

ACL ( The Annual Meeting of the Association for Computational Linguistics ) 是自然语言处理(NLP)与计算语言学领域最具影响力的国际学术会议之一,被中国计算机学会(CCF)推荐为 A类会议。ACL 2025 将于7月27日—8月1日在奥地利维也纳举行。
PKU-DAIR实验室论文《Enhancing Unsupervised Sentence Embeddings via Knowledge-Driven Data Augmentation and Gaussian-Decayed Contrastive Learning》被 ACL 2025 录用。
Enhancing Unsupervised Sentence Embeddings via Knowledge-Driven Data Augmentation and Gaussian-Decayed Contrastive Learning
作者:Peichao Lai, Zhengfeng Zhang, Wentao Zhang, Fangcheng Fu, Bin Cui
Github链接:https://github.com/aleversn/GCSE
问题背景与动机

句子表示学习作为自然语言处理的基础任务,旨在生成准确的句子嵌入以提升语义推理、检索和问答等下游任务的性能。基于对比学习的无监督句子嵌入方法因计算效率高且无需人工标注数据,成为当前的研究热点。该类方法的核心思想是通过对比损失函数,拉近语义相似句子的嵌入距离并推远不相似句子的距离。然而,其性能高度依赖训练样本的数量与质量,在数据增强过程中,如何有效提升样本的多样性和纯净度,成为无监督对比学习的关键挑战。
核心挑战:数据多样性与噪声问题
现有方法主要面临两大瓶颈:
其一,数据多样性不足。现有数据增强方法常忽略实体、数量等细粒度知识,导致生成样本的语义变体有限。传统规则化方法依赖固定模板修改句子(如简单词替换),而基于大语言模型(LLM)的方法(如 SynCSE、MultiCSR)虽通过提示引导生成多样化样本,但缺乏对知识的显式控制,样本多样性受限于 LLM 的概率分布,难以覆盖同一知识的多维度表达(如实体类型、数量级变化)。
其二,数据噪声过高。无监督场景下,负样本易包含表面语义相似但实际语义无关的 “假负例样本”,而 LLM 生成的合成样本可能因语义分布偏差引入额外噪声。现有去噪方法(如 MultiCSR 的线性规划过滤)可能误删有价值样本,导致数据多样性进一步下降。如图 1 所示,在 STS-Benchmark 验证集上,现有方法普遍存在假正例(FP)和假负例(FN)样本比例失衡的问题,表明假负样例噪声已成为影响模型判别能力的关键因素。
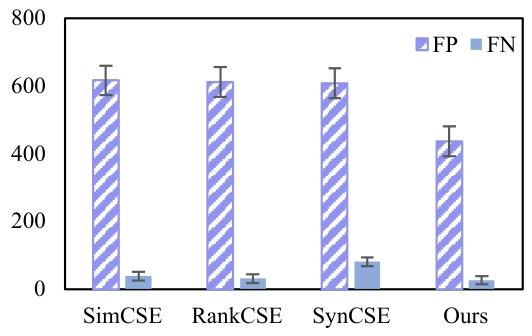
图1. 不同方法在验证集上假正例(FP)和假负例(FN)对比
为解决上述问题,本研究提出结合知识图谱与 LLM 的流水线式结构的数据增强方法,并引入高斯衰减对比学习模型(GCSE)。具体动机包括:
1. 显式建模细粒度知识:通过知识图谱提取句子中的实体、数量及其关系,引导 LLM 生成包含结构化语义变体的样本(如实体替换、数量调整),突破传统方法对全局语义的粗粒度控制,提升样本多样性。
2. 动态抑制噪声影响:设计高斯衰减函数调整假负例样本的梯度权重,在训练初期降低其对语义空间的扭曲,随着模型收敛逐步恢复权重,实现噪声样本的有效利用而非直接丢弃。
3. 提升数据利用效率:在少样本和轻量级 LLM 场景下实现较高性能,证明了方法对低资源场景的适应性。通过上述创新,本研究旨在为无监督句子嵌入提供一种兼顾多样性与噪声影响的解决方案,推动其在实际场景中的应用。
数据增强和模型训练流程


