


Building Data Infrastructure for Truly Agentic AI
为真正自主的 AI 构建数据基础设施
Beyond Legacy Systems: The Infrastructure Demands of Intelligent Agents
超越传统系统:智能代理的基础设施需求
Today’s enterprise data architecture wasn’t designed for agentic AI. It was built for an era where data served as a historical record — static, compartmentalized, and primarily retrieved through explicit queries. As organizations rush to deploy increasingly sophisticated AI systems, many are discovering a fundamental mismatch between their existing data infrastructure and what truly intelligent agents require.
当今的企业数据架构并非为自主 AI 而设计。它是为数据作为历史记录的时代而构建的——静态、分割化,主要通过明确查询来检索。随着组织急于部署日益复杂的 AI 系统,许多人发现其现有数据基础设施与真正智能代理所需之间存在根本性不匹配。
What we’re witnessing isn’t merely a technical upgrade but a complete reconceptualization of how data infrastructure must function to support autonomous, context-aware systems that reason, plan, and evolve through experience.
我们所见证的不仅仅是技术升级,而是数据基础设施必须如何运作以支持自主、具有上下文感知能力的系统进行推理、规划和通过经验进化的全面重新概念化。
The Structural Impedance Mismatch
结构性阻抗不匹配
The limitations of traditional data infrastructure become apparent when examining how large language models (LLMs) interact with enterprise knowledge. Current systems operate on principles of deterministic execution with rigid schemas and transactional focus. These systems were “designed primarily for transactional accuracy and consistent record-keeping, not for the dynamic, relationship-rich understanding required by generative AI.”
传统数据基础设施的局限性在考察大型语言模型(LLMs)如何与企业知识交互时变得明显。当前系统基于确定性执行原则,具有僵化的模式并专注于事务性。这些系统“主要设计用于事务性准确性和记录一致性,而不是生成式 AI 所需的动态、关系丰富的理解。”
This creates what engineers describe as a “structural impedance mismatch” between neural and symbolic components. Consider a standard REST API interaction:
这造成了工程师所说的“神经网络与符号组件之间的结构阻抗不匹配”。考虑一个标准的 REST API 交互:
{
"user_id":42,
"transaction_type":"purchase",
"amount":79.95,
"timestamp":"2025-04-21T14:30:00Z"
}
If a single bracket is misplaced or a required field omitted, the entire transaction fails. This strict enforcement of structure creates reliability at the expense of flexibility — precisely the opposite of what agentic systems need to operate effectively across complex, ambiguous enterprise environments.
如果单个括号放置错误或遗漏了必需字段,整个事务就会失败。这种对结构的严格执行在牺牲灵活性的同时创造了可靠性——这正是自主系统在复杂、模糊的企业环境中有效运行所需要相反的东西。
Vector Retrieval: A Transitional Technology with Inherent Limitations
向量检索:一种具有内在局限性的过渡技术
Many organizations have implemented Retrieval-Augmented Generation (RAG) systems using vector embeddings. While this represents an improvement over pure parametric approaches, research demonstrates fundamental limitations when applied to complex enterprise environments:
许多组织已经实施了使用向量嵌入的检索增强生成(RAG)系统。虽然这比纯参数化方法有所改进,但研究表明,将其应用于复杂的企业环境时存在根本性局限性:
Semantic gaps between query vectors and relevant content vectors
查询向量与相关内容向量之间的语义差距
Granularity tradeoffs between document-level representations (lacking precision) and sentence-level chunks (fragmenting context)
文档级表示(缺乏精确性)与句子级片段(割裂上下文)之间的粒度权衡
Reasoning limitations when synthesizing information across multiple documents
跨多文档综合信息时的推理局限性
Sense-making challenges in interpreting complex contexts requiring multi-source integration
在需要多源整合的复杂情境中解读的挑战
Associativity gaps in forming transitive relationships across separate entries
形成跨不同条目的传递关系时的结合性差距
These aren’t implementation issues but architectural limitations. Research shows vector-based systems lose up to 12% accuracy when scaled to 100,000 pages, while graph-based approaches maintain performance with only 2% degradation at similar scales.
