

【该工作由南京大学自然语言处理组和华为翻译中心合作完成,论文链接:https://arxiv.org/pdf/2502.19941,代码:https://github.com/NJUNLP/njuqe】
01
研究动机
机器翻译质量评估(Quality Estimation,QE)任务是旨在没有参考译文的情况下,仅依靠源语句(SRC)评估机器翻译语句(MT)的质量[1]。多维质量标准(Multidimensional Quality Metric, MQM)[2]标注兼具细粒度和可解释性,所以它已成为近年来QE领域的主要标准。如表1所示,MQM不仅能够识别错误短语,还在二分类词级别标签(OK/BAD)的基础上,进一步标注由BAD单词组成的错误短语的严重程度(MINOR/MAJOR/CRITICAL),这些标注信息最终会被聚合成句级别标签(Score)。
表1: MQM数据样例。测试时,参考译文 (REF) 不可用

但是获取这种细粒度的MQM标注需要耗费大量人力,因此相关数据集通常规模较小且仅限于特定语言对。因此,研究者逐渐转向利用平行语句合成MQM数据,主要包括生成合成翻译语句和生成合成标签两个部分。
早期方法多使用NMT模型直接生成合成翻译,再利用基于词汇重叠的TER工具,与参考译文对齐获得粗粒度标签[3]。但由于TER忽略了语义信息,常将语义等价但表述不同的词误标为BAD,从而引入大量假负例。
为减少标签噪音,我们在先前研究中提出约束束搜索(Constrained Beam Search, CBS)方法 [4],通过在合成翻译语句生成过程中保留参考译文的主要结构,有效降低结构多样性。这显著提升了OK标签的准确性。然而,该方法仍局限于OK/BAD二分类,难以满足MQM标准对错误严重程度的细粒度要求。
为解决这一问题,近期方法如 MQMQE [5] 和 InstructScore [6] 开始探索更细粒度的标签生成方式。图1展示了MQMQE方法,该方法通过在参考译文中随机遮掩文本片段,基于翻译模型对于遮掩部分概率分布进行负采样替换这些片段,并依据采样概率标注所对应的错误严重程度。InstructScore方法指导GPT-4基于参考译文生成含有翻译错误的翻译语句,并标识翻译错误对应的位置。
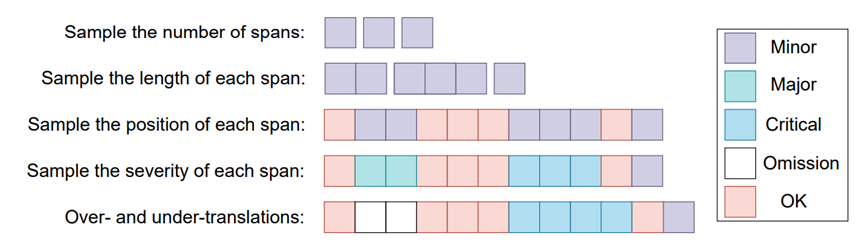
图1: MQMQE方法示意
尽管上述方法取得一定成效,但其生成的数据分布与真实数据之间仍存在显著偏差[7]。这种分布偏移问题不仅会导致质量评估性能下降,还会影响下游人类偏好优化[8]。具体而言,MQMQE的负采样策略导致合成翻译语句流畅性不足(随机掩码往往会破坏完整短语结构),且其合成标签与人类偏好存在偏差(翻译模型对自身输出往往过度自信)。虽然InstructScore能生成流畅的合成翻译语句和精确的标签,但其产生的错误类型与先进翻译模型的典型错误模式存在差异,且依赖强大的闭源大语言模型需要耗费大量时间和资金成本。
