
DRUGAI
预测治疗反应是真实世界应用中的重要问题,但治疗反应的异质性在实践中仍是一大挑战。为此,研究人员提出了无监督机器学习方法,通过聚类电子健康记录(EHR)相似的患者来缓解该问题,然而这些方法难以保证分组内部结果一致性。本文中,研究人员提出了一个通用机器学习框架——图编码混合生存模型(GEMS),用于识别具有一致生存结果和基线特征的预测性亚表型。研究人员将该方法应用于晚期非小细胞肺癌(aNSCLC)接受一线免疫检查点抑制剂(ICI)治疗的真实世界数据中,以预测总生存期(OS)。结果表明,该方法在预测OS方面优于传统方法,并识别出三个具有可重复性、且在基线特征和生存结局上具有显著差异的亚表型,展示了其在解析治疗反应异质性和辅助治疗决策中的潜力。

非小细胞肺癌(NSCLC)具有显著的异质性,其病理生理特征受肿瘤及其微环境中的生物标志物表达、免疫反应和组织学差异的影响。NSCLC 占所有肺癌的 80-85%,其中 75% 在晚期被诊断,五年生存率仅为 26.4%。患者间在合并症负担和伴随用药等方面也表现出差异性。尽管免疫治疗和靶向疗法取得显著进展,治疗反应仍存在高度异质性。
为应对疾病复杂性和个体差异,研究人员提出精准医学,目标是在合适的时间为合适的患者提供合适的治疗。实现这一目标需整合多层次数据,包括组学、临床和环境信息。近年来,随着大规模生物医学数据的积累,机器学习方法被广泛应用于从中挖掘洞见,为医学转型提供了新机遇。
然而,个体化治疗仍面临诸多挑战,包括患者状态异质性、疾病机制认知不足以及生物标志物获取不完善。作为中间策略,分层医学通过已有信息(如遗传标志)划分患者群体,以提高治疗一致性。另一种策略是采用无监督机器学习从数据中划分患者群体,但这些方法难以保证组内治疗结局一致。
为此,研究人员提出了一种通用机器学习框架——图编码混合生存模型(GEMS),用于从电子健康记录(EHR)中识别预测性亚表型。每个亚表型代表一组具有相似基线特征和一致生存结局的患者,并在不同亚表型间呈现明显的生存差异。研究人员将 GEMS 应用于来自美国大型肿瘤数据库的晚期 NSCLC 患者队列,在个体治疗反应预测方面优于现有方法,并识别出三个具有显著生存差异的预测性亚表型。
