

Stanford CS224W: Machine Learning with Graphs
By Alexander Hurtado + Aditya Iswara as part of the Stanford CS 224W Final Project
https://github.com/jbcdnr/gretel-path-extrapolation
https://github.com/alexanderjhurtado/cs224w_wikinet
https://colab.research.google.com/drive/1geXYFIopoh7W4bLFrICqdkh1HuVySLQn?usp=sharing
介绍
在本篇博文中,我们将探讨现代图机器学习技术在Wikispeedia 导航路径(https://snap.stanford.edu/data/wikispeedia.html)数据集上的应用。我们的目标是根据玩家之前访问过的页面路径,预测其目标维基百科页面。
West 和 Leskovec此前已在未使用图神经网络的情况下解决了类似的问题[1]。Cordonnier和 Loukas也曾使用图卷积网络(在 Wikispeedia 图上进行非回溯随机游走)解决了这个问题(https://github.com/jbcdnr/gretel-path-extrapolation)[2]。我们的技术与这两篇论文不同,并显示出一些有希望的结果。
数据+问题陈述
我们的数据来自斯坦福网络分析项目(SNAP) (http://snap.stanford.edu/index.html)的数据集。该数据集捕捉了维基百科超链接网络上的导航路径,这些路径是由玩Wikispeedia 的玩家收集的。对于初学者来说,Wikispeedia 是Wikiracing游戏的一个版本。游戏规则很简单——玩家通过遍历连接不同页面的超链接,竞赛从维基百科上的源文章导航到设定的目标文章。
那么我们的任务是什么?给定数千名 Wikispeedia 用户创建的维基百科页面路径,如果我们知道用户迄今为止访问过的页面顺序,我们能否预测玩家的目标文章?我们能否利用图神经网络的表达能力来做到这一点?
数据预处理
