
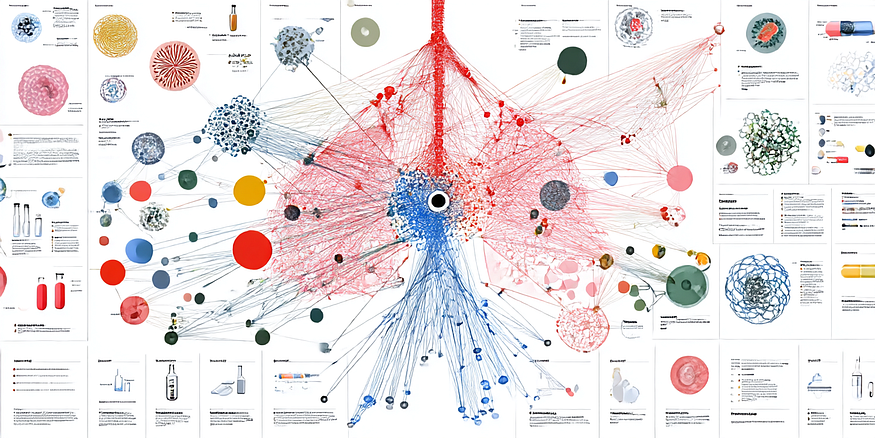
Latent Graph
潜在图
Latent graphs are learned graph representations that capture implicit relationships in data without predefined structures (e.g., ontologies).
潜在图是学习到的图表示形式,能够在没有预定义结构(例如本体)的情况下捕捉数据中的隐含关系。
Latent graphs infer hidden connections through:
潜在图通过以下方式推断隐藏连接:
Disentangled embeddings separating object features (e.g., surgical tools vs organs), by breaking ontological constraints of graphs
分离对象特征(例如,手术工具与器官)的解耦嵌入,通过打破图的本体约束
Graph neural networks predicting unobserved edges via link prediction
通过链接预测预测未观察到的边的图神经网络
Multi-scale relation encoding (local object positions + global scene context)
多尺度关系编码(局部物体位置+全局场景上下文)
Microsoft’s GraphRAG is a a latent, on-the-fly text-centric extraction and summaries by an LLM to augment context for RAG-style retrieval and reasoning over unstructured data. One obvious concern with latent graphs are the hallucinations and semantic drift associated with relying on LLMs during feature extraction and creation of community reports.
微软的 GraphRAG 是一种潜力的、实时文本中心提取和总结,由 LLM 增强 RAG 风格检索和推理在非结构化数据上。潜图的一个明显问题是依赖 LLM 在特征提取和社区报告创建过程中产生的幻觉和语义漂移。
GraphRAG
This article will not cover the evolving field related to knowledge graph embeddings, specifically — distance vs. semantic matching for grounding. You can read more about this here. I however, did evaluate Microsoft’s GraphRAG for grounded results, and you can see more in the results section.
本文不会涵盖与知识图谱嵌入相关的不断发展的领域,特别是——用于定位的距离与语义匹配。你可以在这里了解更多(https://arxiv.org/abs/2309.12501)。然而,我确实评估了微软的 GraphRAG 用于获得定位结果,你可以在结果部分看到更多。
In this article, I will highlight an experiment conducted to evaluate the capabilities of GraphRAG by providing a working example of an implementation.
在本文中,我将重点介绍一个实验(https://github.com/usathyan/graphrag),通过提供一个工作示例来评估 GraphRAG 的功能。
The primary objectives were to:
主要目标是要:
Build a latent knowledge graph from the scientific articles.
从科学文章中构建一个潜在知识图谱。
Test the system’s ability to retrieve and synthesize information for a range of scientific questions.
测试系统在检索和综合信息以回答一系列科学问题方面的能力。
Observe the impact of different Large Language Models (LLMs) used for the chat/synthesis components on query success and answer quality.
观察用于聊天/综合组件的不同大型语言模型(LLMs)对查询成功率和答案质量的影响。
In the near future, I will update this project with ability to ground the facts to popular biomedical ontologies and revisit the evaluations.
在不久的将来,我将更新此项目,使其能够将事实与流行的生物医学本体相结合,并重新进行评估。
Experiment linking scientific articles in drug discovery space
在药物发现领域连接科学文章的实验
For this experiment, I used Perplexity.AI, to help me identify and build a high-quality, relevant corpus of sample articles for drug discovery target identification, leveraging open-access PDFs, PubMed Central (PMC), Europe PMC, bioRxiv, and related sources. I then set up a GraphRAG environment on my M1-Max Mac studio, running local models using ollama for indexing, and using Openrouter.ai’s models for querying. The selection and rationale for these LLMs were based on balancing cost and performance. Since the articles used were PDF, I also built some tools using Microsoft’s MarkItDown libary to convert them to markdown. You can find more details about these in the Github project.
