

【该工作由南京大学自然语言处理组、美团和中国移动研究院合作完成,论文链接:https://arxiv.org/abs/2504.01801,代码:https://github.com/NJUNLP/SynCS 】
01
研究动机
在本文中,我们聚焦于当前大语言模型中出现的一种有趣现象——自发的跨语言迁移能力。尽管大多数开源大模型在其预训练语料中仅包含少量多语言数据(例如LLaMA-3[1]中多语言数据占比仅为8%,平均到每种非英语语言则比例极低),这些模型却仍展现出较强的多语言理解与生成能力。我们认为,这种现象源于模型在预训练过程中发生了自发的跨语言迁移,即模型能够从主要训练语言(如英语)中学习到的能力自动迁移到其他语言上。然而,目前关于这一现象的研究尚缺乏对其数据层面成因的系统解释,这在一定程度上限制了多语言大模型的发展与优化。
近年来的一些研究表明,在大模型的训练中引入语码切换(Code-Switching)数据可以显著提升其跨语言迁移能力。语码切换指的是在同一个上下文中混合使用多种语言的现象。代表性工作包括基于语码切换的课程学习方法CSCL[2]和多语言预训练前对齐技术PreAlign[3]。这些研究证实了语码切换数据在增强模型跨语言泛化能力方面的有效性。
受此启发,我们提出了两个核心问题:
1. 大模型在预训练过程中产生的自发跨语言迁移是否与语码切换现象有关?
围绕这两个问题,本文开展了深入研究,首次提出并验证了一个假设:即使在预训练语料中语码切换数据的比例非常低,它们仍然是引发大模型自发跨语言迁移的关键因素。在此基础上,我们提出了一种低成本、高效率的语码切换数据合成方法SynCS ,用于生成高质量的语码切换样本。进一步地,我们系统比较了不同类型语码切换数据在扩大规模时对模型跨语言迁移能力的影响差异,最终形成了一套通过合成语码切换数据来增强大模型多语言能力的有效策略,为未来多语言大模型的设计与优化提供了新的思路与实证支持。
02
贡献
1. 我们揭示了预训练数据中自然出现的极少量语码切换数据是大模型自发跨语言迁移现象的关键因素。
2. 我们提出了一种能够低成本合成高质量语码切换数据的合成方法SynCS。SynCS数据大幅提升了模型的跨语言迁移,其提升效果堪比20倍数据量目标语言单语数据。
3. 我们探究了不同类型的语码切换数据在扩大数据规模时对大模型跨语言迁移能力的影响差异,给出了在使用语码切换数据来增强大模型多语言能力时的指导。
03
大模型自发跨语言迁移现象的理解
我们对语码切换做了如表1所示的定义。首先按照粒度将其分为句子级别和词级别,其中句子级别就是在一段文本中,每个语言的文本是以句子作为最小单元出现的;词级别就是在单个句子当中,不同语言的词交替出现。进而每个粒度又被分为标注和替换两种类型,其中标注是指在某个词后面用该词的另一种语言的翻译进行标注,替换则是用该词的翻译直接替换原始词。
表1:FineWeb-Edu数据集中四种语码切换数据的示例

为了防止子词共享带来的额外影响,我们选择中文和英文两个语言之间的语码切换作为研究对象。图1展示了FineWeb-Edu[4]和Chinese-FineWeb-Eduv2[5]两个高质量预训练数据集中,各种类型的语码切换数据的分布。其分别代表在英文文档中出现的中文语码切换和在中文文档中出现的英文语码切换。首先,在FineWeb-Edu中,0.4%的文档包含中文字符,这些片段中词级别语码切换占比62%,并且其中标注类型占主导地位;在Chinese-FineWeb-Eduv2中,由于中文中存在较多的英语词使用,因此包含英文的文档占比51.2%,同样是词级别语码切换占主要部分(73%),不同于英文文档中的中文词级别语码切换,其替换类型占主导地位。