准备用于图机器学习的数据集需要大量的预处理工作。我们的首要目标是将数据表示为一个有向图,以维基百科文章为节点,以连接文章的超链接为边。在这一步中,我们借助了Python 网络分析库NetworkX以及 Cordonnier & Loukas [2] 的先前研究成果。值得一提的是,Cordonnier & Loukas 巧妙地将 SNAP 数据集中的超链接图结构处理并编码为一个图形建模语言(GML) (https://networkx.org/documentation/stable/reference/readwrite/gml.html)文件,我们可以轻松地将其导入 NetworkX。
从这一点出发,我们的下一个目标是处理来自Cordonnier & Loukas 存储库(https://github.com/jbcdnr/gretel-path-extrapolation)和原始 SNAP 数据集的数据,以便为 NetworkX 图中的每一篇文章添加节点级属性。对于每个节点,我们希望包含页面的入度和出度,以及文章内容的概念,该概念由与文章中每个单词对应的 FastText 预训练词向量的平均值表示。同样,Cordonnier & Loukas 已在文本文件中对每个页面的入度和对应的文章词向量进行了处理和编码。此外,我们希望将每篇文章的层级分类概念(例如,“猫”页面的分类为“科学 > 生物学 > 哺乳动物”)添加到其对应的节点。为了实现此功能,我们使用Pandas处理了来自 SNAP 数据集的类别数据,以解析制表符分隔的值,从而为每篇文章生成一个多热向量,描述文章所属的类别。我们能够使用库的set_node_attributes方法将新文章属性添加到 NetworkX 图中的每个相应节点。
| import | |
| # read our graph from file | |
| # define our new node attributes | |
| # add our new attributes to the graph | |
create_networkx_graph.py
现在,我们的 NetworkX 图已锁定、加载完毕,随时可以运行!然而,我们仍然需要处理和定义输入数据和标签——也就是导航路径和目标文章。与之前类似,我们使用 pandas 解析 SNAP 数据集中已完成导航路径的制表符分隔值。然后,我们处理每条导航路径,移除返回点击(由 Wikispeedia 玩家从当前页面导航回上一个页面时创建),并截断每条路径中的最后一篇文章,以生成目标文章(即数据标签)。最后,我们丢弃所有长度超过 32 个超链接点击的导航路径,并将每条导航路径填充至 32 个,以生成清理后的导航路径(即数据输入)。
总而言之,我们处理的数据集产生了超过 50,000 条导航路径,这些路径连接着 4000 多篇不同的维基百科文章。