结果
研究框架概述
本研究的整体流程如图1所示。研究人员基于美国肿瘤EHR数据库(ConcertAI Patient360™ NSCLC)构建了一组接受一线免疫检查点抑制剂(ICI)治疗的晚期非小细胞肺癌(aNSCLC)患者队列(2015年1月至2023年1月)。每位患者用一个104维特征向量表示,涵盖人口统计学信息、实验室检测、生命体征、合并症、转移部位及用药情况等。
研究人员提出的GEMS模型能够识别与真实世界总生存期(OS)相关的预测性亚表型。该模型采用图神经网络(GNN)编码器构建患者表示,并通过聚类模块对患者进行分群,最终形成用于生存预测的混合模型。训练完成后,GEMS可用于识别ICI治疗患者的亚表型。
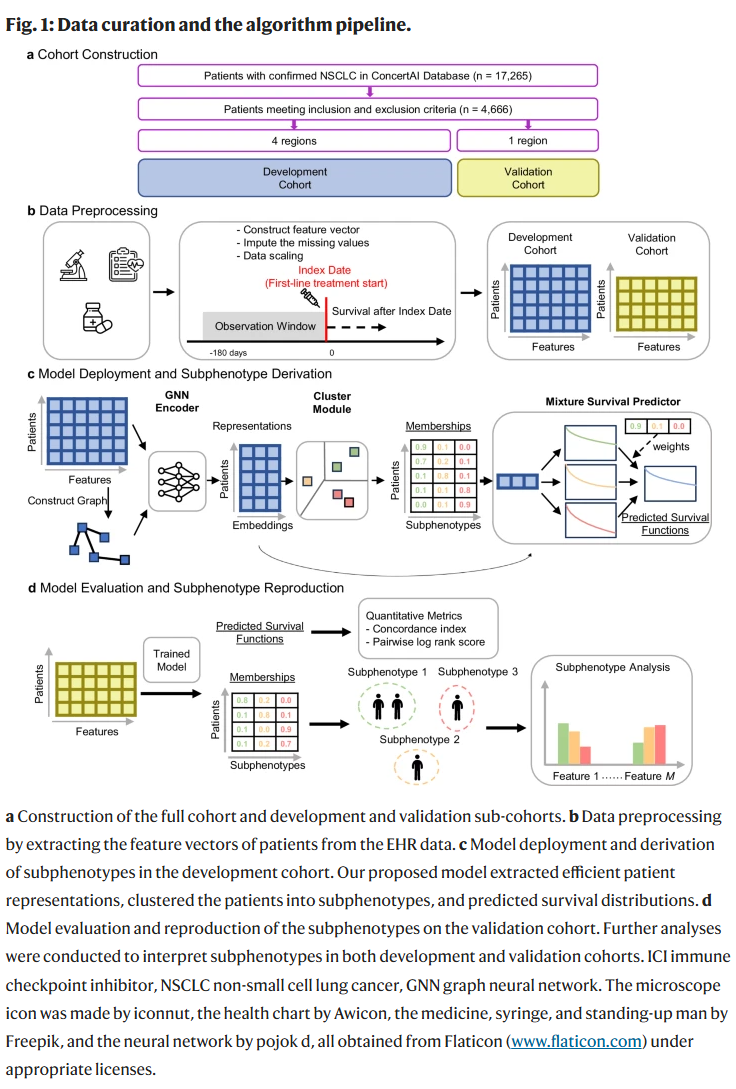
研究队列
研究使用了一项回顾性观察性队列,共包含17,265名确诊为NSCLC的患者。经筛选后,最终纳入4666名患者,剔除了不符合标准或缺少生存信息的个体。该队列平均年龄为68.69岁,女性占43.77%,白人占81.37%。其中71.09%的患者在随访中记录了死亡事件,中位OS为314天。
研究人员依据临床机构所在的地理区域将队列划分为开发集和验证集,分别占69.12%和30.88%。两个子队列在年龄和性别上分布相似,但验证集中白人比例和社区机构患者比例更高。详细人口统计信息见表1。
定量预测性能
研究使用一致性指数(c-index)和log-rank评分评估GEMS与多种基线模型在预测OS方面的表现。比较模型包括Cox回归、加速失效时间模型(AFT)、生存支持向量机、梯度提升树(GBDT)、神经生存聚类(NSC)、K-means和层次聚类等。
GEMS在验证集中的平均c-index为0.665,优于最佳基线方法GBDT的0.652;log-rank评分为69.17,也高于NSC的56.23。此外,在开发集中交叉验证结果也显示GEMS在c-index和log-rank评分方面表现更优。
