
在大模型逐渐成为智能系统核心引擎的今天,检索增强生成(RAG)技术为解决模型的知识盲区以及提升响应准确性提供了关键性的解决方案。本书围绕完整的RAG系统生命周期,系统地拆解其架构设计与实现路径,助力开发者和企业构建实用、可控且可优化的智能问答系统。
首先,本书以“数据导入—文本分块—信息嵌入—向量存储”为主线,详细阐述了从多源文档加载到结构化预处理的全流程,并深入解析了嵌入模型的选型、微调策略及多模态支持;其次,从检索前的查询构建、查询翻译、查询路由、索引优化,到检索后的重排与压缩,全面讲解了提高召回质量和内容相关性的方法;接下来,介绍了多种生成方式及RAG 系统的评估框架;最后,展示了复杂RAG范式的新进展,包括GraphRAG、Modular RAG、 Agentic RAG和Multi-Modal RAG的构建路径。
本书适合AI研发工程师、企业技术负责人、知识管理从业者以及对RAG系统构建感兴趣的高校师生阅读。无论你是希望快速搭建RAG系统,还是致力于深入优化检索性能,亦或是探索下一代AI系统架构,本书都提供了实用的操作方法与理论支持。
适读人群 :AI研发工程师、产品经理、企业技术负责人 计算机、人工智能相关专业学生 后端开发工程师
咖哥继AI Agent之后的又一力作,给程序员最实用的RAG实战课
从零开始,一步步搭建个人和企业的知识库
不使用任何框架,深入解析RAG的十大组件,纯手工打造RAG系统
基于DeepSeek、LangChain、LlamaIndex、开源嵌入模型和Milvus的知识库构建指南

作者:黄佳 著
年份:2025
出版社:人民邮电出版社、异步图书
书籍汇总:
链接: https://pan.baidu.com/s/1FFw_24YdJIUfLGunRGT_7g?pwd=9at9
链接: https://pan.baidu.com/s/1wp1sxh_p5Cv9dI5OpBaSCg?pwd=2arp

在留言区参与互动发送(我想要一本赠书)
并点击转发朋友圈,邀好友助力点赞你的留言
我们将选点赞率最高的1名读者获得赠书1本
时间以公众号推文发出24小时为限
记得扫码加号主微信,以便联系邮寄地址哦
欢迎自购或向图书馆荐购


关注我们丨文末赠书
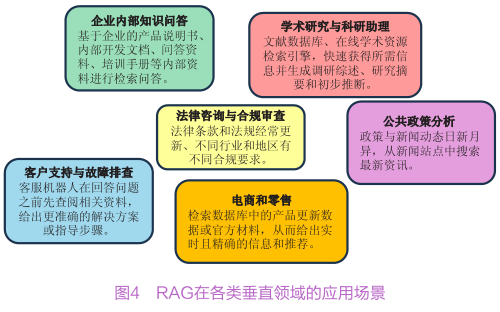
RAG这么火,你会用吗?
自从大模型技术走向市场以来,“幻觉”现象总是对用户造成困扰,而RAG(Retrieval-Augmented Generation,检索增强生成)技术正在成为解决这一难题的利器。国内众多科技大厂在实践RAG技术时都取得了阶段性的成果。
蚂蚁集团采用RAG技术,通过知识库分层构建、复杂文档处理、混合搜索策略和总结模型优化,答案获取效率提高约20%。
阿里云通过外挂知识库提供可靠知识,优化知识检索与答案生成流程,成功化解智能问答面临的幻觉、知识更新滞后、隐私数据泄露等挑战。
哔哩哔哩运用大模型升级智能客服系统,优化RAG链路和检索机制,构建全面的领域知识库,智能客服拦截率提升近30%。
字节跳动充分发挥RAG和FineTuning(微调)两种建设思路,利用大模型构建答疑机器人,实现研发基建部门答疑值班。
RAG这么厉害,很多小伙伴撸起袖子就想一气呵成地干好,但却没少碰壁,一是发现其所涵盖的技术栈特别广泛,二是实现过程中遇到技术难点后一筹莫展。难道要将AI所有的知识都学习一遍才能做好RAG吗?
其实不然,只要《大模型应用开发:RAG实战课》一书在手,就能轻松搞定!这本书不是简单地罗列操作过程,而是帮助读者构建整个RAG技术栈的认知体系和底层架构,这样一来,无论什么样的RAG框架和模型,读者都能从容实施,游刃有余。