这不是实现问题,而是架构限制。研究表明,基于向量的系统在扩展到 10 万页时,准确率会下降高达 12%,而基于图的方案在相似规模下仅下降 2%即可保持性能。
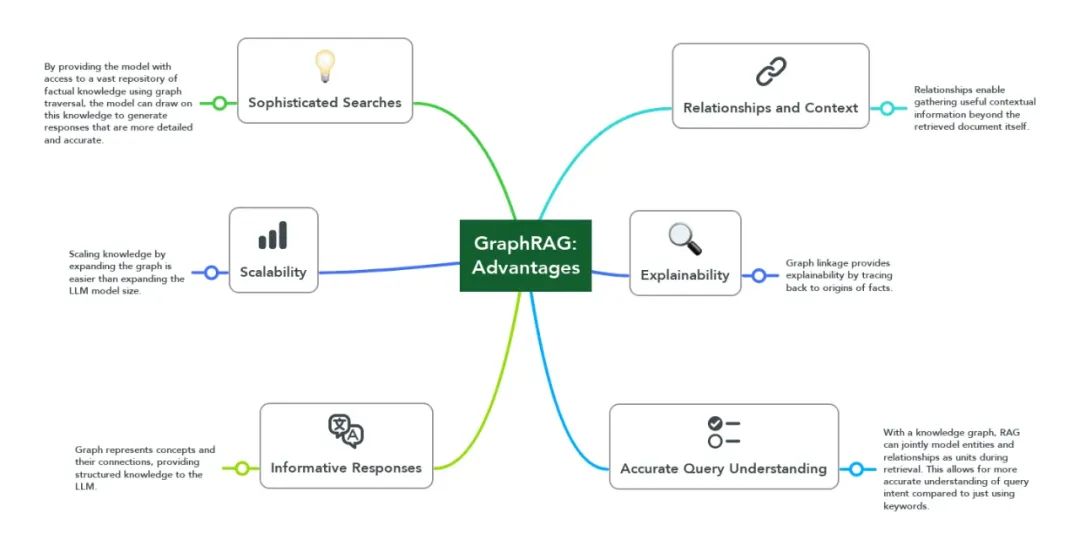
The Graph Advantage: Knowledge as Relationships
图的优势:知识即关系
What does an agentic-ready infrastructure look like? All evidence points toward graph-based architectures as the optimal foundation. Unlike vector embeddings that flatten relationships into statistical similarities, graph structures explicitly model connections between concepts.
一个适合自主智能的基础设施看起来是怎样的?所有证据都指向基于图的架构作为最佳基础。与将关系扁平化为统计相似性的向量嵌入不同,图结构明确地建模了概念之间的连接。
This approach offers three critical advantages:
这种方法提供了三个关键优势:
1. Multi-hop Reasoning
多跳推理
Graphs enable systems to connect information across documents through explicitly defined relationship paths. When a financial analyst asks about “the impact of the new product launch on Q3 projections,” a graph-based system can navigate from product specifications to manufacturing costs to pricing strategies to revenue projections — even when this information exists in different documents across different departments.
图能够通过明确定义的关系路径连接不同文档中的信息。当一位财务分析师询问“新产品发布对第三季度预测的影响”时,基于图的系统可以从产品规格导航到制造成本,再到定价策略,最后到收入预测——即使这些信息分散在不同的部门的不同文档中。
2. Context Preservation
上下文保留
Graph structures naturally preserve context across interactions, addressing what practitioners call the “contextual amnesia” problem in traditional AI systems. By maintaining relationship networks rather than isolated chunks, the system develops an increasingly sophisticated understanding of how information interconnects.
图结构天然地在交互中保留上下文,解决了传统 AI 系统中的“上下文遗忘”问题。通过维护关系网络而非孤立的数据块,系统逐渐发展出对信息相互关联的复杂理解。
3. Cross-Domain Navigation
跨域导航
Perhaps most importantly, graph architectures enable navigation across organizational boundaries. The system can identify tools operating on similar entities or domains even when they exist in different departments, enabling truly enterprise-wide problem-solving capabilities.