在这个实验中,我使用了 Perplexity.AI,帮助我识别并构建一个高质量、相关的样本文章语料库,用于药物发现靶点识别,利用开放获取 PDF、PubMed Central (PMC)、Europe PMC、bioRxiv 及相关资源。然后我在我的 M1-Max Mac 工作室上设置了一个 GraphRAG 环境,使用 ollama 进行本地模型索引,并使用 Openrouter.ai 的模型进行查询。这些 LLMs 的选择和理由是基于平衡成本和性能。由于使用的文章是 PDF 格式,我还使用 Microsoft 的 MarkItDown 库构建了一些工具将它们转换为 markdown。你可以在 Github 项目(https://github.com/usathyan/graphrag)中找到更多关于这些的细节。
Articles used:
使用的文章:
A comprehensive map of molecular drug targets (PMC6314433)
分子药物靶点的全面地图 (PMC6314433)
Therapeutic target database update 2022 (bioRxiv/TTD)
治疗靶点数据库更新 2022(bioRxiv/TTD)
Leveraging big data to transform target selection (PMC4785018)5
利用大数据转化靶点选择(PMC4785018)5
Comprehensive Survey of Recent Drug Discovery Using Big Data (Europe PMC)
大数据在近期药物发现中的综合调查(Europe PMC)
Discovering protein drug targets using knowledge graph (bioRxiv)
利用知识图谱发现蛋白质药物靶点(bioRxiv)
Utilizing graph machine learning within drug discovery (bioRxiv)
在药物发现中应用图机器学习(bioRxiv)
Sample queries:
示例查询:
“What are emerging therapeutic targets for non-small cell lung cancer identified in the last five years?”
“过去五年中,非小细胞肺癌的新兴治疗靶点有哪些?”
“Which proteins have been implicated as druggable targets in CRISPR screens for metabolic diseases?”
“在代谢疾病的 CRISPR 筛选中,哪些蛋白质被确定为可成药靶点?”
“List novel kinase targets associated with resistance to current melanoma therapies.”
“列出与当前黑色素瘤疗法耐药性相关的激酶靶点。”
“Summarize recent advances in computational methods for target identification in rare genetic disorders.”
“总结在罕见遗传病靶点识别中计算方法的新进展。”
“What are the most frequently validated targets in published high-throughput screening studies for neurodegenerative diseases?”
“已发表的神经退行性疾病高通量筛选研究中,哪些靶点验证频率最高?”
“Which disease pathways have newly identified protein targets with available structural data?”
“哪些疾病通路有新发现的蛋白质靶点且具有可用的结构数据?”
“Find articles reporting on target deconvolution methods in phenotypic drug discovery.”
“查找在表型药物发现中报告靶点去卷积方法的文献。”
“Summarize the use of knowledge graphs for predicting novel drug-target interactions.”
“总结知识图谱在预测新型药物靶点相互作用中的应用。”
“What are the most cited targets for immuno-oncology drug development in the last three years?”
“过去三年免疫肿瘤学药物开发中最常被引用的靶点是什么?”
“Which targets have been identified using multi-omics integration in cardiovascular disease research?”
“在心血管疾病研究中,哪些靶点是通过多组学整合被识别的?”
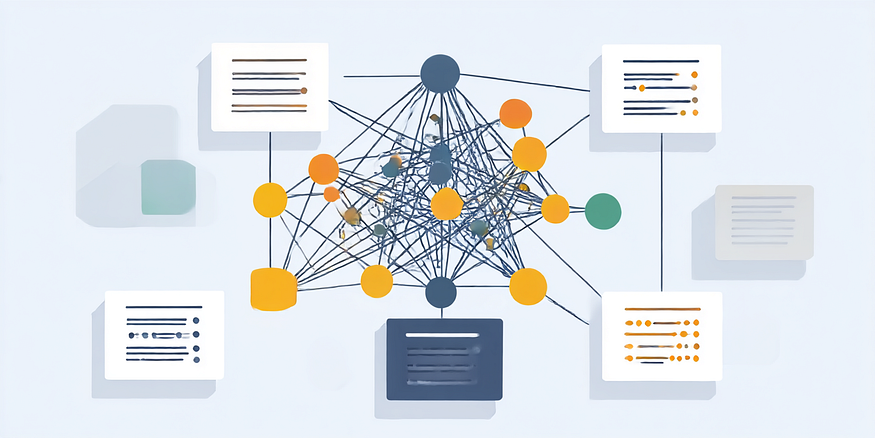
GraphRAG
The results:
结果:
OpenAI’s gpt-4.1-mini provided the best balance of performance and cost for these experiments. It successfully handled most of the complex summarization and information extraction queries. This model is also rated #1 on openrouter.ai’s Science leaderboard.
OpenAI 的 gpt-4.1-mini 在这些实验中提供了最佳的性能与成本平衡。它成功处理了大部分复杂的摘要和信息提取查询。该模型在 openrouter.ai 的科学排行榜上排名第一(https://openrouter.ai/rankings/science?view=week)。
GraphRAG can only synthesize answers based on the information present in the indexed documents. If the information isn’t there, no amount of prompt engineering or model power can create it.