图2. 数据增强和句子表示训练工作流
如图2所示,本方法通过LLM进行数据增强,从源数据中合成新样本,然后使用经过初始过滤的合成数据训练GCSE模型。
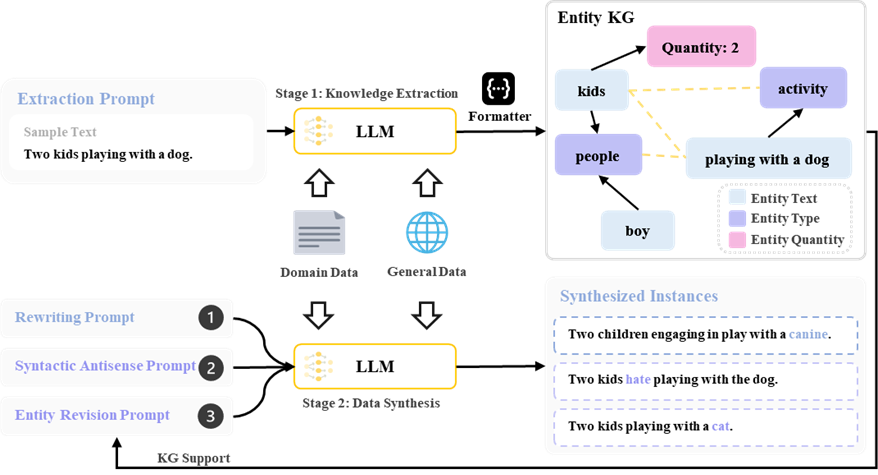
图3. 基于知识抽取构建实体知识图谱的数据生成框架
1. 数据增强:知识驱动的样本合成流程
数据增强模块旨在通过LLM生成高质量、多样化的训练样本,平衡领域特异性与通用语义空间的适配性。该流程分为知识提取与整合和基于 LLM 的正负样本合成两个核心环节,如图 3 所示。首先,从源数据中提取实体、数量等细粒度知识,构建实体知识图谱(KG),其中节点包含实体文本、类型及数量(如 “孩子 - 人物 - 两个”),边分为硬边(实体与类型 / 数量的固定关系)和软边(同一句子内实体间的关联)。通过知识图谱,可系统地捕捉样本中的结构化信息,为后续合成提供语义约束。
知识提取与图谱构建
具体而言,通过设计提取提示词,利用 LLM 从每个样本中解析出知识集合,每个知识单元包含实体文本、类型和数量。将所有样本的知识单元整合为实体知识图谱,其中节点包含所有提取的三元组,通过构建实体和对应实体类型的硬边(如 “狗 - 动物”)和实体与上下文其他实体的软边(如 “狗 - 公园” 的共现关系)连接节点。这种结构化表示允许模型高效识别可替换的实体节点(如同一类型的 “猫”“狗”),确保合成样本与源样本的语义关联性。
基于 LLM 的正负样本合成
在样本合成阶段,通过三类提示词引导 LLM 生成多样化样本:
(1) 改写提示词:生成正样本,如通过 “重写句子但保留原意” 指令生成语义等价变体(如 “两个孩子和狗玩耍”→“孩童与犬类嬉戏”)。
(2) 语法反义提示词:生成语法层面矛盾的负样本,如通过否定词或情感反转构造语义对立句(如 “孩子没有和狗玩耍”)。
(3) 实体 / 数量修订提示词:基于知识图谱搜索相邻节点(如替换 “狗” 为同类型实体 “猫”,或调整数量 “两个”→“一个”),生成细粒度差异的负样本。 通过知识图谱约束实体替换范围(如仅选择同类型实体或关联实体),确保负样本在表面特征上接近源样本,但在细粒度语义上存在明确差异,从而提升对比学习的有效性。生成样本经评估模型初步过滤后,形成最终的训练数据集。
2. 模型训练:两阶段对比学习框架
模型训练过程分为通用对比学习预训练和带噪声抑制的对比学习微调两个阶段,旨在通过渐进式训练提升模型对语义空间的建模能力。首先,利用通用数据和领域数据预训练一个评估模型,学习通用语义分布;随后,将评估模型的结构和参数迁移至 GCSE 模型,并通过高斯衰减函数动态调整难负样本的影响,实现对合成数据中噪声的有效抑制。
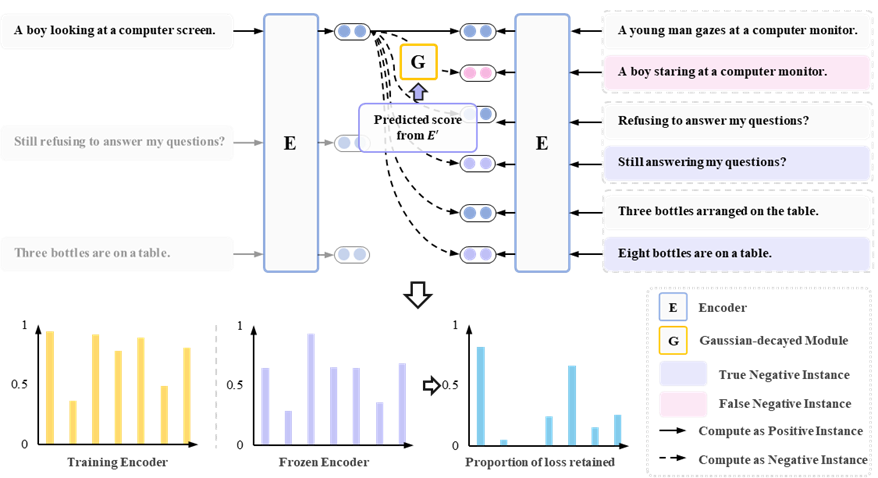
图4. 基于高斯衰减的GCSE模型批次训练示例图
第一阶段:通用对比学习预训练
在预训练阶段,采用标准对比学习框架SimCSE训练评估模型。对于每个无标签句子,将其自身通过随机 dropout 生成两个不同视图作为正样本对,同批次其他句子作为负样本。损失函数采用 InfoNCE 形式,计算正样本对的余弦相似度并拉远与负样本的距离。此阶段通过通用数据(如 Wikipedia)和领域数据的混合训练,使评估模型学习到均匀的语义分布,为后续噪声过滤和特征提取提供相对可靠基准。预训练完成后,评估模型参数被冻结,用于合成数据的质量评估。
第二阶段:带高斯衰减的对比学习微调
在微调阶段,GCSE 模型以评估模型为骨干网络,接收由数据增强流程生成的三元组样本 。首先通过评估模型过滤合成样本:
正样本筛选:采用较高阈值保留与源样本相似度高(如 0.9)的合成句;
负样本筛选:选择与源样本相似度相对较高的合成句或随机批次内负样本来保留文本多样性以及易混淆负样例。对于过滤后的负样本,引入高斯衰减函数动态调整其梯度权重。该函数根据 GCSE 模型与评估模型对负样本的相似度预测差异的自动衰减梯度:
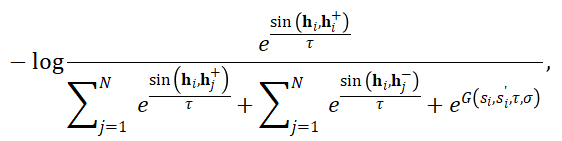

