
2025年5月13日,中国科学院上海药物研究所郑明月团队在Nature Machine Intelligence杂志在线发表了题为“Bridging Chemistry and Artificial Intelligence by a Reaction Description Language”的研究论文,报道了一种名为ReactSeq的化学反应描述语言,该语言可以编码化学反应中的分子编辑操作,使自然语言处理(NLP)模型在逆合成预测、反应表征和检索、交互问答等方面表现得更为出色。

背景
以大语言模型(LLMs)为代表的人工智能技术,在自然语言处理方面取得了前所未有的突破,正在深刻影响科学研究的范式。在生命科学领域,语言模型(LMs)现已被用于挖掘蛋白质和基因序列中的隐含信息,并取得了显著成果。在化学与药物研发领域,处理化学分子与反应的“化学语言模型”(CLMs)也逐渐兴起。
与自然语言、蛋白质或基因不同,化学分子并不具备天然的序列型表示。CLMs依赖化学家定义的分子线性编码来学习和生成分子结构。目前最常用的分子线性编码是简化分子线性输入系统(SMILES)。近年来,为了提升CLMs在特定任务中的表现,研究人员也设计了一些新的分子线性编码语言,例如,SELFIES,t-SMILES,和PSMILES等。
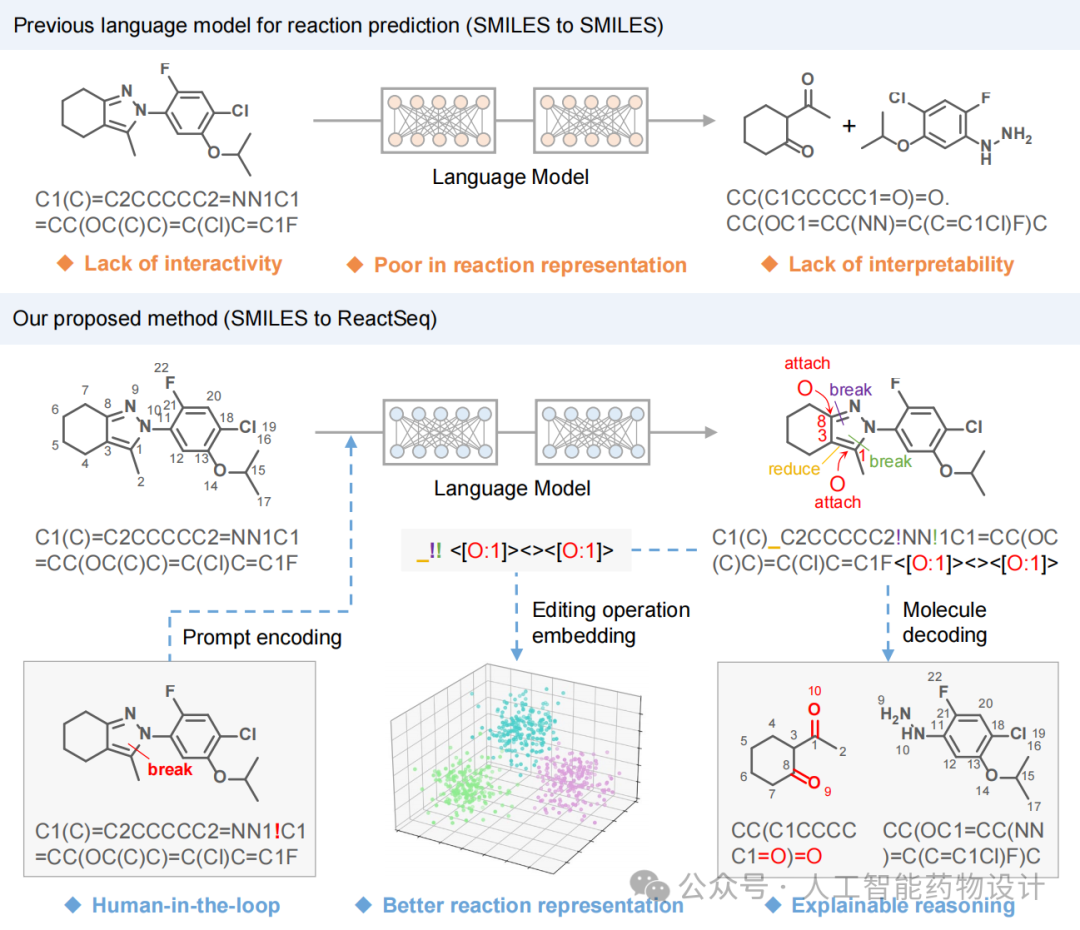
然而,这些分子线性编码语言均用于描述化学分子的静态结构,无法明确表达化学中原子与键的变化过程。这限制了语言模型在化学反应预测与表示中的应用。目前,用于化学反应预测的语言模型(包括正向合成与逆合成预测)通常直接将产物和反应物的线性表示相互转换,在可解释性与交互性方面存在不足(图1,顶部)。此外,尽管预训练语言模型在多种序列数据的表示学习方面已展现强大能力,但其在化学反应表示方面的进展仍相对有限。