图1:FineWeb-Edu(左图)和Chinese-FineWeb-Eduv2(右图)数据集中语码切换数据的统计
我们进而对这些自然存在的语码切换数据进行了消融实验。本文首先从FineWeb-Edu数据集中随机采样60B tokens并从Chinese-FineWeb-Eduv2中随机采样600M tokens来组成我们的预训练数据,英文和中文的数据比例保持100:1来模拟预训练数据的语言不平衡特性。我们进而从该原始数据集开始,过滤掉所有含有中英语码切换的文档,由于此时数据集文档总数变少,我们补充从同源数据集额外采样的等数量不含有语码切换的文档,以保持数据总数的一致,由此构造了一个不包含任何中英语码切换的数据集。由于该数据集的构造过程实际上是文档替换过程,新文档数据的引入可能会导致数据集整体的分布偏移,因此我们进而构造了控制实验数据集,即用相同的新文档去随机替换原始数据集中的文档。这样我们能够确定实验结果的差异直接来源于语码切换数据的缺失。
表2:预训练语料中自然存在的语码切换数据对自发跨语言迁移的影响
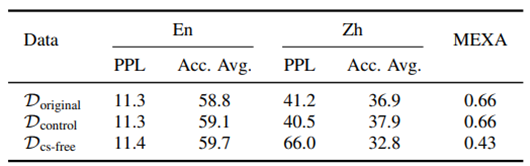
如表2所示,我们在三个数据集上从头预训练了一个1.5B大小的模型,并评测了这些模型在中英维基百科数据上的困惑度和多个基准测试集上的性能,我们还测试了不同模型的MEXA[6]指标,这是一个评估模型多语言表示对齐程度的指标,数值越高表明模型的多语言对齐程度越好。结果表明,不包含语码切换的数据集训练得到的模型在这些指标上均产生了显著下降,相比之下,控制实验数据集的结果和原始数据集并无明显差异,这表明了预训练语料中自然出现的极少量语码切换数据是大模型自发跨语言迁移现象的关键因素。
04
大模型自发跨语言迁移现象的增强
有了以上发现,我们进一步尝试通过注入更多语码切换数据来增强该跨语言迁移。由于自然的语码切换数据极其稀有,并且其出现的文档通常带有一定的领域偏好,例如语言教育领域多出现语码切换。因此通过自然语码切换数据来提升既不灵活,也不现实。本文进而尝试使用合成数据的方法来自由控制语码切换数据的所处领域,以及高效地提升数据总量。
4.1语码切换数据合成方法SynCS
本文提出了SynCS,一种能够低成本快速合成高质量语码切换数据的方法。针对本文定义的四种语码切换类型,对于句子级别语码切换,可以直接使用翻译器翻译来合成;对于词级别的语码切换,如图2所示,相关工作的做法是使用GPT-4o这类SOTA模型进行合成,其不仅成本高昂,由于目前的大模型对语码切换数据的合成并不稳定,该方法还需要输入平行语料,这进一步限制了该方法的使用。因此,我们提出了如图3所示的基于数据蒸馏的词级别语码切换数据合成方法,首先通过相关工作的方法,对一小批高质量平行数据进行语码切换合成,然后使用这些数据构造单源有监督微调数据集,即把数据的双语输入改为单语输入,进而使用该数据微调一个较小的模型,以得到能对任何预训练单语数据合成特定语言语码切换数据的合成模型。
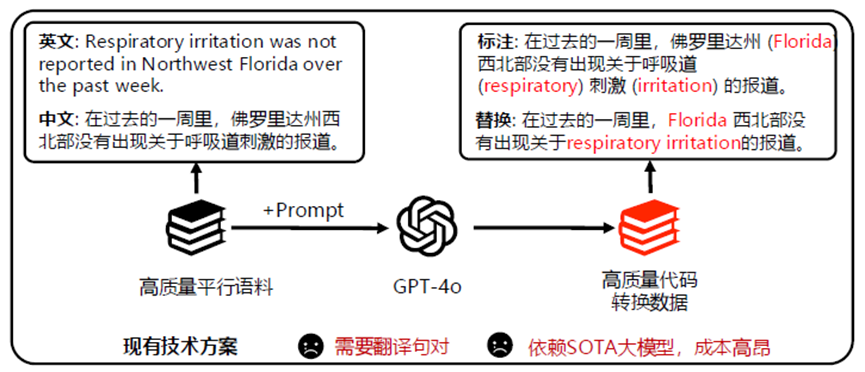
图2:现有词级别语码切换合成方法
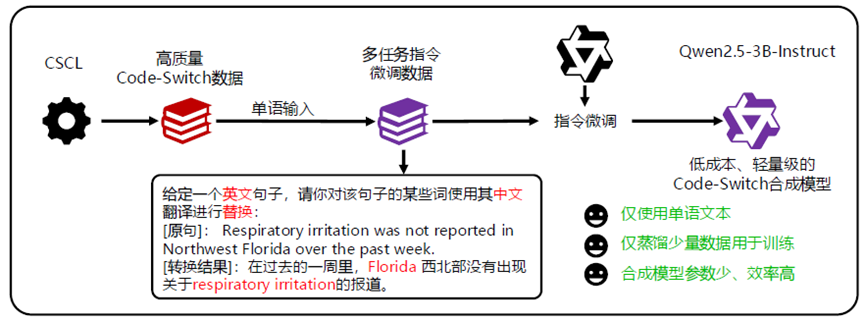
图3:基于数据蒸馏的词级别语码切换合成方法
4.2 不同类型语码切换数据的影响差异
我们使用SynCS数据合成框架来合成不同规模、不同类型的语码切换数据,来探究他们的作用差异,以及最优的合成策略。我们主要关心以下问题:
1. 不停增加合成语码切换数据的比例,迁移效果是否稳定提升?
