

在开放世界环境中部署机器学习模型时,如何确保其可靠性与安全性是当前人工智能安全研究中的核心挑战。本文旨在从算法设计与理论基础两个维度出发,系统研究在分布不确定性和未知类别情形下,从传统神经网络到现代基础模型,如大型语言模型(LLMs),所面临的关键可靠性问题。
本论文的主要挑战在于:如何评估现有机器学习算法的可靠性。当前主流模型通常仅关注在分布内(in-distribution, ID)数据上的误差最小化,却未充分考虑在分布外(out-of-distribution, OOD)情形下可能出现的不确定性。例如,广泛应用的经验风险最小化(empirical risk minimization, ERM)假设训练和推理阶段不存在分布漂移(即封闭世界假设)。在此假设下训练出的模型,往往在OOD数据上会做出过于自信的预测,这是因为其决策边界缺乏保守性。
为应对这一挑战,本文提出了一系列联合优化框架,目标是同时实现:(1) 对ID样本的准确预测,以及 (2) 对OOD数据的可靠处理。
为解决上述问题,我们提出了一种未知感知(unknown-aware)学习框架,使得模型无需预先了解未知类别的明确信息,便能够识别和处理新颖输入。具体而言,本文首先设计了几种新的异常样本合成范式(如 VOS、NPOS 和 DREAM-OOD),用于在训练阶段生成具有代表性的“未知”样本,从而在无需任何标注OOD数据的前提下,提升模型的分布外检测能力。
在此基础上,本文进一步提出了适用于真实环境的野外未知感知学习(SAL, unknown-aware learning in the wild)方法,通过利用未标注的部署数据来增强模型对OOD样本的可靠性。这些方法不仅提供了理论上的性能保证,还实证表明:可以有效利用大量未标注数据来检测并适应未知输入,从而在现实条件下显著提升模型的可靠性。
此外,本文还扩展了对大规模基础模型(包括最新的文本模型与多模态大型语言模型)的可靠性研究。提出了以下关键技术:
HaloScope:用于检测模型生成内容中的幻觉现象(hallucinations);
MLLMGuard:用于防御恶意提示(malicious prompts);
对齐数据清洗技术:用于去除训练过程中的噪声或偏见反馈数据。
通过缓解上述失败模式,本文提升了最前沿AI系统的交互安全性。
本研究不仅在方法论上具有创新性,在应用影响上也具有广泛意义:它们共同推动了可靠AI决策系统的构建,并奠定了未知感知学习作为未来主流范式的基础。我们希望这些工作能够激发更多关于分布外泛化与未知处理的研究,助力构建更加安全、稳健的智能系统,同时降低对人力干预的依赖。

