
近日,清华大学智能产业研究院(AIR)-北京智源人工智能研究院“健康计算联合研究中心” 发布 AI驱动的超高通量药物虚拟筛选平台DrugCLIP https://www.drugclip.com , 该平台系统由AIR 兰艳艳教授团队研发。 DrugCLIP 在筛选速度上对比传统方法实现了百万倍提升,同时在预测准确率上也取得显著突破。依托该平台团队打通了从AlphaFold结构预测到药物发现的关键通道,首次完成了覆盖人类基因组规模的药物虚拟筛选,为后AlphaFold时代的创新药物发现带来了新的可能性。
药物研发长期面临“高风险、高投入、低成功率”的难题,在靶点发现与先导化合物筛选阶段,受限于传统工具的计算能力,绝大多数潜在靶点和化合物仍未被充分探索。人类基因组编码有2万余个蛋白,每个蛋白可能包含多个结合口袋,然而现有药物靶点开发只覆盖其中小部分。另一方面,理论上可合成的小分子数量高达10^60,远超现有药物化合物库规模。以筛选1万个蛋白质靶点,每个靶点对应10⁹个候选分子候选为例,需完成约10¹³次蛋白-配体打分。即便使用当前最先进的分子对接工具,也需数百年才能完成,严重制约了新靶点与新分子之间匹配的探索效率。如何在如此浩瀚的生物与化学空间中精准高效地发现活性化合物,是当前创新药物研发面临的核心挑战。
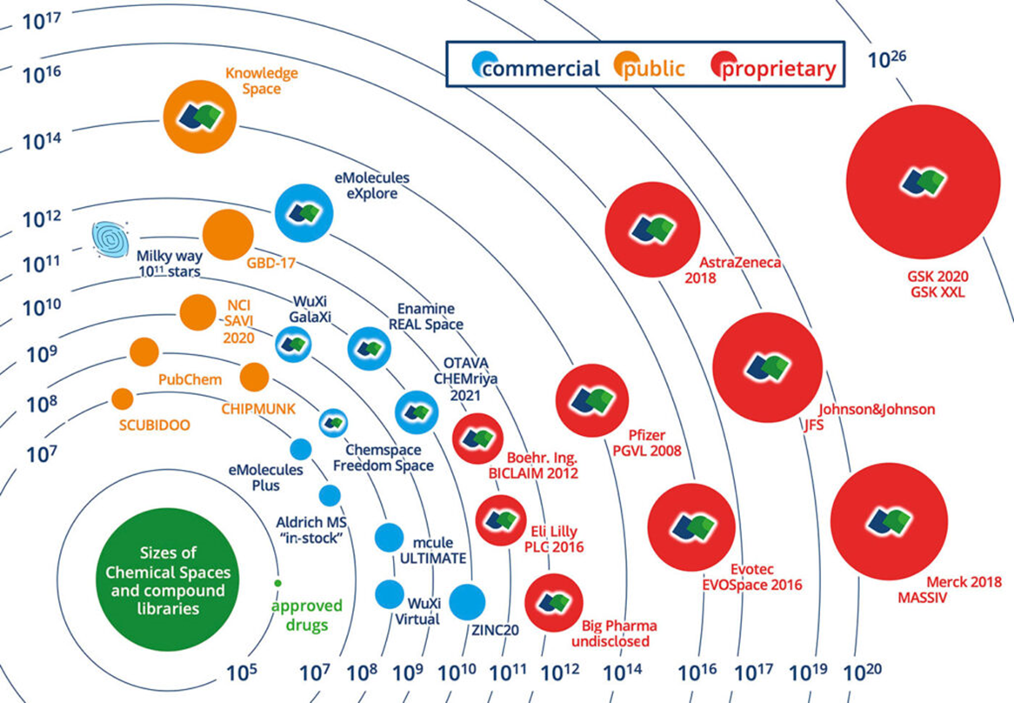
图:化学空间大小示意图(引用:Gastreich, M. BioSolveITDrugSpace2022)