研究人员还评估了GEMS在预测无进展生存期(PFS)方面的表现。在固定GNN编码器和聚类模块的基础上,仅调整生存预测模块,GEMS在PFS预测任务中同样优于基线模型。
通过消融实验,研究人员评估了各模块及损失函数的影响。结果显示,使用GNN编码器显著提升了性能,相较于直接使用原始特征或替换为多层感知机(MLP)均有优势。此外,移除聚类或统计显著性损失项会降低模型效果。
UMAP可视化进一步表明,使用GNN编码器后,患者在潜在空间中的分布更加清晰,生存期不同的患者被有效区分,而原始特征空间中分布混杂。
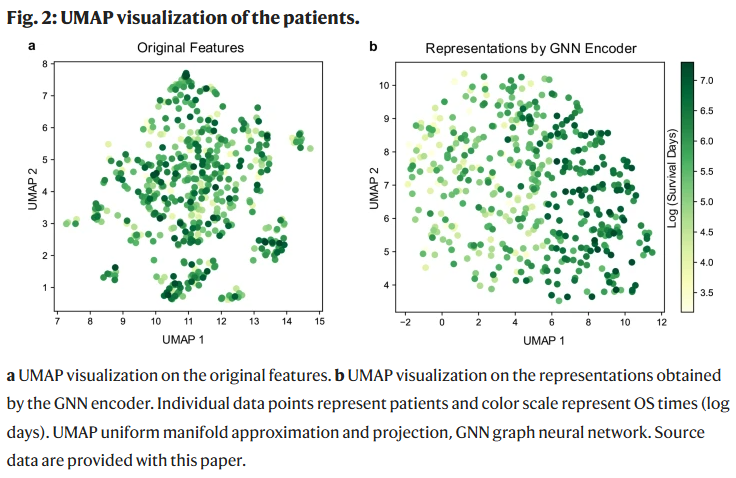
预测性亚表型
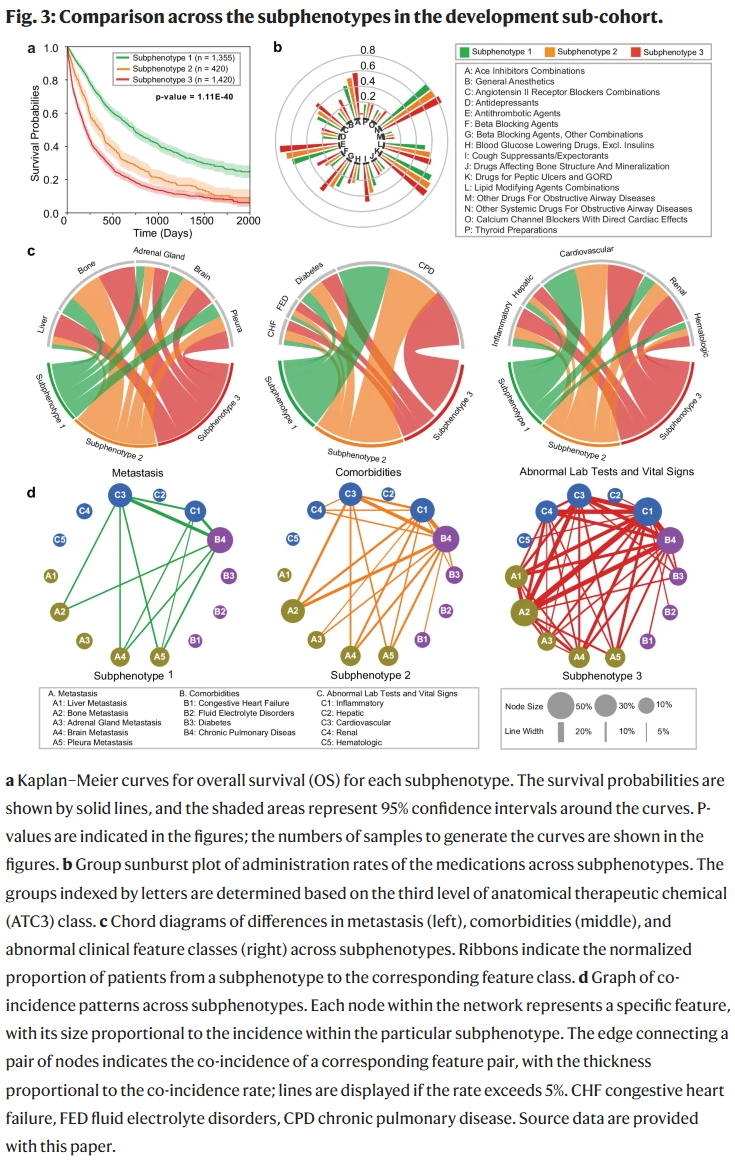
在开发集中,研究人员识别出三类预测性亚表型,分别展示了不同的人口学特征、吸烟史与OS差异(见表3和图3)。
亚表型1(n=1335, 42%):女性比例最高(55.50%),平均OS最长(688天)。该组患者使用止咳药、β阻滞剂、ACE抑制剂等药物比例较低,转移至骨、肾上腺和脑的发生率也最低,合并症如心衰、糖尿病及肾功能异常比例最小。
亚表型2(n=420, 14%):女性比例最低(33.78%),平均OS为454天。生存概率下降速度在治疗后500天内较平稳,之后加速下降。其肝转移率与亚表型1相近,合并症和异常检查结果处于中等水平。
亚表型3(n=1420, 44%):女性占35.21%,平均OS最短(321天)。该组患者的药物使用率最高,肝、骨、肾上腺及脑转移率均为最高,合并流体电解质紊乱、糖尿病和肾功能异常比例也最高,显示出更重的疾病负担。
这些亚表型揭示了晚期NSCLC患者在治疗反应和生存结局上的异质性,并为精准治疗提供了潜在依据。
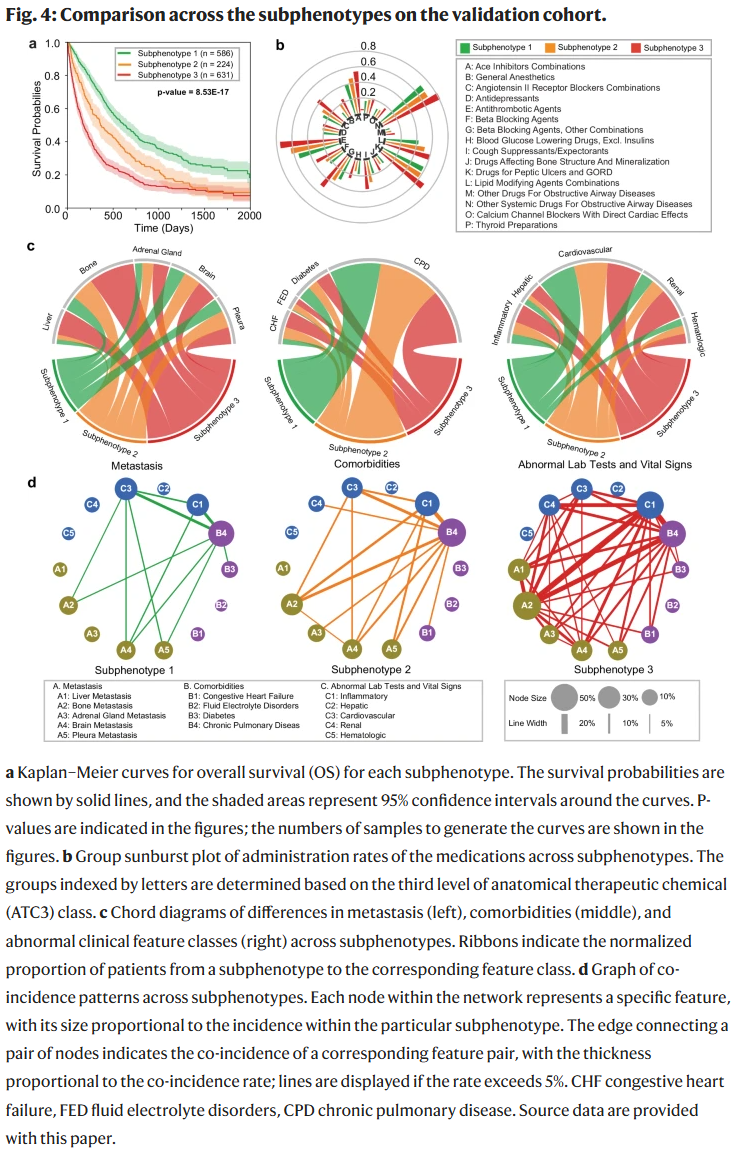
验证队列中的亚表型可重复性
