

引言
构建“大视觉语言模型”(Multimodal Large Language Models,简称 MLLMs)已经成为多模态领域的研究热潮。从最初的GPT-4-Vision,到后来的Qwen-VL、DeepSeek-VL 等模型,这些系统已能同时理解文字和图像,广泛应用于图文问答、图像推理、医学辅助诊断等任务。为了比较它们的能力,研究者也推出了越来越多的多模态评估基准,例如 MME、MMBench、MMMU 等(如图 1(a) 所示)。然而,问题也随之而来:评测成本正迅速成为瓶颈。
与纯文本模型相比,多模态模型需要同时处理图像和文本,大大增加了输入长度;再加上许多工作还会引入chain-of-thought(CoT)提示、使用ChatGPT人工辅助打分,这些都让一次完整的评估变得昂贵又耗时。那么问题来了:有没有可能在不牺牲评估准确性的前提下,大幅提升评估效率?
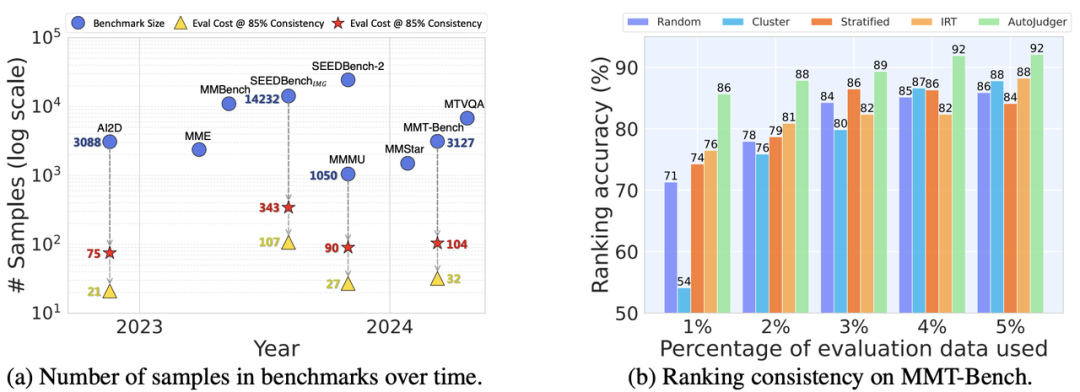
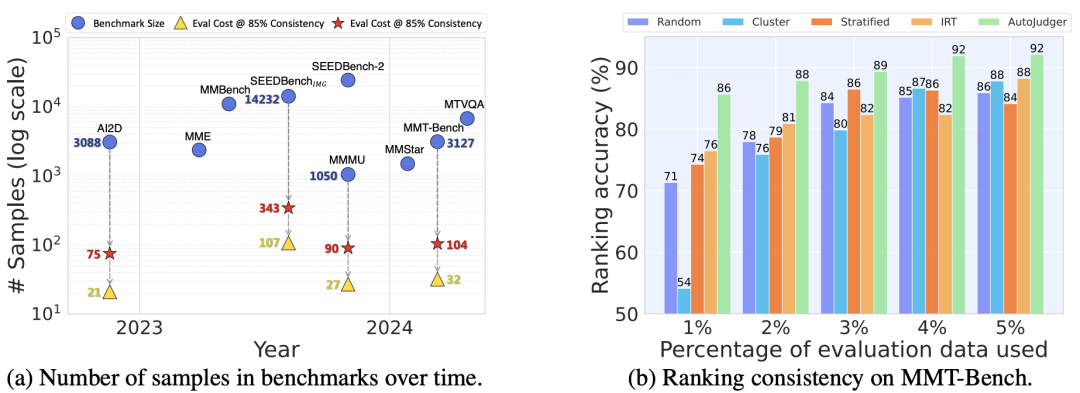
图1:AutoJudger 的评测规模与效率表现。(a) 展示了多种常用于多模态大模型(MLLM)评估的基准规模。图中三角形与五边形标记分别表示 AutoJudger 在与完整评估结果达到 85% 与 90% 一致性时所需的样本数量。(b) 在 MMT-Bench 上对比了多种高效评测方法。AutoJudger 仅使用 4% 的数据(125 个样本)即可达到 92% 的排名一致性。
为此,近期出现了一些“高效评测”的探索方向,比如从完整基准集中挑选少量具有代表性的小样本子集。然而,已有的方法大多只适用于文本领域,基于题目类别、难度等级等信息进行抽样,但多模态评测则面临更多挑战:
大多数多模态评测基准并未明确标注问题的难度。 图文对语义信息丰富,依赖类别等粗粒度特征难以保障抽样题目的语义多样性。 模型间性能差异显著,统一子集评测可能导致区分效率低,例如对强模型分配大量简单问题信息增益有限。
面对这些挑战,我们提出了一个新的解决方案——AutoJudger:一个面向多模态模型的智能体驱动的自动评测系统, 只需要一小部分数据,就能实现 85% 到 90% 的评测一致性(如图1(a)所示)。我们将评估过程类比为一场“面试”:AutoJudger作为面试官,在庞大的题库中与模型交互,动态提问、判断能力,完成高效精准的能力评测。
我们在多个主流基准上对AutoJudger进行了全面测试,覆盖17个代表性MLLMs。我们发现:AutoJudger只使用原始题库中的4%样本数量,就能在MMBench上实现92%的排名一致性(如图1(b)所示)。
问题定义
随着多模态大模型(MLLMs)体量增大,全面评测成本急剧上升。为了能够降低评测带来的算力资源消耗,我们希望在评测少量试题的前提下得到尽可能准确的结果。
设完整测试集为 ,目标是选择一个子集 ,使得模型 在 上的表现 与其在 上的表现 尽可能一致:
其中,表示一致性度量函数,为一致性阈值。进一步地,我们希望在多个模型 上保持排名一致性,问题可形式化为:
其中表示压缩比例,本文默认。
AutoJudger
AutoJudger 是一个面向多模态大模型(MLLM)的自动化、智能化评测框架,模拟“人类面试官”动态提问的机制,以提升评测效率与题目适配性。它通过将模型能力估计与样本难度建模相结合,实现了针对大规模题库的精细化样本选择与智能迭代评测。整体流程包括五大核心模块(如下图的图2所示):
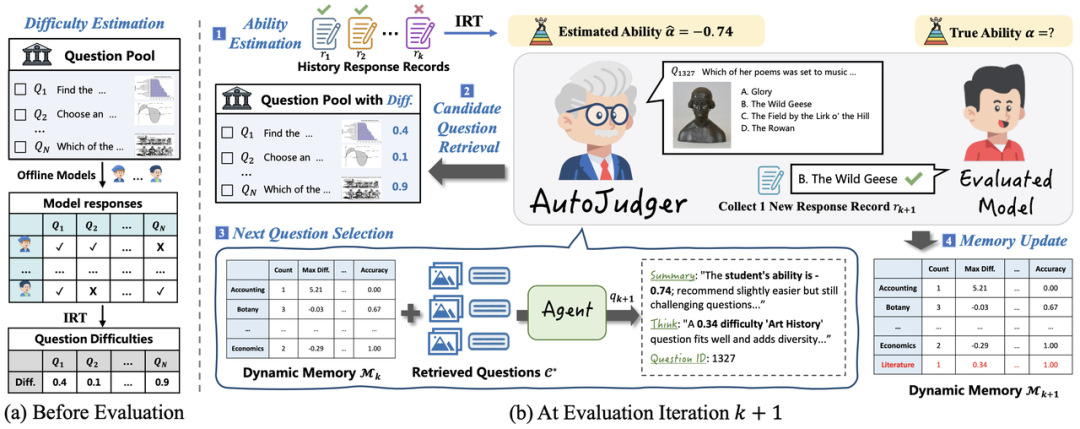
图2:AutoJudger 的整体框架。在评估开始前,系统通过一组离线模型对基准测试中的问题难度进行预估。在每一轮评估中,AutoJudger 首先根据当前对模型能力的估计检索候选问题,随后选择最合适的问题,获取被评估模型的回答,并更新其内部记忆。
问题难度估计
AutoJudger 在评测前,采用项目反应理论(Item Response Theory, IRT) 中的 Rasch 模型,借助一批离线大模型对评测题目的回答记录,拟合出每道题的难度参数。IRT 提供的公式如下:
其中表示模型能力,表示题目难度。通过最大似然估计,在保持评测模型和离线模型集不重合的前提下,构建全题库的难度先验,为后续自适应评测打下基础。
模型能力估计
AutoJudger 在每轮评测后,根据当前模型对已评测题目集合的答题记录,使用 IRT 模型实时估计模型的当前能力。通过构造基于似然函数的目标函数,并采用二分搜索高效求解,获取最能解释当前答题情况的能力值,用于指导下一轮样本选择。
候选问题检索
面对大规模题库,AutoJudger 首先进行能力范围筛选:仅保留回答概率在 0.2–0.8 的题目(避免过难/过易题)。再进一步应用max-min 语义检索策略,鼓励语义多样性:
我们保留与之间欧几里得距离最大的前五个问题作为最终候选集合。由此,这种具备语义感知能力的检索策略能够确保所选问题不仅与实时能力相匹配,同时引入新的语义覆盖,从而增强问题集的多样性与代表性。
下一题推荐
在获得候选问题集合之后,我们引导面试官智能体对候选问题进行细粒度语义分析,并推荐被测模型的下一个问题,形式化定义如下:
由于面试官智能体由能力强大的多模态大语言模型提供支持,我们充分利用其多模态理解与推理能力,对候选问题进行深入分析。具体而言,智能体综合考虑以下因素:
面试历史记录; 被测模型在当前轮次的能力评估结果; 候选问题集合中每个问题的语义特征; 候选问题对应的难度信息。
通过上述多因素联合分析,智能体能够展现清晰的推理过程,从 中选择出最适合作为下一轮评估的问题 ,以实现能力匹配与语义覆盖的平衡。最终,我们将该问题加入已评估的问题集合中,更新为。面试官智能体的详细提示设计与输入构造可参考原文附录 F。
动态记忆机制