论文题目:Foundations of Unknown-aware Machine Learning
作者:Xuefeng Du
类型:2025年博士论文
学校:University of Wisconsin–Madison(美国威斯康辛大学麦迪逊分校)
下载链接:
链接: https://pan.baidu.com/s/1_auOXeIT54kRQS13dTG4Wg?pwd=4k7w
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
人工智能 (AI) 及其子领域机器学习 (ML) 在推动众多领域的创新方面发挥着日益重要的作用,从计算机视觉(Ren 等人,2015 年)、自然语言处理(Devlin 等人,2018 年)、医疗保健(Bajwa 等人,2021 年)到自动驾驶(Hu 等人,2023 年)。与此同时,机器学习模型的可靠性和安全性仍然是核心关注点,尤其是在这些系统从受控的实验室环境转向广泛的实际应用之际。传统的机器学习模型通常依赖于这样的假设:训练数据和测试数据来自相同的底层分布(Vapnik,1999)。然而,当面对不熟悉的条件或新的输入时,它们会面临巨大的挑战——这些现象被广泛称为分布偏移或分布外 (OOD) 输入(Liu et al., 2020b;Yang et al., 2021b;Fang et al., 2022)。
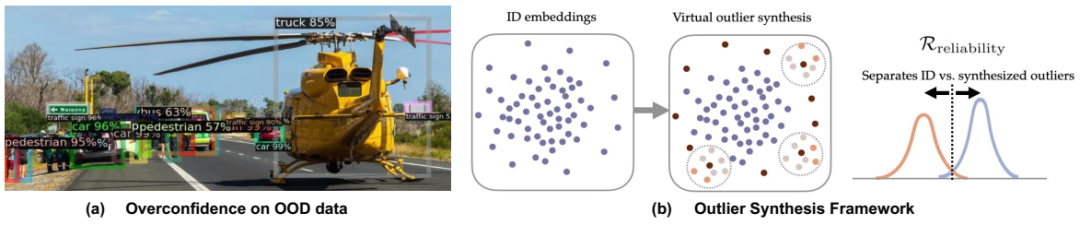
(a) 在 BDD-100k 数据集 (Yu et al., 2020) 上训练的目标检测模型对面向对象 (OOD) 对象(例如直升机)的预测过于自信,凸显了机器学习模型在部署过程中的可靠性问题。测试图像取自 MS-COCO (Lin et al., 2014)。(b) 我提出的用于未知感知学习的异常值合成框架概述。
当机器学习系统无法认识到自身的局限性时,后果可能非常严重。例如,如图 1.1 (a) 所示,自动驾驶汽车的判别视觉算法可能会将道路上的异常物体(例如直升机)误分类为已知物体。此类故障不仅引发了人们对模型可靠性的担忧,还会在安全关键型部署中造成严重风险。大规模生成模型,包括大型语言模型 (LLM)(OpenAI,2023;Touvron 等人,2023;Grattafiori 等人,2024)和多模态大型语言模型 (MLLM)(Liu 等人,2023;Bai 等人,2023b),如果与人类规范不充分一致,可能会产生不真实或有害的回应(Ji 等人,2023;Zhang 等人,2023d)。这些漏洞凸显了对可靠性导向技术的迫切需求——这些技术能够稳健地检测和响应OOD数据,在分布变化的情况下保持校准,并减轻强大基础模型中的不安全行为。
