

继作者团队此前对经典图神经网络(GNNs)在节点分类任务中的研究 [1],本研究进一步探讨了经典GNNs在图分类与图回归任务中的潜力。为此,本文通过提出GNN+框架,将六项常用超参数技术(边特征、归一化、Dropout、残差连接、FFN和位置编码)集成进经典GNNs架构中(包括 GCN、GIN 和 GatedGCN),以全面重估其性能表现。实验结果表明,在公平对比近三年提出的30个主流GTs和GSSMs时,经典GNNs在14个广泛使用的大规模图级任务数据集上整体性能优异,在全部数据集上进入前三,其中在8个任务中取得第一。值得强调的是,经典GNNs在保持高效性能的同时,在大多数数据集上显著快于GTs模型,最高可达10倍的加速。本研究挑战了“复杂全局建模架构在图级任务中天然优越”的主流观点,重新确认了经典GNNs在图级任务中的适用性与竞争力,强调其作为强大基线模型的现实潜力。

Title: Can Classic GNNs Be Strong Baselines for Graph-level Tasks? Simple Architectures Meet Excellence
作者:罗元凯,时磊,吴晓明
单位:北京航空航天大学、香港理工大学
日期:2025年6月3日
Paper Link: https://arxiv.org/abs/2502.09263
Code: https://github.com/LUOyk1999/GNNPlus
重新评估经典GNNs系列工作:
1. 引言
图级任务(graph-level tasks)是图机器学习中最具挑战性的研究方向之一,涵盖了从小规模分子图的属性预测,到大规模蛋白质图与代码图的分类与回归。在这些任务中,整个图被视为基本学习单元,要求模型能够全面理解图结构与节点属性的联合模式。
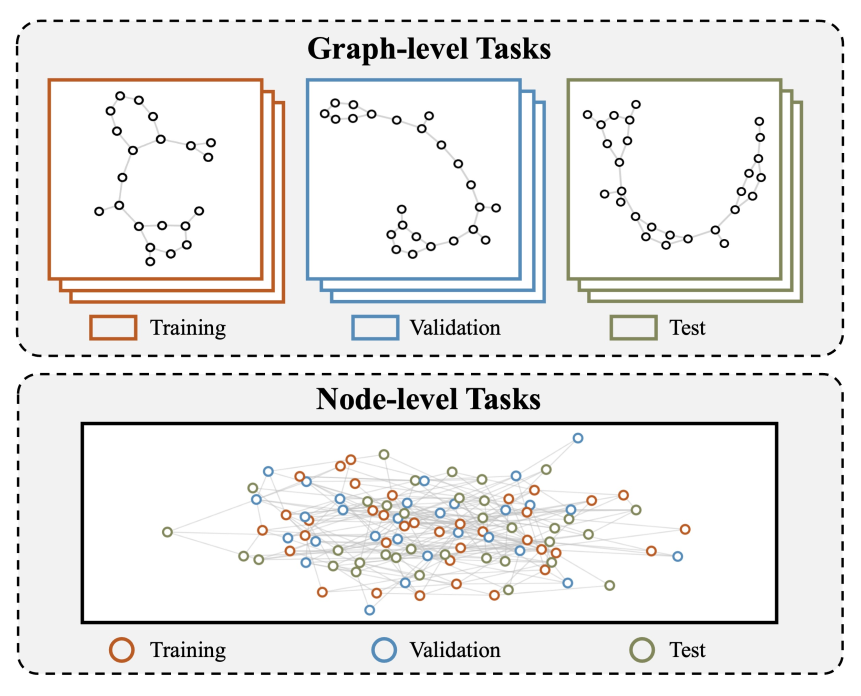
图级和节点级任务之间的差异。
近年来,随着Graph Transformer(GTs)和Graph State Space Models(GSSMs)等模型在多个公开排行榜上取得优异成绩,尤其是在小分子图领域,其全局序列建模机制被认为具备天然的表示优势。在这一趋势推动下,逐渐形成一种共识:相比基于局部消息传递机制的经典GNNs,此类复杂模型在图级任务中更具表现力和应用潜力。
然而,已有研究[1]显示,经典GNNs在节点任务中的表现被系统性低估,其原因在于以往超参数设置不合理、评估覆盖范围有限。本研究自然延伸出一个问题:经典GNNs在图级任务中是否也存在未被挖掘的性能潜力?
