
由人工智能领域权威专家 Christopher M. Bishop 及其子 Hugh Bishop 历时多年打造,系统梳理深度学习近 20 年理论基础与关键进展,涵盖 Transformer、LLM、GAN、扩散模型等新技术。
本书全面且深入地呈现了深度学习领域的知识体系,系统梳理了该领域的核心知识,阐述了深度学习的关键概念、基础理论及核心思想,剖析了当代深度学习架构与技术。全书共 20 章。本书首先介绍深度学习的发展历程、基本概念及其在诸多领域(如医疗诊断、图像合成等)产生的深远影响;继而深入探讨支撑深度学习的数学原理,包括概率、标准分布等;在网络模型方面,从单层网络逐步深入到多层网络、深度神经网络,详细讲解其结构、功能、优化方法及其在分类、回归等任务中的应用,同时涵盖卷积网络、Transformer 等前沿架构及其在计算机视觉、自然语言处理等领域的独特作用。本书还对正则化、采样、潜变量、生成对抗网络、自编码器、扩散模型等关键技术展开深入分析,阐释其原理、算法流程及实际应用场景。
对于机器学习领域的新手,本书是全面且系统的入门教材,可引领其踏入深度学习的知识殿堂;
对于机器学习领域从业者,本书是深化专业知识、紧跟技术前沿的有力工具;
对于相关专业学生,本书是学习深度学习课程、开展学术研究的优质参考资料。
无论是理论学习、实践应用还是学术研究,本书都是读者在深度学习领域探索与前行的重要指引。

书名:深度学习:基础与概念
作者:Christopher M.Bishop、Hugh Bishop 著
年份:2025
出版社:人民邮电出版社、异步图书
书籍汇总:
链接: https://pan.baidu.com/s/1FFw_24YdJIUfLGunRGT_7g?pwd=9at9
链接: https://pan.baidu.com/s/1wp1sxh_p5Cv9dI5OpBaSCg?pwd=2arp

在留言区参与互动发送(我想要一本赠书)
并点击转发朋友圈,邀好友助力点赞你的留言
我们将选点赞率最高的1名读者获得赠书1本
时间以公众号推文发出24小时为限
记得扫码加号主微信,以便联系邮寄地址哦
欢迎自购或向图书馆荐购

一本好的教材兼备两大特质——体量恢弘、思想深邃。由世界公认的机器学习专家Christopher M.Bishop耗时16年精心打磨而成的《深度学习:基础与概念》,就是这样一本经典的深度学习入门书,随着大模型的发展,这本书与时俱进涵盖 Transformer、LLM、GAN、扩散模型等新技术新进展,更适合当下。
本书一经问世,就得到2024年诺贝尔物理学奖和2018年图灵奖得主Geoffrey Hinton、2018图灵奖得主Yann LeCun和2018图灵奖得主Yoshua Bengio这三位人工智能领域巨头联袂推荐,迅速攀升至亚马逊最畅销书籍排行榜的首位,Springer Nature 2024 年度最畅销著作的荣誉更是让它在学术出版界风头无两,被业界公认为 “深度学习领域迫切需要的现代教材”。


十几年前,Bishop大神的Pattern Recognition and Machine Learning(PRML)以贝叶斯视角揭示了机器学习算法的本质,被称为该领域的“圣经”。经典前作封神,新作再续传奇,如今,他推出姊妹篇《深度学习:基础与概念》,系统梳理了深度学习近20年来的理论基础与关键进展,重构深度学习理论根基。

▼点击下方,即可购书
大神出品必不凡!接下来让我们一起翻开这本领域巨著,看看他这次又带来了哪些超硬核的干货!
作译者皆是AI专家,作品质量可靠
能打造出一本又一本领域巨著,作者必定要功力深厚。
本书两位作者Christopher M.Bishop和Hugh Bishop,就是深耕人工智能领域数十年的资深专家。
Christopher M.Bishop是爱丁堡大学计算机科学名誉教授和剑桥大学达尔文学院院士,现任微软研究院剑桥AI for Science (AI4Science)部门的技术院士兼总监,并且是英国人工智能委员会的创始成员,曾任首相科学技术委员会成员 (2019)。