研究人员使用在开发集上训练的GEMS模型对验证集中的患者进行亚表型划分。各亚表型的人口学特征、吸烟史和生存期统计见表4,详细的基线临床特征见补充数据2。图4展示了不同亚表型的总生存期(OS)Kaplan-Meier曲线,以及临床基线特征在亚表型间的关联和共现模式。
亚表型1(n=586,40.67%):平均OS最长(617天),女性比例最高(58.02%)。该类患者的转移发生率最低,电解质紊乱和心衰等合并症最少,肾功能异常值最少,用药水平也最低。
亚表型2(n=224,15.54%):女性比例为40.62%,平均OS为473天。其死亡风险在治疗开始后的前500天最低,随后在500-1000天期间随疾病进展而上升,趋势与开发集一致。肝转移率较低(5.80%),其他临床特征为中等水平。
亚表型3(n=631,43.79%):平均OS最短(307天),女性比例最低(32.81%)。该类患者的转移率、合并症负担和临床异常指标均为最高。
总体来看,验证集中得到的亚表型在生存期及临床特征上与开发集保持一致,说明所识别的亚表型具有良好的稳定性和可重复性。
亚表型预测特征分析
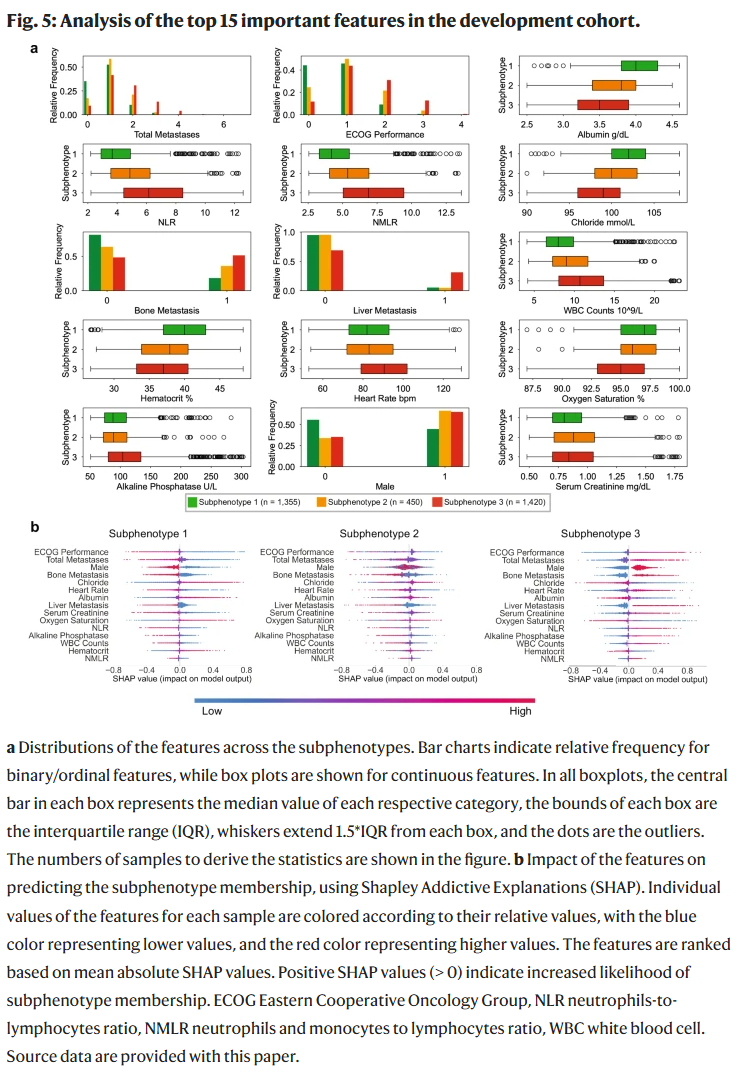
为进一步理解各亚表型的差异,研究人员在开发集中比较了各变量在不同亚表型之间的分布差异,并根据p值排序,选出前15个显著变量用于后续分析(见补充数据1)。图5a展示了这些变量在不同亚表型中的分布,图5b通过SHAP(Shapley加性解释)方法量化了这些变量对亚表型预测的贡献。
其中,ECOG体能状态评分(ECOG-PS)和转移部位总数是最具预测力的特征。
亚表型1中,90.2%的患者ECOG-PS<2,87.7%的患者转移部位少于2个;
亚表型3中,44.0%的患者ECOG-PS≥2,49.04%的患者转移部位≥2,且肝转移比例最高(31.20%);
亚表型2中,ECOG-PS为1的患者占比最高(50.1%),且以单一转移部位为主(58.6%)。
其他重要预测特征还包括实验室检查和生命体征指标:
中性粒细胞与淋巴细胞比值(NLR)及中性粒细胞和单核细胞与淋巴细胞比值(NMLR)可区分亚表型2;
