
感染性休克(又称脓毒性休克)是指由脓毒症引发的严重循环障碍和细胞代谢紊乱的综合征,在临床表现上可以视为脓毒症发展的「终末阶段」。感染性休克具有极高的病死率,也是目前重症监护病房最致命的疾病之一。根据一项基于英国国家级重症监护数据库的研究报告显示,感染性休克患者的住院死亡率可高达 55.5% 。
面对这一高致死率的进展性疾病,临床中针对感染性休克强调「时间就是生命」,提倡早发现、早干预、早治疗,从而来降低病死率。然而,由于感染性休克患者病情复杂,临床医学数据稀少,导致针对感染性休克患者病情进展的早期预警变得十分困难,这也是有效干预脓毒症向感染性休克恶化的关键瓶颈。
目前,随着重症医学信息化程度加深,人工智能与重症医学的交叉融合已经让脓毒症早期预警不再困难,但针对感染性休克的研究却迟滞不前。这是因为多数研究样本数量稀少,依赖于单一的机器学习算法,同时又未能通过多中心验证,导致它们迟迟难以推广至感染性休克患者早期风险预测的临床实践当中。
有鉴于此,华中科技大学同济医学院附属同济医院叶庆教授、医药卫生管理学院吴红教授团队,开创性地提出了一个基于 TOPSIS(Technique for Order Preference by Similarity to an Ideal Solution)的分类融合(TCF)模型,用于预测 ICU 中感染性休克患者 28 天内的死亡风险。该模型整合了 7 种机器学习模型,在跨专业、多中心验证中具有较高的稳定性和准确性,为临床医生提供了一个值得信赖的感染性休克死亡风险早期预警的辅助工具。
研究成果以「Artificial intelligence based multispecialty mortality prediction models for septic shock in a multicenter retrospective study」为题,发表于 Nature 子刊 npj digital medicine 。
研究亮点:
* 研究采用高效的融合策略,构建了一个基于多基本分类模型的高泛化能力和鲁棒性的融合模型,克服了小样本队列和单一分类模型在临床场景中性能不佳的问题
