
DRUGAI
大型语言模型(LLMs)因其处理人类语言和执行非特定训练任务的能力而备受关注。然而,研究人员对其化学能力尚缺乏系统性了解,这对于模型优化与风险控制至关重要。本研究提出了ChemBench——一个用于评估先进LLMs在化学知识和推理能力方面与化学专家对比的自动化框架。研究人员整理了2700余组问答对,评估了多种主流开源与闭源模型,发现表现最优的模型在平均水平上超越了参与研究的顶尖人类化学家。然而,这些模型在部分基础任务上仍存在困难,并易出现过度自信的预测。研究结果展示了LLMs在化学领域的显著潜力,同时突出了提升其安全性与实用性的必要性,也为化学教育改革和领域专属基准测试框架的价值提供了参考。

大型语言模型(LLMs)是一类基于海量文本训练的机器学习模型,能够生成连贯句子。随着模型规模不断扩大,其能力迅速提升,已能通过医学或其他专业考试,甚至在接入网络搜索与合成工具后,实现化学反应的设计与执行。一些观点认为其展现出“通用人工智能”的潜力,也有批评认为它们只是“概率鹦鹉”,只能复述训练内容,存在固有局限。尽管如此,研究人员仍看到其在未明确训练任务上的泛化能力。
化学与材料科学领域迅速关注这一趋势,有人甚至提出“化学的未来是语言”。研究人员已开始利用LLMs进行性质预测、反应优化、材料生成、信息提取,甚至构建可自然语言控制的自动化实验系统。
由于化学知识大多以文本形式储存和交流,研究人员认为LLMs在该领域仍具巨大潜力。许多化学洞见来源于研究人员对数据的解释,而非数据库本身,因此基于文本的理解和推理或许是获取这些知识的最佳途径,未来甚至可能催生能协助回答问题或设计实验的化学助手系统。
然而,化学机器学习模型能力的迅速提升,也引发了关于其双重用途的担忧,例如被用于设计有害物质。这类技术本质上既可用于筛选无毒分子,也可反向识别有毒分子。更需注意的是,LLMs的用户群远超专业人士,学生或公众也可能用其获取实验建议或安全信息,若模型输出错误内容,可能带来安全隐患。
即便对专家而言,了解模型在化学知识与推理方面的能力也至关重要。目前,尽管已有部分尝试通过提问来测试LLMs在科学领域的表现,但缺乏系统性评估其与人类专家的差异。
为深入了解LLMs在化学科学中的表现与改进空间,研究人员需要标准化评估框架。目前通用评估体系如BigBench等在化学任务覆盖极少,化学语言模型开发者通常依赖结构化数据集评估分子属性预测任务,难以全面反映模型的通用化学能力。