因此,为推动语言模型在化学领域的应用,研究团队提出了一种名为ReactSeq的反应描述语言(图1,底部)。ReactSeq受逆合成分析过程的启发,定义了目标产物的结构及其转换为反应物所需的分子编辑操作(MEOs)。这些MEOs包括化学键的断裂与变化、原子电荷的改变以及离去基团(LGs)的添加等操作。在基于ReactSeq的逆合成语言模型中,反应物不是从零开始逐个生成,而是通过一系列MEOs由产物结构转化而来。这种方式确保了预测的反应物与产物之间具有精确的原子映射,从而提高了模型的可解释性。使用ReactSeq,即便是基础的Transformer模型也能在逆合成预测中达到领先水平。此外,ReactSeq中的MEO采用显式token表示,可支持人类专家通过提示词对模型进行引导和上下文提示(In-Context Prompting)。结果显示,专家提示显著提升了模型性能,甚至可引导探索新颖的化学反应。MEO token的嵌入表示还可作为通用、可靠的反应向量表示。这种自监督的表示能够自然地区分反应类型并评估其相似性,从而促进相似反应的检索、实验流程的推荐以及反应收率的预测。
结果与讨论
ReactSeq概述
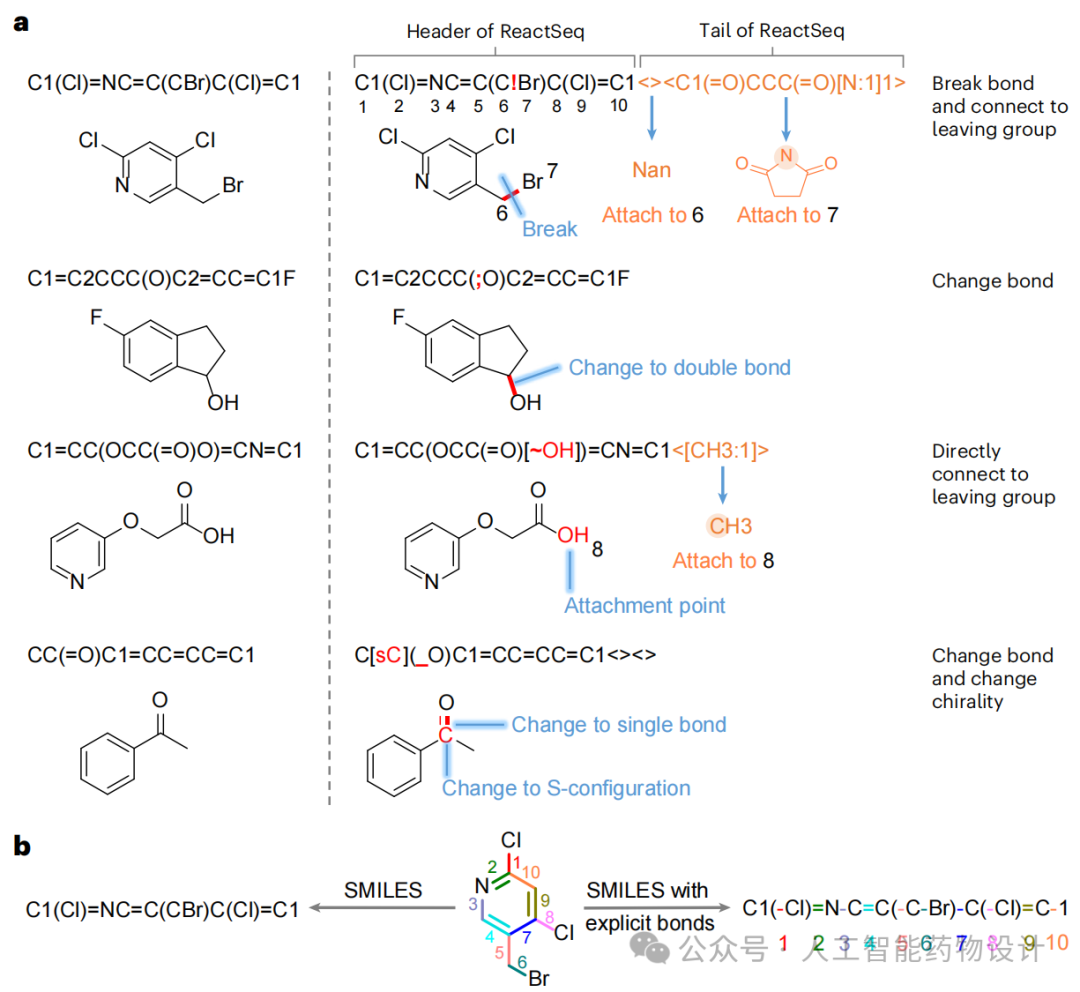
ReactSeq由两个部分组成:头部和尾部(图2a)。头部包含目标分子的结构以及其原子和化学键的变化信息,描述了如何将目标分子转化为相应的合成子(Synthons)。尾部包含离去基团(LGs)的结构及其与合成子的连接方式,描述了如何将合成子补全为反应物。