为此,本文构建了GNN+框架,在三类经典GNNs模型(GCN、GIN、GatedGCN)基础上,引入六项被广泛使用的超参数技术(边特征整合、归一化、Dropout、残差连接、前馈网络、位置编码),全面评估其在14个广泛使用的大规模图级任务数据集中的表现。主要发现如下:
- 经典GNNs在全部数据集上进入前三,8个数据集取得第一,性能全面对标或超越当前SOTA GTs、GSSMs等架构
; - 经典GNNs有显著的训练效率优势,更适合大规模图学习场景
; - 通过消融实验,系统验证了GNN+框架中每个模块的有效性,揭示其对性能的独立与联合贡献
这些结果再次重申:经典GNNs在图表示学习中的核心地位不应被忽视,简单模型在合理设计与调优下,依然是图级任务中的强大竞争者。
2. GNN+框架介绍
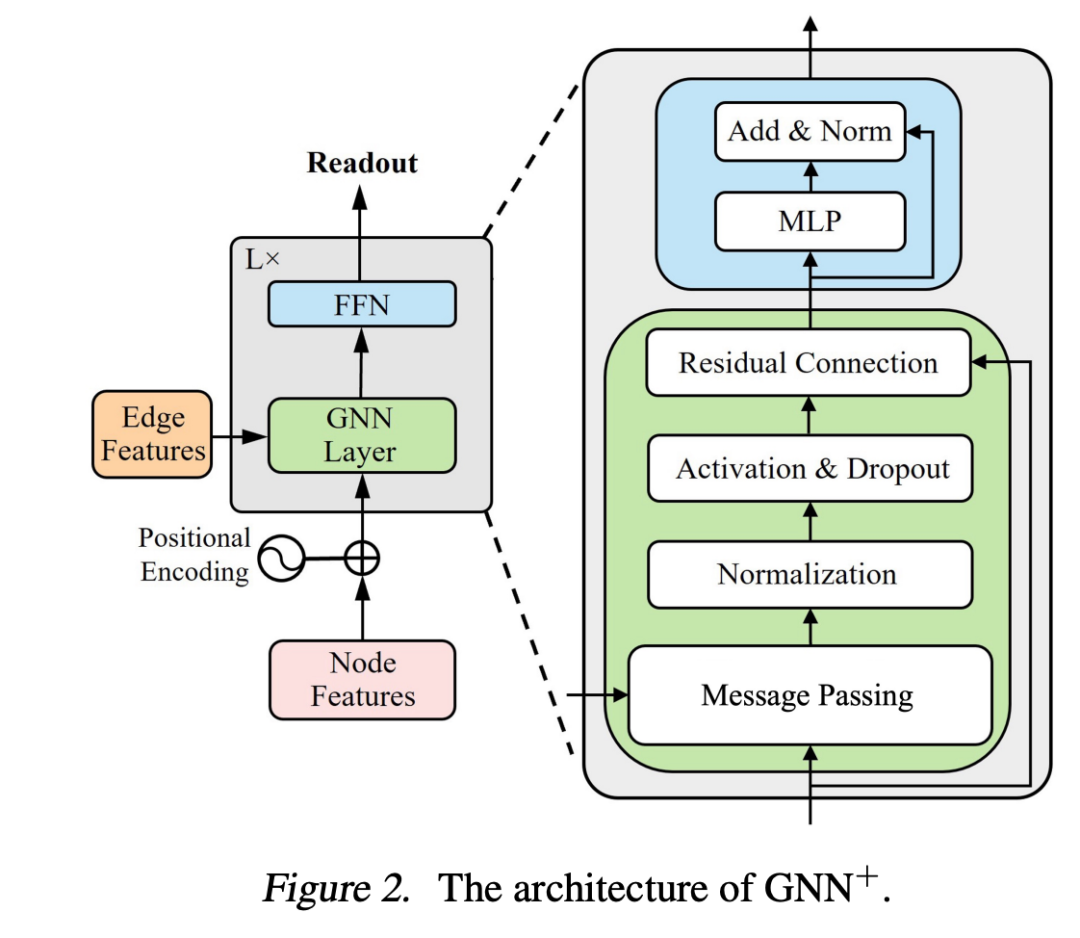
GNN+是一个统一增强框架,适用于经典GNNs。其核心在于在消息传递基础上,融入如下六项广泛使用的超参数技术,用以提升表示能力和训练稳定性:
- 边特征整合