部分基于考试题或自动文本挖掘的方法虽被提出,但因难以应用于黑箱系统、话题覆盖有限或缺乏专家验证,未被广泛接受。现有基准也难评估模型在处理分子或化学表达式方面的特殊能力,更无法与人类专家进行直接对比。
为此,研究人员构建了ChemBench,一个评估LLMs在化学科学中能力的基准框架。该基准包含2788个多来源问答对,涵盖本科及研究生阶段的广泛主题,能够测试模型的知识、推理与直觉水平,并支持评估包括外部工具增强系统在内的各类文本输出模型。

结果与讨论
基准数据集设计
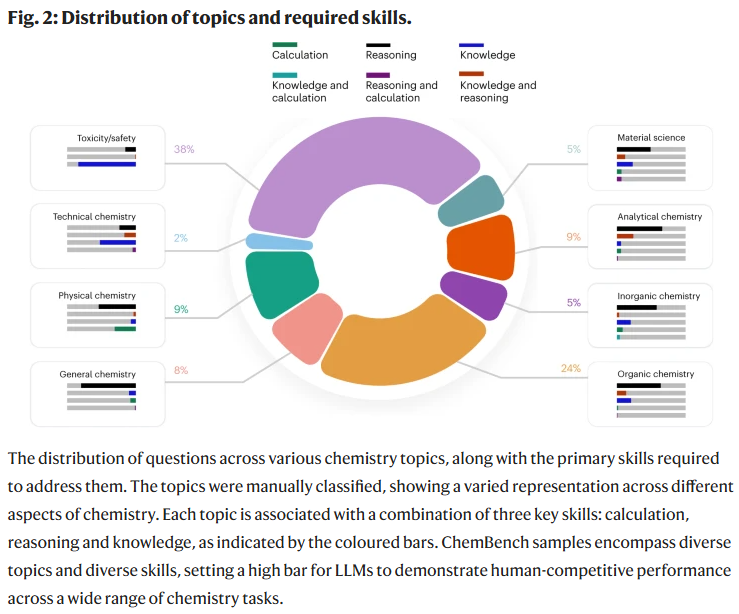
研究人员从多种来源(包括教材、大学考试、化学数据库等)收集并构建了一个包含2,700多个问答对的化学基准数据集 ChemBench,涵盖一般化学、无机、分析与技术化学等多个领域,并按所需技能(知识、推理、计算、直觉等)及难度进行分类。与多数现有以选择题为主的基准不同,ChemBench同时包含2,544道选择题与244道开放题,以更真实地反映化学教育和研究情境。
为便于常规评估,研究人员还构建了一个包含236题的代表性子集 ChemBench-Mini,该子集由19位化学专家完成答题,并在某些情况下允许使用工具如网页搜索,以模拟真实任务环境。
模型评估框架与表现
由于科学文本的专业性,ChemBench支持对分子结构(如SMILES)、单位和公式等元素进行语义标注与特殊处理,使模型更有效地理解输入内容。考虑到许多LLMs仅开放文本生成接口,ChemBench基于最终生成结果进行评估,以适应实际应用中的模型使用方式。
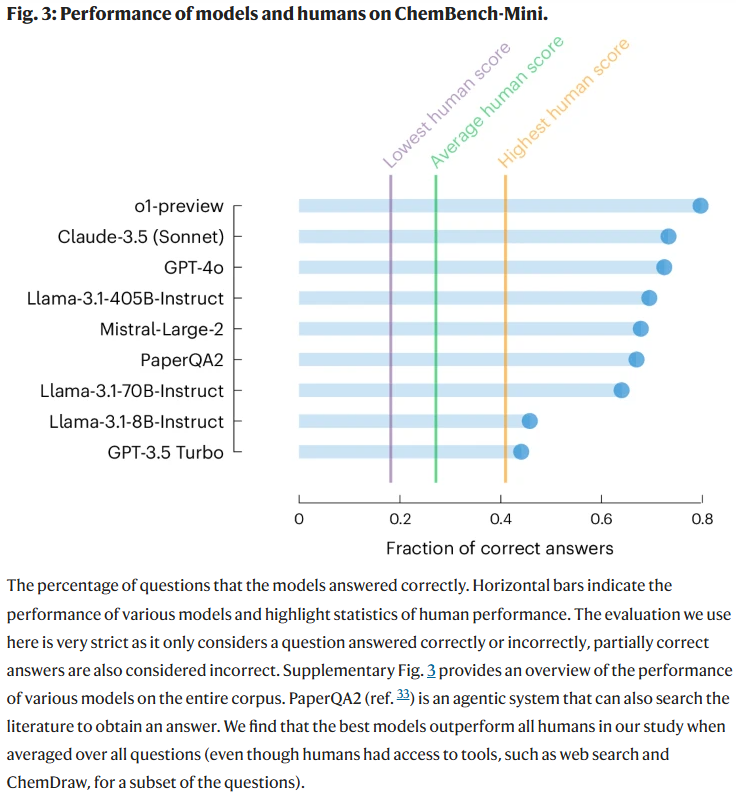
研究人员评估了多种主流大语言模型(包括开源与闭源系统),发现部分模型(如o1-preview)整体正确率甚至是研究中最优秀化学家的两倍,许多模型也超过人类平均水平。值得注意的是,模型在处理需大量知识积累的问题时仍表现欠佳,表明当前的检索增强生成方法(如PaperQA2)在获取专业数据库信息方面存在局限。
此外,模型表现与其参数规模呈正相关,说明通过扩展模型仍有提升空间。
各化学子领域表现
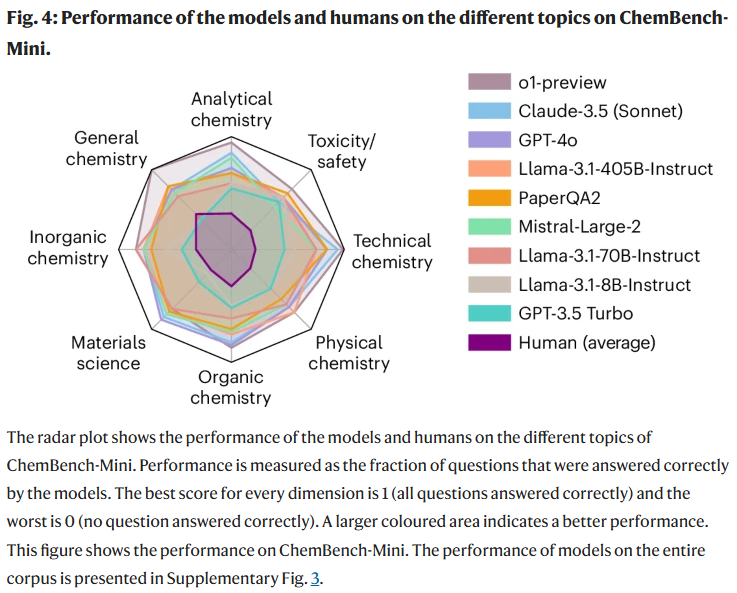