Hugh Bishop是Christopher M.Bishop的儿子,是伦敦一家基于端到端深度学习的自动驾驶公司Wayve的应用科学家,负责设计和训练深度神经网络。他拥有剑桥大学工程系机器学习和机器智能专业硕士学位,以及杜伦大学计算机科学工程学硕士学位。

Christopher M.Bishop在1996年出版过关于神经网络的Neural Networks for"Pattern Recognition(NNPR)一书,推动了神经网络作为模式识别工具的应用,备受赞誉;2006年又出版了从贝叶斯主义角度诠释机器学习的名著Pattern Recognition and Machine Learning(PRML),是很多机器学习爱好者的启蒙图书。

PRML的出版早于深度学习革命,虽未涵盖深度学习内容,却因其贝叶斯框架的普适性至今仍被奉为经典。不过Bishop 大神早就觉得是时候更新这本书,出第2版,增加一些关于深度学习的内容了。
在 COVID-19 期间,他与儿子开启了这个合作写书项目。但他们很快意识到,所需要的不是在 PRML 上增加几章,而是整个领域已经发生了如此大的变化。
而且,2020年,Bishop大神与儿子启动修订计划,却意识到领域变革远超预期。他们也不想写一本只是不断累积越来越多的材料的书,那会变成一本巨大的、庞杂的书籍。
Bishop大神认为一本书的价值在于提炼,在于它将你的注意力吸引到特定的事物子集上,重点在于“提炼”而非“堆砌”。最终,他们放弃简单增补,转而打造全新著作《深度学习:基础与概念》(DLFC)。

ChatGPT爆火后,他们抢抓时机,于2023年NeurIPS会议前出版新书,回应全球对AI底层原理的迫切需求。该书发布仅两个月,在Springer平台的访问量就高达63k,在海外AI圈引发学习热潮。

▲英文原书在世界最著名、最有影响力的AI和机器学习会议——神经信息处理系统大会(NeurIPS)上备受关注
考虑到国内的读者同样迫不及待地想要读到这本巨著,为保证翻译质量,我们特邀Momenta 研发负责人、CSDN &《新程序员》首席内容顾问邹欣,北京理工大学计算机学院特别副研究员阮思捷,中国人工智能领军科学家、上海市人工智能社会治理协同创新中心研究员刘志毅,北京理工大学电子政务研究院执行院长、计算机学院特聘教授王树良等一批AI领域大咖翻译本书。

终于,这本全面系统的“深度学习领域迫切需要的现代教材”能与我们见面了。
兼具“新”与“深”,更适合当下
作者在前言中提到:“大语言模型正在迅速演进,然而其底层的Transformer架构和注意力机制在过去5年基本保持不变,并且机器学习的许多核心原则已被人们熟知数十年。”
我们只有吃透这些“不变”的原理,才能不被眼花缭乱的“震惊”迷惑。
正是基于这个原则,本书的编排兼具“新”(涵盖LLM、扩散模型等)与“深”(理论扎实),帮助深度学习的新手及有经验的从业者全面理解支撑深度学习的基础理论,以及现代深度学习架构和技术的关键概念,为读者未来在专业领域的深造打下坚实的基础。

新内容
如果你读过PRML,读本书时肯定会觉得似曾相识,它们的结构其实非常接近,你可以理解为作者用这十多年来领域的新进展重塑了PRML,就得到了本书。
本书可以看作PRML的“伴随读物”,采用了PRML中的一部分相关内容并进行了改写,以更专注于深入学习所需的基础概念,确保内容能自成一体。例如,PRML只用了一章讲神经网络,本书用了几章的篇幅深入讲解,体现了时代范式的变迁。
比如,由固定非线性基函数的线性组合构成的线性回归模型可以表达为单层权重和偏置参数的神经网络(第4章)、基于基函数线性组合的分类模型也可以视作单层(神经)网络(第5章)、具有多层可学习参数的神经网络:前馈网络(feed-forward network)或多层感知机(multi-layer perceptron)(第6章)等。