▼点击下方,即可购书
我们先从探索RAG的技术核心开始,为应用实践做好准备。
RAG的核心
RAG的核心功能,就是它可以访问一个外部知识库或文档集,从中检索与当前问题相关的片段,将这些最新或特定领域的外部信息纳入“思考过程”,然后再进行回答生成。这使得大模型在回答问题时,不必依赖于其在训练过程中“记住”的知识,以此有效降低“幻觉”。
RAG使大模型能够“查阅资料”,将静态的、受限于训练时间的语言模型转变为能够动态获取信息、实时扩展知识的智能体。对大模型的“闭卷考试”瞬间变成了“开卷考试”,这种变化对大模型应用效果提升有着巨大潜力。
RAG的核心组件包括知识嵌入、检索器和生成器。
知识嵌入(Knowledge Embedding):将外部知识库的内容读取并拆分成块,通过嵌入模型将文本或其他形式的知识转化为向量表示,使其能够在高维语义空间中进行比较。这些嵌入向量捕捉了句子或段落的深层语义信息,并被索引存储在向量数据库中,以支持高效检索。
检索器(Retriever):负责从外部知识库(向量表示的存储)中查找与用户输入相关的信息。检索器采用嵌入向量技术,通过计算语义相似性快速匹配相关文档。常用的方法包括基于稀疏向量的BM25和基于密集向量的近似最近邻检索。
生成器(Generator):利用检索器返回的相关信息生成上下文相关的答案。生成器通常基于大模型,在内容生成过程中整合检索到的外部知识,确保生成的结果既流畅又可信。
为我们揭开RAG奥秘的本书作者黄佳,是新加坡科研局首席研究员(Lead Researcher),前埃森哲新加坡公司资深顾问。入行20多年来,他参与过政府部门、银行、电商、能源等多领域大型项目,积累了极为丰富的人工智能和大数据项目实战经验。