亚表型1特征包括白蛋白正常、女性比例高、血细胞比容高和肌酐低;
亚表型3特征则表现为心率升高、血氧饱和度下降、碱性磷酸酶升高和白细胞计数增高。
这些结果揭示了各亚表型在临床特征和潜在生理状态上的系统性差异,有助于支持个体化治疗策略的制定。
讨论
本研究中,研究人员提出了一种通用的机器学习框架 GEMS,用于识别预测性亚表型,确保每类亚表型内患者在基线特征和生存结局上的一致性。该方法应用于一组接受一线免疫检查点抑制剂(ICI)治疗的晚期非小细胞肺癌(aNSCLC)患者EHR数据,并成功识别出三种用于预测总生存期(OS)的亚表型。这些亚表型在不同地理区域的开发集与验证集中均表现出一致的人口统计、临床特征与生存趋势,体现了其稳定性和可重复性。
亚表型1和亚表型3涵盖了研究中大部分患者,分别代表基线特征轻微和严重的两个群体。亚表型1患者比例为42%(开发集)与40.67%(验证集),女性比例最高,用药最少,转移和合并症发生率最低,临床检测异常最少,且拥有最长的OS。相反,亚表型3患者(44%;43.79%)以男性为主,具有最高的转移率、合并症比例和异常临床指标,生存期最短。亚表型2人数最少(14.40%;15.54%),其基线特征和生存期均处于中间水平。该类患者在治疗初期(前500天)死亡风险较低,但在后期(500-1000天)随疾病进展快速上升,呈现独特的动态变化。
研究人员进一步利用SHAP方法对亚表型预测特征进行了解释分析。关键特征包括ECOG体能状态评分(ECOG-PS)和转移部位数量,这与已有文献中对OS的影响一致。肝转移的出现也与更差的生存结果有关。中性粒细胞与淋巴细胞比值(NLR)和中性粒+单核细胞比值(NMLR)有助于区分亚表型2,NLR的中位数为4.87,落在已知的ICI疗效预警阈值区间。此外,亚表型2患者通常伴有较差的肾功能(如低白蛋白、高肌酐)、红细胞减少和相对正常的心肺功能(心率、血氧饱和度正常)。亚表型3中的碱性磷酸酶升高也被视为肝骨转移相关的潜在生物标志物。上述特征间的交互反映了更复杂的病理生理机制,例如轻中度肾功能不全与血细胞比容下降间的关联在男性中更为显著。这些特征模式在验证集中亦得到复现。