新技术
本书从概率、统计和计算等多个角度交叉讲解算法和模型,强调了通过可解释性和可计算性来模拟智能的本质。读者在阅读过程中可能会体验到类似于大语言模型带来的“顿悟时刻”(Aha Moment),这是一种在人类认知中突然出现的、非线性的解决问题的美妙体验。
近年来,人工智能发展迅速,大语言模型的出现更是推动了人工智能向更高层次发展,而这一切的基础都源于神经网络和深度学习。
本书全面系统地介绍了神经网络和深度学习的相关知识,不盲目追逐可能很快会过时的热门架构,而是注重基础性和持久价值,重点关注那些经得起时间考验的方法。书中涵盖了 Transformer、LLM、GAN、扩散模型等热门架构,直击 ChatGPT 技术内核,为读者进一步学习、应用和研究人工智能提供了坚实的技术基础。
本书的亮点在于,它不仅包含新的内容,还巧妙地将这些内容融入清晰的知识体系中,实现了在变化中体现不变的本质,让读者能够清晰地看到技术的发展脉络,这正是 Bishop大神的高明之处。
更广泛
本书全面且深入地呈现了深度学习领域的知识体系,系统梳理了该领域的核心知识,阐述了深度学习的关键概念、基础理论及核心思想,剖析了当代深度学习架构与技术。
本书首先介绍深度学习的发展历程、基本概念及其在诸多领域(如医疗诊断、图像合成等)产生的深远影响,继而深入探讨支撑深度学习的数学原理,包括概率、标准分布等。
在网络模型方面,从单层网络逐步深入多层网络、深度神经网络,详细讲解其结构、功能、优化方法及其在分类、回归等任务中的应用,同时涵盖卷积网络、Transformer等前沿架构及其在计算机视觉、自然语言处理等领域的独特作用。

本书还对正则化、采样、潜变量、生成对抗网络、自编码器、扩散模型等关键技术展开深入分析,阐释其原理、算法流程及实际应用场景。基本上我们能用到的深度学习知识都包含在本书的讨论范畴中。





尽管本书篇幅宏大,但其深入浅出的表述和大量案例的使用,使得复杂概念易于理解,比如,第1章用一个案例引出机器学习的历史和基础概念。


本书分20章,每章聚焦一个主题,内容相互独立又线性衔接,前文为后文奠基。这种结构便于知识消化与吸收,无论是用于本科生或研究生的机器学习课程教学,还是为深度学习研究者、自学者提供参考,都非常合适。
更具深度
本书内容绝非浅尝辄止。面对深度学习知识的广泛性与快速迭代,作者力求深入,提炼关键思想与基础概念,这些内容在领域内经久不衰。只有掌握核心原理,才能从模仿应用跃升至自主创新。
同时作者认为,扎实的数学和算法功底能让读者将深度学习技术灵活应用于新场景,例如,图神经网络在社交与生物信息学中的应用,以及利用对流标准化和结构化分布处理非规范数据,助力前沿突破。

满载赞誉,经典之作助力入门深度学习
正因如此,本书获得读者及业内人士的广泛认可和高度评价,在美亚上获得4.5分的评分。

国内外人工智能领域各专家、教授都对本书给予高度赞赏。


本书旨在讲清概念,强调现实中用得上的技术,而非抽象的理论。对于复杂概念,会结合文字、图表、公式等多种形式呈现,帮助不同背景的读者理解。
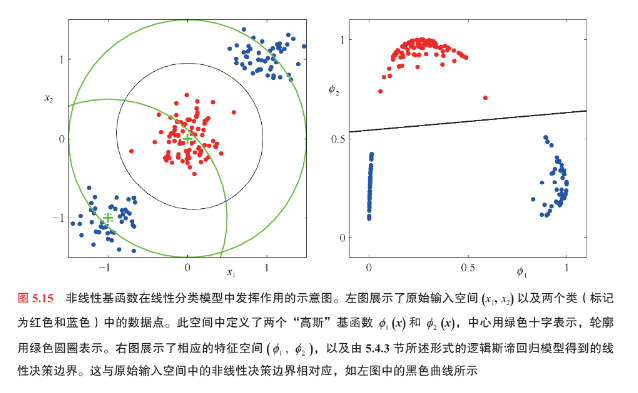
书中专门开辟板块总结关键算法,这些总结虽未提升算法的计算效率,但通过补充数学说明,可以助力不同背景的读者理解书中的内容。


