
点击蓝字
关注我们

海外智库观察
人工智能(AI)技术正在重塑全球治理结构,也加剧了中美战略竞争的复杂性。作为全球AI领域的领导者,中国与美国分别构建出两种高度差异化的治理模式:中国主张以“国家主导+平台配合”为主的集中型治理,美国则坚持“企业主导+透明协商”的分布式治理。在伦理审查、算法备案、模型安全、国际扩展等核心议题上,两国路径不断分化,却又在应对风险、规范输出、产业协同等方面展现出相似的政策趋向。为系统呈现中美人工智能治理的分歧与交汇,本文选取卡内基国际和平基金会与兰德公司于2024–2025年发布的代表性研究报告,结合百度、字节跳动、OpenAI等企业的政策实践,从制度逻辑、监管机制、国际布局与企业策略四大层面展开深入编译与对比分析。
卡内基国际和平基金会
Carnegie Endowment for International Peace推动更具全球包容性的可信人工智能议程
首先,报告深入分析了《生成式人工智能服务管理办法》所构建的核心监管体系。文件于2023年由中国网信办发布,其执行力度体现在两方面:一是平台责任明确化,要求所有向公众开放的AI服务必须备案,二是风险可控化,提出“事前评估+事中抽查+事后处罚”的动态审查体系。截至2024年底,中国已有119个模型完成备案流程,涵盖百度“文心一言”、阿里“通义千问”、商汤“日日新”、科大讯飞“星火”等多款主力模型。备案内容包括训练数据来源说明、输出风险说明、伦理影响评估报告、算法优化路线图,形成了一种“合规文档-行为追溯-监管接入”三层监管闭环。
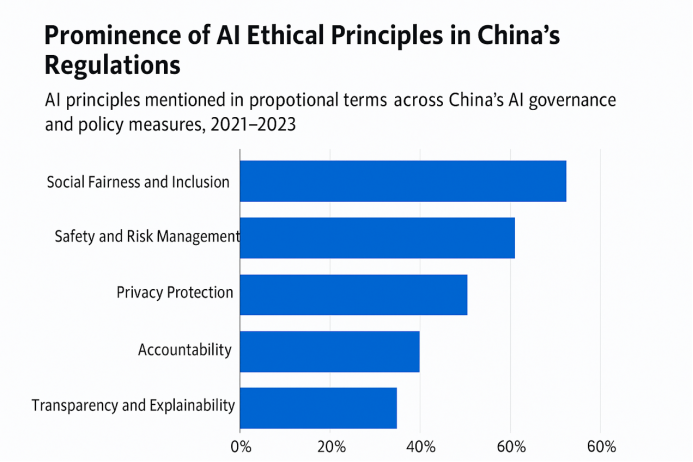
此外,卡内基报告还强调中国政府在AI治理中高度重视“伦理审查嵌入式机制”的制度建设。与美欧以行业自律为主不同,中国将伦理评估作为行政监管的一部分,纳入产品上线前置条件。例如,百度“文心一言”团队设有“AI伦理审查委员会”,由法律、心理学、语言学专家组成,每月召开评估会议,对模型输出的新风险类型(如种族偏见、精神误导、身份造假等)形成专题报告。2024年上半年,百度针对模型误导用户进行金融操作的问题,主动下线推广接口,并发布整改说明。阿里“通义千问”则启动“人类反馈标签工程”(RHF),组织300人团队参与长期打分,协助识别伦理边界模糊内容,如性别刻板印象、国家象征歪曲等。
报告还指出,中国不仅在国内构建监管体系,也正在利用其对外援助政策将AI治理工具包输出至发展中国家。以柬埔寨为例,2024年中国与柬政府合作建设AI监管实验室,输出算法评估模板、备案文档范式与训练数据标签体系;在坦桑尼亚,中国国家互联网信息办公室为其AI政务平台提供“舆情风险识别模块”和“内容透明度通报机制”。卡内基认为,这些扩展路径虽然在西方舆论中存有争议,但已成功获得一批全球南方国家的认可,形成以“执行力”为核心的AI治理出口战略。
最后,卡内基对中国治理模式进行评价:其优势在于统一、高效、执行力强,适合政治集中度高的发展中国家采纳;但其局限也十分明显,如对多样性文化表达空间压缩、透明度低、公众参与度不足等,导致其模式在欧盟与北美缺乏制度认同。报告呼吁西方国家在批评中国模式的同时,应正视全球多极治理现实,探索与中国在高风险领域(如深度伪造、自动武器部署)开展有限对话机制。
兰德公司
RAND Corporation中国的人工智能模型正在缩小差距——但美国的真正优势在于其他方面