在训练初期,若负样本被误判为相似(假负例),期望GCSE对齐评估模型的相似度分数,利用高斯函数抑制其梯度,避免语义空间因假负样例而发生错误变化;随着训练推进,若真负样本的相似度分数与评估模型逐渐加大,其梯度权重将逐步恢复,确保模型最终学会区分细粒度语义差异。此机制在保留样本多样性的同时,有效缓解了噪声对训练的干扰。
实 验 结 果
实验数据与场景配置
实验在两类场景下展开:一是基于 Wikipedia 文本的默认设置,遵循经典方法合成样本;二是模拟低资源场景,采用 STS-12(2.2k)、PAWS(3.5k)、SICK(4.5k)等领域无标签数据与 NLI 通用数据(比例 1:3),验证模型在有限数据下的性能。数据增强环节利用 ChatGLM3-6B、GPT-3.5 Turbo、Deepseek-V3-0324 等多个参数规模 LLM 生成样本,覆盖从 6B 到 32B 参数的本地模型,以测试方法对不同 LLM 的适配性。
模型架构与训练流程
主干网络采用 BERT 和 RoBERTa(base/large 版本),训练分为两阶段:首先通过标准对比学习在混合数据上预训练评估模型,学习通用语义分布,其参数后续冻结用于合成数据过滤;然后以评估模型为骨干初始化 GCSE,输入经知识图谱引导生成的三元组样本(源句、正样本、负样本),通过设定阈值初始过滤高噪声样本,并利用高斯衰减函数动态调整难负样本的梯度权重,平衡噪声抑制与样本多样性。
评估指标与基线对比
核心评估聚焦语义文本相似性(STS)任务,覆盖 7 个标准子集,以 Spearman 相关系数为指标,并通过 SentEval工具对比包括传统无监督方法(如 SimCSE、RankCSE)和 LLM 增强方法(SynCSE、MultiCSR)。实验在 NVIDIA A800 GPU 上完成数据合成,于 8 块 NVIDIA TITAN RTX GPU 进行模型训练,确保效率与稳定性。
主要实验结果
在语义文本相似性(STS)任务上,本文方法展现出显著的性能优势。表1结果显示,基于不同大语言模型(LLM)合成数据的 GCSE 模型在所有主干网络(BERT、RoBERTa)上均优于现有无监督基线方法。例如,使用 Deepseek-V3-0324 和 GPT-3.5 Turbo 合成样本的 GCSE 模型在 STS 任务平均得分中表现最佳;即使采用轻量级 LLM(如 ChatGLM3-6B),GCSE 仍能超越 SynCSE、MultiCSR 等先进方法。具体而言,与标准无监督 SimCSE 相比,GCSE(ChatGLM3-6B)在 Base 模型上平均提升 5.40%,在 Large 模型上提升 3.95%;在强基线 RankCSE 基础上,平均提升 1.90%,验证了 LLM 数据合成流程的有效性。