为在评估过程中保持上下文连贯性,AutoJudger 引入了记忆机制。该机制强调长期的统计感知能力,通过构建语义推断类别的 Markdown 表格,持续积累关于历史选题与模型回答的高层信息。鉴于许多评测基准缺乏预定义类别标签,或存在标注噪声,AutoJudger 基于语义特征对题目进行自动归类,并在新主题出现时动态扩展类别表。
对于每一类题目,记忆机制会记录以下统计信息:问题数量、最大/最小/平均难度以及该类别下模型的总体准确率。这一机制使智能体具备全局视角,能够意识到不同语义领域的覆盖度与平衡性。一个典型的记忆表如下所示:
该记忆表体现了更贴近真实评估场景的使用方式,涵盖了多样的题目难度分布与不均衡的类别结构。例如,“艺术史”包含 20 道题目,覆盖范围广、准确率较高;而“会计学”则题目数量较少、难度更高且结果波动较大。
通过这一统计追踪机制,智能体可以识别出当前评估中语义覆盖不足或过于困难的领域,从而在后续迭代中实现更具针对性的问题选择与评估策略。
实验设置
本文在四个多模态评测基准(AI2D-Test、MMMU-Dev Val、SEEDBench-Image 和 MMT-Bench-Val)上验证了 AutoJudger 的效果,涵盖从简单图示题到复杂跨模态任务。评测智能体基于 Qwen-VL-7B-Instruct 构建,结合 CLIP ViT-B/32 进行语义检索。本文提出“排名一致性(Ranking Accuracy)”指标,用于衡量压缩评测与完整评测在模型排序上的一致性。基线方法包括统一采样(随机、分层、聚类)和模型自适应采样(基于 IRT 的难度匹配),以全面评估 AutoJudger 的准确性与稳定性。
主实验
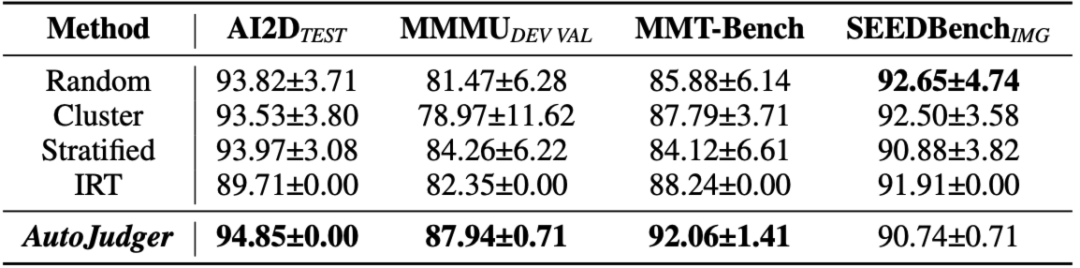
表1:5% 压缩比率下不同方法的性能。我们计算了平均排序准确率及相应的置信区间,最佳结果以粗体标出。可以看到AutoJudger在四个数据集中的三个取得了最佳效果,并具有良好稳定性。
在表1中,我们使用四个广泛使用的基准数据集中仅 5% 的样本,将我们的框架与几种高效的评测基线方法进行了比较。从中可以得出三个关键观察结论:
AutoJudger 在大多数基准测试中始终优于所有基线方法,显示出其在低数据量场景下的有效性。 与存在随机性的基线方法(如随机、分层、聚类)相比,AutoJudger 表现出显著更低的方差,表明其具有更高的稳定性和鲁棒性。 基于 IRT 的难度匹配方法(即,每次选取与当前被试者能力值最接近的难度的试题)作为一种确定性方法,虽然不引入随机性,但其性能并不理想——例如,在 MMMU 上 IRT 表现明显较差。
相比之下,AutoJudger 结合了实时模型反馈和历史记录,以动态选择合适的问题。这种自适应策略逐渐削弱了随机性带来的负面影响,在提升稳定性时实现了更优的性能。
此外,在下面的图3中,我们比较了不同压缩比例下各种方法的性能与稳定性:
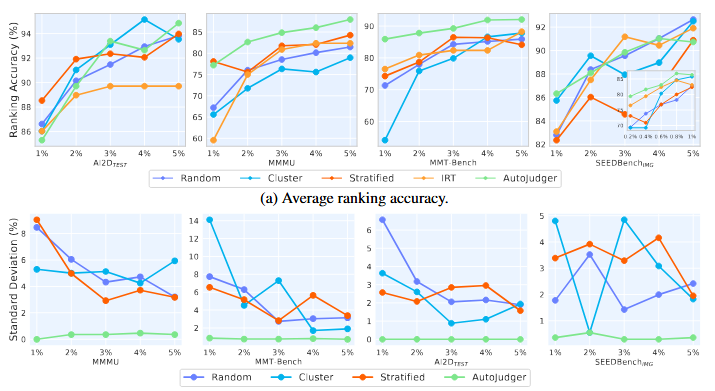