从第2章开始,每章最后都会给出一套设计好的习题,每道习题按难度分级,从几分钟就能完成的简单的一星级(*)到明显更复杂的三星级(***),旨在帮助读者巩固书中解释的关键思想或以重要方式扩展和泛化它们。

本书配有一个网站(https://www.bishopbook.com),用于提供习题解答、可下载图表等配套素材。

唯思想永恒
就像一位读者分享的那样:Bishop大神的书适合你在不同的学习阶段反复地读,直到你发现他讲的确实都是基础,这才能读出精妙之处来。
如果你对深度学习感兴趣,那不妨拿起本书,探索其深邃思想,开启AI世界的全新认知。

—END—
原创
初审:刘鑫
复审:栾传龙
终审:孙英
【目录】
第 1 章 深度学习革命 1
1 1 深度学习的影响 2
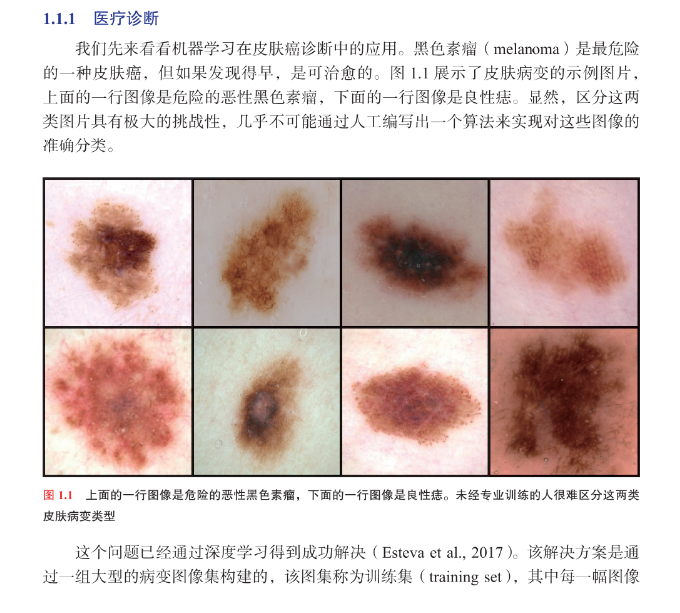
1 1 1 医疗诊断 2
1 1 2 蛋白质结构预测 3
1 1 3 图像合成 4
1 1 4 大语言模型 5
1 2 一个教学示例 6
1 2 1 合成数据 7
1 2 2 线性模型 7
1 2 3 误差函数 8
1 2 4 模型复杂度 8
1 2 5 正则化 11
1 2 6 模型选择 12
1 3 机器学习简史 14
1 3 1 单层网络 15
1 3 2 反向传播 16
1 3 3 深度网络 17
第 2 章 概 率 21
2 1 概率法则 23
2 1 1 医学筛查示例 23
2 1 2 加和法则和乘积法则 24
2 1 3 贝叶斯定理 26
2 1 4 再看医学筛查示例 27
2 1 5 先验概率和后验概率 28
2 1 6 独立变量 28
2 2 概率密度 28
2 2 1 分布的示例 30
2 2 2 期望和协方差 31
2 3 高斯分布 32
2 3 1 均值和方差 32
2 3 2 似然函数 33
2 3 3 似然的偏差 35
2 3 4 线性回归 36
2 4 密度变换 37
多元分布 39
2 5 信息论 40
2 5 1 熵 40
2 5 2 物理学视角 42
2 5 3 微分熵 43
2 5 4 熵 44
2 5 5 Kullback-Leibler 散度 45
2 5 6 条件熵 47
2 5 7 互信息 47
2 6 贝叶斯概率 47
2 6 1 模型参数 48
2 6 2 正则化 49
2 6 3 贝叶斯机器学习 50
习题 50
第 3 章 标准分布 55
3 1 离散变量 56
3 1 1 伯努利分布 56
3 1 2 二项分布 57
3 1 3 多项分布 58
3 2 多元高斯分布 59
3 2 1 高斯几何 60
3 2 2 矩 62
3 2 3 局限性 64
3 2 4 条件分布 64
3 2 5 边缘分布 67
3 2 6 贝叶斯定理 70
3 2 7 似然 72
3 2 8 序贯估计 73
3 2 9 高斯混合 74
3 3 周期变量 76
冯·米塞斯分布 76
3 4 指数族分布 80
充分统计量 84
3 5 非参数化方法 85
3 5 1 直方图 85
3 5 2 核密度 86
3 5 3 最近邻 88
习题 90
第 4 章 单层网络:回归 97
4 1 线性回归 97
4 1 1 基函数 98
4 1 2 似然函数 100
4 1 3 似然 101
4 1 4 最小二乘的几何表示 102
4 1 5 序贯学习 102
4 1 6 正则化最小二乘法 103
4 1 7 多重输出 104
4 2 决策理论 105
4 3 偏差 - 方差权衡 108
习题 112
第 5 章 单层网络:分类 115
5 1 判别函数 116
5 1 1 二分类 116
5 1 2 多分类 117
5 1 3 1-of-K 编码方案 119
5 1 4 最小二乘分类 119
5 2 决策理论 121
5 2 1 误分类率 122
5 2 2 预期损失 124
5 2 3 拒绝选项 125
5 2 4 推理和决策 125
5 2 5 分类器精度 128
5 2 6 ROC 曲线 129
5 3 生成分类器 131
