


关键词:大规模并行计算; 欧氏空间; k-Center

导 读
本文是对已被 ICALP 2025 接收的 Fully Scalable MPC Algorithms for Euclidean k-Center 一文的解读。该工作由北京大学姜少峰课题组与 University of Warwick 的 Artur Czumaj、MIT 的 Mohsen Ghaffari 合作完成,论文主要贡献者之一高贵晨为北京大学计算机学院博士生。
论文聚焦于大规模并行计算(Massively Parallel Computation, MPC)模型下欧氏空间中 k-Center 问题,分别在低维和高维的设定下设计了完全可扩展的常数轮 MPC 算法。

← 扫码跳转论文
论文地址:https://arxiv.org/abs/2504.16382
01
问题及背景
对大规模数据进行聚类是计算机科学中一项基本的计算任务,我们考虑欧氏空间下的
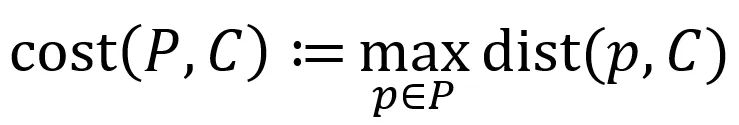
其中,
MPC 模型最早由 Karloff、Suri 和 Vassilvitskii[1]于2010年提出,是并行计算中一种重要的模型,可以用来建模 Hadoop、Spark 等众多实际广泛应用的并行计算框架。在 MPC 模型中,设有
除了轮数尽量追求常数轮,MPC 算法还应该是完全可扩展(Fully Scalable)的:即算法在任何内存参数
02
主要结果
针对欧氏空间(包括低维和高维)中的
03
技术概述
我们针对
几何RS和MDS的规约和结果
几何 RS 和 MDS 的定义:对于集合
规约:已有研究表明(参见例如[4]),若
RS 和 MDS 的结果:我们在低维和高维设定下分别获得了关于 RS 和 MDS 的结果,如表1所示。结合前文所述的规约方法,这些结果自然地推出了
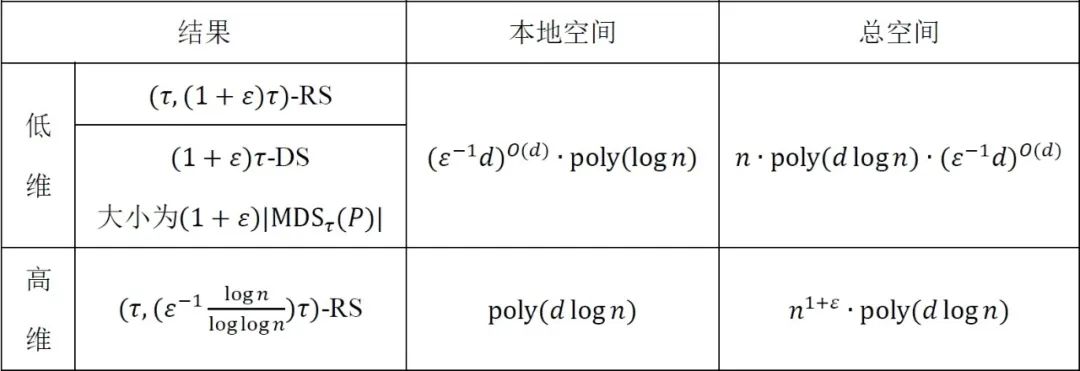
表1. RS 和 MDS 的结果,所有结果均可在
MIS、RS 和 MDS 是 MPC 中基础却非常具有挑战性的问题。已有的相关研究大多集中在(一般)图或一般度量空间上,并且这些研究所取得的界限往往不如我们的结果,例如,他们需要使用超常数轮数的算法[5-10],和/或不是完全可扩展的[9, 11, 12]。我们的结果似乎表明,这些问题在欧式空间中的表现与在图/一般度量空间中的表现非常不同。一方面,我们在低维和高维下都得到了完全可扩展的算法;但另一方面,我们的算法对于 MIS 和 MDS 来说仍然只是“近似解”,例如,在低维情况下,我们的 RS 和 MDS 结果对 MIS 和 MDS 的支配参数都有
高维设定下的 RS
我们在高维空间中提出的
基于几何哈希的预处理步骤:为了突破
04
总 结
本文探索了低维和高维欧式空间中
参考文献
[1] Howard J. Karloff, Siddharth Suri, and Sergei Vassilvitskii. A model of computation for MapReduce. SODA 2010.
[2] MohammadHossein Bateni, Hossein Esfandiari, Manuela Fischer, and Vahab S. Mirrokni. Extreme k-center clustering. AAAI 2021.
[3] Sam Coy, Artur Czumaj, and Gopinath Mishra. On parallel k-center clustering. SPAA 2023.
[4] Dorit S. Hochbaum and David B. Shmoys. A unified approach to approximation algorithms for bottleneck problems. Journal of the ACM 1986.
[5] Krzysztof Onak. Round compression for parallel graph algorithms in strongly sublinear space. arXiv 2018.
[6] Mohsen Ghaffari and Jara Uitto. Sparsifying distributed algorithms with ramifications in massively parallel computation and centralized local computation. SODA 2019.
[7] Mohsen Ghaffari, Christoph Grunau, and Ce Jin. Improved MPC algorithms for MIS, matching, and coloring on trees and beyond. DISC 2020.
[8] Chetan Gupta, Rustam Latypov, Yannic Maus, Shreyas Pai, Simo Särkkä, Jan Studený, Jukka Suomela, Jara Uitto, and Hossein Vahidi. Fast dynamic programming in trees in the MPC model. SPAA 2023.
[9] Jeff Giliberti and Zahra Parsaeian. Massively parallel ruling set made deterministic. DISC 2024.
[10] Hongyan Ji, Kishore Kothapalli, Sriram V. Pemmaraju, and Ajitanshu Singh. Fast deterministic massively parallel ruling sets algorithms. ICDCN 2025.
[11] Mélanie Cambus, Fabian Kuhn, Shreyas Pai, and Jara Uitto. Time and space optimal massively parallel algorithm for the 2-ruling set problem. DISC 2023.
[12] Alireza Haqi and Hamid Zarrabi-Zadeh. Almost optimal massively parallel algorithms for k-center clustering and diversity maximization. SPAA 2023.
[13] Johannes Schneider and Roger Wattenhofer. An optimal maximal independent set algorithm for bounded-independence graphs. Distributed Computing 2010.
[14] Michael Luby. A simple parallel algorithm for the maximal independent set problem. STOC 1985.
[15] Artur Czumaj, Arnold Filtser, Shaofeng H.-C. Jiang, Robert Krauthgamer, Pavel Veselý, and Mingwei Yang. Streaming facility location in high dimension via geometric hashing. FOCS 2022.

图文 | 高贵晨
PKU 姜少峰Lab

姜少峰博士,现任北京大学前沿计算研究中心助理教授、北京大学博雅青年学者,于2021年正式加入中心。他于2017年在香港大学获得博士学位,曾在以色列魏茨曼科学研究学院进行博士后研究,并曾在芬兰阿尔托大学任助理教授。他的研究方向为理论计算机科学,近期侧重于大数据算法及其在机器学习中的应用,并已在包括 STOC,FOCS,SICOMP,SODA,ICML,NeurIPS 等主流国际期刊和会议上发表论文多篇。
姜少峰Lab相关科研动态


— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

点“阅读原文”转论文链接
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