在标准SMILES中,双键和三键的标记是可见的,而单键的标记是隐藏的。然而,通过使用Explicit Bond SMILES(图2b),这些隐藏的单键也可以被显式标记。通过用MEO token(如用感叹号“!”表示断裂一个键)替换SMILES中的键标记,得到了ReactSeq的头部,它记录了化学键的变化与断裂。在某些反应中,目标分子在逆合成过程中不涉及重原子之间的键断裂或变化,而是直接连接到LGs。对于这类情况,首先将原子标记转换为显式氢形式,例如将“O”变为“[OH]”,然后,为其添加对应的MEO token(“~”)。此外,ReactSeq中还定义了手性、电荷和顺反异构体的变化方式。
为了获得ReactSeq的尾部,首先识别目标分子中可能连接LGs的原子,即附着点,包括直接连接LGs的原子或涉及键断裂与还原的原子。每个附着点的LGs被包含在尖括号中,并根据其连接附着点的原子索引排序。通过这些步骤,可以获得一个标准的头到尾的ReactSeq,其与目标分子的SMILES高度对齐。
ReactSeq提升逆合成预测性能
为了展示ReactSeq的应用,研究团队首先将其用于逆合成预测,所用模型为未作任何修改的标准Transformer。表1展示了该方法与其他方法在USPTO-50k数据集上的全面比较。无论是否提供反应类型,基于ReactSeq的方法在所有情况下均优于其他方法。
该方法采用两阶段逆合成推理策略,首先识别反应中心,然后补全合成子,分别对应ReactSeq的头部和尾部部分。尽管许多基于图编辑的方法(如G2Gs、RetroXpert、GraphRetro)和序列方法RetroPrime也采用类似策略,但它们在Top-k(k ≥ 3)准确率上表现不佳。这可能是由于每个阶段采用了不同的模型,导致信息流中断,误差积累。相比之下,ReactSeq将两个阶段整合在一个序列中,使得模型可端到端顺序处理两个任务,从而实现了更高的top-k准确率。