表1. 默认设置下的实验结果
在模拟低资源、高质量领域数据的场景下(表1),GCSE 使用仅为 SynCSE 和 MultiCSR 14% 的样本量,仍实现了更高的平均 Spearman 相关系数。例如,在 BERT-base 模型上,GCSE(GPT-3.5 Turbo)平均得分达 81.92,显著优于依赖全量 NLI 数据的基线方法,表明本文提出的数据合成策略和领域样本选择方法能高效利用有限数据,提升模型对目标领域的语义建模能力。

表2: 模拟低资源场景下的实验结果
此外,GCSE 在不同规模的 LLM 下均表现出鲁棒性:从 6B 参数的 ChatGLM3 到 32B 参数的 Qwen2.5,模型性能随 LLM 规模增长呈上升趋势,但即使使用较小 LLM,GCSE 仍能通过知识驱动的数据增强弥补模型能力的不足,在 STS 任务中保持领先。实验结果表明,本文方法在数据效率和模型泛化性上实现了双重突破,为无监督句子嵌入提供了新的性能基准。
总 结

本研究提出知识驱动的数据增强框架与高斯衰减对比学习模型(GCSE),通过提取实体、数量等细粒度知识构建知识图谱来指导LLM生成多样化样本,并创新性地采用高斯衰减梯度调节机制:在训练初期降低困难负样本的梯度权重,根据其与评估模型的分布偏差动态调整梯度影响,从而在提升数据多样性的同时有效抑制噪声干扰。实验表明,GCSE在STS任务上能够以更少数据量和较小模型参数规模实现显著的性能提升,实验在BERT和RoBERTa系列模型上取得了优于现有方法的平均性能,为细粒度句子表示学习提供了兼顾语义多样性与噪声控制能力的新范式。
欢迎关注本公众号,帮助您更好地了解北京大学数据与智能实验室(PKU-DAIR),第一时间了解PKU-DAIR实验室的最新成果!
实验室简介
北京大学数据与智能实验室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR实验室)由北京大学计算机学院崔斌教授领导,长期从事数据库系统、大数据管理与分析、人工智能等领域的前沿研究,在理论和技术创新以及系统研发上取得多项成果,已在国际顶级学术会议和期刊发表学术论文200余篇,发布多个开源项目。课题组同学曾数十次获得包括CCF优博、ACM中国优博、北大优博、微软学者、苹果奖学金、谷歌奖学金等荣誉。PKU-DAIR实验室持续与工业界展开卓有成效的合作,与腾讯、阿里巴巴、苹果、微软、百度、快手、中兴通讯等多家知名企业开展项目合作和前沿探索,解决实际问题,进行科研成果的转化落地。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