* 研究成果突破了感染性休克早期死亡风险预测难的问题,为临床医生提供了一个高效、稳定、可靠的临床决策工具,有助于医生更早地密切监测患者的病情进展,并采取更积极的治疗措施

论文地址:
https://go.hyper.ai/faMLL
开源项目「awesome-ai4s」汇集了百余篇 AI4S 论文解读,并提供海量数据集与工具:
https://github.com/hyperai/awesome-ai4s
数据集:广泛数据,精确处理
为了构建具有广泛适用性的感染性休克预测模型,研究团队整合了 3 家医院自 2003 年 2 月到 2023 年 11 月间,共计 4,872 名 ICU 感染性休克患者的临床数据,其参与者背景复杂多样,有助于研究团队开展多中心、跨专科验证,以证明模型的有效性和适用性。如下图所示:
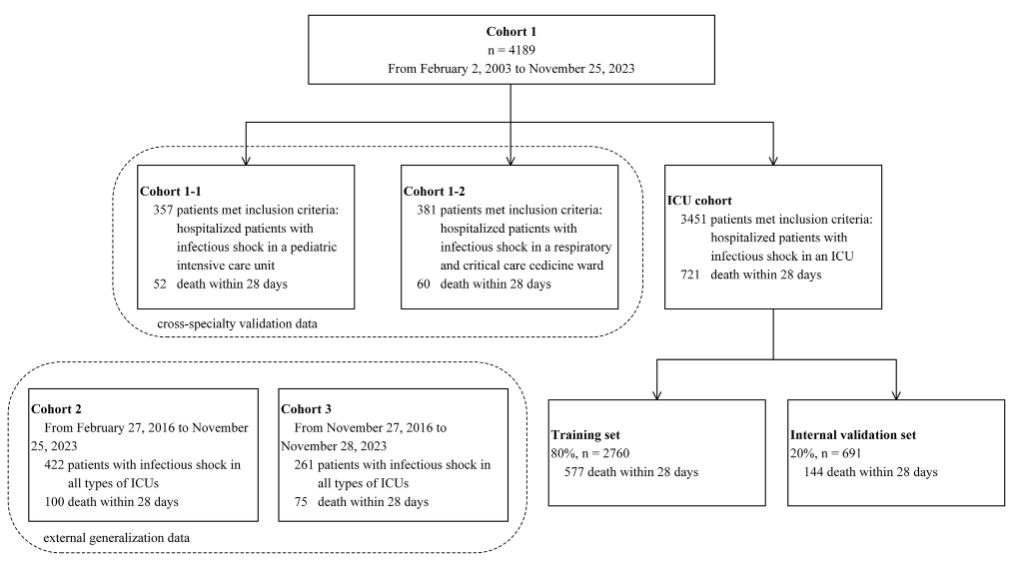
具体来说,cohort 1 共计包含了 4,189 名参与者,其中普通 ICU 患者 3,451 名(721 名阳性,2,730 名阴性);儿科 ICU 患者(cohort 1-1)有 357 名(52 名阳性);呼吸 ICU 患者(cohort 1-2)有 381 名(60 名阳性)。
* 阳性结果为在 ICU 住院 28 天内经历全因死亡的参与者,未经历全因死亡的参与者被标记为阴性结果(下同)
其中,普通 ICU 患者数据集作为主要研究人群并用于模型构建和内部验证,训练数据和验证数据按照 8:2 划分,分别为 2,760 名(577 名阳性)和 691 名(144 名阳性)。儿科 ICU 患者和呼吸 ICU 患者数据集则进一步评估了模型在不同专科重症监护病房的适用性和稳定性。
cohort 2 和 cohort 3 包含了不同 ICU 的感染性休克患者,分别有 422 名参与者(100 名阳性,322 名阴性)和 261 名参与者(75 名阳性,186 名阴性)。这两部分数据集主要用于进行外部验证,以评估其在不同中心的泛化能力和有效性。