研究团队还在更大规模的USPTO-MIT数据集上评估了该方法的性能,Top-1、Top-3、Top-5和Top-10的预测准确率分别为60.5%、78.5%、83.3%和87.6%,显示出该方法在大规模数据集上的良好适用性。此外,还在真实世界的反应数据集ELN上进行了外部评估,模型同样取得了先进的性能,进一步验证了其出色的泛化能力。

ReactSeq支持可解释的逆合成预测
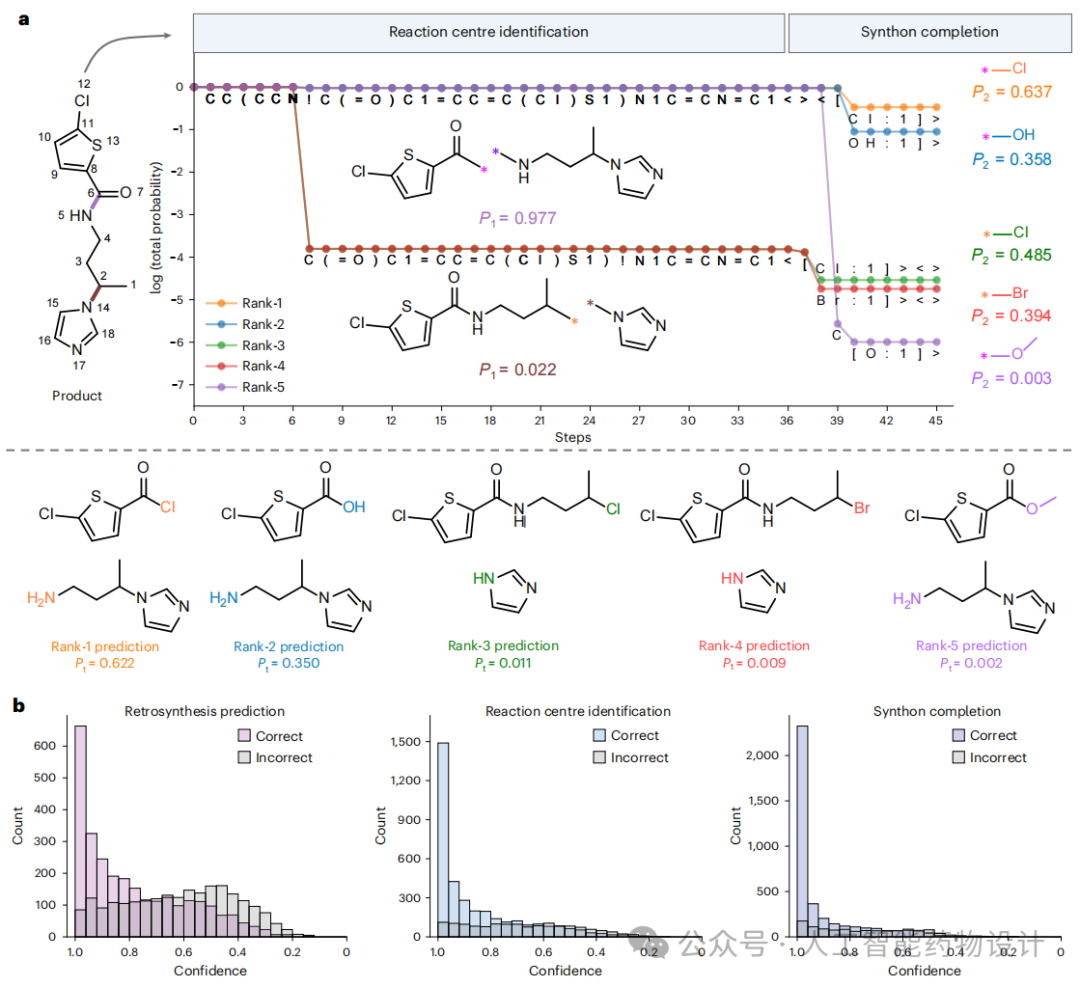
传统的序列逆合成方法直接将产物SMILES转换为反应物SMILES,未能描述从产物到反应物的具体转化过程。ReactSeq通过识别反应中心与补全合成子两个阶段解决了这一问题。
基于ReactSeq模型在反应中心识别中Top-1准确率为73.1%,在合成子补全中为77.6%,均显著优于现有方法。一些基于序列方法(如Retroformer)利用注意力权重指示反应中心并进行原子映射,但注意力机制提供的解释无法保证与模型实际执行的转化一致。相比之下,ReactSeq无需修改模型架构,即可使语言模型准确追踪整个反应过程中原子与键的变化,为可解释的逆合成预测提供了更简洁可靠的方案。
图3a展示了模型使用beam search生成ReactSeq的过程,总概率为各步预测概率的乘积。值得注意的是,总预测概率主要受MEO tokens影响,因为这些tokens表示产物分解与合成子补全的动态过程,而与静态结构相关的tokens预测概率较稳定。相比之下,基于SMILES的模型的总预测概率受多个token影响,显示出更复杂的决策过程。此外,ReactSeq的头部与尾部预测概率还能用于评估模型在每个阶段的预测置信度,随着模型置信度提升,预测准确率也明显提高(图3b)。