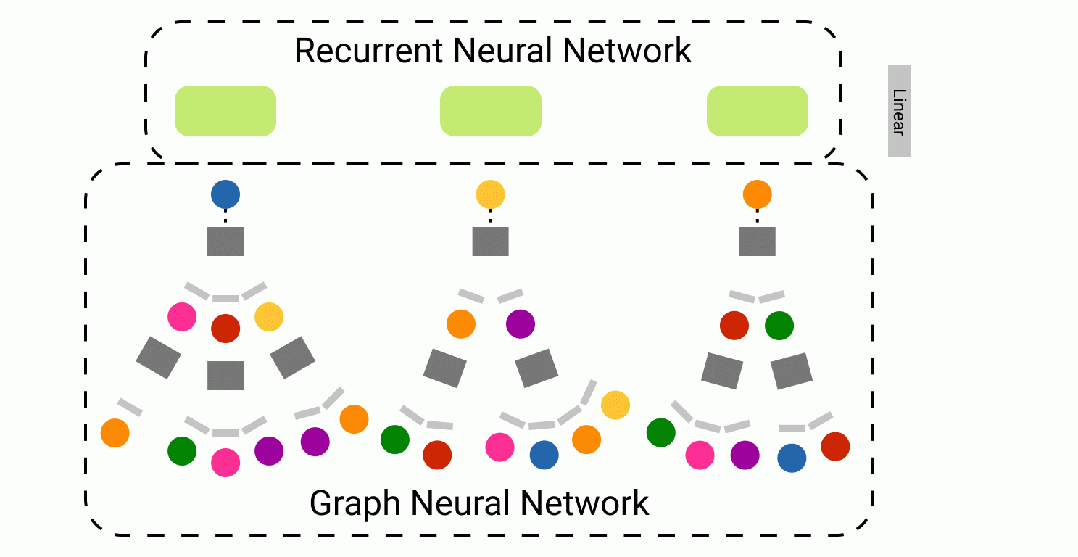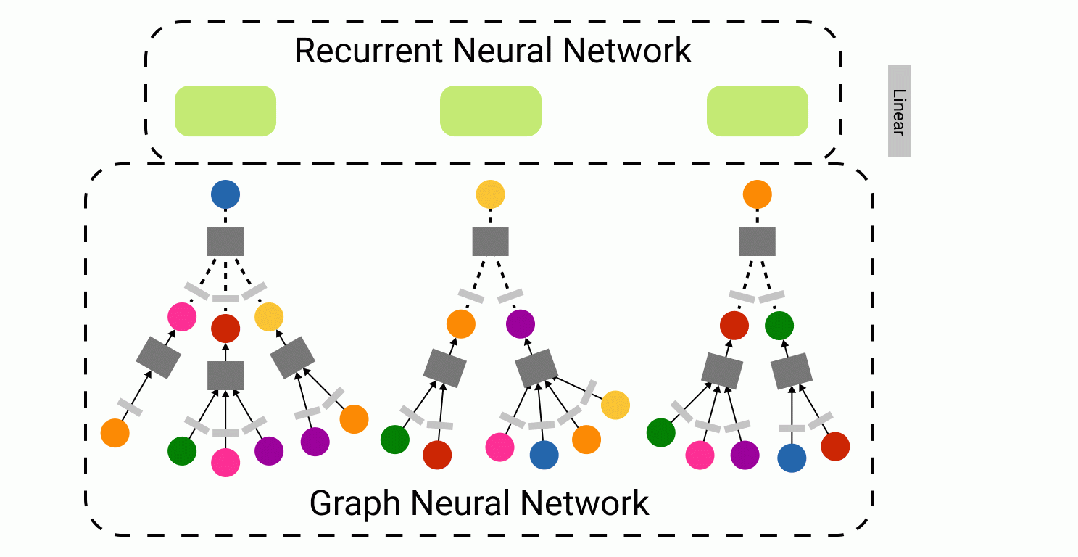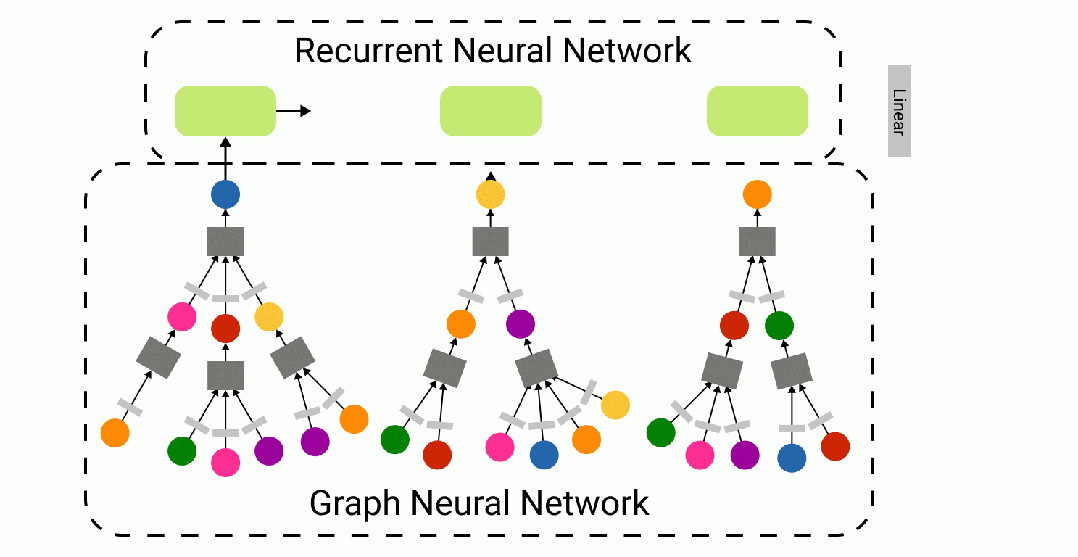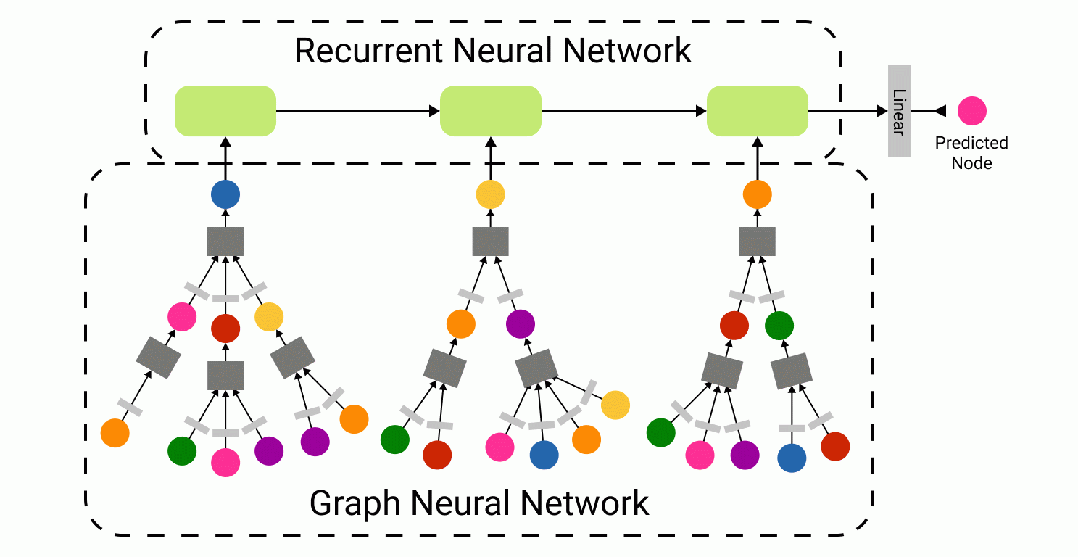
WikiNet 模型架构
WikiNet 前向传播的动画 — 使用 Figma 制作
我们针对给定导航路径预测 Wikispeedia 中目标文章的创新方法,尝试将循环神经网络 (RNN) 捕捉序列知识的能力与图神经网络 (GNN) 表达图网络结构直觉的能力相结合。我们提出了WikiNet——一种 RNN-GNN 混合网络。
| import | |
| import | |
| from | |
| from | |
| # convert our networkx graph into a PyTorch Geometric (PyG) graph | |
| # define our PyTorch model class | |
| classModel(torch.nn.Module): | |
| def__init__(self, pyg_graph): | |
| super().__init__() | |
| def forward(self, indices): | |
| return F.log_softmax(predictions, dim=1) |
networkx_to_pyg_model.py
WikiNet 接收一批页面导航路径作为我们的模型输入。这些路径以节点索引序列的形式表示。每条导航路径的长度都被填充到 32——我们从序列开头的索引为 -1 的地方填充了较短的序列。然后,我们使用图神经网络获取现有的节点属性,并为超链接图中的每个维基百科页面生成大小为 64 的节点嵌入。对于缺失的节点(例如:索引为 -1 的填充“节点”),使用全 0 的张量作为节点嵌入。
在调用生成分批路径并将其作为节点嵌入序列之后,我们将该张量输入到批量归一化层以稳定训练。然后,我们将该张量输入到循环神经网络(在本例中为长短期记忆(LSTM) 模型)中。在将张量输入到最终的线性层之前,对 RNN 的输出应用另一个批量归一化层。该线性层将 RNN 输出投影到 4064 个类别之一,每个潜在目标节点对应一个类别。最后,对得分应用对数 softmax函数。
WikiNet 图神经网络变体
我们将讨论在 WikiNet 实验中用于生成节点嵌入的三种图神经网络类型——图卷积网络、图注意力网络和GraphSAGE。