本研究的优势包括:
亚表型基于生存结果进行监督建模,确保组内一致性且组间具有明显区分;
队列划分明确,分别来自美国不同地区,增强了模型的泛化能力;
所识别的亚表型具备明确的临床意义,符合已有对aNSCLC的研究认知;
框架基于通用的特征向量表示与数据驱动的训练流程,具有良好的可拓展性,可应用于其他疾病研究中。
但研究亦存在一些局限性:
亚表型的形成基于特征与生存结果的相关性,不具备因果推断能力,未来可探索因果驱动的亚表型识别方法;
数据来源为回顾性EHR,无法揭示aNSCLC的生物机制;
当前仅利用结构化和部分整理后的非结构化数据,未充分挖掘如医嘱文本、影像报告等原始数据;
合并症信息基于诊断编码,可能存在漏报或误报;
肿瘤EHR中常存在药物使用、合并症和基因组信息的缺失,未来可通过与理赔数据整合来完善;
由于缺乏非ICI治疗患者数据,本研究仅聚焦于接受ICI治疗的群体,限制了适用范围;
所使用的特征主要为治疗前的最新检测值,未纳入纵向变化趋势,而原始数据中多数患者仅有一次记录,这一限制可通过其他包含更多时间点的数据集进一步探索。
综上,研究人员构建了一个用于识别临床结局预测性亚表型的机器学习框架,并在aNSCLC患者的真实世界数据中验证其有效性。所识别的三个亚表型具有可重复性和临床相关性,为理解治疗反应的异质性提供了新视角,并展示了该框架在多种疾病背景下的潜在应用价值。
整理 | WJM
参考资料
Pan, W., Hathi, D., Xu, Z. et al. Identification of predictive subphenotypes for clinical outcomes using real world data and machine learning. Nat Commun 16, 3797 (2025).
https://doi.org/10.1038/s41467-025-59092-8
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