因此问题的关键在于如何缓解合成MQM数据中的分布偏移问题。
02
贡献
1.我们提出了一个新颖的合成MQM数据框架DCSQE(Distribution-Controlled Data Synthesis for QE)。它结合了约束束搜索算法、监督信号引导、对齐MQM标准和模型多样性策略极大的缓解了分布偏移问题。
2.经过评估我们在EN-DE、ZH-EN、HE-EN三个语言对的有监督与无监督设定下进行实验,结果显示DCSQE显著优于基线方法。
3.分析实验中,我们提供了对合成数据生成的一些见解,包括尽可能地利用已有的正确监督信号、模型很难标注自身的输出、多样化的生成有助于提升数据质量等,这些见解有望为通用奖励模型的合成数据带来启发,
03
方法
DCSQE方法的整体流程如图2所示。其中生成器负责生成合成翻译语句部分,TER工具和标注器负责生成合成标签部分。
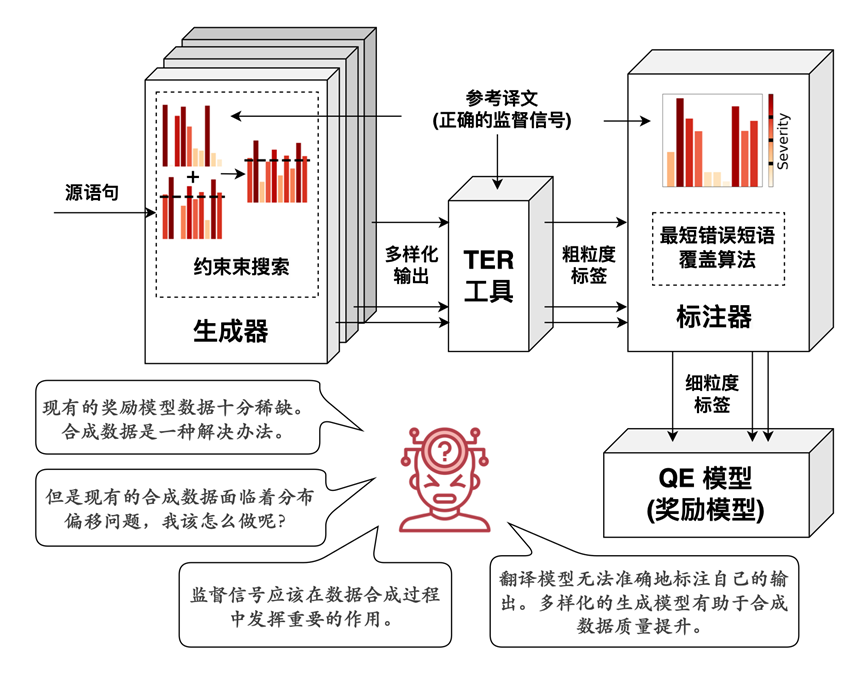
图2: 我们探索了通过利用监督信号和增加模型多样性来提升QE合成数据质量的方法。直方图表示翻译模型的生成概率
3.1 生成合成翻译语句
我们使用NMT模型作为生成器(Generator),并采用CBS算法约束其生成过程,使其输出尽可能保留参考译文的结构。
3.2 生成合成标签
在合成标签方面,我们首先利用TER 工具对参考译文与合成翻译语句进行词级别对齐,从而获得初步的粗粒度标签。得益于CBS在生成过程中对参考译文结构的保留,TER 在标注“OK”标签时展现出较高的真阳率。因此,我们将 TER 标注中被识别为“OK”的部分作为高置信度的正样本予以保留。
然而,对于可能存在误标的部分(尤其是由于词汇重叠度匹配被 TER 错误标注为“BAD”的正确单词),我们进一步引入了另一个基于NMT 的标注器(Annotator)进行细粒度纠正。Annotator 接收源语句并对合成翻译进行强制解码,以此估计每个目标词的生成概率。依据该概率在预设区间中的位置,我们将其标注为 OK、MINOR、MAJOR 或 CRITICAL 四类与MQM标准对齐,其中后三类均视为不同程度的翻译错误。为了进一步增加标注准确性,Annotator需训练于用于合成MQM数据的平行语料,以避免在缺乏翻译知识情况下模型产生的随机判断。