ReactSeq支持基于提示的反应预测
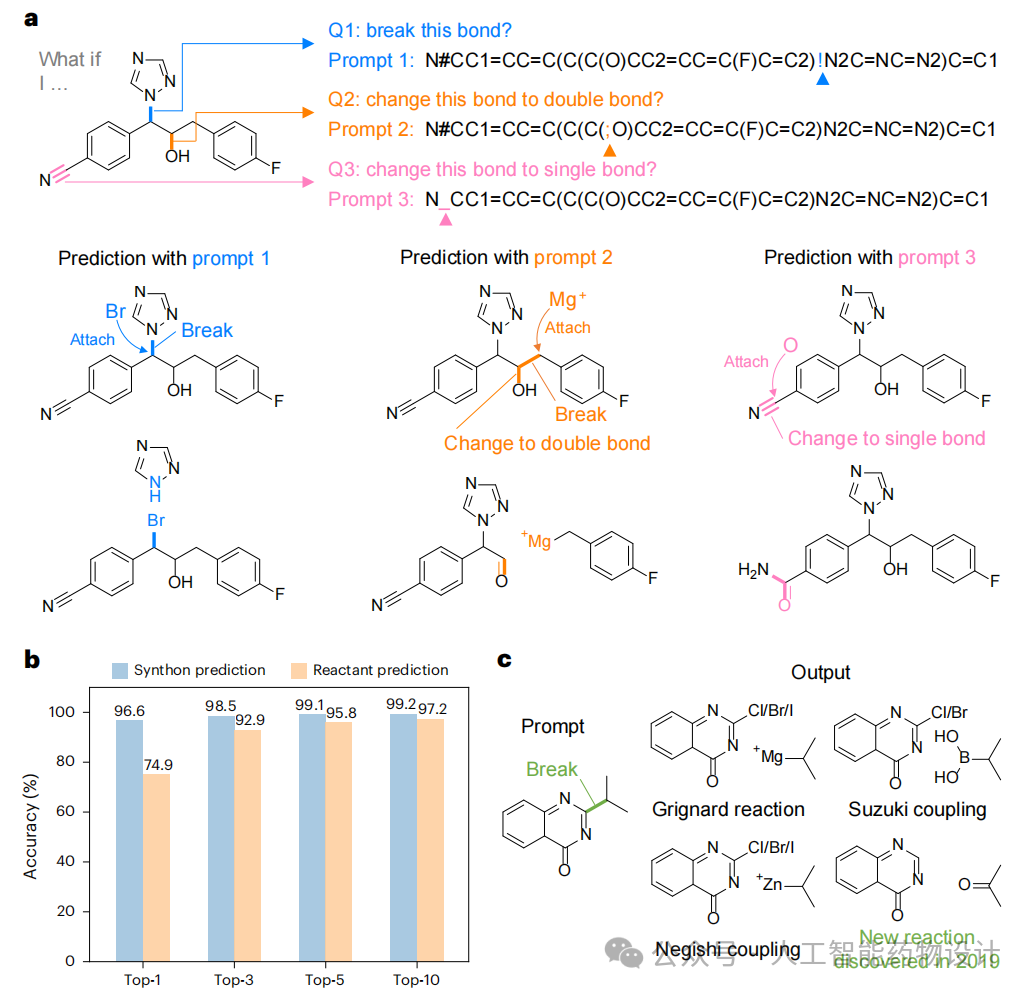
在人类专家进行逆合成分析时,通常拥有关于反应类型与位置的先验知识。通过提示词(prompts)注入这些专家知识往往能引导语言模型生成更准确的预测。此过程中关键挑战是如何用语言表达多样的人类提示。Thakkar等人曾通过在SMILES中标记原子实现提示,但其仅限于表示断键位置,未能编码其他提示类型。
而ReactSeq定义了多种MEO tokens,能够更全面、细致地表达人类提示。为此,研究团队使用ReactSeq训练了一个提示学习模型。如图4a所示,该模型能够处理ReactSeq编码的多种分子编辑提示,并被引导执行特定的反应转化。在USPTO-50k数据集上的实验中,提示学习策略在反应中心识别中达到了96.6%的Top-1准确率,在最终反应物预测中为74.9%,显著优于未使用提示的模型(图4b)。
在逆合成预测之外,ReactSeq在提示引导下还能更有效地探索特定化学反应空间,具有发现新反应的潜力。研究团队通过一项回顾性实验验证了这一点。2019年,Dong等人发现醛类与酮类可作为杂环C-H官能团化的反应物。研究团队对其论文中报道的产物进行了逆合成预测,并通过提示词标明断键位置。结果表明,模型不仅成功预测了Grignard反应、Negishi耦合、Suzuki耦合等常见C-C偶联反应,还在第10个候选中准确预测了醛类与杂环化合物的偶联反应(图4c)。