首先,让我们讨论一下图神经网络的一般工作原理。在图神经网络中,关键思想是根据每个节点的局部邻域为其生成节点嵌入。也就是说,我们可以将信息从其邻近节点传播到每个节点。
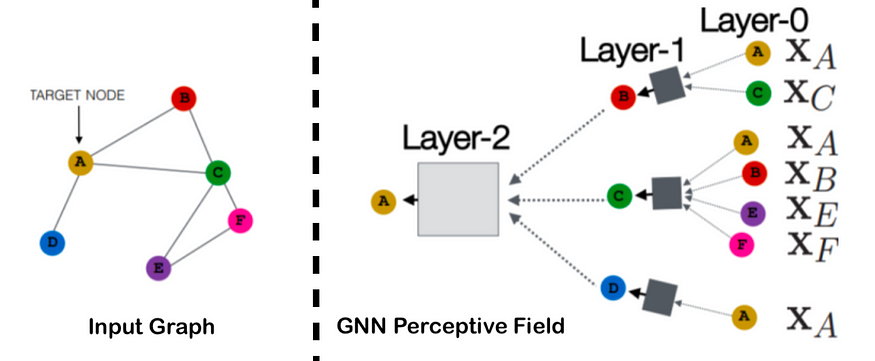
左:输入图 — 右:目标节点 A 的 GNN 计算图
上图表示输入图的计算图。x_u表示给定节点 u 的特征。这是一个简单的两层示例,尽管 GNN 计算图的深度可以是任意的。我们将节点u在第n层的输出称为节点u的“第n层嵌入”。
最初,在第 0 层,每个节点的嵌入由其初始节点特征x给出。在较高层次上,第k层嵌入由第 ( k-1 ) 层嵌入生成,方法是聚合来自每个节点邻居集合的第k层嵌入。这促使每个 GNN 层执行一个两步过程:
1.消息计算
2.聚合
在消息计算中,我们将节点的第k层嵌入传递给“消息函数”。然后,在聚合过程中,我们使用“聚合函数”聚合来自节点邻居以及节点本身的消息。更具体地说,我们有:

图卷积网络(GCN)
一种简单直观的消息计算方法是使用神经网络。为了进行聚合,我们可以简单地取邻居节点消息的平均值。在GCN中,我们还将使用一个偏置项来聚合节点本身在前一层的嵌入。最后,我们将这个输出传递给一个激活函数(例如ReLU)。因此,该方程如下所示:
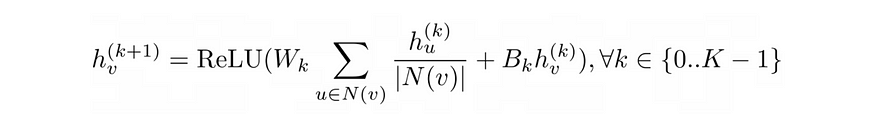
图卷积网络的更新规则
在这里,我们可以训练参数矩阵W_k和B_k作为机器学习管道的一部分。[3]
GraphSAGE
GraphSAGE 与 GCN 有几个不同之处。在该模型中,消息在聚合函数中计算,该函数由两个阶段组成。首先,我们聚合节点的邻居——在本例中使用均值聚合。然后,我们通过连接节点上一层的嵌入来聚合节点本身。此连接乘以权重矩阵W_k,并通过激活函数得到输出 [4]。计算第 ( k+1 ) 层嵌入的整体公式如下:

GraphSAGE 的更新规则
图注意力网络(GAT)
GAT 的设计动机在于,并非所有邻居节点都具有同等重要性。GAT 与 GCN 类似,但我们不是进行简单的均值聚合,而是使用注意力权重来对节点进行加权 [5]。具体而言,更新规则如下:
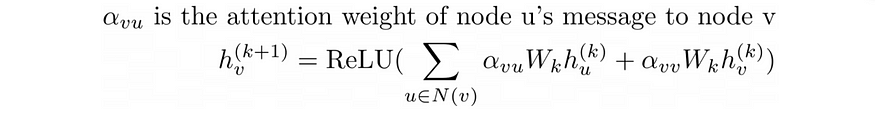
图注意力网络的更新规则
我们可以看到,GCN 的更新规则与 GAT 的更新规则相同:
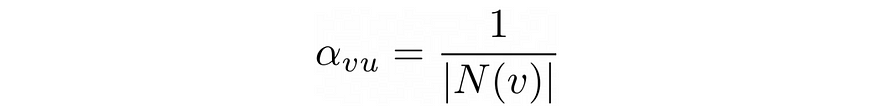