:将边特征引入消息传递过程,有助于建模节点之间更丰富的结构关系,特别适用于分子图等边信息关键的任务 - 归一化
:对每层输出应用normalization,可缓解协变量偏移,提高训练稳定性与收敛速度 - Dropout
:在激活后对节点表示进行随机丢弃,有效抑制过拟合,并减少图中节点表示间的共适应性 - 残差连接
:在层间引入残差连接,有助于缓解深层GNNs中的梯度消失问题,使网络能够更有效地堆叠更多层 - 前馈网络(FFN)
:在每层后追加前馈网络,增强非线性变换能力,从而提升模型的表达能力 - 位置编码(PE)
:通过将节点的位置编码与其特征拼接,引入全图结构感知能力,弥补GNNs对全局信息建模的不足
3. 数据集与实验设置
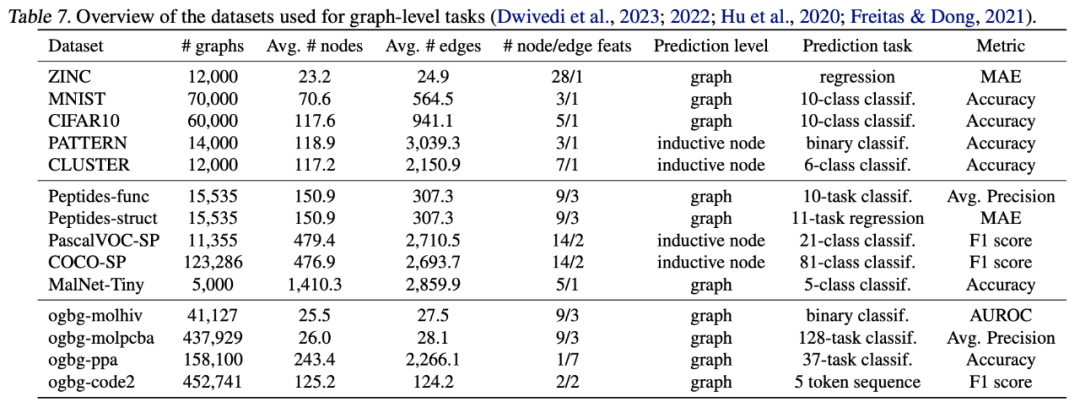
本研究在三个广泛使用的图级任务基准上进行全面评估:
- GNN Benchmark
[2](ZINC, MNIST, CIFAR10, PATTERN, CLUSTER) - Long-Range Graph Benchmark (LRGB)