为突破虚拟筛选规模瓶颈,DrugCLIP创新性地构建了蛋白口袋与小分子的“向量化结合空间”,将传统基于物理对接的筛选流程转化为高效的向量检索问题。该模型结合对比学习、3D结构预训练与多模态编码技术,能在三维结构层面精准建模蛋白-配体间的相互作用。训练后的高潜力分子将自然聚集于目标蛋白口袋的向量邻域,能够有效支撑快速的大规模虚拟筛选。依托这一机制,DrugCLIP在128核CPU + 8张GPU的计算节点上,能实现毫秒级打分与万亿级日吞吐能力,筛选100万个候选分子仅需0.02秒,日处理能力达31万亿次,对比传统方法实现了百万倍提升。
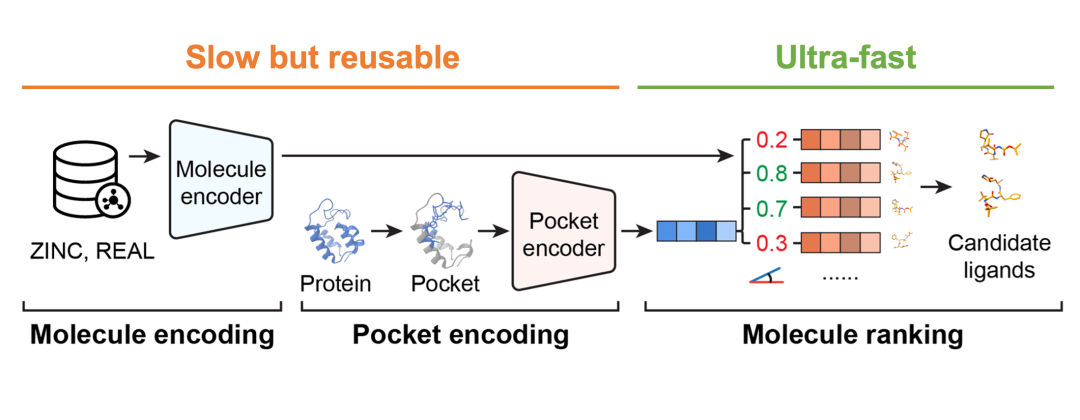
图:DrugCLIP编码及检索流程
DrugCLIP在多个公开数据集上表现优异。以DUD-E与LIT-PCBA为例,DrugCLIP在BEDROC、EF1%、AUC等关键指标上均优于传统对接工具(如AutoDock Vina)及近年来代表性AI方法,展现出在早期药物发现方面的领先能力。
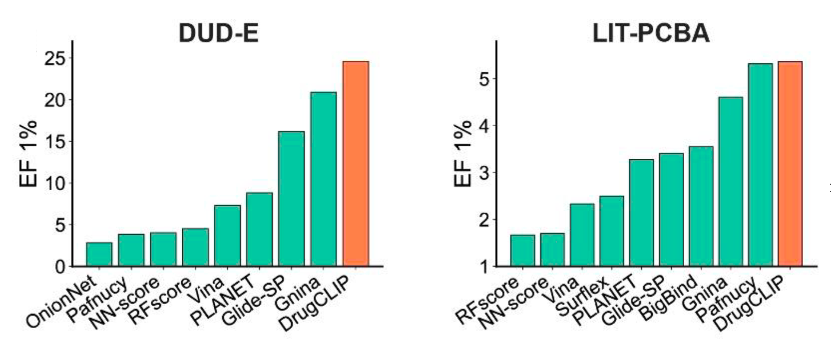
图:公共数据集评测效果对比
团队与清华大学闫创业教授团队合作,在去甲肾上腺素转运体(NET)的临床相关靶点上开展了系列生物实验验证。 NET是抑郁症、注意缺陷多动症以及疼痛等疾病的重要靶点,目前虽然有多款抑制剂已经上市,但在选择性等方面仍然有巨大的优化空间。团队使用DrugCLIP模型从160万个候选分子中筛选出约100个高评分分子,同位素配体转运实验检测显示其中15%为有效抑制剂,其中12个分子结合能力优于现有抗抑郁药物安非他酮。相关复合物结构已通过冷冻电镜解析,进一步验证了DrugCLIP筛选结果的生物学可信度。
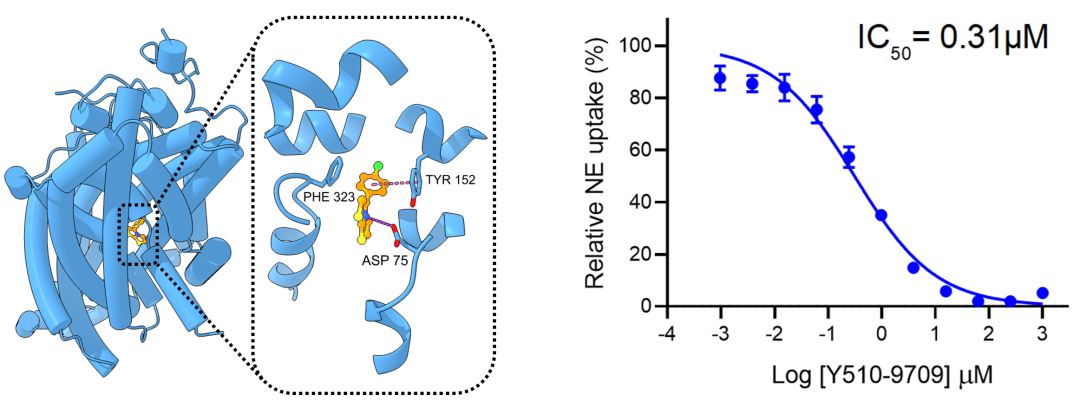