2. 预训练语料中英文占主导且质量较高,在给定计算资源的情况下,对英文文档合成目标语言的语码切换是否效果更好?
3. 4种类型的语码切换起到的作用是否有差异?以及最好的策略?
如图4所示,左图为在1%的中文文档中不断提升合成的英文语码切换数据比例,其中文能力呈现先提升后下降的趋势,这说明目标语言的单语文档还是比较重要的,在4种类型中,词级别的语码切换显著好于句级别,并且标注类型好于替换类型,这启示我们如果要在中文数据中做英文的语码切换来提升迁移,最好使用词级别标注类型;
右图中,我们随机选定60B数据中的20%文档进行合成来保证英文训练的稳定,不停地提升每个文档中被翻译的token比例,可以发现,4种类型的语码切换均有稳定的效果提升,并且都显著优于添加等量的中文单语数据,其中替换类型的效果明显优于标注类型,这可能是因为预训练数据中英文占主导,对标注类型来说,其原始的英文上下文仍然完整的被保留,模型可能不会过多的关注语码切换的部分,而替换类型更严重地破坏了原始英文的上下文,迫使模型学习被替换部分的意义,从而产生更好的跨语言迁移效果。
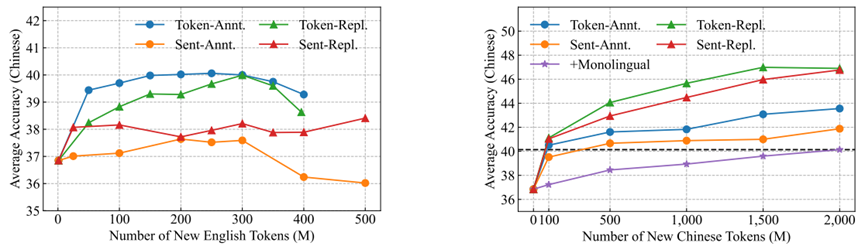
图4:在英文文档中合成中文语码切换(左图)和在中文文档中合成英文语码切换(右图)在不同数据规模下的效果
通过以上实验结论,我们进而启发式的探究了这些类型的最优组合,如表3所示,两种最好效果的类型,即在英文数据中做目标语言的词级别和句级别替换,融合起来的效果最好,相比于添加等量目标语言单语数据提升了2.7,并且SynCS合成数据在只添加100M的情况下,效果能够持平添加2000M单语的效果。
表3:最优合成策略的探究以及更大规模的实验结果
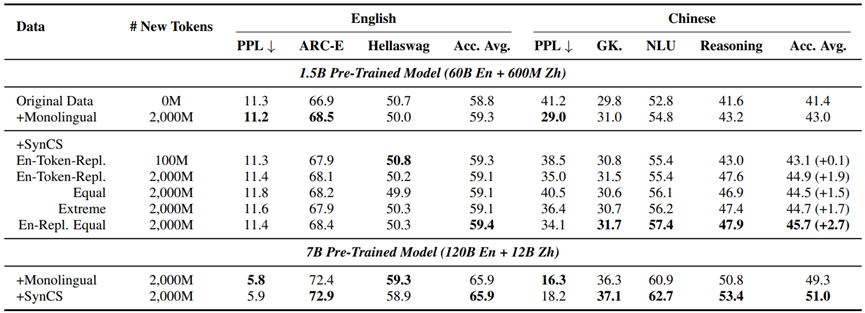
我们还在更大的规模上进行了验证,我们使用132B的数据(120B英文和12B中文,提升了语言比例到10:1)预训练了一个7B的模型,其效果依然优于添加单语数据。我们进而将方法扩展到高、中、低资源语言上,如表4所示,实验结果表明我们的合成方法在这些语言上依然有效。
表4:扩展到高、中、低资源语言上的效果
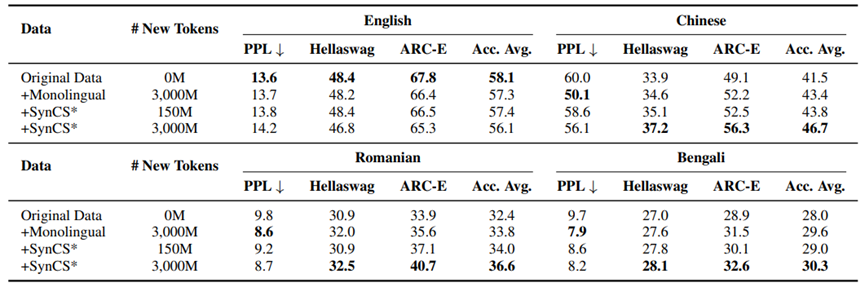
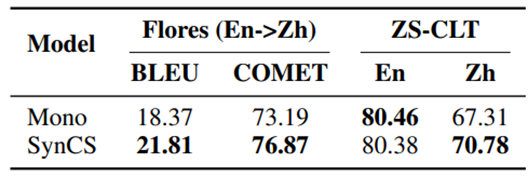
最后,我们从预训练的1.5B基座模型出发,对这些模型进行下游任务的微调,如表5所示,在经过翻译任务微调后,使用SynCS数据预训练的基座模型展现出了更强的翻译能力,另外我们评测了Zero-Shot跨语言迁移任务,即模型只在英文的XNLI上进行训练,测试中文XNLI上的效果,结果表明,我们的基座模型有更强的跨语言迁移能力。
表5:下游任务上的性能
4.3 效果分析
从实验结果可知,效果最好的两种数据类型是在英文数据中进行词级别和句级别的替换,我们对平行句子在模型中间层的表示向量进行降维可视化,图5中给出了示例,这两种效果最好的类型的表示空间是最右侧子图,其将模型的中英表示空间进行了均匀的混合,提升了对齐程度,而其他类型都是中间子图的效果,其变化相对较小一些。
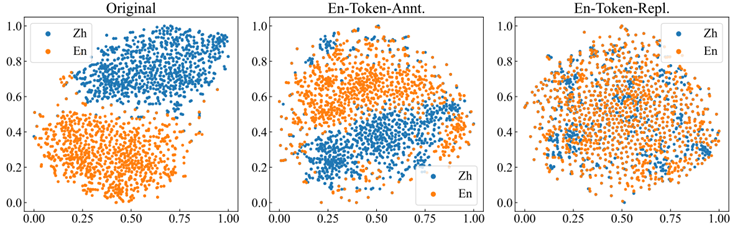