由于MQM标准还要求译员对含有错误的完整短语进行标注,我们在Annotator内部设计了一个后处理算法模块——最短短语覆盖错误(Shortest Phrase Covering Errors, SPCE),用于将先前产生的词级别标注转化为短语级别的标注。对于连续的含有翻译错误的单词,该算法基于句法依存树,利用最小公共祖先方法定位最小错误连通块,并补全必要的路径与边界词,从而构造出语义连贯且结构紧凑的错误短语。最终,该短语以其中最严重单词的词级别标签作为其整体的错误严重程度。图3展示了SPCE模块的整体算法流程。
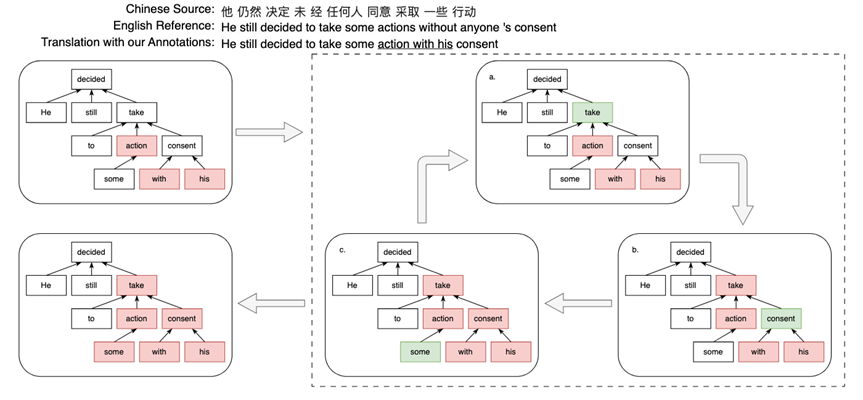
图3: SPCE算法流程
04
实验
4.1 实验设置
数据集:WMT22 英语-德语(EN-DE)汉语-英语(ZH-EN)和 WMT23 英语-德语(EN-DE)汉语-英语(ZH-EN)希伯来语-英语(HE-EN)数据集[9]。其中HE-EN只包含测试集,用于检测模型的无监督对于每个语言方向,我们随机从WMT QE比赛提供的平行语料中采样了约50万对平行语料对用于实验。
评价指标:句子级任务采用Spearman相关系数(WMT23/22比赛的首要评价指标),Pearson相关系数(WMT21首要评价指标)。词级别任务采用Matthews相关系数(MCC,23/22首要评价指标),F1-MULT(WMT19首要评价指标)。F1-MULT为OK与BAD标记F1分数的乘积。短语级别任务采用加权 F1分数(WMT首要评价指标)。所有指标越大表示模型性能越强。
4.2 主实验结果
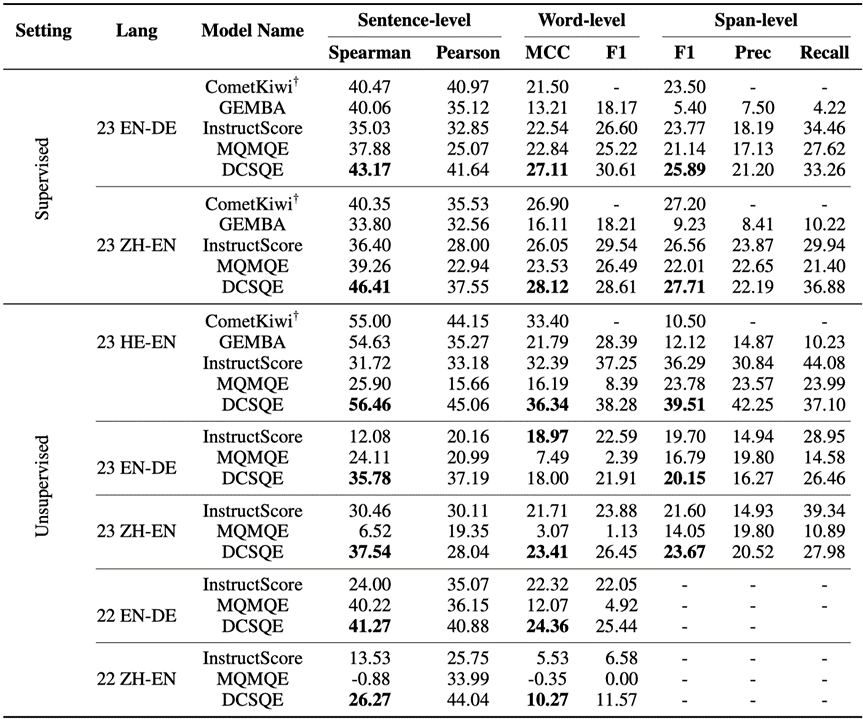
表2展示了在WMT22 EN-DE/ZH-EN和WMT23 EN-DE/ZH-EN/HE-EN上有监督和无监督的实验结果。
在有监督设置下,DCSQE 在两个语言对的测试中表现出显著优势,相较于 CometKiwi 实现了显著提升,平均在 Spearman、MCC 和 F1 分数上分别提高了 4.38、3.41 和 1.45。值得注意的是,DCSQE 也显著优于基于强大语言模型 GPT-4 的 GEMBA-MQM方法[10]。此外,与其他合成数据方法(如 MQMQE 和 InstructScore)相比,DCSQE 始终保持更优性能,表明所生成的合成数据质量更高。
在无监督设置下,MQMQE 和 InstructScore 相较于其有监督设置出现了显著性能下降,平均分别下降了 15.74 和 7.64 分,暴露出先前合成 QE 数据中的分布偏移问题。而 DCSQE 展现出更强的稳健性,平均仅下降 6.64 分,表现出对分布偏移的更强适应能力。此外,DCSQE 在 HE-EN 上也优于 CometKiwi(该方法依赖于其他语言对的标注数据),说明 DCSQE 在该语言对上所生成的合成数据拥有很高的质量。