将问题按子领域划分后发现,不同模型在不同主题上的表现差异较大。通用与技术化学得分较高,但毒理安全和分析化学相对较低。例如在核磁共振信号预测任务中,即使是最强模型的正确率也仅为22%。分析还表明,模型对结构推理的依赖程度较低,更多是基于训练集中分子的相似性作答。
值得关注的是,尽管模型在一些基础考试题上表现良好(如德国化学限制法规题中GPT-4得分达71%,远超人类的3%),但这类表现并不代表其能胜任更复杂或开放性的任务,反映出教材类测试对模型评价的局限。
结构复杂度与模型推理
进一步分析显示,模型在结构复杂度更高的分子上并未表现更差,说明它们并未真正具备基于结构进行推理的能力,而是可能依赖于记忆或训练数据的近似。
安全机制影响与可拓展性
模型API中的安全策略也可能限制某些答案的生成(如关于氰化物的问答),当前评估中对此类限制有所低估。研究人员正尝试与模型开发者合作,拓展ChemBench以支持更全面的开放科学评估。
化学偏好判断能力
研究人员还测试了模型在化学偏好判断(如分子筛选中的选择)方面的能力。结果显示,尽管人类专家之间一致性较好,模型的判断几乎随机,表明未来有必要探索偏好对齐等微调方法在化学领域的应用潜力。
置信度评估能力
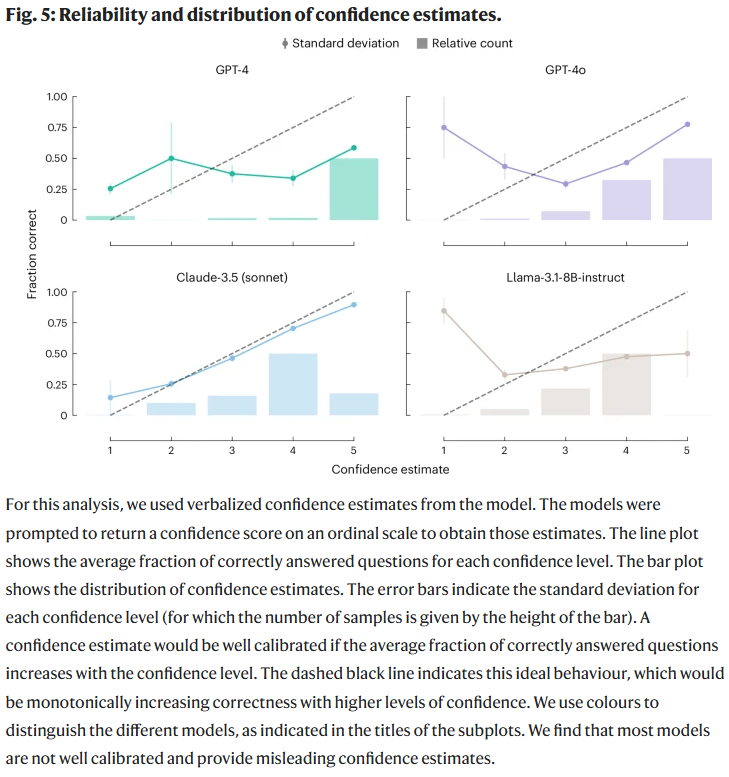
研究人员分析了模型对自身回答准确性的信心水平。结果表明,部分模型在高置信度下依然错误频出,未能提供可靠的自我评估。例如GPT-4对错误答案的信心甚至高于其正确答案,表明当前模型缺乏有效的置信度校准机制,需进一步改进以满足高风险化学任务中的可解释性与安全性需求。
整理 | WJM
参考资料
Mirza, A., Alampara, N., Kunchapu, S. et al. A framework for evaluating the chemical knowledge and reasoning abilities of large language models against the expertise of chemists. Nat. Chem. (2025).
https://doi.org/10.1038/s41557-025-01815-x
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