图:冷冻电镜解析的NET与筛选到的分子复合物结构与对应化合物的IC50
特别的是,DrugCLIP支持对AlphaFold预测的蛋白结构和apo(无配体)状态下的蛋白口袋进行筛选,扩大了其在真实药物发现场景中的适用性。团队和清华大学刘磊教授团队合作针对E3泛素连接酶TRIP12(thyroid hormone receptor interactor 12)进行了虚拟筛选与实验验证。TRIP12在肿瘤细胞中促进重要抑癌基因TP53的降解,因此其抑制剂可能有抗肿瘤的潜力。TRIP12也参与降解葡糖脑苷脂酶(glucocerebrosidase),进而引发α-突触核蛋白(α-synuclein)的积累和聚积,因此其抑制剂对帕金森综合征等神经退行性疾病有潜在疗效。TRIP12发挥酶活性的HETC结构域目前尚无任何文献报导的抑制剂与可供虚拟筛选使用的实验结构。团队使用DrugCLIP模型从160万个候选分子中高通量筛选出约50个高评分分子,SPR实验证实其中10个分子与TRIP12有结合能力,两个亲和力较高的分子也对TRIP12的泛素连接酶活性有一定的抑制活性。
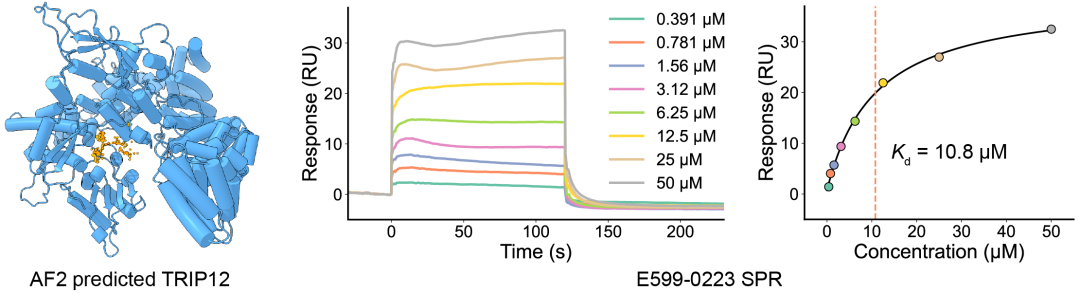
图:AlphaFold2预测的TRIP12结构与筛选获得的其中一个化合物的SPR曲线
构建人类蛋白组筛选数据库,推动后AlphaFold时代药物发现新范式
依托DrugCLIP,团队首次完成了人类基因组规模的虚拟筛选项目,覆盖约1万个蛋白靶点、2万个结合口袋,分析超过5亿个小分子,富集出200万余个高潜力活性分子,构建了目前已知最大规模的蛋白-配体筛选数据库。该数据库已面向全球科研社区开放,为基础研究与早期药物发现提供了强大数据支持。