5 3 1 连续输入 132
5 3 2 似然解 134
5 3 3 离散特征 136
5 3 4 指数族分布 136
5 4 判别分类器 137
5 4 1 激活函数 137
5 4 2 固定基函数 138
5 4 3 逻辑斯谛回归 139
5 4 4 多类逻辑斯谛回归 140
5 4 5 probit 回归 141
5 4 6 规范连接函数 143
习题 144
第 6 章 深度神经网络 149
6 1 固定基函数的局限性 150
6 1 1 维度诅咒 150
6 1 2 高维空间 152
6 1 3 数据流形 153
6 1 4 数据依赖的基函数 155
6 2 多层网络 156
6 2 1 参数矩阵 157
6 2 2 通用近似 158
6 2 3 隐藏单元激活函数 159
6 2 4 权重空间的对称性 161
6 3 深度网络 162
6 3 1 层次化表示 162
6 3 2 分布式表示 163
6 3 3 表示学习 163
6 3 4 迁移学习 164
6 3 5 对比学习 165
6 3 6 通用网络结构 168
6 3 7 张量 168
6 4 误差函数 169
6 4 1 回归 169
6 4 2 二分类 170
6 4 3 多分类 171
6 5 混合密度网络 172
6 5 1 机器人运动学示例 172
6 5 2 条件混合分布 173
6 5 3 梯度优化 175
6 5 4 预测分布 176
习题 177
第 7 章 梯度下降 181
7 1 错误平面 182
局部二次近似 183
7 2 梯度下降优化 184
7 2 1 梯度信息的使用 185
7 2 2 批量梯度下降 185
7 2 3 随机梯度下降 186
7 2 4 小批量方法 187
7 2 5 参数初始化 188
7 3 收敛 189
7 3 1 动量 190
7 3 2 学习率调度 192
7 3 3 AdaGrad、RMSProp 与 Adam 算法 193
7 4 正则化 195
7 4 1 数据归一化 195
7 4 2 批量归一化 196
7 4 3 层归一化 197
习题 198
第 8 章 反向传播 201
8 1 梯度计算 202
8 1 1 单层网络 202
8 1 2 一般前馈网络 202
8 1 3 简单示例 205
8 1 4 数值微分法 206
8 1 5 雅可比矩阵 207
8 1 6 黑塞矩阵 209
8 2 自动微分法 211
8 2 1 前向模式自动微分 213
8 2 2 逆模式自动微分 215
习题 217
第 9 章 正则化 219
9 1 归纳偏置 220
9 1 1 逆问题 220
9 1 2 无免费午餐定理 221
9 1 3 对称性和不变性 222
9 1 4 等变性 224
9 2 权重衰减 225
9 2 1 一致性正则化项 226
9 2 2 广义权重衰减 228
9 3 学习曲线 230
9 3 1 早停法 230
9 3 2 双重下降 231
9 4 参数共享 234
软权重共享 234
9 5 残差连接 236
9 6 模型平均 239
dropout 241
习题 243
第 10 章 卷积网络 247
10 1 计算机视觉 248
图像数据 248
10 2 卷积滤波器 249
10 2 1 特征检测器 250
10 2 2 平移等变性 251
10 2 3 填充 252
10 2 4 跨步卷积 253
10 2 5 多维卷积 253
10 2 6 池化 255
10 2 7 多层卷积 256
10 2 8 网络架构示例 257
10 3 可视化训练好的 CNN 259
10 3 1 视觉皮层 259
10 3 2 可视化训练好的滤波器 260
10 3 3 显著性图 262
10 3 4 对抗攻击 263
10 3 5 合成图像 264
10 4 目标检测 265
10 4 1 边界框 265
10 4 2 交并比 266
10 4 3 滑动窗口 267
10 4 4 跨尺度检测 268