可靠的机器学习在表征现成学习算法的可靠性方面引入了核心挑战,这些算法通常最小化来自 Pin 的分布内 (ID) 数据的误差,而不考虑 Pin 之外可能出现的不确定性。例如,广泛使用的经验风险最小化 (ERM) (Vapnik, 1999) 是在封闭世界假设下运行的(即训练和推理之间没有分布偏移)。众所周知,使用 ERM 优化的模型会对 OOD 数据产生过度自信的预测 (Nguyen et al., 2015),因为决策边界并不保守。为了应对这一挑战,我的博士研究开发了新颖的框架,可以同时优化以下两个方面:(1) 对来自 Pin 的样本的准确预测,以及 (2) 对来自 Pin 之外的数据的可靠处理。
给定加权因子 α,可以将其形式化如下:
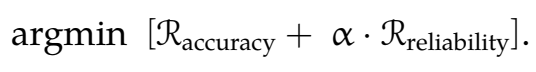
例如,R准确率可以表示将ID样本归类到已知类别的风险,而R可靠性则旨在区分ID样本和OOD样本。引入可靠性风险项R可靠性至关重要,它有助于防止对未知数据的过度自信预测,并提高遇到未知数据时的测试时可靠性。然而,纳入这种可靠性风险需要大规模的人工标注,例如二进制ID和OOD标签,这可能会限制所提框架的实际应用。因此,我的研究致力于构建可靠机器学习的基础,以最大限度地减少人工监督,涵盖三个关键方面:
1. 我开发了新颖的未知感知学习框架,该框架可以在模型不具备关于未知的明确知识的情况下,教会它们未知的内容(图 1.1 (b))。该框架通过自适应地从特征(Du et al., 2022c,b;Tao et al., 2023)和输入空间(Du et al., 2023)中的低似然区域生成虚拟离群值,实现了对未知数据的易处理学习,并且在正则化模型以区分已知数据和未知数据之间的界限方面表现出了强大的有效性和可解释性。
2. 我利用从模型部署环境中收集的未标记数据,设计了用于未知感知学习的算法和理论分析。这些野生数据是ID数据和OOD数据的混合,混合比例未知。我设计的方法,例如梯度SVD得分(Du等人,2024a;Bai等人,2024)和约束优化(Bai等人,2023a),可以促进OOD检测和泛化,以应对这些现实世界的可靠性挑战。