[3,4](Peptides-func, Peptides-struct, PascalVOC-SP, COCO-SP, MalNet-Tiny) - Open Graph Benchmark (OGB)
[5](ogbg-molhiv, ogbg-molpcba, ogbg-ppa, ogbg-code2)
基准包括图回归、图分类等多类任务,覆盖从小规模分子图到百万级大图,测试模型的广泛适应性。
所有经典GNNs和GTs、GSSMs等模型均在相同的超参数搜索空间下训练,并使用标准划分与评估指标进行对比。
4. 实验结果分析
4.1 主性能对比
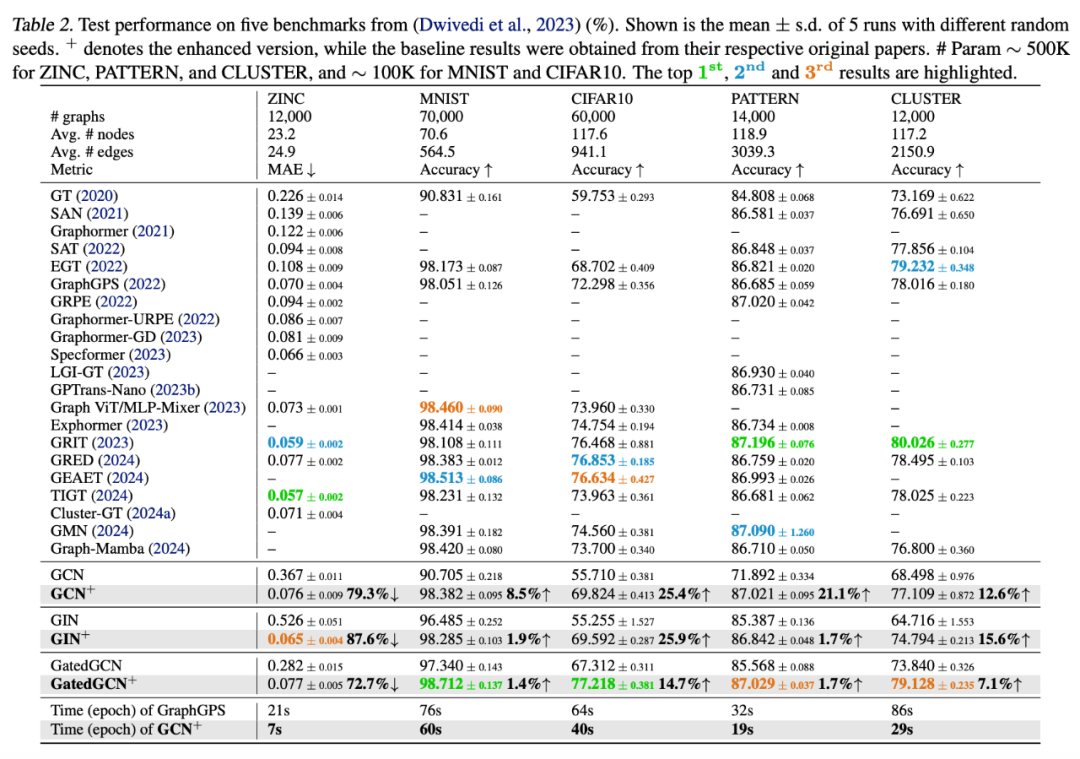 GNN Benchmark实验结果
GNN Benchmark实验结果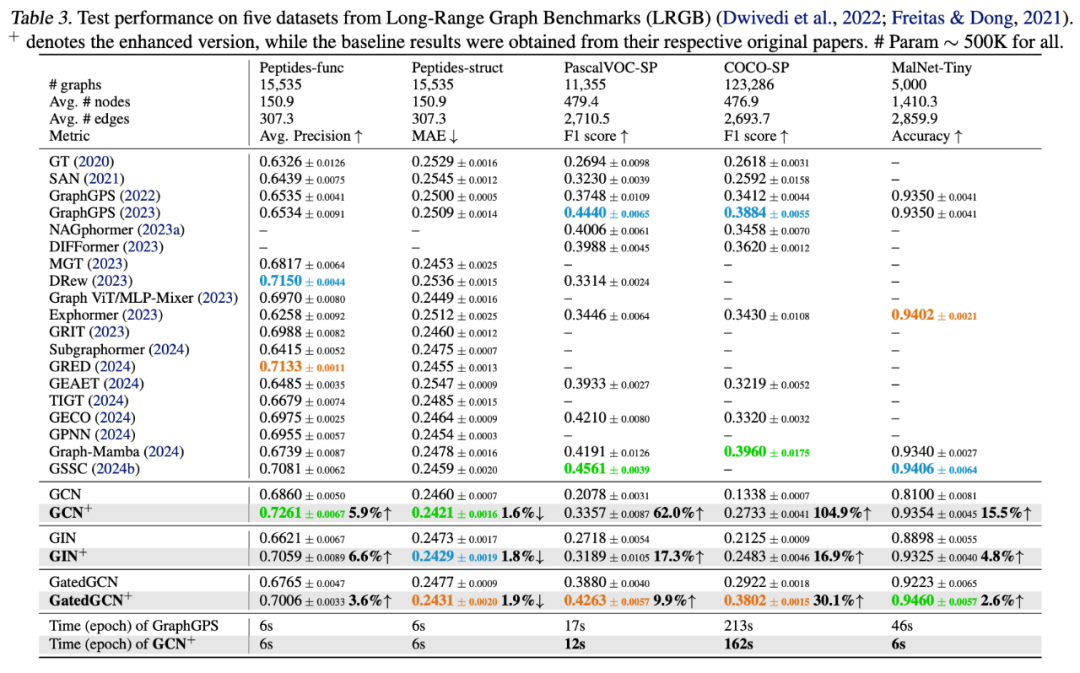
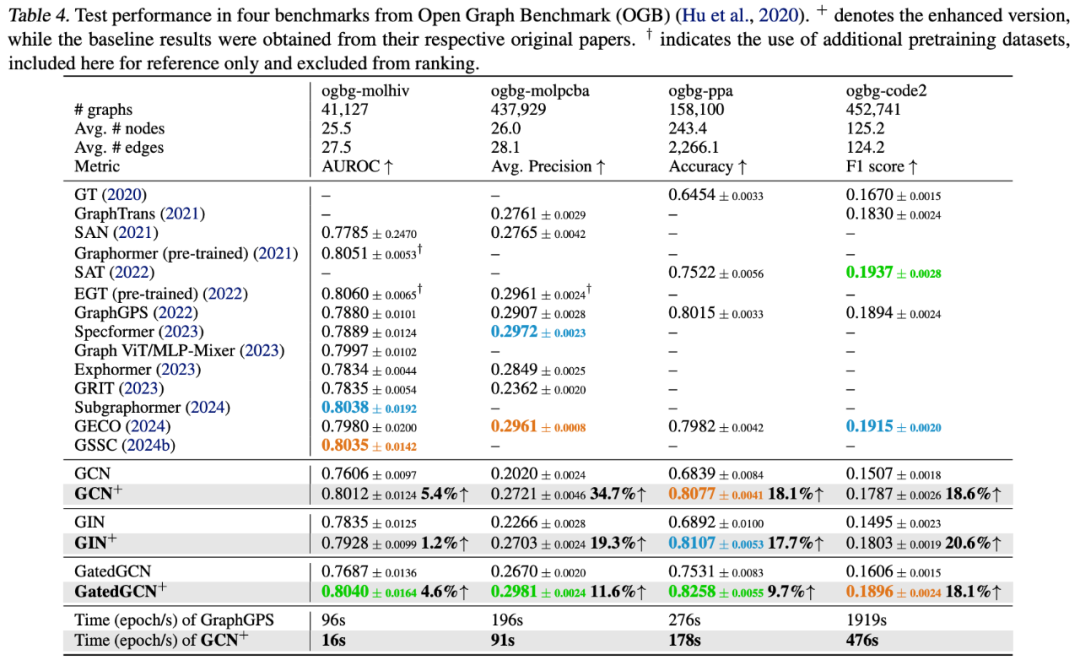
结果显示GCN+、GIN+和GatedGCN+三者在所有数据集均进入前三,其中8项任务取得第一,整体性能全面对标甚至超越主流GTs与GSSMs:
在GNN Benchmark中,GNN+在ZINC、PATTERN和CLUSTER任务上的性能提升尤为显著,GatedGCN+在MNIST与CIFAR10中超越GEAET与GRED等最新模型。 在LRGB基准下,GCN+在Peptides-func与Peptides-struct上取得最佳表现,GatedGCN+在MalNet-Tiny中排名第一,并在PascalVOC-SP和COCO-SP中稳居前三。 OGB基准实验进一步验证了GNN+在大规模图任务中的优势,GatedGCN+在四个数据集中三次排名第一,在ogbg-ppa上提升约9%,性能超过多个预训练GTs模型。
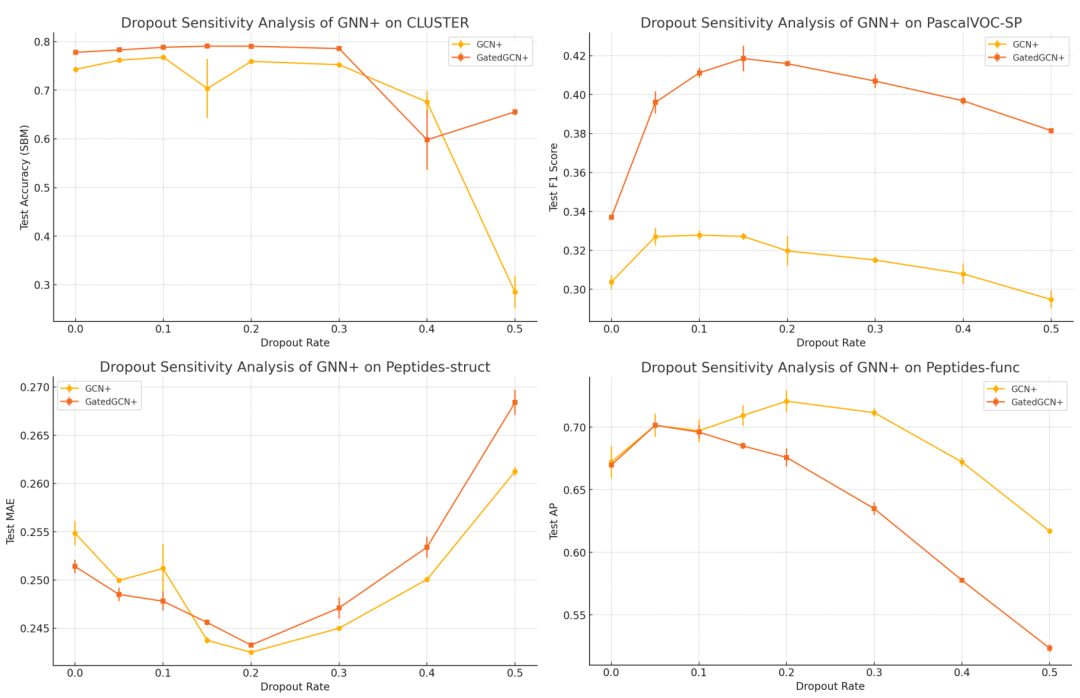
GNN+ 在 CLUSTER、PascalVOC-SP、Peptides-struct 和 Peptides-func 上的辍学率敏感性分析。
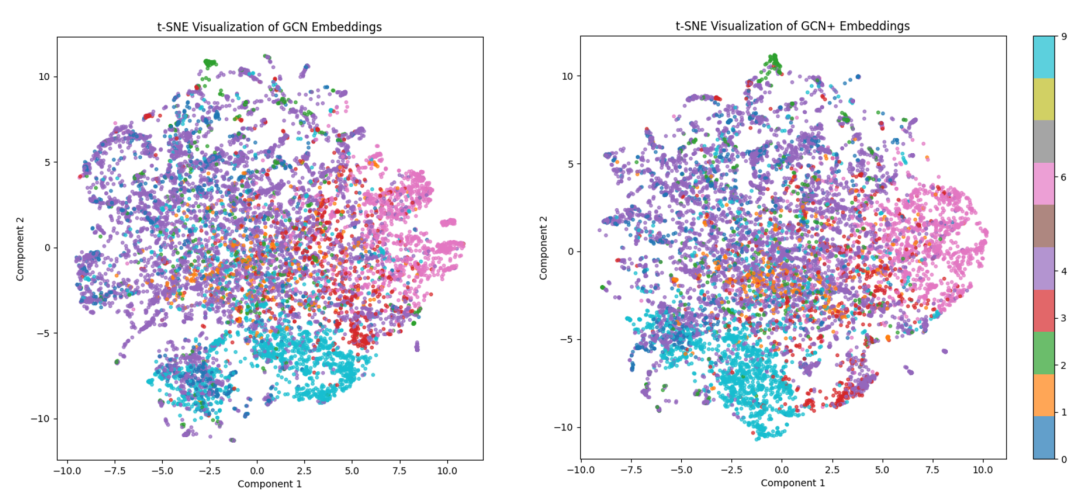
t-SNE 对 GCN(左)和 GCN+(右)学习到的图级嵌入进行可视化。颜色表示不同的类别。