视频演示:ReactSeq 如何通过提示预测反应
(https://huggingface.co/spaces/Oopstom/ReactSeq)
ReactSeq 促进更优的化学反应表示
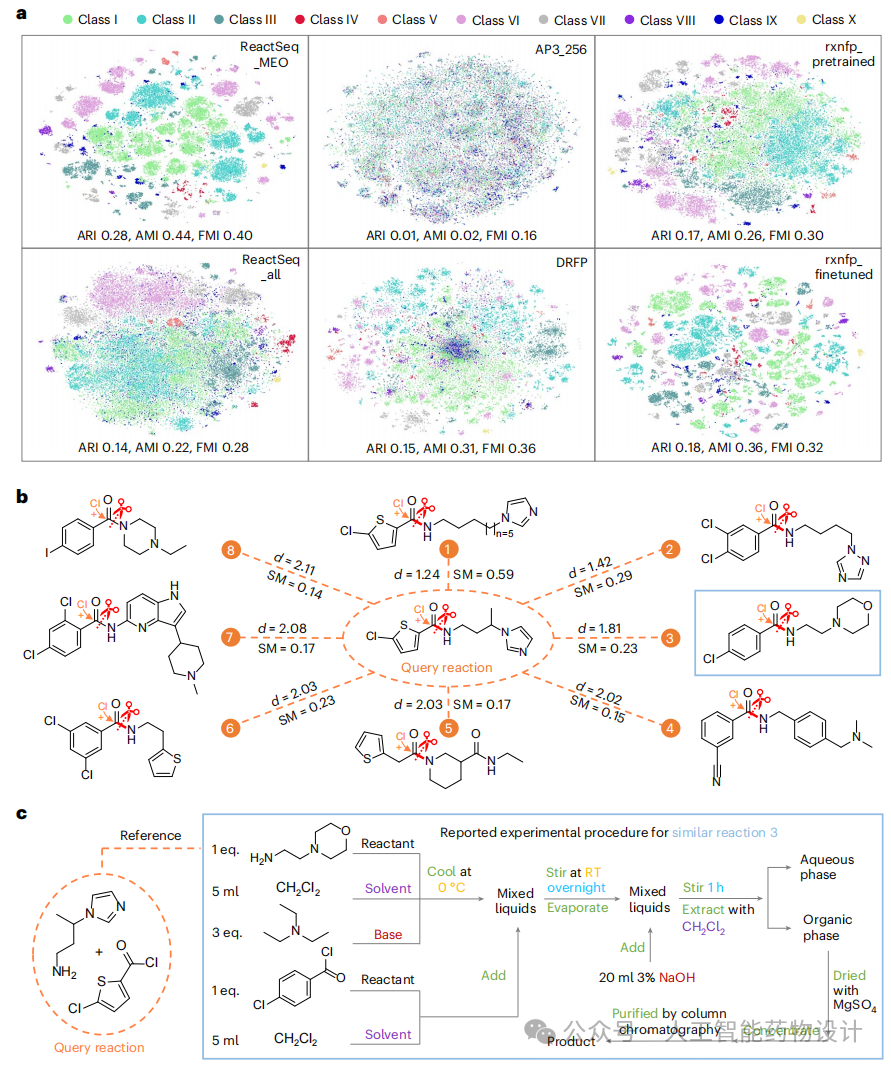
除了反应预测任务,研究团队还利用ReactSeq进行化学反应表示学习。具体而言,从逆合成模型中提取了ReactSeq中MEO tokens的嵌入,作为化学反应的表示(称为 ReactSeq_MEO)。图5a展示了基于t-SNE方法对USPTO-50k数据集中的化学反应表示的可视化结果。不同类型的反应在表示空间中被清晰地区分开来,同一类型的反应聚集在一起,并形成更小的子簇。值得注意的是,这些反应类型由人类专家进行分类,这表明该的模型通过对化学反应数据的自监督学习,获得了类似于人类专家的化学洞察力。
研究团队还尝试提取ReactSeq中所有token的嵌入(ReactSeq_all),而不仅限于MEO token。这种做法显著降低了模型性能,说明对于反应类型的表示而言,刻画原子和键的变化是至关重要的,而来自非MEO token的嵌入似乎引入了噪声,从而削弱了表示效果(见图5a)。
图5b展示了一个利用ReactSeq_MEO进行相似反应检索的例子。以图3中Rank-1的预测反应为查询,从训练集中检索出八个最相似的反应。它们全部与查询反应属于相同的类别。检索到的相似反应的实验流程可以为实现该查询反应提供借鉴。为了验证这一点,将该查询反应已报道的实验流程与相似反应1、2、3的实验流程进行了对比。相似反应1和2的实验流程与查询反应完全一致,说明它们可以直接复用。尽管相似反应3的实验流程与查询反应显著不同,但实验证明了其在实现查询反应方面是有效的(图5c)。这些结果验证了基于ReactSeq_MEO的反应表示方法在实验流程推荐方面的实际应用价值。