另外,为了精确实验结果,研究团队提取了 93 项常规的临床特征,包括人口统计学信息、疾病及治疗史、生命体征信息等,最终优化到 34 项用于实验。
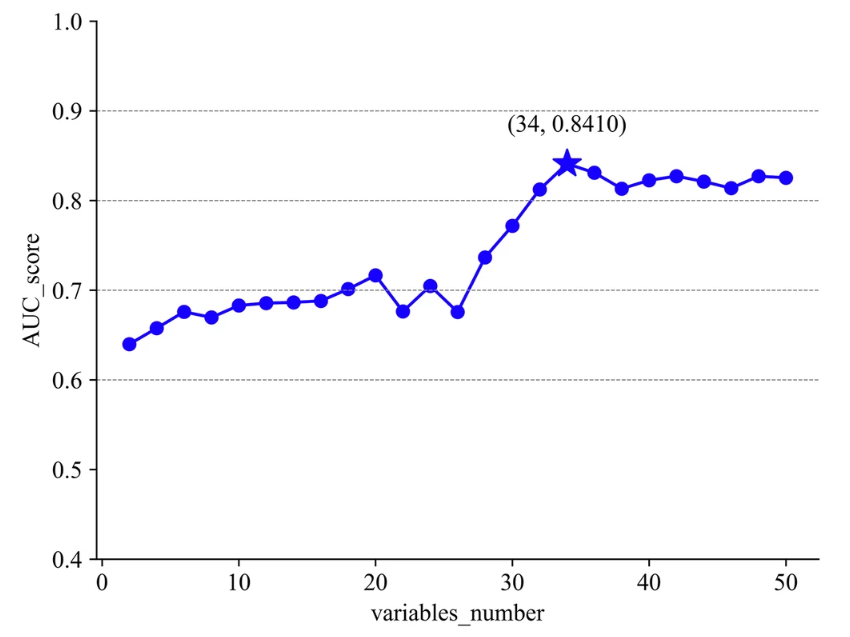
具体来看,数据预处理共包含 5 个部分:第一步,研究团队首先通过缺失率计算,删除了缺失率高于 30% 的 23 项变量;第二步,根据伯努利方差公式(Bernoulli’s variance formula)计算布尔特征(Boolean Features)的方差,再次移除一致性超 90% 的离散随机变量;第三步,通过缺失值插值方法(Logistic 回归多重插补)进一步优化至 61 项变量;第四步,再次进行高相关性特征筛选(Pearson 相关系数 ≥0.7),此时还剩 50 个变量。如下图所示:
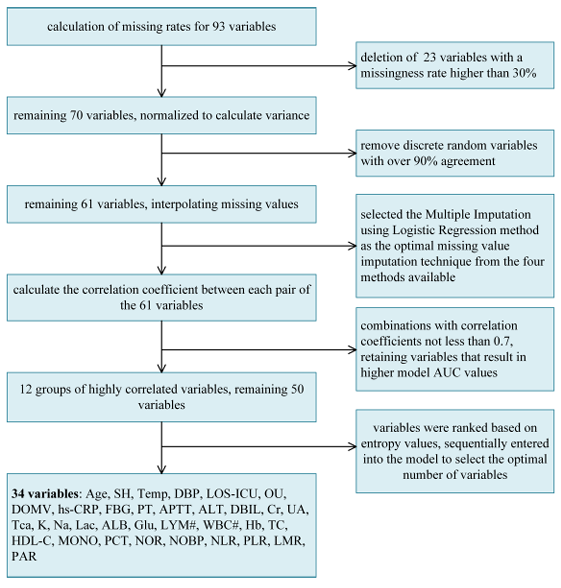
第五步,研究人员根据信息熵排序(由高到低),最终选择出了用于实验的 34 项关键变量,包含了年龄、手术史、体温、舒张压等重要因素。
需要说明的是,为了保护参与者隐私,所有数据在分析之前已做了去标识化处理。
模型架构:融合模型,精准预测
TCF 模型的研究主要分为 3 个步骤:第一步是利用感染性休克患者的住院数据建立 7 个子模型, 每个子模型产生 6 个评估指标的结果;第二步基于融合策略,将子模型整合为一个融合模型,并验证该模型优于其他模型;第三步涉及跨各种数据集测试以验证模型的性能,并对模型进行可解释性分析(实验结果部分说明)。
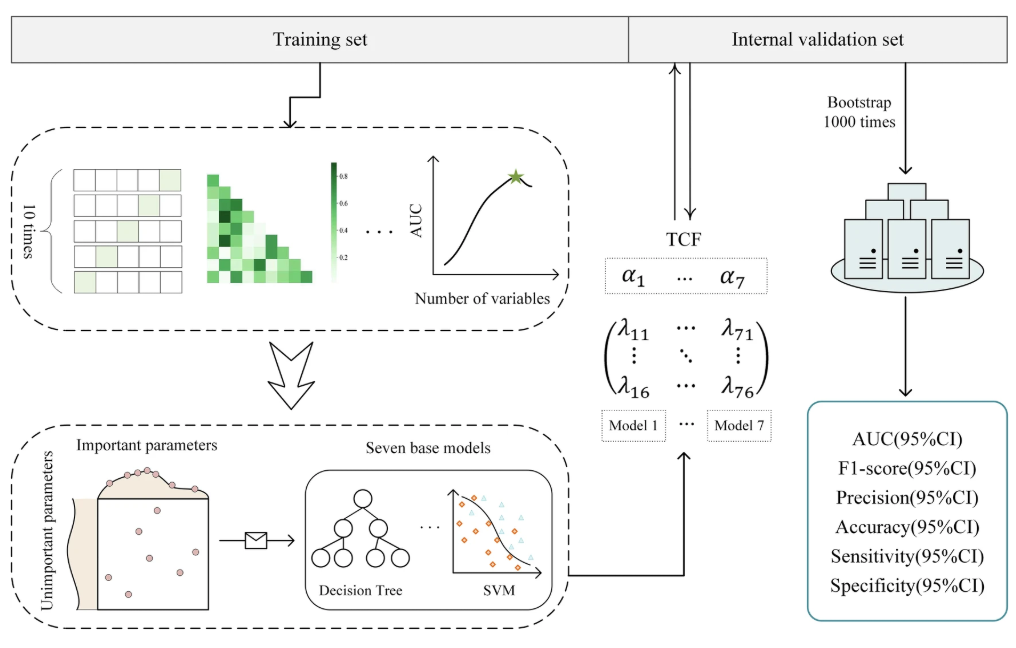
具体来看,第一步,研究团队首先使用经过特征处理后普通 ICU 数据集训练并测试 7 个子模型,根据 1:1 规则对训练集应用 Synthetic Minority Over-sampling Technique(SMOTE),以减轻类不平衡的负面影响,之后经过最小-最大归一化后,通过五重交叉验证和随机搜索确定最优参数组合,并在训练集上训练 