图5:SynCS数据对模型内部表示空间的影响
最后,我们计算了模型每一层的MEXA指标,如图6所示,从原始数据出发,我们首先可以发现清洗掉自然的语码切换后各层的语言对齐程度均产生了大幅下降,在添加目标语言单语数据后,各层对齐程度有较小幅度提升,这是模型的自发跨语言迁移。最后,使用SynCS数据时,模型的语言对齐程度在各层都产生了显著的提升。
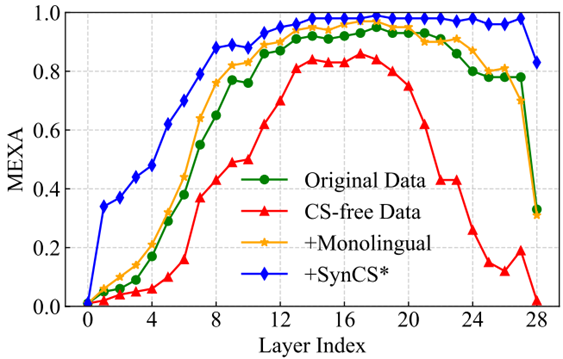
图6:SynCS数据训练对模型多语言表示对齐的影响
这些模型语言对齐程度的变化表明了我们方法的有效性。
05
总结
本工作揭示了预训练数据集中自然存在的极少量语码切换数据对大模型自发跨语言迁移现象的重要作用,并提出了一个能够低成本合成高质量语码切换数据的方法SynCS。本工作对各种类型的语码切换数据进行了各种规模下的探究,给出了一个使用语码切换合成数据来增强模型跨语言迁移的有效方法,实验和分析充分表明了我们方法的有效性。
参考文献
[1] Grattafiori A, Dubey A, Jauhri A, et al. The llama 3 herd of models[J]. arXiv e-prints, 2024: arXiv: 2407.21783.
[2] Yoo H, Park C, Yun S, et al. Code-Switching Curriculum Learning for Multilingual Transfer in LLMs[J]. arXiv preprint arXiv:2411.02460, 2024.
[3] PreAlign: Boosting Cross-Lingual Transfer by Early Establishment of Multilingual Alignment (Li et al., EMNLP 2024)
[4] Penedo G, Kydlíček H, Lozhkov A, et al. The fineweb datasets: Decanting the web for the finest text data at scale[J]. Advances in Neural Information Processing Systems, 2024, 37: 30811-30849.
[5] Yijiong Yu, Ziyun Dai, et al. OpenCSG Chinese Corpus: A Series of High-quality Chinese Datasets for LLM Training, https://arxiv.org/abs/2501.08197
[6] Kargaran A H, Modarressi A, Nikeghbal N, et al. MEXA: Multilingual Evaluation of English-Centric LLMs via Cross-Lingual Alignment[J]. arXiv preprint arXiv:2410.05873, 2024.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