黄佳还是一位积极的技术分享者,他曾出版《大模型应用开发:动手做 AI Agent》《GPT 图解:大模型是怎样构建的》等多本畅销书。他的写作风格独特,书中常以人物“咖哥”引发讨论,通过对话来讲解技术理论与实践过程,帮助读者轻松进入AI技术的世界。
如今,黄佳看到知识浪潮迅速增长,众多技术人却迷失其中,抓不住学习的重点。因此,黄佳决定编写本书,帮助技术人去除糟粕,取其精华,深入理解大模型应用开发的本质,做好大模型时代的知识检索。
了解RAG的核心知识之后,我们现在可以跟着咖哥学习,从理论到实践全盘掌握RAG技术了。
跟着咖哥,全盘掌握RAG
RAG是大模型时代应用开发的一项伟大创新,弥补了单纯靠参数记忆知识的不足,使大模型在应对不断变化或高度专业化的问题时具有更强的适应性和灵活性。本书从RAG系统构建出发,逐步深入系统优化、评估以及复杂范式的探究,下面分为四个部分逐一详解。
RAG系统构建
这部分是RAG技术落地的第一步。在数据导入环节,书中详细讲解了如何读取与解析多样化的文件格式,包括TXT文本、CSV文件、网页文档、Markdown文件、PDF文件等,还有借助Unstructured工具从图片中提取文字并导入。
文本分块是影响检索精度与生成质量的关键步骤,书中介绍了按固定字符数、递归、基于格式或语义等多种分块策略。针对信息嵌入,介绍了从早期词嵌入到当下流行的OpenAI、Jina等现代嵌入模型,详细说明了如何对嵌入模型进行微调。
针对向量存储则介绍了Milvus、Weaviate等主流向量数据库,以及选型时在索引类型、检索方式、多模态支持等多方面因素的考量,为构建高效的向量存储系统提供依据。
RAG系统优化
优化是提升RAG系统性能的关键。在检索前处理中,介绍查询构建如何实现Text-to-SQL等复杂转换,查询翻译能将简单模糊的查询重写为精准表述,查询路由则通过逻辑路由等方式将查询导向最合适的数据源。
索引优化给出节点-句子滑动窗口检索、分层合并等实用方法,提高检索效率。检索后处理涵盖RRF、Cross-Encoder等重排手段,以及Contextual Compression Retriever等压缩技术,这些手段和技术可以对检索结果执行校正操作。
在响应生成阶段,通过改进提示词、选择适配的大模型,采用Self-RAG等优化方式,提升生成内容的质量,确保系统输出既准确又符合用户需求。
RAG系统评估
评估是度量RAG系统性能的重要手段。书中构建了全面的评估体系,评估数据集为测试提供基础素材,检索评估通过精确率、召回率等7种指标,度量系统从知识库中获取相关信息的能力。响应评估基于n-gram匹配、语义相似性等3类指标,判断生成回答的质量。
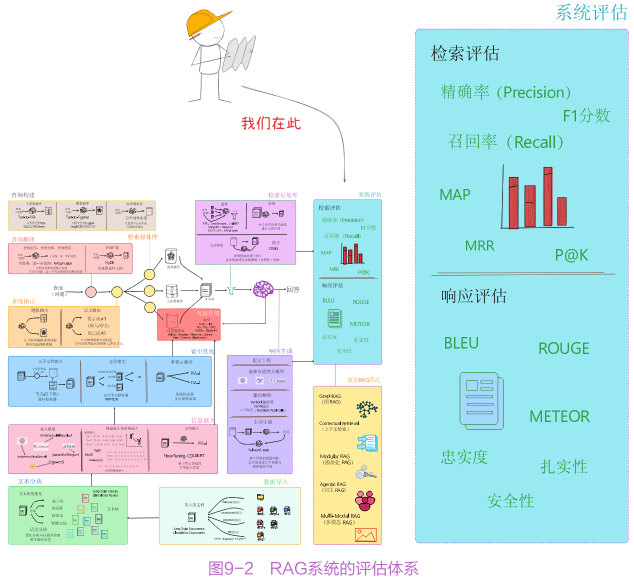
该部分还介绍了RAGAS、TruLens等4种评估框架,帮助读者从不同维度对RAG系统进行量化分析,清晰了解系统在准确性、相关性、可靠性等方面的表现,进而有针对性地进行改进。
复杂RAG范式
最后一部分是对RAG技术的前沿探索,包括以下RAG范式:
GraphRAG:整合知识图谱,提升对复杂问题的处理能力;
上下文检索:突破传统上下文限制的困境,为用户提供更贴合语境的回答;
Modular RAG:实现从固定流程到灵活架构的转变;
Agentic RAG:引入自主代理驱动机制,让系统具备更强的自主性和智能性;
Multi-Modal RAG:实现多模态检索增强生成,支持文本、图像、音频等多种信息融合。
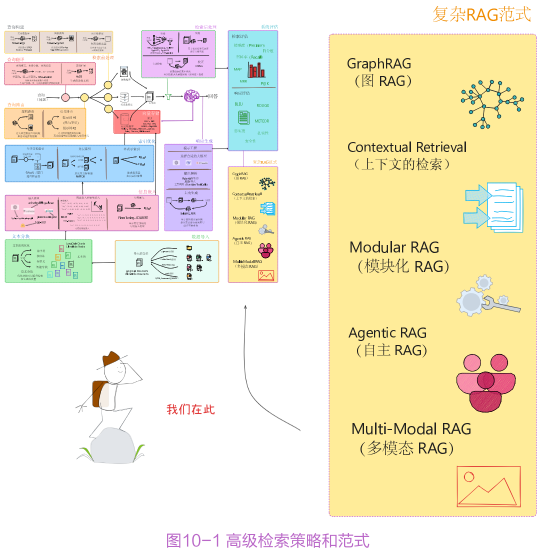
经过这四个部分的系统化学习,读者将打下RAG的理论基础,并掌握RAG实施的方法与工具,大力提升大模型的工作效能。
结语
RAG实现了“模型的智力”与“人类知识宝库”的有机结合,使得智能系统更加紧密地嵌入实际业务流程,为用户提供始终符合时代、情境、专业要求的智慧服务。《大模型应用开发:RAG 实战课》的适时推出,为广大技术人打开了通往大模型应用开发的大门。
本书的一大特点是内容完整、体系化,从RAG技术的基本概念、在大模型应用开发技术演进路径中的位置讲起,深入RAG系统的核心组件、执行流程,再到系统构建的各个环节,包括数据导入、文本分块、信息嵌入、向量存储等,以及系统优化、评估和复杂范式的拓展,形成了一套完整的知识体系。
同时,作者通过虚拟人物“咖哥”“小冰”“小雪”之间生动有趣的对话展开技术讨论,以通俗易懂的语言讲解复杂的概念,评价模型与技术工具的技术特点,方便读者理解理论并掌握实践原则。

