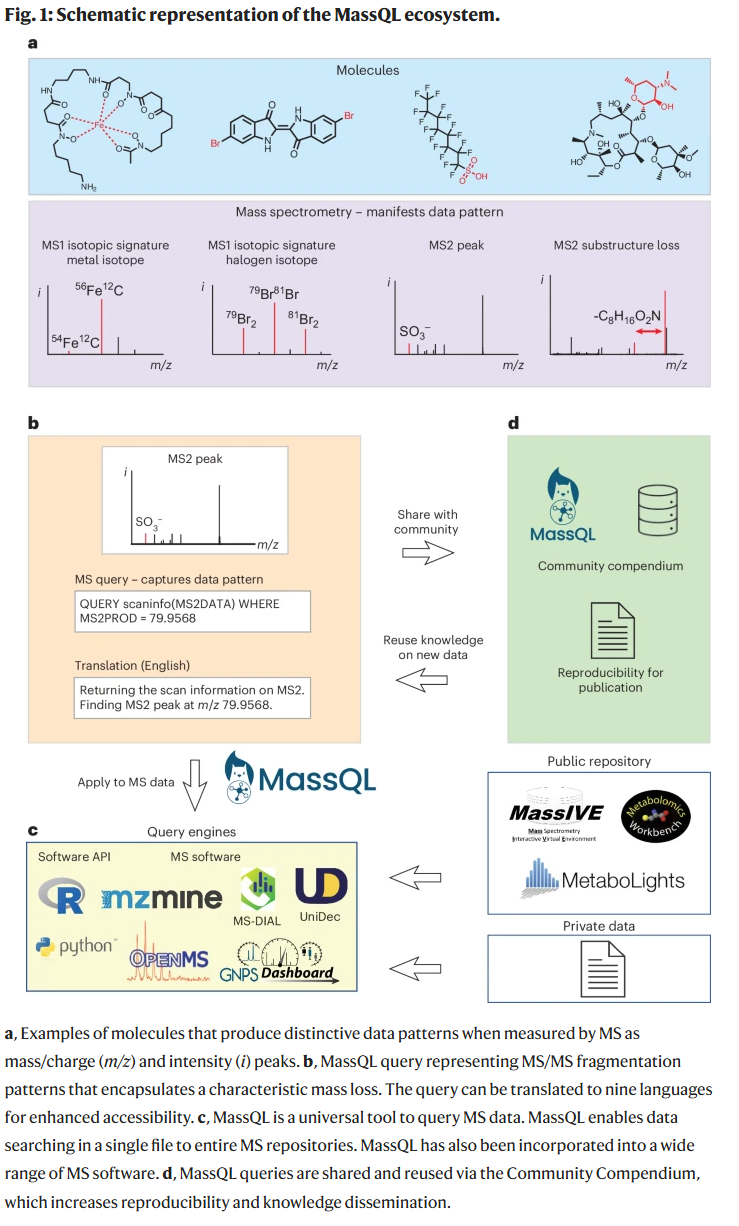
质谱技术具备识别同位素模式(如溴化物)、诊断性碎片(如硫酸根离子)和中性丢失(如糖基丢失)等结构特征的能力,是一种强大的分析工具。然而,如何综合利用这些多维信息仍面临挑战。为此,研究人员开发了 MassQL 语言,通过简洁而富表达力的语法,支持在 MS1 和 MS/MS 数据中搜索相关化学模式,还可结合色谱和离子迁移率限制。用户可自定义误差范围、强度阈值,并使用逻辑运算符组合多个条件,从而实现复杂查询。由于这些模式普遍存在于不同类型的质谱数据中,MassQL 可跨厂商、跨质谱平台使用,大幅降低质谱数据挖掘门槛。此外,MassQL 的语法结构允许扩展和演化,保持对新质谱技术的兼容性。
MassQL 的计算生态包括语法定义、解析器、查询引擎、Web 界面,以及支持大规模并行查询的 NextFlow 工作流,适用于从单个文件到整个数据库的查询。MassQL 的语法基于常见质谱术语,使得具有基础质谱知识的研究人员也能轻松编写查询。为进一步降低使用门槛,研究人员提供了详尽文档、教学视频、在线沙盒环境,并开发了一个支持多语言翻译的查询解释器和基于大语言模型的实时对话助手。此外,一个社区维护的应用案例库也已建立,便于查询共享与复用。
MassQL 起初集成在 GNPS 平台中,为扩大应用范围,研究人员推动其在多个开源与商业质谱软件中实现原生支持,如 MZmine、MS-DIAL、pyOpenMS、UniDec 和 Bruker 的 MetaboScape。这些工具共享语法但采用独立引擎,确保语义一致的同时优化性能。MassQL 还提供 Python 与 R 接口及 Web API 以支持平台集成。
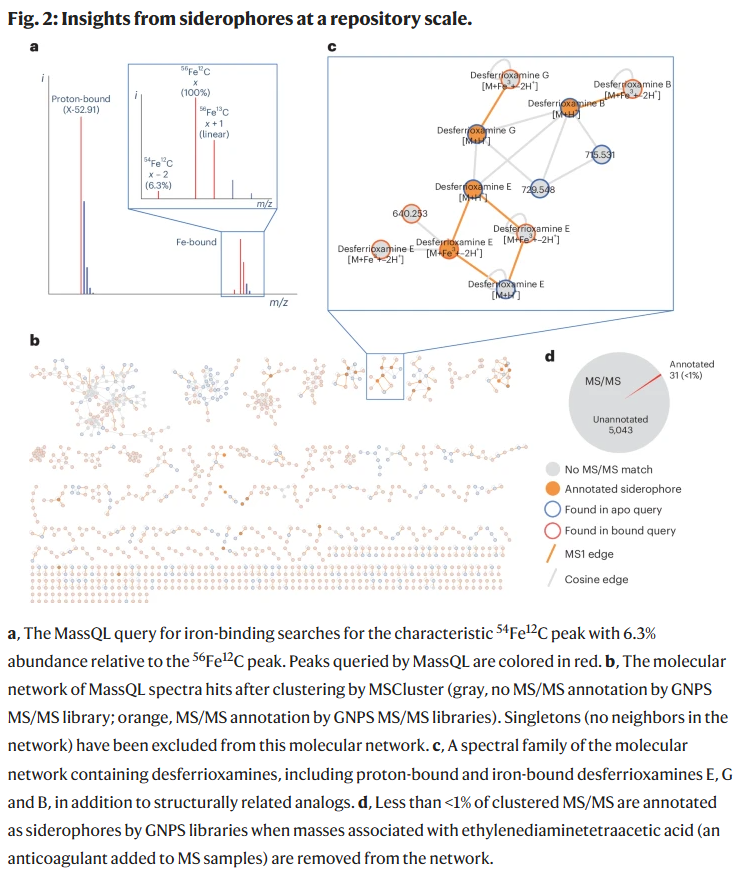
铁载体分子的数据库级发现
铁结合小分子(如铁载体)在微生物和哺乳动物体内调节铁稳态中发挥关键作用。研究人员基于之前开发的注铁代谢组分析方法,构建 MassQL 查询以识别具有特征 m/z 差值(52.91)和同位素分布的铁结合分子。利用 Eutypa lata 提取物的质谱数据开发查询后,在 GNPS/MassIVE 的 23 亿个分析物中识别了 26,944 条 MS/MS 光谱,经过聚类与网络分析,发现大量潜在铁载体分子,其中大部分尚未在现有数据库中注释,揭示了新的化学空间。
