
【论文标题】Meta-KD: A Meta Knowledge Distillation Framework for Language Model Compression across Domains 【作者团队】Haojie Pan, Chengyu Wang, Minghui Qiu, Yichang Zhang, Yaliang Li, Jun Huang 【发表时间】2020/12/02 【论文链接】https://arxiv.org/abs/2012.01266
【推荐理由】
本文来自阿里巴巴的研究团队,作者提出了一个元知识提炼(Meta-KD)框架,以建立一个元老师模型,该模型捕获元学习启发下跨领域的可迁移知识并将其传递给学生模型。
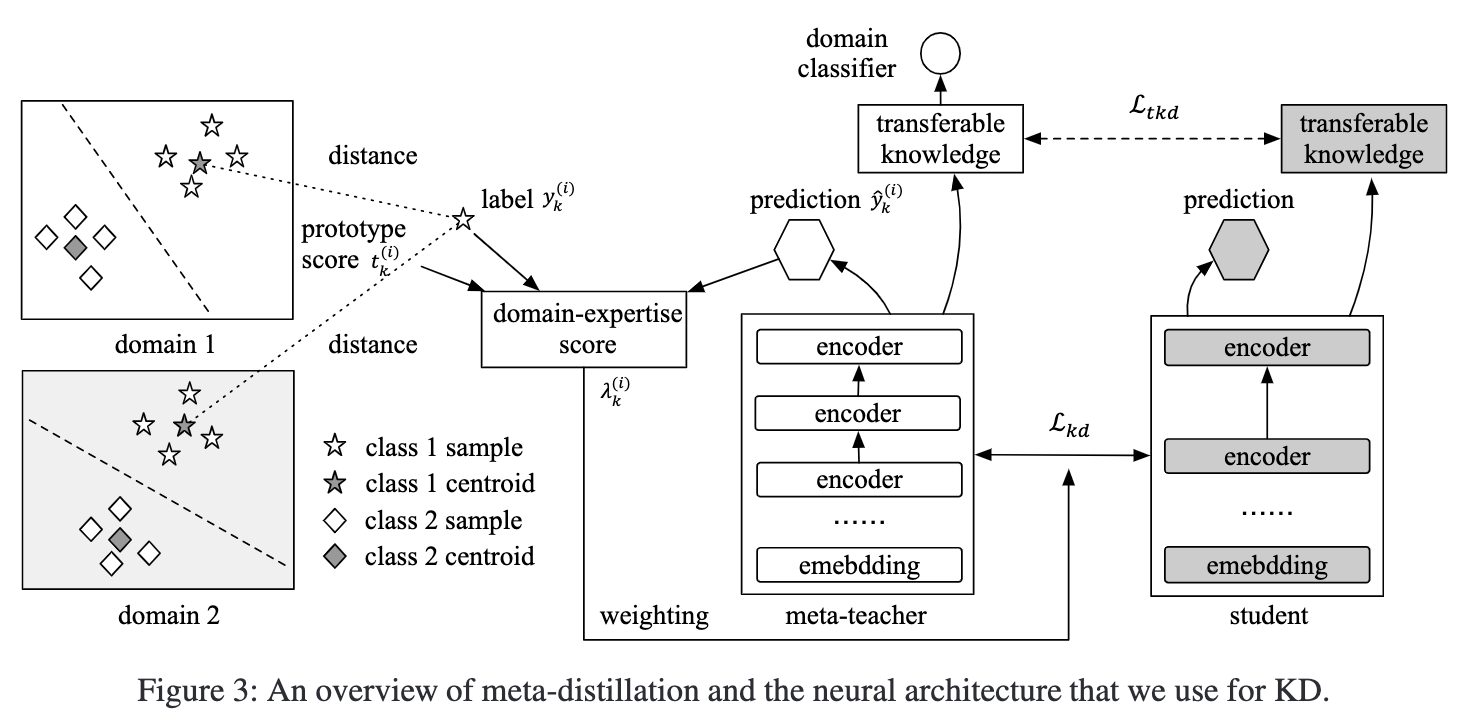
预训练的语言模型已应用于各种NLP任务,并获得了可观的性能提升。但是,较大的模型大小以及较长的推理时间限制了此类模型在实时应用程序中的部署。典型的方法考虑知识蒸馏以将大型教师模型提炼为小型学生模型。但是,大多数这些研究仅关注单域,而忽略了来自其他域的可迁移知识。作者认为,训练具有跨域摘要的可迁移知识的教师可以实现更好的泛化能力,以帮助知识提炼。为此,作者提出了一个元知识提炼(Meta-KD)框架,以建立一个元老师模型,该模型捕获元学习启发下跨领域的可迁移知识并将其传递给学生模型。具体来说,作者首先利用跨域学习过程在多个域上训练元教师,然后提出一种元蒸馏算法,以在元教师的指导下学习单域学生模型。在两个公共多域NLP任务上进行的实验证明了所提出的Meta-KD框架的有效性和优越性。作者还演示了在短镜头和零镜头学习设置中的Meta-KD功能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