图 RAG 只能根据索引文档中的信息来合成答案。如果信息不存在,无论多少提示工程或模型能力都无法创造它。
Highly specific queries, especially those asking for ranked lists (“most cited”) or quantitative details not typically found in narrative text, are challenging unless the input data is specifically structured or contains explicit mentions. I did not get good responses in local search either. This could also be a result of lack of extensive corpus.
高度具体的查询,尤其是那些要求排序列表(“引用最多”)或定量细节的查询,这些细节通常不在叙述性文本中,除非输入数据是专门结构化的或包含明确提及,否则具有挑战性。我在本地搜索中也没有得到好的响应。这也可能是由于缺乏广泛语料库的结果。
The different outcomes for Query 5 on separate runs with the same model and data indicate the probabilistic nature of LLMs (Hallucinations!) and perhaps variability in the document chunk retrieval and mapping steps. This is a factor to consider for applications requiring high determinism.
使用相同模型和数据对查询 5 进行多次独立运行的不同结果,表明了 LLMs(幻觉!)的随机性,以及文档片段检索和映射步骤中的可变性。这是需要考虑的一个因素,对于需要高确定性的应用而言。
The GraphRAG system, particularly when paired with a capable model like openai/gpt-4o-mini, demonstrated a strong ability to index a corpus of scientific articles and provide detailed, synthesized answers to complex domain-specific questions.
GraphRAG 系统,特别是与像 openai/gpt-4o-mini 这样强大的模型配合使用时,展示了强大的能力,能够索引科学文章语料库,并提供针对复杂特定领域问题的详细、综合的答案。
Smaller models like gpt-4.1-nano may be suitable for simpler queries or when cost is an extreme constraint but will likely struggle with nuanced synthesis.
像 gpt-4.1-nano 这样的小型模型可能适用于简单的查询,或者在成本是极端约束的情况下,但很可能会在细微的综合方面遇到困难。
For queries that failed due to likely absence of information (e.g., Query 2, 9, 10), the solution lies in curating a more appropriate or comprehensive set of input documents.
由于信息可能缺失而导致的查询失败(例如查询 2、9、10),解决方案在于整理更合适或更全面的输入文档集。
And for Graph Enthusiasts, the Graph Statistics:
对于图爱好者,以下是图统计信息:
For 6 articles, it extracted 3224 entities, 2242 relationships, and generated about 167 community reports.
对于 6 篇文章,它提取了 3224 个实体、2242 个关系,并生成了大约 167 份社区报告。
The knowledge graph seems to begin with a person node as reference. A person is linked to their publications, and so on. The default prompt used to extract graph uses organization, name, geography as example entities, and most likely thats the reason we have these extracted. More details on modifying entity extraction characterstics can be found here. While I did not try it, it does offer feature extraction using NLTK toolkit, which I have also demonstrated here.
知识图谱似乎以一个人物节点作为参考起点。一个人会链接到他们的出版物,等等。用于提取图的默认提示使用组织、名称、地理作为示例实体,这很可能是我们提取到这些内容的原因。有关修改实体提取特征的更多详情,可以在这里找到(https://microsoft.github.io/graphrag/index/methods/)。虽然我没有尝试过,但它确实提供了使用 NLTK 工具包进行特征提取的功能,我也在这里演示过(https://github.com/usathyan/bio-ner)。
These graphs then are grouped into communities. See this guide on how and what this means.
这些图表随后被分组为社区。查看此指南(https://microsoft.github.io/graphrag/index/default_dataflow/)了解其含义和方法。
These communities are summarized. See example summaries for top 2 communities.
这些社区被总结。查看前两个社区的示例总结。
These community reports are vectorized and searched along with the other data (they have their own embeddings). While, GraphRAG does not inherently use knowledge embeddings — it does offer multiple levels of embeddings to mitigate bonding edges and relationships together (see section 7, that talks about 3 embedding layers)
这些社区报告被向量化,并与其他数据一起搜索(它们有自己的嵌入)。虽然 GraphRAG 本身不使用知识嵌入——但它确实提供多个级别的嵌入来缓解绑定边和关系(参见第 7 节(https://microsoft.github.io/graphrag/index/default_dataflow/),该节讨论了 3 个嵌入层)
But, let me start by saying its impressive! All prompts are default, but this is where the prompt tuning guide is useful. One of the tools that comes with it, is Auto Tune. This is similar to the Github repo I had shared earlier, that uses a competency question based generation to generate relevant entities from documents.
但,让我先说一句,它令人印象深刻!所有提示都是默认的,但这是提示调整指南(https://microsoft.github.io/graphrag/prompt_tuning/overview/)有用的地方。其中附带的一个工具是 Auto Tune(https://microsoft.github.io/graphrag/prompt_tuning/auto_prompt_tuning/)。这与我之前分享的 Github 仓库类似(https://github.com/usathyan/KG),它使用基于能力问题的生成来从文档中生成相关实体。
See Readme for a more comprehensive report and on how to run this tool yourself.
参见 Readme(https://github.com/usathyan/graphrag) 以获取更全面的报告以及如何自行运行此工具。
All code written by Google Gemini 2.5 Pro, using Cursor.
所有代码由 Google Gemini 2.5 Pro 编写,使用 Cursor。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