4.2 消融研究
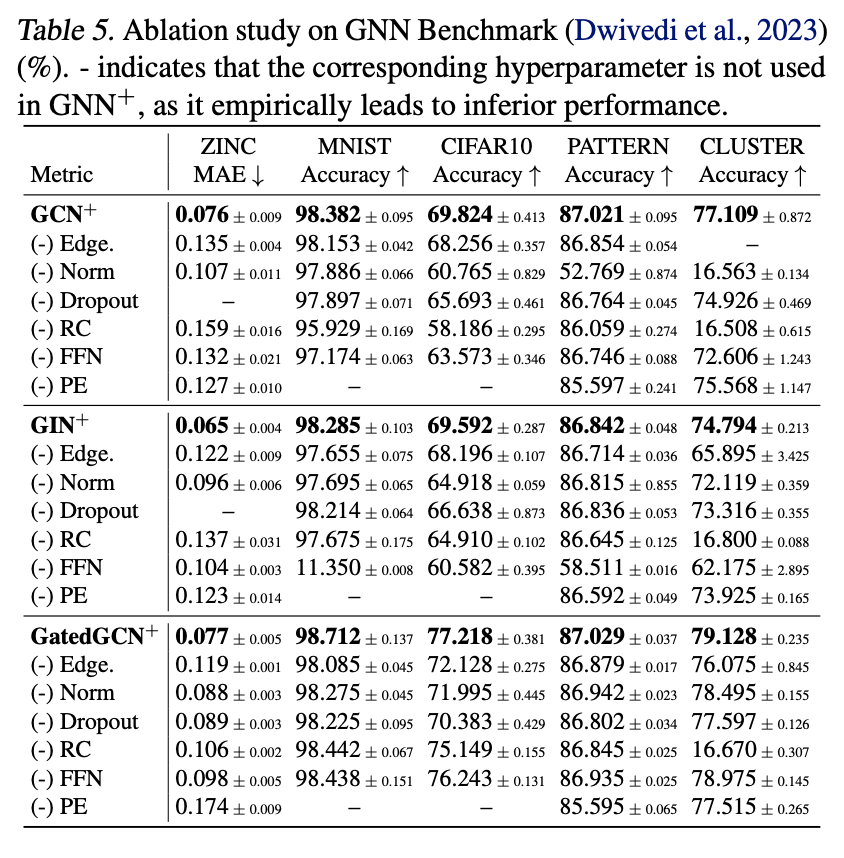
GNN Benchmark消融结果
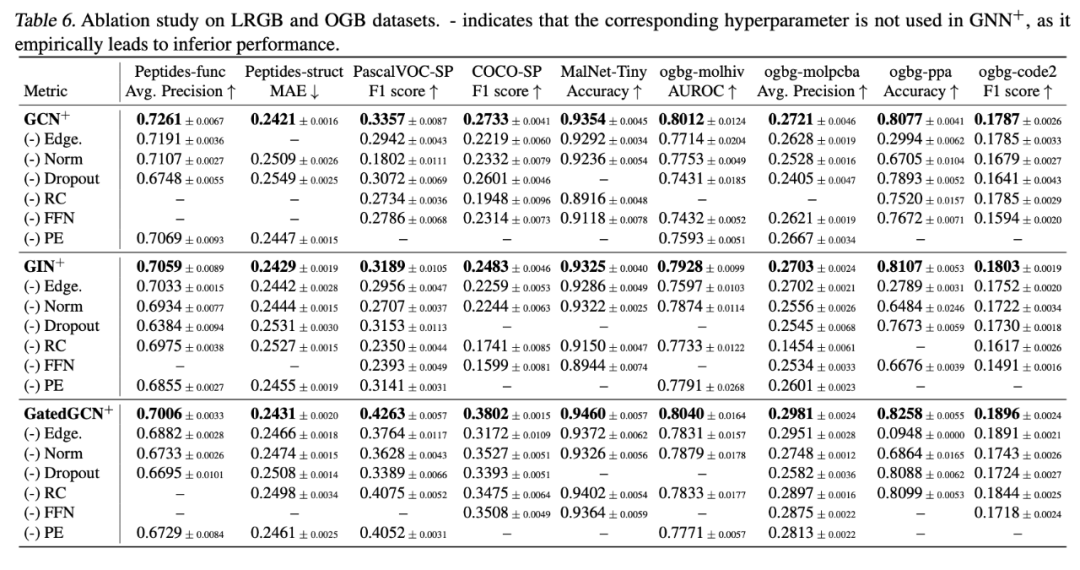 LRGB和OGB的消融结果
LRGB和OGB的消融结果
本研究对GNN+框架中的六个超参数模块(边特征、归一化、Dropout、残差连接、前馈网络、位置编码)进行逐一消融,结果表明各模块均为性能提升的关键组成:
消融观察1:边特征在分子图和图像超像素数据集中尤为重要
消融观察2:归一化在相对大规模数据集中影响更显著,而在小规模数据集中影响较小
消融观察3:Dropout对大多数数据集均有积极作用,且极低的dropout率已足够
消融观察4:残差连接通常是必要的,除非是在浅层GNNs处理小图时
消融观察5:FFN对GIN+和GCN+至关重要,显著影响其在各数据集上的表现
消融观察6:位置编码对相对小规模数据集尤为有效,而对大规模数据集影响较小
5. 总结
本文系统性重新审视了经典GNNs在图级任务中的表现,并提出统一增强框架GNN+。实验证明:经典GNNs在图级任务中不仅具备与最先进模型相媲美的能力,甚至在多个任务上取得最优结果,且训练效率更高。研究结果强烈挑战了“复杂图模型优于经典GNNs”的普遍认知,进一步强调合理设计与调优对于GNN性能释放的重要性。
参考文献
[1] Yuankai Luo, Lei Shi, and Xiao-Ming Wu. Classic GNNs are strong baselines: Reassessing GNNs for node classification. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024.
[2] Vijay Prakash Dwivedi, Chaitanya K Joshi, Anh Tuan Luu, Thomas Laurent, Yoshua Bengio, and Xavier Bresson. Benchmarking graph neural networks. Journal of Machine Learning Research, 24(43):1–48, 2023.
[3] Vijay Prakash Dwivedi, Ladislav Rampášek, Mikhail Galkin, Ali Parviz, Guy Wolf, Anh Tuan Luu, and Dominique Beaini. Long range graph benchmark. Advances in neural information processing systems, 2022.
[4] Scott Freitas and Yuxiao Dong. A large-scale database for graph representation learning. Advances in neural information processing systems, 2021.
[5] Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 2020.


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