7 个子模型,分别是 Decision Tree(DT),Random Forest(RF),XGBoost(XGB),LightGBM(LGBM),Naive Bayes(NB),Support Vector Machine(SVM)和 Gradient Boosted Decision Tree(GBDT)。
最后,研究团队又使用内部验证数据对测试结果进行验证,并通过 6 个评估指标对模型的性能进行评估,分别为 area under ROC curve(AUC),F1-score,precision(PRE),accuracy(ACC),sensitivity(SEN)和 specificity(SPE)。
第二步,研究团队整合了这 7 个各有优缺点的子模型,设计了一个基于 TOPSIS 的分类融合模型 TCF,将 7 个模型的评估结果结合起来,为感染性休克的诊断提供一个综合的预测结果。子模型的权重由 TOPSIS-score 计算,加权后的预测概率即为 TCF 的预测概率,以 0.5 为临界值推导出 TCF 的分类结果。
具体 TCF 模型的融合算法如下:
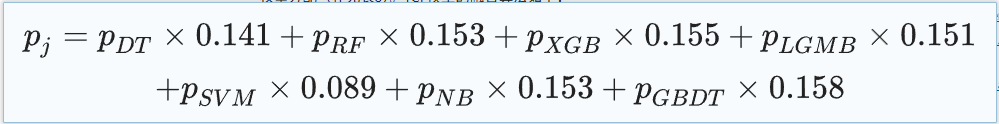
统计分析方面,对于连续特征,给出中位数、上四分位数和下四分位数的统计数据;对于离散特征,报告每个类别的比例。在本次研究中,最小的数据集是队列 3,根据中心极限定理,连续特征的均值分布可以认为是正态分布。
然后,研究采用 Levene 检验来确定两组数据之间特征的同质性,采用 Chi-square 检验比较其他数据与内部验证集的离散特征差异,连续特征差异采用独立样本 t-test 检验或 Welch’s t-test 检验,使用 1,000 个 bootstrap 样本计算评估指标的 95% 置信区间。
为了更深入理解模型的推理过程,研究团队还通过绘制 SHAP 特征重要性热图将其特征重要性进行可视化处理。以 AUC 性能最好的 GBDT 模型为例,如下图所示:
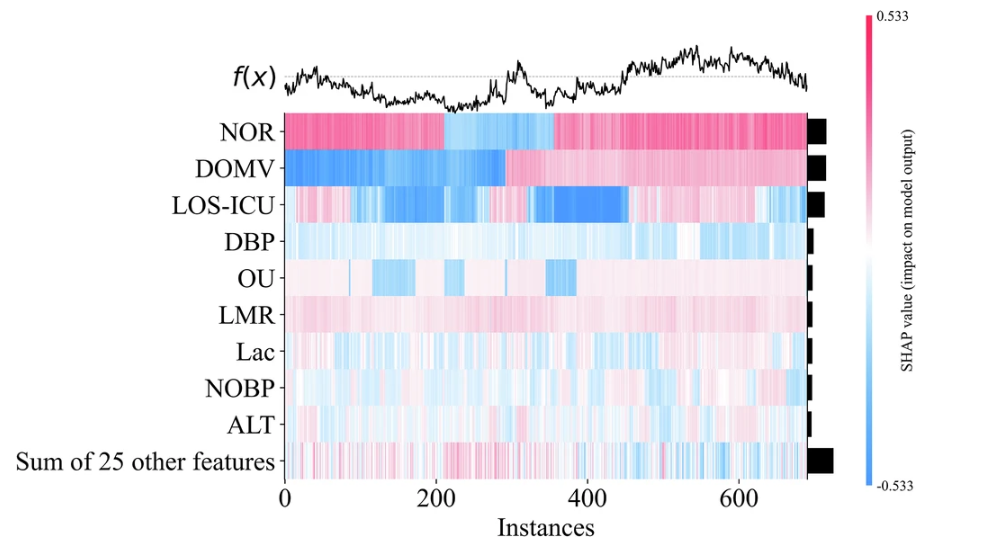
特征重要性排序不仅可以提高临床预测模型的透明度和可信度,还能为医疗实践提供有价值的参考。如此一来,模型即满足了医生对模型透明度的需求,同时也量化了临床净收益,实现了临床可解释性与实用性并重,为模型在临床实践中得到应用奠定了基础。
实验结果:多维验证,可靠易用
为了验证融合模型(TCF)的性能,研究团队首先将其与子模型进行了比较,结果如下图所示:
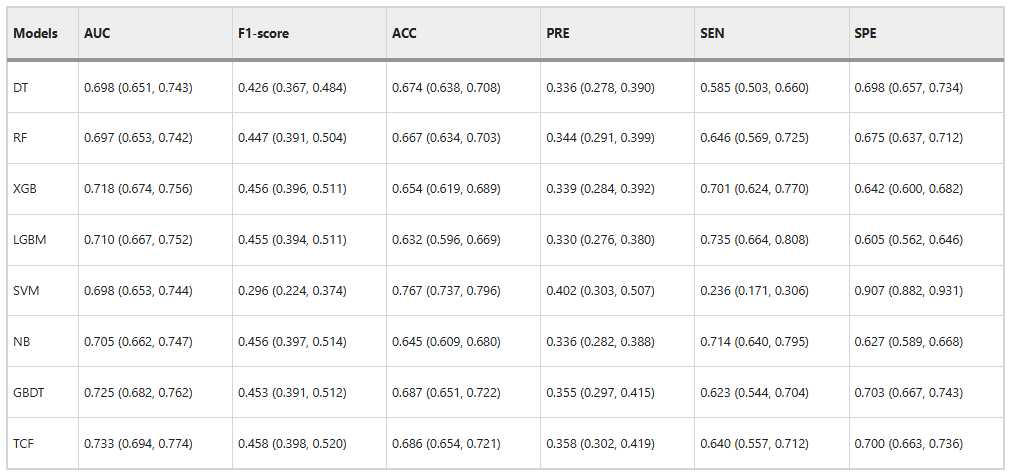
TCF 在内部验证集上的 2 个综合评价指标上均优于子模型,AUC 为 0.733,F1-score 为 0.458 。此外,ACC 为 0.686 和 PRE 为 0.358 也高于多数子模型。这显示出其具有出色的分类能力。
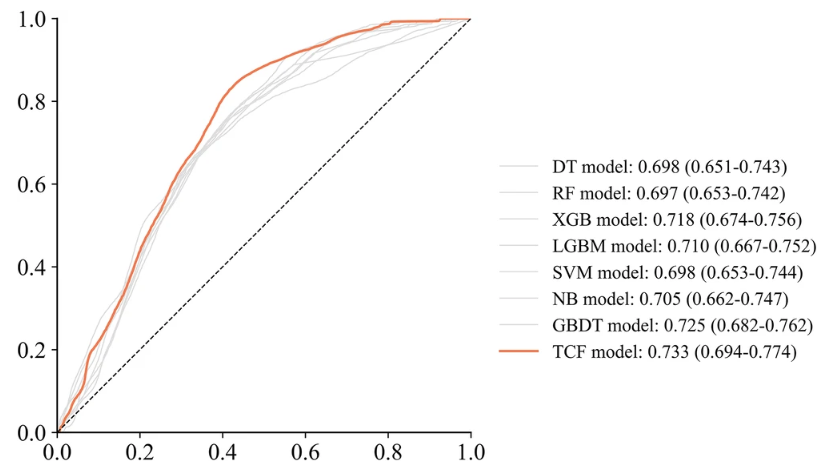
虽然 TCF 模型在 SEN 和 SPE 上的得分都没有达到最佳性能,分别是 0.640 和 0.700,但它可以通过整个子模型的偏差识别效果,从而获得最佳的整体性能。如下图所示。
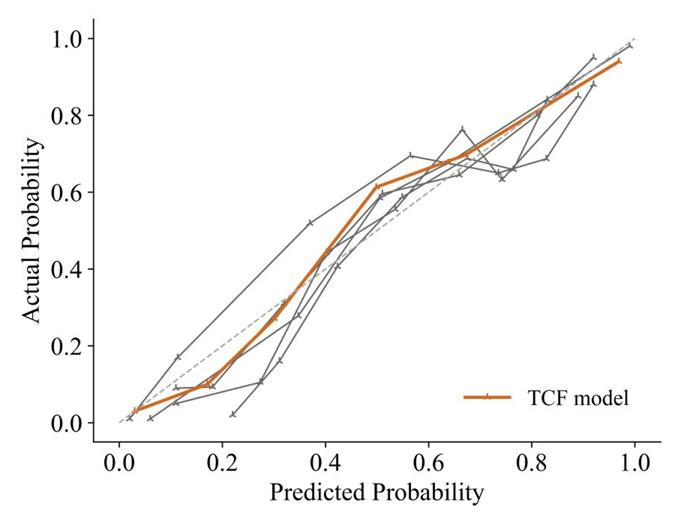
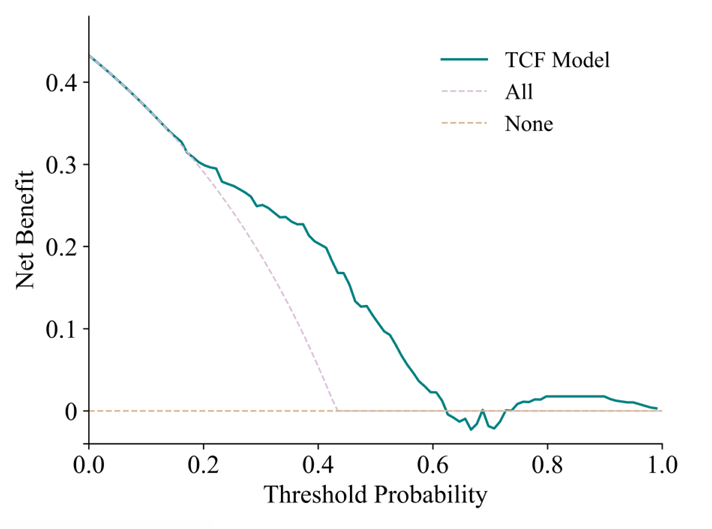
校准曲线和 Decision Curve Analysis(DCA)曲线表明了 TCF 模型的预测结果与实际结果一致。首先,TCF 模型的校准曲线最接近对角线,这表明它在所有模型中具有最佳的校准性能;其次,TCF 模型的曲线在大多数阈值概率下始终优于「All」和「None」策略,尤其在 0.1 到 0.5 的概率范围内展现出更高的净收益。这表明 TCF 模型在一定范围内具有潜在的临床应用价值,可以帮助临床医生做出更有利的决策。
随后研究团队进行了多中心验证,该验证可以更准确地展示 TCF 模型的预测性能,以及不同数据集之间存在的异质性。如下图所示:
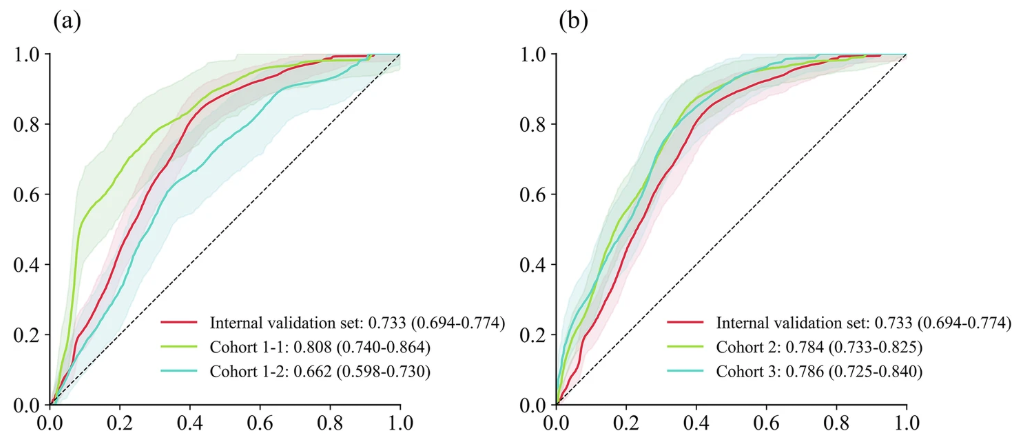