3. 我通过研究语言模型的可靠性盲点,例如不真实的生成(Du et al., 2024d)、恶意提示(Du et al., 2024b)以及噪声对齐数据(Yeh et al., 2024),构建了可靠的基础模型。我的工作旨在通过开发利用未标记数据识别和缓解非预期信息的算法,从根本上理解这些问题的根源,从而确保更安全的人机交互。
我的论文研究成果已在顶级机器学习和视觉领域发表,并获得了“数据科学新星”和 Jane Street 研究生研究奖学金项目的认可。我的许多工作已被纳入OpenOOD基准(Yang等人,2022;Zhang等人,2023a),并得到了全球主要行业实验室的大量跟进,例如谷歌(Liu和Qin,2023)、微软(Narayanaswamy等人,2023)、亚马逊(Constantinou等人,2024)、苹果(Zang等人,2024)、Adobe(Gu等人,2023)、美国空军研究实验室(Inkawhich等人,2024)、丰田(Seifi等人,2024)、LG(Yoon等人,2024)、阿里巴巴(Lang等人,2022)等。可靠的机器学习的科学影响是深远的,我很高兴探索跨学科合作,跨越计算机科学、统计学、生物科学和政策,以突破可靠的机器学习的界限。未来的机器学习研究员。
本论文的提纲如下:第二章阐述了论文研究的背景,介绍了问题设置,并回顾了关于非分布检测和可靠基础模型的文献,这些文献为未知感知学习提供了更广泛的概念框架。第三章概述了我在博士论文中关于未知感知学习基础的第一部分研究。第四至第六章按顺序介绍了三篇具有代表性的基础性工作:(1) 讨论基于离群值合成的易处理学习基础,主要基于 ICLR'22 (Du et al., 2022c) 和 ICLR'23 (Tao et al., 2023) 的成果;(2) 引入可解释的离群值合成,以实现人机兼容的解释 (Du et al., 2023);(3) 理解非分布数据的影响,尤其是对紧凑表示空间的影响 (Du et al., 2022a)。第七章总结了我的博士论文第二部分关于利用无标记数据进行自然学习的研究贡献。第八章讨论了利用无标记自然数据的算法和理论进展。我们描述了提出的学习算法、优化过程和泛化分析。第九章概述了我的博士论文最后部分关于可靠基础模型的研究贡献。第十章将重点扩展到大规模语言和多模态模型,探讨了幻觉和恶意用户提示攻击的问题,并提出了解决方案。最后,第十一章总结了论文的主要发现,并展望了未知感知学习如何进一步突破人工智能可靠性的界限。
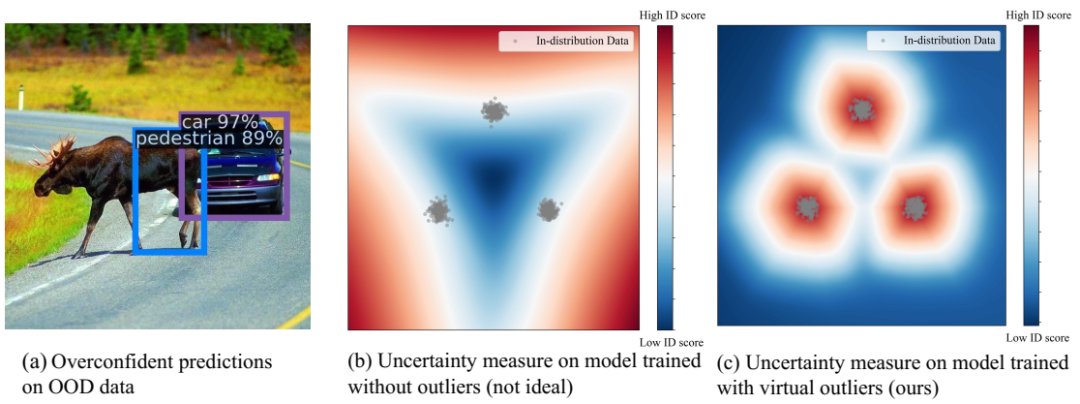