表2:主实验结果
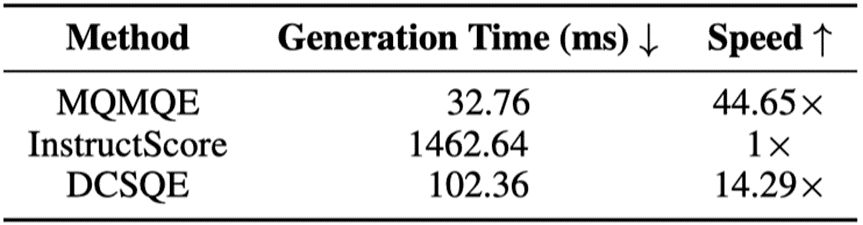
4.3 生成开销
如表3所示,DCSQE在保持较小的生成开销的同时增强了合成数据的质量。
表3: 在单个V100 GPU上不同合成数据方法生成单个样本的时间
05
分析实验
在分析实验中,我们想要探究哪些因素有助于缓解MQM合成数据中的分布偏移问题。为此,我们考虑了如下问题:
1.基于对MQM标准的建模,Annotator中引入的细粒度标注机制与SPCE算法是否能有效缓解合成数据中的分布偏移问题从而提升数据质量?
2.Generator与Annotator使用不同的NMT模型对缓解分布偏移问题有帮助吗?
3.单一Generator所生成的翻译语句在多样性方面是否具有足够的覆盖能力,从而有助于减轻分布偏移带来的影响?
4.Generator与Annotator各自的翻译性能在缓解分布偏移中起到了怎样的作用?
为了回答上述问题,我们引入三个翻译模型S、M、L,他们分别在100万,500万和2000万的平行语料上进行训练。为了增加多样性,我们额外训练了S'、M'、L',他们也同样在100万,500万和2000万的平行语料上进行训练,但数据不重叠。
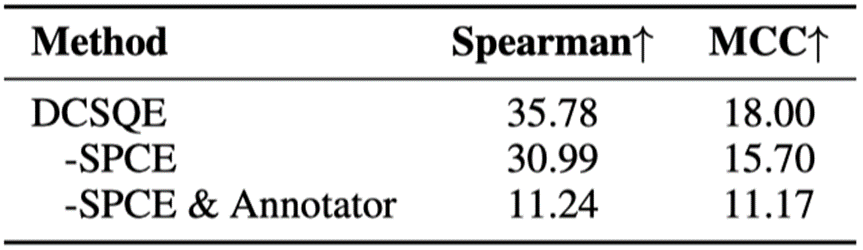
5.1 Annotator和SPCE算法均有效
在该实验中我们回答了问题1。我们的方法从对齐MQM标准的角度出发,设计了细粒度标注机制和SPCE算法,旨在更贴近真实标注行为。表4所示的消融实验结果表明,这一设计确实有效,二者协同作用显著提升了标注质量,验证了以MQM标准为导向的设计理念在缓解分布偏移方面的有效性。
表4: 消融实验
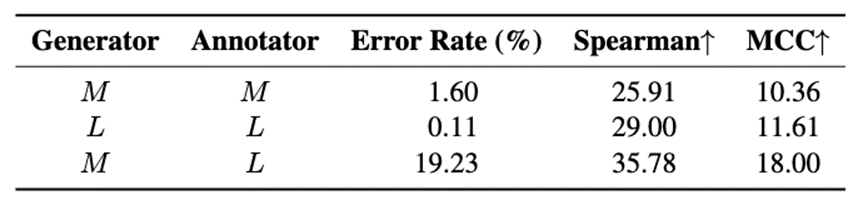
5.2 模型无法准确地标注自身
在该实验中我们回答了问题2。表5结果表明,无论翻译质量如何,模型始终倾向于认为自己的输出是正确的,从而增加了“OK”标签的比例,导致合成标签中出现大量假负例,从而影响合成数据质量。这种“自我标注偏差”降低了标注准确性,进而影响数据质量,说明Generator与Annotator使用相同模型是不利于缓解分布偏移的。
表5: 分析模型L和M单独和协作部署在DCSQE中的结果
5.3 多样的Generator有助于提升合成数据质量
在该实验中我们回答了问题3。我们在表6中比较了使用单一Generator与多个Generator的合成效果。实验表明,引入多个Generator可以有效提升翻译样本的多样性,从而构建更具分布覆盖能力的数据,显著提升QE性能。