可见,与大多数研究中多中心预测效果略低于训练集和内部验证集的预测效果不同,在本次研究中,除 cohort 1-2(呼吸 ICU 患者数据集)的 AUC(0.662)略有下降外,cohort 1-1(儿科 ICU 患者数据集)、 cohort 2 和 cohort 3 的 AUC 均有改善,分别为 0.808 、 0.784 和 0.786 。
另外,由于多中心样本数量有限,研究团队特别结合 4 个外部验证数据集进行预测(1,421 例患者数据,含 287 例阳性),其 AUC 为 0.7705,这表明了 TCF 模型能够有效区分感染性休克低危险因素的患者,具有良好的校准能力。
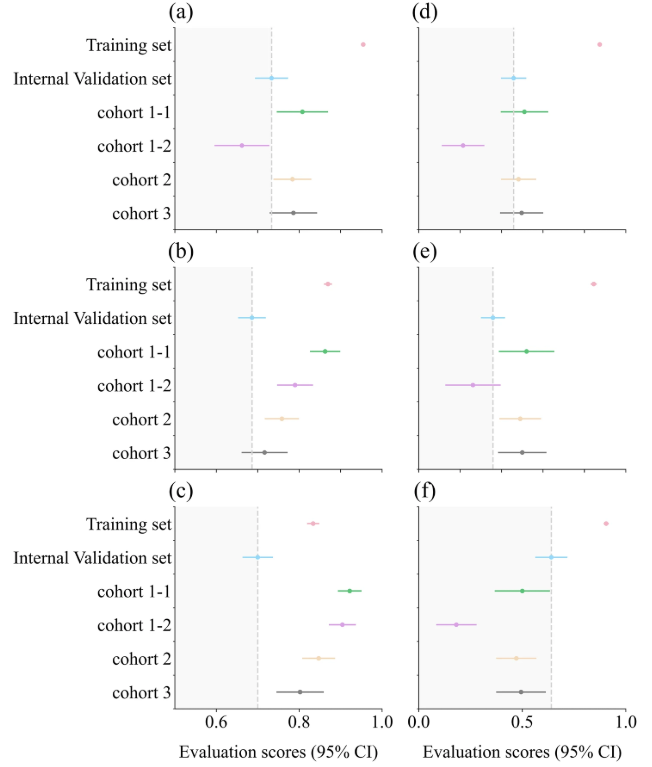
其中,a 为 AUC 箱线图;b 为 ACC 箱线图;c 为 SPE 箱线图;d 为 F1-score 箱线图;e 为 PRE 箱线图;f 为 SEN 箱线图。灰色虚线表示内部验证集的结果,其他数据集的评估分数落在深灰色区域内,表明与内部验证集相比性能下降。
总而言之,TCF 模型在内部数据集和外部验证集上均取得了一致且良好的性能, 在预测感染性休克患者 28 天内死亡风险方面显示出优于单个模型的表现。该模型为 ICU 临床医生提供了一个可靠且易用的预测工具,尤其在患者病情恶化的关键早期,可以有效帮助医生针对不同患者提供有效、个性化的治疗干预,改善患者预后。
人工智能在脓毒症/感染性休克治疗中大展身手
随着科技的不断发展,人工智能与重症医学的交叉融合早已成为相关研究人员高度关注的领域,本次研究无疑是其中具有开创性价值的一次探索。正如前文提到,脓毒症/感染性休克作为一种具有高死亡率和发病率的全球性公共卫生危机,亟需通过早期发现和干预来提高患者的生存率。
在过去,针对脓毒症早期预警模型的研究早已花开蒂落,不少实验室都提出了相关研究成果。