最重要的是,图架构能够跨越组织边界进行导航。系统可以识别在不同部门中操作相似实体或领域的工具,从而实现真正企业级的问题解决能力。
Beyond Storage: The Cognitive Architecture of Agentic Systems
超越存储:自主系统的认知架构
An effective agentic data infrastructure extends far beyond static knowledge representation. It integrates specialized cognitive functions through components that mirror human information processing:
一个有效的自主数据基础设施远不止静态知识表示。它通过模拟人类信息处理功能的组件来整合专门认知功能:
Specialized Memory Structures
专用记忆结构
Episodic memory: Captures experiential events with complete contextual metadata
情景记忆:捕获具有完整上下文元数据的经验事件
Semantic memory: Constructs entity-relationship networks encoding conceptual knowledge
语义记忆:构建实体关系网络来编码概念知识
Procedural memory: Implements linear chains representing process steps or action sequences
程序性记忆:实现表示流程步骤或动作序列的线性链
Temporal memory: Employs timestamped relationships tracking information evolution
时序记忆:采用带时间戳的关系来跟踪信息演化
Planning Mechanisms
规划机制
Graph-based planning transforms complex task execution by representing workflows as directed acyclic graphs (DAGs) rather than linear sequences. This enables:
基于图的规划通过将工作流表示为有向无环图(DAG)而非线性序列来转换复杂任务的执行。这能够实现:
Parallel execution of independent subtasks
独立子任务的并行执行
Graceful recovery through explicit dependency modeling
通过显式依赖建模实现优雅恢复
Encapsulated sub-workflows for consistency and reuse
封装子工作流以实现一致性和可重用性
Causal graph integration for domain-specific understanding
因果图集成以实现特定领域的理解
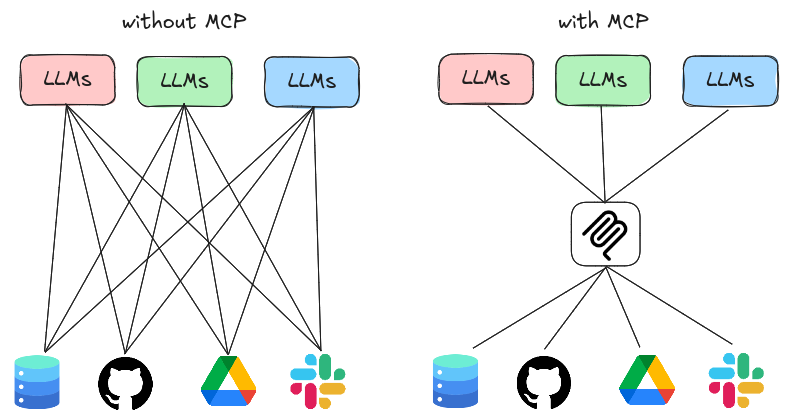
Tool Orchestration
工具编排
The Model Context Protocol (MCP) provides a standardized communication framework for AI-to-tool interactions, but requires enhancement through semantic orchestration layers that model:
模型上下文协议(MCP)为 AI 与工具的交互提供了标准化的通信框架,但需要通过语义编排层进行增强,这些层建模了:
Hierarchical relationships between tools
工具之间的层次关系
Functional dependencies between components
组件之间的函数依赖关系
Entity relationships connected to enterprise data
与企业数据关联的实体关系
Domain associations across business units
跨业务单元的领域关联
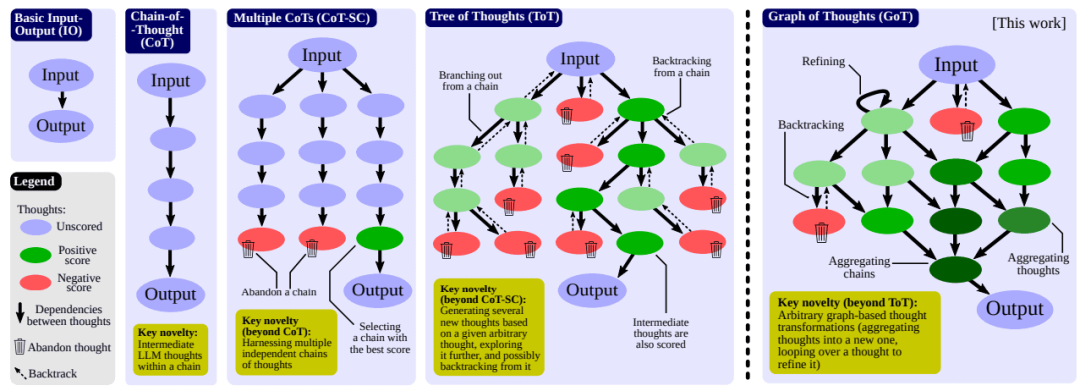
Reasoning Engines
推理引擎
Graph-based reasoning transforms dynamic thinking processes into structured computational pathways that adapt to problem complexity in real-time:
基于图的推理将动态思维过程转化为适应实时问题复杂性的结构化计算路径:
Chain of Thought (CoT) for sequential reasoning
思维链 (CoT) 用于顺序推理
Tree of Thoughts (ToT) for exploring multiple directions
思维树 (ToT) 用于探索多个方向
Graph of Thoughts (GoT) for arbitrary connections
思维图 (GoT) 用于任意连接
Adaptive decomposition for nested subgraphs
自适应分解用于嵌套子图
Self-Evolution: The Trillion-Dollar Moat
自我进化:万亿美元的护城河
Perhaps the most transformative aspect of proper agentic infrastructure is its capacity for continuous improvement through what Konstantine Buhler describes as the “self-evolution data flywheel” — where usage generates insights that enhance knowledge structures.