10 4 5 非抑制 269
10 4 6 快速区域卷积神经网络 270
10 5 图像分割 270
10 5 1 卷积分割 270
10 5 2 上采样 271
10 5 3 全卷积网络 272
10 5 4 U-Net 架构 273
10 6 风格迁移 274
习题 275
第 11 章 结构化分布 279
11 1 概率图模型 280
11 1 1 有向图 280
11 1 2 分解 280
11 1 3 离散变量 282
11 1 4 高斯变量 284
11 1 5 二元分类器 286
11 1 6 参数和观测值 287
11 1 7 贝叶斯定理 288
11 2 条件独立性 289
11 2 1 3 个示例图 289
11 2 2 相消解释 292
11 2 3 d 分离 293
11 2 4 朴素贝叶斯 294
11 2 5 生成式模型 296
11 2 6 马尔可夫毯 297
11 2 7 作为过滤器的图 298
11 3 序列模型 299
潜变量 301
习题 302
第 12 章 Transformer 305
12 1 注意力 306
12 1 1 Transformer 处理 308
12 1 2 注意力系数 308
12 1 3 自注意力 309
12 1 4 网络参数 310
12 1 5 缩放自注意力 312
12 1 6 多头注意力 313
12 1 7 Transformer 层 315
12 1 8 计算复杂性 316
12 1 9 位置编码 317
12 2 自然语言 319
12 2 1 词嵌入 320
12 2 2 分词 321
12 2 3 词袋模型 322
12 2 4 自回归模型 323
12 2 5 递归神经网络 324
12 2 6 通过时间的反向传播 325
12 3 Transformer 语言模型 326
12 3 1 解码器型 Transformer 326
12 3 2 抽样策略 329
12 3 3 编码器型 Transformer 330
12 3 4 序列到序列 Transformer 332
12 3 5 大语言模型 333
12 4 多模态 Transformer 336
12 4 1 视觉 Transformer 336
12 4 2 图像生成 Transformer 337
12 4 3 音频数据 339
12 4 4 文本语音转换 340
12 4 5 视觉和语言 Transformer 342
习题 343
第 13 章 图神经网络 347
13 1 基于图的机器学习 348
13 1 1 图的属性 349
13 1 2 邻接矩阵 349
13 1 3 排列等变性 350
13 2 神经信息传递 351
13 2 1 卷积滤波器 352
13 2 2 图卷积网络 353
13 2 3 聚合算子 354
13 2 4 更新算子 356
13 2 5 节点分类 357
13 2 6 边分类 358
13 2 7 图分类 358
13 3 通用图网络 359
13 3 1 图注意力网络 359
13 3 2 边嵌入 360
13 3 3 图嵌入 360
13 3 4 过度平滑 361
13 3 5 正则化 362
13 3 6 几何深度学习 362
习题 363
第 14 章 采 样 365
14 1 基本采样 366
14 1 1 期望 366
14 1 2 标准分布 367
14 1 3 拒绝采样 369
14 1 4 适应性拒绝采样 370
14 1 5 重要性采样 371
14 1 6 采样 - 重要性 - 重采样 373
14 2 马尔可夫链蒙特卡洛采样 374
14 2 1 Metropolis 算法 375
14 2 2 马尔可夫链 376
14 2 3 Metropolis-Hastings 算法 378
14 2 4 吉布斯采样 380
14 2 5 祖先采样 382
14 3 郎之万采样 383
14 3 1 基于能量的模型 384
14 3 2 化似然 385
14 3 3 朗之万动力学 386