需要注意的是,与权重矩阵不同,注意力权重并非每个层都独有。为了计算这些注意力权重,我们首先计算注意力系数。对于每个节点v和邻居u,该系数的计算公式如下:

然后,我们可以使用 softmax 函数计算最终的注意力权重,以确保权重总和为 1:
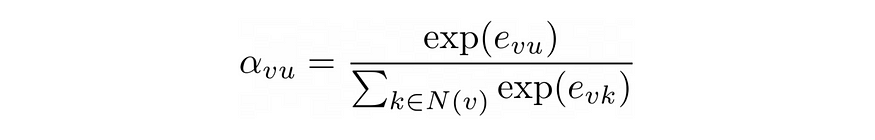
这使我们能够联合训练注意力权重和权重矩阵。
训练参数
为了训练模型,我们按照 90/5/5% 的比例将数据集随机拆分为训练、验证和测试数据集。我们使用Adam 算法作为训练优化器,并使用负对数似然作为损失函数。我们使用了以下超参数:

WikiNet 训练超参数
实验结果

WikiNet实验结果
我们评估了针对 WikiNet 的三种 GNN 变体的目标文章预测准确率。这类似于 Cordonnier & Loukas [2] 使用的 precision@1 指标。我们的每个 GNN-RNN 混合模型在目标文章预测上的绝对准确率都比基于节点特征运行的纯 LSTM 基线模型高出 3% 到 10%。我们使用 GraphSAGE 作为模型的 GNN 变体,报告的最高准确率达到了 36.7%。看来,图神经网络能够捕捉和编码维基百科页面局部邻域结构的信息,这使得其在目标文章预测方面的表现显著优于单纯的导航路径序列。
参考文献
[1] West, R. & Leskovec, J. Human Wayfinding in Information Networks (2012), WWW 2012 — Session: Web User Behavioral Analysis and Modeling
[2] Cordonnier, J.B. & Loukas, A. Extrapolating paths with graph neural networks (2019).
[3] Kipf, T.N. & Welling, M. Semi-Supervised Classification with Graph Convolutional Networks (2017).
[4] Hamilton, W.L. & Ying, R. & Leskovec, J. Inductive Representation Learning on Large Graphs (2018).
[5] Veličković, P. et al. Graph Attention Networks (2018).



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