比如美国杜克大学 Armando D Bedoya 等人发表的题为「Machine learning for early detection of sepsis: an internal and temporal validation study」的研究,其中介绍并验证了一种基于深度学习(多输出高斯过程和递归神经网络)的预测模型 MGP-RNN,在与包括 random forest 、 Cox regression 和 penalized logistic regression 在内的 3 种机器学习方法,以及 3 种临床评分的比较中,该模型在各项指标上均优于其他模型和临床评分,可提前 5 小时检测脓毒症。
论文地址:
https://pmc.ncbi.nlm.nih.gov/articles/PMC7382639
除此之外,美国加利福尼亚州一家名为 Dascena 公司的团队也在一篇研究中给出他们的见解,他们采用回顾性研究方法,使用 MIMIC II 临床数据库中 32,000 名患者的数据,通过 9 种常见生命体征测量之间的相关系,开发了一种名为 InSight 的脓毒症早期预警算法。结果显示,该算法在持续 Systemic Inflammatory Response Syndrome(SIRS)发作前 3 小时预测脓毒症的灵敏度达到 0.90,特异性为 0.81,表现超过了现有生物标志物检测方法。研究以「A computational approach to early sepsis detection」为题发表。
论文地址:
https://www.sciencedirect.com/science/article/abs/pii/S0010482516301123?via%3Dihub
人工智能与重症医学的融合让脓毒症的早期预警不再困难,而本次研究无疑是填补了脓毒症发展到危重阶段无法及时预警的空白,是一次更具医学价值的探索。当然,更重要的是本次研究所提到的融合性策略,通过平衡子模型的灵敏度和特异性优势,从而提升整个模型的综合性能,这为后续通过多模型集成解决相关问题铺垫了道路,启发了更多研究通过类似方法解决医疗场景中的实际困难。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