图3:不同压缩比例下不同方法的平均效果和波动性表现。
从评估准确性来看,所有基准方法在相对简单的 AI2D 基准测试上表现良好;但在 MMT 和 MMMU 等复杂基准测试上,AutoJudger 显示出持续且显著的优势。我们认为 AutoJudger 在 SEEDBench 上提升较小的原因在于该数据集本身规模较大——约为其他数据集的四倍,因此即使 5% 的采样也已包含足够多的数据供收敛。为此,我们进一步探索了更低的压缩率,发现当压缩率低于 1% 时,AutoJudger 的优势再次变得非常明显。总之,这些结果表明,AutoJudger 能够在复杂基准上以更低的成本实现可靠的评估。 从稳定性的角度来看,显然所有基准方法都需要较大的子集来确保评估的稳定性,而正如前所述,AutoJudger 采用了一种自适应策略,能够有效在不同数据规模下保持稳定性。
分析与发现
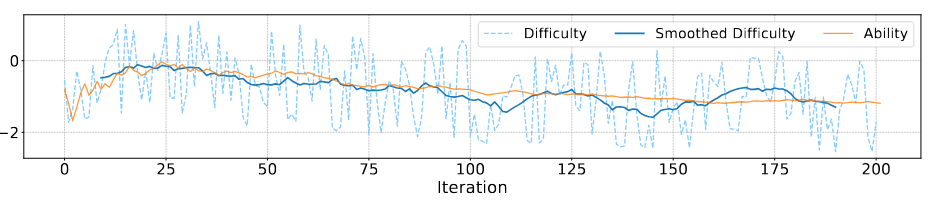
图4:MiniCPM-V-2 能力估计值与问题难度在 MMMU评估过程中的演变趋势。“Smoothed difficulty”是指最近 20 个问题的平均难度,而“difficulty”表示每次迭代中所选择问题的实际难度。
AutoJudger 的设计旨在挑选出既符合模型能力、又具有最大多样性的题目。为了验证这一设计,我们首先考察了模型能力估计值与所推荐题目难度之间的关系。如图4所示,AutoJudger 能够自适应地选择那些难度动态匹配被评估模型能力的题目。
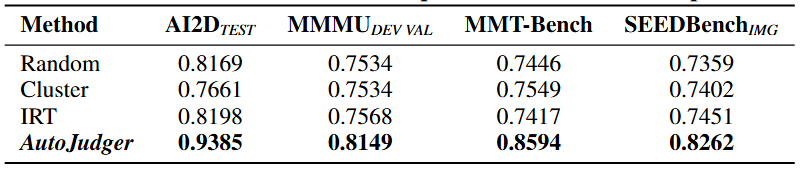
表2:5%压缩比例下不同方法平均语义距离
在难度匹配的基础上,我们进一步评估 AutoJudger 是否能在所选题目中保持语义上的多样性。我们通过 CLIP ViT-B/32 生成的嵌入向量之间的平均欧几里得距离来量化所选题目之间的语义相似性。如表2所示,AutoJudger 所选题目的平均语义距离显著高于其他方法所选题目的平均距离,这表明 AutoJudger 在语义多样性方面表现更优。
总结
AutoJudger 提供了一种高效、准确、可扩展的多模态模型评测方案,适用于大规模模型开发和部署场景。通过结合项目反应理论与智能采样策略,AutoJudger 显著降低了评测成本,同时保持了评测结果的高质量和一致性。未来的工作将探索更多语义嵌入策略和自适应评测机制,进一步提升评测系统的智能化水平。
使用说明
AutoJudger的数据以及评估框架已经开源,请参考https://github.com/IMNearth/AutoJudger。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区计算中心

点击“阅读原文”跳转至Github
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