然而,兰德指出,这种“模型逼近”的表象不能掩盖美国的结构性优势。首先是算力资源:美国仍然掌握全球约60%以上的高端AI GPU计算资源,NVIDIA于2025年推出的Blackwell芯片已成为全球训练主流芯片。兰德特别提到,中国由于受到美国芯片出口管制影响,尽管大力发展华为“昇腾”芯片与寒武纪生态,但在大型模型训练效率、生态兼容性与长期维护成本方面仍存在明显劣势。2024年,OpenAI训练GPT-4-Turbo仅耗时4.5周,而百度“文心一言4.0”所需时间超过9周。
其次,报告强调美国AI治理架构的透明度与多方参与特征是其软性实力的核心体现。2024年,美国国会通过《可信AI治理法案》,要求所有进入公众市场的AI模型必须提交“模型评估报告”“数据偏见说明书”与“红队测试结果”。OpenAI与Anthropic建立公开“风险交叉评估平台”,对用户可能遭遇的生成误导、AI幻觉和深度伪造建立量化评估标准。相比之下,中国虽然制定了完整的审查机制,但大多依赖企业内部自审,缺乏独立第三方验证程序与用户权利申诉通道。
除了模型能力与治理架构的比较,兰德报告进一步分析了中美在国际AI治理话语权上的博弈态势。文章指出,尽管中国在全球南方的影响力有所扩展,但在多边技术标准制定与伦理协议层面,美国依然掌握主导地位。2025年,美国借助OECD、G7与美欧科技理事会推动“可信AI”框架的全球签署,该框架涵盖算法可解释性、数据透明度、模型可追溯性与责任分担机制。截至2025年4月,已有42个国家正式采纳这一框架,成为国际技术贸易的“信任通行证”。OpenAI与微软、谷歌等公司所参与制定的“国际模型透明度评估协议”(IMTA),也成为多个国家引入AI审查机制的模板基础。
反观中国,虽然在联合国平台上提出了“全球AI发展倡议”,并与金砖国家启动“AI伦理合作沙箱”,但其影响力仍相对集中在亚非国家。报告分析了中国在埃塞俄比亚与柬埔寨的AI基础设施援助项目,尽管取得实地落地成果,但在制度输出方面更多依赖“规则嵌入式硬件部署”,而非真正意义上的规则共建。兰德认为,这种策略在短期内可实现“技术扩展”,但难以构建广泛制度同盟。在2025年欧盟AI法案修订草案中,中国主导的“风险导向评估”未被采纳,反而借鉴了美国推行的“用途分级+结果审查”结构,表明美式治理范式仍具较强制度吸附力。
此外,兰德指出,在应对AI风险(尤其是深度伪造、虚假舆论、自动决策失控)方面,美国正在推动多边治理新机制。例如,美日欧三方已于2025年3月启动“跨境红队协同计划”,建立模型交叉攻击共享库,用以测试系统脆弱性;而中国在此方面仍以国家内部管控为主,未建立跨国模型评估通用接口。这种技术治理“孤岛化”可能限制其长期制度吸引力。
原文链接:
2.https://www.rand.org/pubs/commentary/2025/05/chinas-ai-models-are-closing-the-gap-but-americas-real.html
文章检索及编译:吴思叡(华盛顿大学)
审核:赵杨博
排版:李森(北京工商大学)
终审:梁正、鲁俊群
往期回顾
清华大学人工智能国际治理研究院(Institute for AI International Governance, Tsinghua University,THU I-AIIG)是2020年4月由清华大学成立的校级科研机构。依托清华大学在人工智能与国际治理方面的已有积累和跨学科优势,研究院面向人工智能国际治理重大理论问题及政策需求开展研究,致力于提升清华在该领域的全球学术影响力和政策引领作用,为中国积极参与人工智能国际治理提供智力支撑。
新浪微博:@清华大学人工智能国际治理研究院
微信视频号:THU-AIIG
Bilibili:清华大学AIIG
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