习题 388
第 15 章 离散潜变量 391
15 1 K 均值聚类 392
图像分割 395
15 2 高斯混合分布 397
15 2 1 似然函数 399
15 2 2 似然 400
15 3 EM 算法 404
15 3 1 高斯混合模型 406
15 3 2 EM 算法与K 均值算法的关系 408
15 3 3 混合伯努利分布 409
15 4 证据下界 412
15 4 1 EM 算法回顾 413
15 4 2 独立同分布数据 415
15 4 3 参数先验 415
15 4 4 广义 EM 算法 416
15 4 5 顺序 EM 算法 416
习题 417
第 16 章 连续潜变量 421
16 1 主成分分析 422
16 1 1 方差表述 423
16 1 2 最小误差表述 424
16 1 3 数据压缩 427
16 1 4 数据白化 428
16 1 5 高维数据 429
16 2 概率潜变量 430
16 2 1 生成式模型 431
16 2 2 似然函数 432
16 2 3 似然法 433
16 2 4 因子分析 436
16 2 5 独立成分分析 437
16 2 6 卡尔曼滤波器 439
16 3 证据下界 439
16 3 1 EM 算法 441
16 3 2 PCA 的 EM 算法 442
16 3 3 因子分析的 EM 算法 444
16 4 非线性潜变量模型 444
16 4 1 非线性流形 445
16 4 2 似然函数 447
16 4 3 离散数据 448
16 4 4 构建生成式模型的 4 种方法 448
习题 449
第 17 章 生成对抗网络 453
17 1 对抗训练 454
17 1 1 损失函数 455
17 1 2 实战中的 GAN 训练 456
17 2 图像的生成对抗网络 458
CycleGAN 459
习题 462
第 18 章 标准化流 465
18 1 耦合流 467
18 2 自回归流 470
18 3 连续流 472
18 3 1 神经 ODE 472
18 3 2 神经 ODE 的反向传播 473
18 3 3 神经 ODE 流 474
习题 476
第 19 章 自编码器 479
19 1 确定性的自编码器 480
19 1 1 线性自编码器 480
19 1 2 深度自编码器 481
19 1 3 稀疏自编码器 482
19 1 4 去噪自编码器 482
19 1 5 掩蔽自编码器 483
19 2 变分自编码器 484
19 2 1 摊销推理 487
19 2 2 重参数化技巧 488
习题 491
第 20 章 扩散模型 493
20 1 前向编码器 494
20 1 1 扩散核 495
20 1 2 条件分布 496
20 2 反向解码器 497
20 2 1 训练解码器 499
20 2 2 证据下界 499
20 2 3 重写 ELBO 501
20 2 4 预测噪声 502
20 2 5 生成新的样本 504
20 3 得分匹配 505
20 3 1 得分损失函数 506
20 3 2 修改得分损失 506
20 3 3 噪声方差 508
20 3 4 随机微分方程 508
20 4 有引导的扩散 509
20 4 1 有分类器的引导 510
20 4 2 无分类器的引导 510
习题 513
附 录 517
附录 A 线性代数 517
A 1 矩阵恒等式 517
A 2 迹和行列式 518
A 3 矩阵导数 519
A 4 特征向量 521
附录 B 变分法 524
附录 C 拉格朗日乘子 526
参考资料 529
索 引 549

在留言区参与互动发送(我想要一本赠书)
并点击转发朋友圈,邀好友助力点赞你的留言
我们将选点赞率最高的1名读者获得赠书1本
时间以公众号推文发出24小时为限
记得扫码加号主微信,以便联系邮寄地址哦
欢迎自购或向图书馆荐购

微信群


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