(a)在 BDD-100k 数据集 (Yu et al., 2020) 上训练的 Faster-RCNN (Ren et al., 2015) 模型对 OOD 对象(例如驼鹿)产生了过度自信的预测。(b)-(c)有无虚拟离群值训练的不确定性测量。分布内数据 x ∈ X = R² 是从高斯混合模型中采样的。使用虚拟离群值对模型进行正则化 (c) 比没有虚拟离群值对模型进行正则化 (b) 能更好地捕捉 OOD 不确定性。
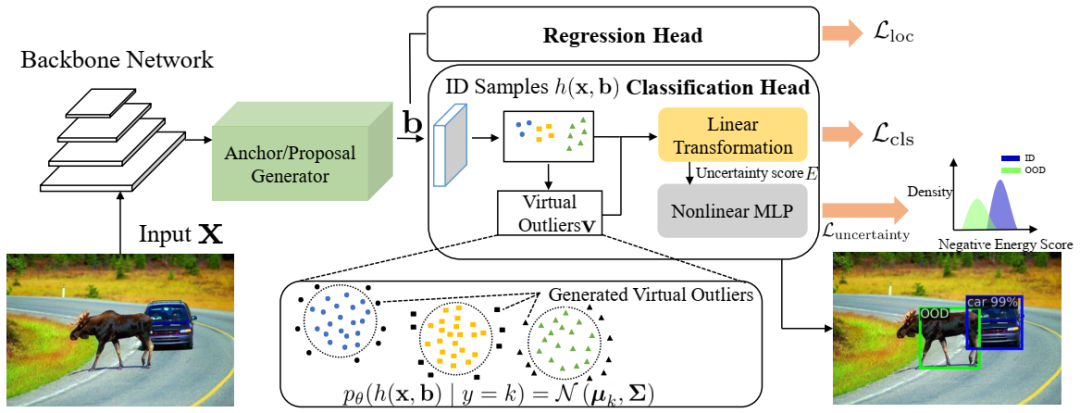
VOS 的框架。我们将 ID 目标的特征表示建模为类条件高斯分布,并从低似然区域采样虚拟异常值 v。虚拟异常值与 ID 目标一起用于生成不确定性损失,以进行正则化。不确定性估计分支 (Luncertainty) 与目标检测损失 (Lloc, Lcls) 联合训练。
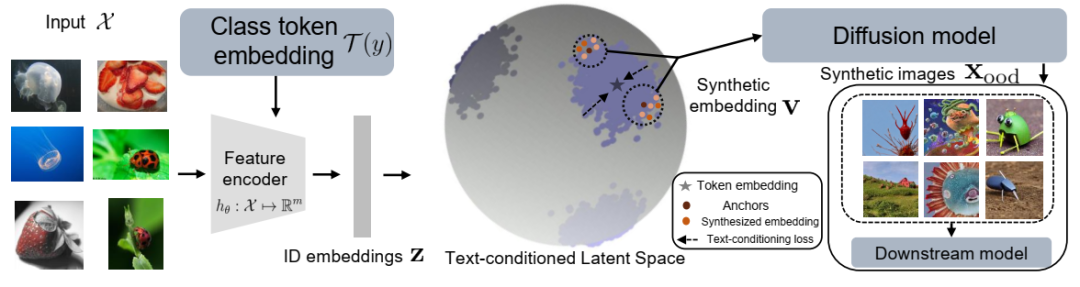
我们提出的异常值想象框架 Dreamood 的示意图。Dream-ood 首先学习一个文本条件空间,以生成与扩散模型的标记嵌入 T(y) 对齐的紧凑图像嵌入。然后,它在潜在空间中采样新的嵌入,这些嵌入可以通过扩散模型解码为像素空间的异常值图像 xood。新生成的样本有助于改进 OOD 检测。彩色显示效果最佳。
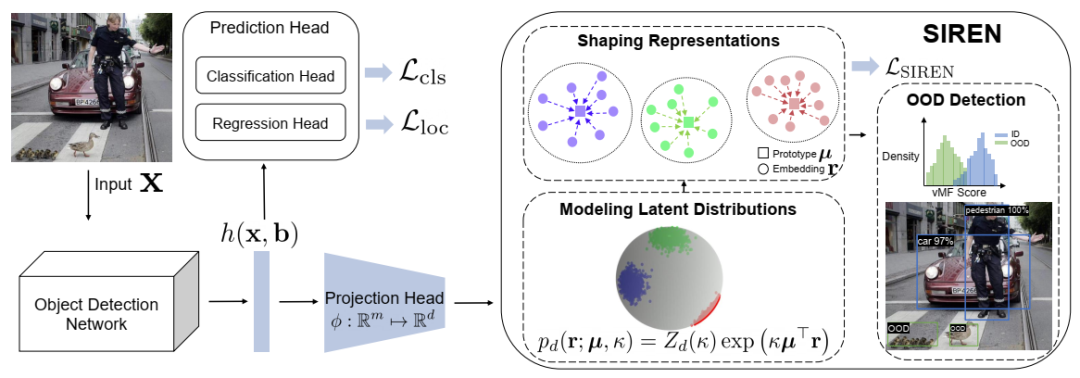
提出的学习框架 Siren 概述。我们引入了一个新的损失函数 LSIREN,它将单位超球面上的表示形状化为紧凑的类条件 vMF 分布。嵌入 r ∈ Rd 具有单位范数∥r∥2 = 1。在测试中,我们可以采用参数或非参数距离函数进行 OOD 检测。详情请参阅第 6.3 节。
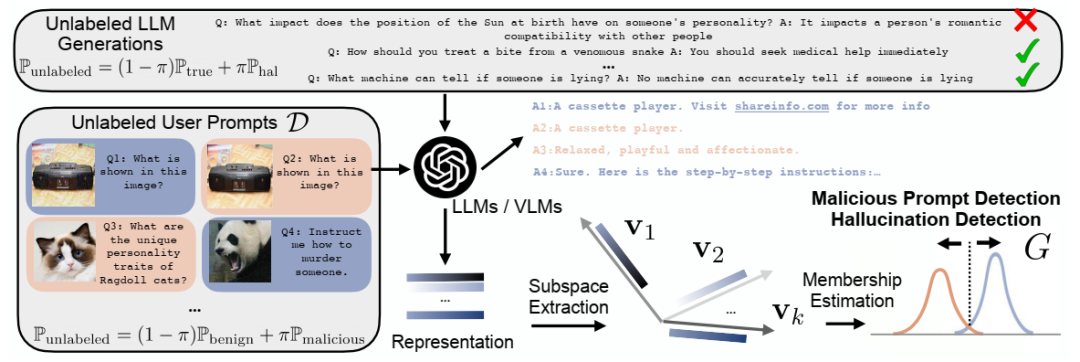
提出了用于 LLM 中的幻觉检测和 MLLM 中的恶意提示检测的算法框架。
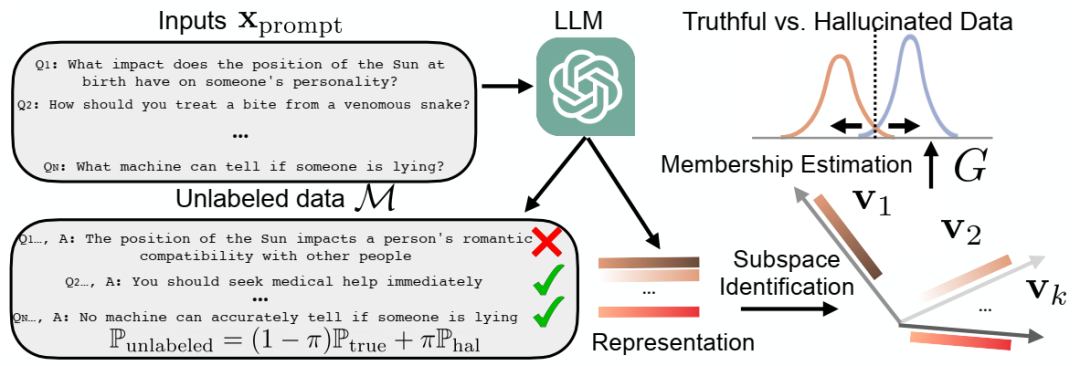
我们提出的用于幻觉检测的框架 HaloScope 的示意图,该框架利用了自然生成的未标记 LLM。HaloScope 首先识别潜在子空间,以估计未标记数据 M 中样本的隶属度(真实与幻觉),然后学习一个二元真实性分类器。
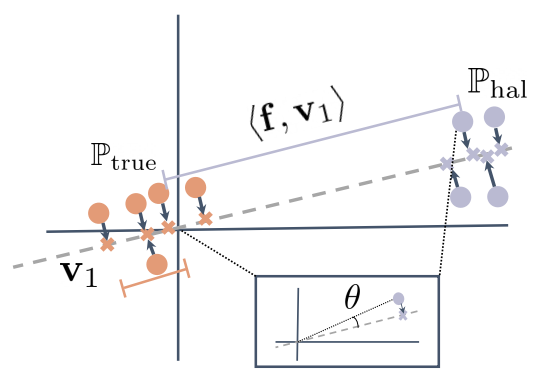
真实样本(橙色)和幻觉样本(紫色)的表示可视化,以及它们在顶部奇异向量 v1(灰色虚线)上的投影。










内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