结论
本研究提出了ReactSeq,一种旨在促进语言模型在化学领域应用的反应描述语言。借助ReactSeq,即使是最基础的Transformer结构也能在逆合成预测中超越复杂的先进模型。同时,ReactSeq赋予了模型执行分子编辑操作(MEO)的能力,使其能够逐步将产物还原为反应物,而非从零生成反应物,从而提升了模型的可解释性。
ReactSeq的一大亮点是引入了显式的MEO token,这些token使得人类专家可以通过提示词介入预测过程,构建基于提示的反应预测模型。实验表明,借助人类提示,模型在逆合成预测中的性能显著提升,且展现出发现新反应的潜力。此外,这些token也有助于提取更高质量的反应表示。与聚合整个ReactSeq的表示不同,聚焦于MEO token的嵌入能够产生更真实、更内在的反应表示。结合这一策略与自监督学习机制,研究团队构建了一种通用且可靠的反应表示,广泛适用于反应分类、相似反应检索、反应产率预测和实验方案推荐等任务。
参考资料
Xiong, J., Zhang, W., Wang, Y. et al. Bridging chemistry and artificial intelligence by a reaction description language. Nat Mach Intell, 2025.
https://doi.org/10.1038/s42256-025-01032-8 (点击下方阅读原文跳转)

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