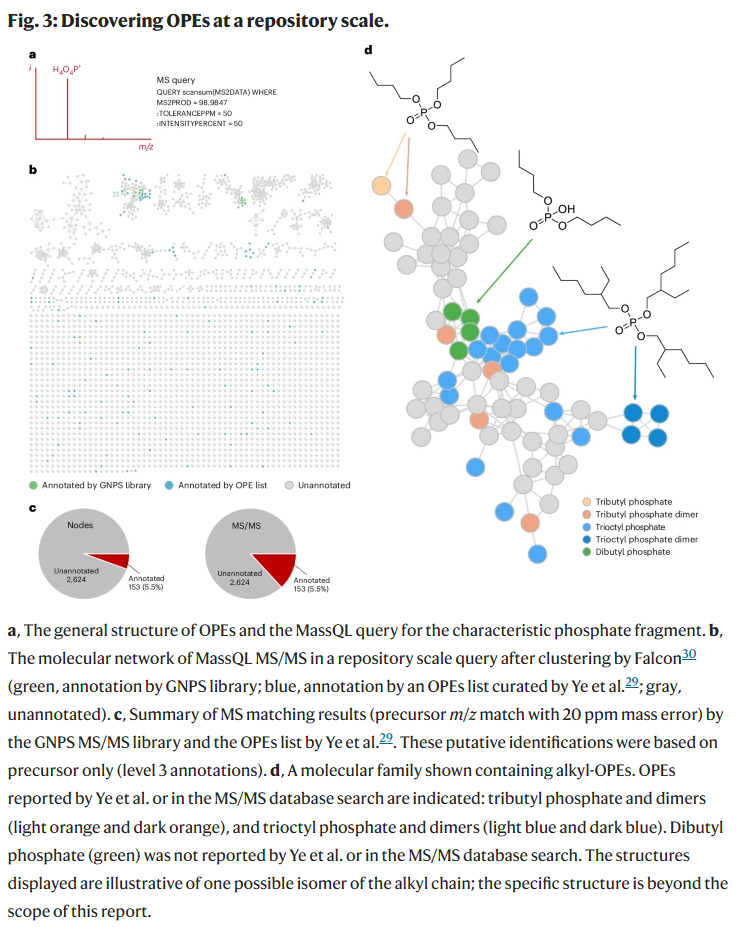
环境中的磷酸酯类物质(OPEs)
磷酸酯类物质是常见的阻燃剂和塑化剂,广泛存在于环境样本中。研究人员基于其特征性碎片离子(m/z 98.9842),构建 MassQL 查询,并在海水测试样本和公共数据库中进行筛查。结果检出约 34 万条相关 MS/MS 光谱,仅 15% 与已知 OPEs 相符,进一步构建共识光谱与分子网络后,发现多个潜在新 OPEs。结合 MassQL 与分子网络的策略,既降低了计算负担,也提升了结构发现的能力。
假阳性控制与验证策略
MassQL 的核心挑战在于如何构建既敏感又特异的查询。通用的假阳性估计方法难以统一,研究人员通常需依据研究目的制定个性化策略。例如在胆汁酸的研究中,通过与光谱库比对来估计假阳性率。但对于结构多样的铁载体类化合物,研究人员采用构建“诱饵查询”策略评估假发现率。在数据库级别搜索中,结合分子网络和光谱比对等方法有助于过滤假阳性,并将数据压缩至可控范围。MassQL 在此过程中作为“预筛选器”使用,为后续分析和验证提供候选目标。研究人员鼓励用户根据自身研究目的制定合理的验证方案。
讨论
研究人员在本研究中提出了 MassQL,这是一种与平台和厂商无关的质谱数据查询语言,可用于在单个或跨多个质谱数据集中搜索特定模式。MassQL 的主要目标是为非计算背景的研究人员提供灵活手段,以简洁的方式表达复杂的质谱模式,减少编写定制脚本的需求。配合社区构建的软件基础设施,MassQL 生态系统降低了化学和生物领域研究人员进入质谱数据挖掘的门槛。MassQL 的应用已扩展至质谱数据挖掘、微生物组研究、暴露组学、生物监测、感染性疾病研究以及天然产物发现等多个领域。