或许,正确代理基础设施最具变革性的方面在于其通过康斯坦丁·布勒尔描述的“自我进化数据飞轮”实现持续改进的能力——即使用生成洞察,从而增强知识结构。
This creates a competitive advantage that static systems cannot match. While traditional systems depreciate over time, becoming increasingly disconnected from operational reality, agentic systems appreciate through:
这创造了静态系统无法匹敌的竞争优势。传统系统随着时间的推移而贬值,越来越脱离实际操作现实,而代理系统则通过以下方式增值:
Knowledge representation that evolves through subject-relationship-object triples
通过主谓宾三元组演变的知识表示
Memory persistence mechanisms that selectively incorporate new information
选择性地整合新信息的记忆持久机制
Hierarchical processing with tiered knowledge structures evolving at different rates
分层处理,采用不同速率演化的分层知识结构
Feedback propagation pathways for optimization signals to traverse the system
优化信号在系统中传播的反馈路径
From Theory to Implementation: Making It Work in Practice
从理论到实践:使其在实践中发挥作用
Implementing these architectural principles doesn’t require unlimited computational resources. Recent optimization techniques make graph-based approaches practical for most organizations:
实现这些架构原则并不需要无限的计算资源。最近的优化技术使基于图的方法对大多数组织来说都切实可行:
LazyGraphRAG reduces preprocessing costs by 99% with modest query latency increases (15–25%)
LazyGraphRAG 通过适度增加查询延迟(15-25%)将预处理成本降低了 99%
KET-RAG maintains 95% of retrieval performance while reducing computational costs by 75–85%
KET-RAG 在保持 95%检索性能的同时,将计算成本降低了 75-85%
MiniRAG requires only 25% of traditional storage footprints
MiniRAG 仅需传统存储空间的 25%
Inference-Time Logical Reasoning enables complex queries with negations and conjunctions
推理时逻辑推理功能支持包含否定和合取的复杂查询
Organizations implementing these approaches have achieved up to 46.2% improvement on complex reasoning tasks that conventional systems struggle with.
采用这些方法的组织在传统系统难以处理的复杂推理任务上实现了高达 46.2%的改进。
The Enterprise Imperative
企业使命
This architectural transformation directly connects to Harvard Business Review’s findings on the data leader’s agenda for 2025. Organizations with mature generative AI implementations demonstrate stronger data foundations, clearer ownership structures, and more strategic prioritization — all elements supported by agentic infrastructure.
这种架构转型直接关联到《哈佛商业评论》关于 2025 年数据领导者议程的研究发现。实施成熟生成式 AI 的组织展现出更强大的数据基础、更清晰的所有权结构和更战略性的优先级排序——所有这些要素都由自主基础设施所支持。
As Seth Earley, founder and CEO of Earley Information Science, emphasizes: “If organizations aren’t getting good results with AI and gen AI, it’s because they don’t understand the fundamentals. Going from hype to value means focusing on use cases and specific outcomes and getting your data and data reference architecture right for that.”
正如 Earley 信息科学的首席执行官兼创始人 Seth Earley 所强调:“如果组织在 AI 和生成式 AI 方面没有取得良好成果,那是因为他们不理解基础知识。从炒作到价值意味着要专注于用例和具体成果,并确保为这些用例配置正确的数据和数据参考架构。”
Conclusion: Documentation vs. Understanding
结论:文档与理解
The agentic data infrastructure represents a fundamental reconceptualization of how AI systems relate to information. Where legacy stacks treated data as static records to be queried, agentic infrastructure creates dynamic knowledge networks that evolve through experience.
自主数据基础设施代表了 AI 系统与信息关系的基本概念重构。在传统技术栈中,数据被视为静态记录以供查询,而自主基础设施则创建动态知识网络,这些网络通过经验不断演进。
The contrast is stark: legacy infrastructure was built for documentation; agentic infrastructure is designed for understanding. As AI capabilities advance, this architectural distinction will increasingly determine which systems can deliver genuine business value and which remain limited by their foundational constraints.
对比鲜明:传统基础设施是为了文档而构建;而能动式基础设施是为了理解而设计。随着 AI 能力的提升,这种架构差异将越来越决定哪些系统能够提供真正的商业价值,哪些系统仍受其基础限制的制约。
Organizations that recognize this shift early and begin architecting their data infrastructure for agentic AI won’t just deploy more effective systems — they’ll create self-reinforcing competitive advantages through continuous, experience-driven improvement that rivals simply cannot replicate.
那些早早认识到这一转变并开始为其自主的 AI 构建数据基础设施的组织,不仅会部署更有效的系统——它们将通过持续、经验驱动的改进创造自我强化的竞争优势,而竞争对手根本无法复制。
参考资料
https://hbr.org/sponsored/2024/11/scaling-generative-ai-for-value-data-leader-agenda-for-2025
https://www.linkedin.com/pulse/usage-moat-konstantine-buhler-frufc/?trackingId=BCw3OIk8SvaaL1334jMcvg%253D%253D
https://www.linkedin.com/posts/anthony-alcaraz-b80763155_why-graphs-are-becoming-the-foundation-for-activity-7305879366322843648-9MZz?utm_source=share&utm_medium=member_desktop&rcm=ACoAACVPJNABGwj10wdhrBRfHh4644U440jiziM



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