表6: Generator多样性的影响

5.4 Generator的翻译性能不能太好也不能太坏
在这一部分中,我们深入探讨了第4个问题的第一层面,即Generator翻译性能对合成数据的影响。我们发现:
1.Generator性能过弱:Generator输出质量低、错误率高,导致生成语句与真实翻译存在较大分布偏差,削弱了数据代表性
2.Generator性能过强:Generator输出几乎无误,无法为模型提供充足的错误样本,限制了QE能力的学习。
为了验证这一观点,我们采用错误率和相似度两个指标来评估Generator。表7展示了不同Generator在这两个指标上的具体表现。
表7: 不同Generator的指标
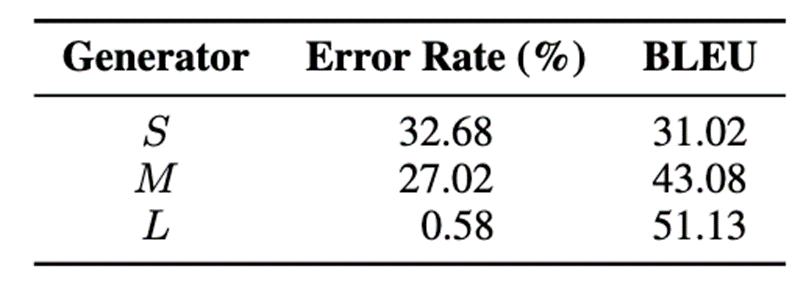
图4进一步揭示了这两个指标与合成数据质量之间的关系。结果表明,高相似度与适度错误率的组合最有利于生成高质量的合成数据,即Generator应在保持真实分布相似性的同时,保留一定量的可学习错误。
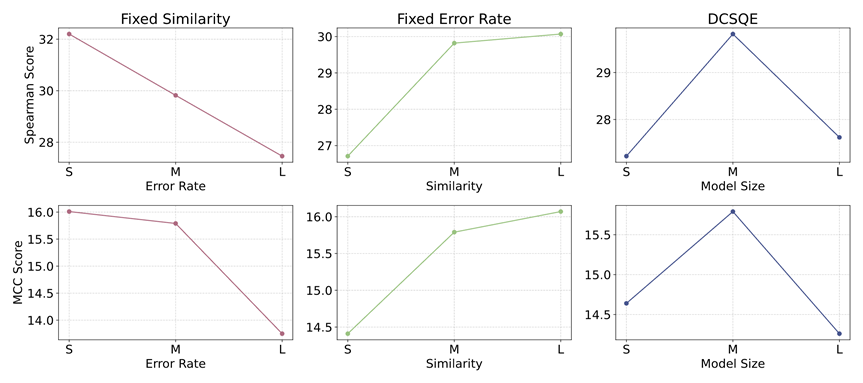
图4: 在句级别和词级别任务中Generator指标对合成数据质量的影响。第一行表示句级别结果。第二行表示词级别结果
5.5 使用监督信号增强Annotator翻译性能是有益的
该部分进一步探讨了第4个问题的第二层面,即如何提升Annotator翻译性能以提升标注质量。我们提出两种增强策略:(1)从Annotator训练集中筛选平行句对用于数据合成(利用已掌握的监督信号),(2)扩展训练语料库(学会更多未掌握的监督信号)。表8结果表明,这两种方式都增强了合成数据质量。
表8: 不同Generator间的对比

06
总结
合成数据的分布偏移问题是目前QE领域面临的一个重要挑战。为应对这一挑战,我们提出DCSQE框架,该框架通过利用参考译文(一种监督信号)来指导生成多样化的合成翻译及其对应的合成标签,从而有效缓解分布偏移问题。实验表明,DCSQE在有监督和无监督两种设置下均取得了最先进的性能表现。此外,我们的分析揭示了与合成数据生成相关的一些关键见解,这些见解有望为通用奖励模型的合成数据方法提供借鉴价值。
参考文献
[1] Lucia Specia, Carolina Scarton, and Gustavo Henrique Paetzold. 2018. Quality estimation for machine translation. Synthesis Lectures on Human Language Technologies, 11(1):1–162.