DrugCLIP平台 https://www.drugclip.com 现已免费开放,用户无需本地部署,通过网页上传蛋白结构即可启动筛选任务。平台集成口袋/分子编码、向量检索、可视化与结果分析等功能,支持多种分子库调用与自定义上传,广泛适用于科研机构与企业用户。
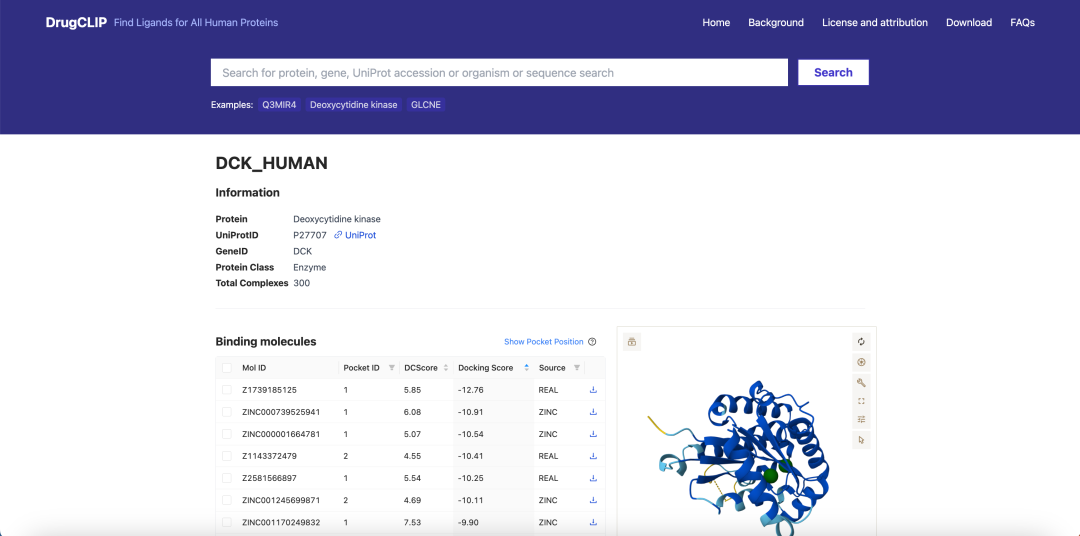
图:人类基因组规模的蛋白虚拟筛选数据库
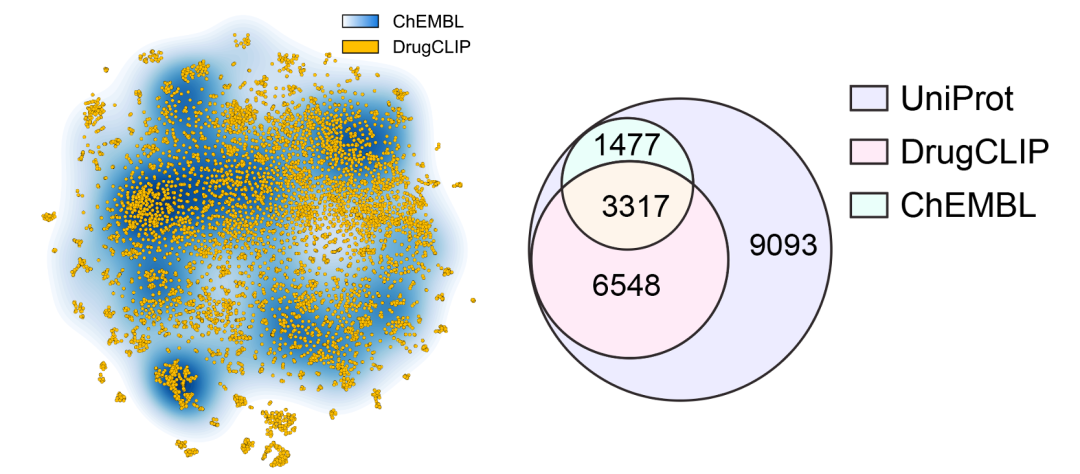
图:人类基因组规模筛选项目覆盖的蛋白数目与现有数据库对比(左:覆盖的靶蛋白空间,使用ESM1b编码并进行t-SNE降维可视化;右:覆盖的UniProt ID数量)
未来,DrugCLIP将与科研产业生态合作伙伴深度合作,在抗癌、传染病、罕见病等方向加速新靶点与First-in-class药物的发现。团队将持续优化引擎性能、拓展支持模态,助力构建一个更智能、高效与普惠的全球药物创新生态。
-------------------------------------------------------------------------------
机构介绍:“清华(AIR)- 智源健康计算联合研究中心” 由清华大学智能产业研究院(AIR)与北京智源人工智能研究院于2021年联合成立,致力于应用最前沿的人工智能技术赋能健康管理、精准诊疗与新药研发,以数据驱动的全新科研范式突破生命健康领域核心技术,服务人类健康福祉。清华(AIR)首席研究员兰艳艳、智源健康计算研究中心负责人叶启威任联合研究中心主任。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