尽管传统的 MS/MS 相似性搜索方法(如光谱库搜索)在识别相似化合物方面具有优势,MassQL 提供了更灵活和精确的查询能力。传统工具通常依赖整体 MS/MS 相似性匹配,而 MassQL 则允许研究人员基于自定义的片段离子、中性丢失、色谱保留时间或漂移时间等约束条件进行检索。这种方法尤其适用于结构微小变化可能导致碎片模式显著变化的情况,避免传统方法遗漏潜在类似物。MassQL 可用于搜索保守的关键片段或中性丢失信号,无需完整的 MS/MS 匹配,从而补充了基于相似性的方法。
此外,将 MassQL 与其他分析工具结合使用,可进一步提升数据解析效率。例如,在本文中,研究人员展示了如何将 MassQL 用作预筛选工具,再结合分子网络和光谱库比对进行下游分析,以支持铁载体和磷酸酯类物质的发现。MassQL 也可作为分子网络后的过滤工具,用于化合物优先级排序和识别碎片对齐不良的化合物。不过,目前 MassQL 在处理连续的 MS 光谱(如色谱峰过程中产生的连续信号)方面仍有限,未来仍有改进空间。
研究人员预计 MassQL 的生态系统将在应用范围和功能上持续扩展。目前,语言表达能力和查询效率仍有提升空间,MassQL 的设计已为此做好架构准备。其格式无关的语法定义允许不同的软件使用统一语义的语法,而由社区开发的查询引擎可基于相同语法提升速度和性能。这一模式已在多个主流质谱软件中实现,如 MS-DIAL、Mzmine 和 Bruker 的 MetaboScape。
MassQL 的发展得益于开放源代码社区的活跃参与,研究人员预计这种社区主导的语言演进将持续推进,最终使 MassQL 更加完善、强大,满足科学界日益增长的质谱数据挖掘需求。
整理 | WJM
参考资料
Damiani, T., Jarmusch, A.K., Aron, A.T. et al. A universal language for finding mass spectrometry data patterns. Nat Methods (2025).
https://doi.org/10.1038/s41592-025-02660-z
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