[2] Arle Lommel, Aljoscha Burchardt, Maja Popovi´c, KimHarris, Eleftherios Avramidis, and Hans Uszkoreit. 2014. Using a new analytic measure for the annotation and analysis of mt errors on real data. In Proceedings of the 17th Annual conference of the European Association for Machine Translation, pages 165–172.
[3] Yi-Lin Tuan, Ahmed El-Kishky, Adithya Renduchintala, Vishrav Chaudhary, Francisco Guzmán, and Lucia Specia. 2021. Quality estimation without humanlabeled data. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 619–625, Online. Association for Computational Linguistics.
[4] Xiang Geng, Yu Zhang, Zhejian Lai, Shuaijie She, Wei Zou, Shimin Tao, Hao Yang, Jiajun Chen, and Shu- jian Huang. 2023b. Improved pseudo data for machine translation quality estimation with constrained beam search. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12434–12447, Singapore. Association for Computational Linguistics.
[5] Xiang Geng, Zhejian Lai, Yu Zhang, Shimin Tao, HaoYang, Jiajun Chen, and Shujian Huang. 2023a. Unify word-level and span-level tasks: Njunlp’s participation for the wmt2023 quality estimation shared task. In Proceedings of the Eighth Conference on Machine Translation, pages 829–834.
[6] Wenda Xu, Danqing Wang, Liangming Pan, Zhenqiao Song, Markus Freitag, William Wang, and Lei Li. 2023. INSTRUCTSCORE: Towards explainable text generation evaluation with automatic feedback. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5967–5994, Singapore. Association for Computational Linguistics.
[7] Vilém Zouhar, Pinzhen Chen, Tsz Kin Lam, Nikita Moghe, and Barry Haddow. 2024. Pitfalls and outlooks in using comet. In Proceedings of the Ninth Conference on Machine Translation, pages 1272–1288.
[8] Wenda Xu, Jiachen Li, William Yang Wang, and Lei Li. 2024b. BPO: Staying close to the behavior LLM creates better online LLM alignment. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11125–11139, Miami, Florida, USA. Association for Computational Linguistics.
[9] Tom Kocmi, Eleftherios Avramidis, Rachel Bawden, Ondˇrej Bojar, Anton Dvorkovich, Christian Federmann, Mark Fishel, Markus Freitag, Thamme Gowda, Roman Grundkiewicz, Barry Haddow, Philipp Koehn, Benjamin Marie, Christof Monz, Makoto Morishita, Kenton Murray, Makoto Nagata, Toshiaki Nakazawa, Martin Popel, Maja Popovi´c, and Mariya Shmatova. 2023. Findings of the 2023 conference on machine translation (WMT23): LLMs are here but not quite there yet. In Proceedings of the Eighth Conference on Machine Translation, pages 1–42, Singapore. Association for Computational Linguistics.
[10] Tom Kocmi and Christian Federmann. 2023. GEMBA-MQM: Detecting translation quality error spans with GPT-4. In Proceedings of the Eighth Conference on Machine Translation, pages 768–775, Singapore. Association for Computational Linguistics.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