▲精彩书摘
本书的另一大特点是实战至上,书中提供了丰富的实践指导内容,在每个关键环节都给出详细的代码示例、工具使用方法和操作步骤,读者可以将理论知识快速应用到实际项目中。

无论是初学者想要快速搭建RAG系统,还是有一定经验的专业人员想要致力于深入优化检索性能、探索新的AI系统架构,都能从书中获取有价值的信息和实用的方法。
—END—
原创
初审:刘鑫
复审:栾传龙
终审:孙英
【目录】
楔子 闹市中的古刹 001
开篇 RAG三问 003
一问 从实际项目展示到底何为RAG 003
文档的导入和解析 005
文档的分块 005
文本块的嵌入 006
向量数据库的选择 006
文本块的检索 007
回答的生成 008
二问 如何快速搭建RAG系统 008
使用框架:LangChain的RAG实现 011
使用框架:通过LCEL链进行重构 016
使用框架:通过LangGraph进行重构 018
不使用框架:自选Embedding模型、向量数据库和大模型 020
使用coze、Dify、FastGPT等可视化工具 023
三问 从何处入手优化RAG系统 025
第 1章 数据导入 028
1.1 用数据加载器读取简单文本 030
1.1.1 借助LangChain读取TXT文件,以生成Document对象 030
1.1.2 LangChain中的数据加载器 031
1.1.3 用LangChain读取目录中的所有文件 032
1.1.4 用LlamaIndex读取目录中的所有文档 034
1.1.5 用LlamaHub连接Reader并读取数据库条目 036
1.1.6 用Unstructured工具读取各种类型的文档 038
1.2 用JSON加载器解析特定元素 040
1.3 用UnstructuredLoader读取图片中的文字 042
1.3.1 读取图片中的文字 042
1.3.2 读取PPT中的文字 043
1.4 用大模型整体解析图文 044
1.5 导入CSV格式的表格数据 048
1.5.1 使用CSVLoader导入数据 048
1.5.2 比较CSVLoader和UnstructuredCSVLoader 050
1.6 网页文档的爬取和解析 051
1.6.1 用WebBaseLoader快速解析网页 051
1.6.2 用UnstructuredLoader细粒度解析网页 052
1.7 Markdown文件标题和结构 054
1.8 PDF文件的文本格式、布局识别及表格解析 057
1.8.1 PDF文件加载工具概述 057
1.8.2 用PyPDFLoader进行简单文本提取 059
1.8.3 用Marker工具把PDF文档转换为Markdown格式 060
1.8.4 用UnstructuredLoader进行结构化解析 063
1.8.5 用PyMuPDF和坐标信息可视化布局 069
1.8.6 用UnstructuredLoader解析PDF页面中的表格 072
1.8.7 用ParentID整合同一标题下的内容 073
1.9 小结 075
第 2章 文本分块 082
2.1 为什么分块非常重要 083
2.1.1 上下文窗口限制了块长度 084
2.1.2 分块大小对检索精度的影响 086
2.1.3 分块大小对生成质量的影响 088
2.1.4 不同的分块策略 088
2.1.5 用ChunkViz工具可视化分块 089
2.2 按固定字符数分块 090
2.2.1 LangChain中的CharacterTextSplitter工具 090
2.2.2 在LlamaIndex中设置块大小参数 092
2.3 递归分块 092
2.4 基于特定格式(如代码)分块 093
2.5 基于文件结构或语义分块 095
2.5.1 使用Unstructured工具基于文档结构分块 095
2.5.2 使用LlamaIndex的SemanticSplitterNodeParser进行语义分块 096
2.6 与分块相关的高级索引构建技巧 097
2.6.1 带滑动窗口的句子切分 097
2.6.2 分块时混合生成父子文本块 098
2.6.3 分块时为文本块创建元数据 100
2.6.4 在分块时形成有级别的索引 101
2.7 小结 103
第3章 嵌入生成 104
3.1 嵌入是对外部信息的编码 104
3.2 从早期词嵌入模型到大模型嵌入 107
3.2.1 早期词嵌入模型 108
3.2.2 上下文相关的词嵌入模型 108
3.2.3 句子嵌入模型和SentenceTransformers框架 109
3.2.4 多语言嵌入模型 111
3.2.5 图像和音频嵌入模型 112
3.2.6 图像与文本联合嵌入模型 112
3.2.7 图嵌入模型和知识图谱嵌入模型 113
3.2.8 大模型时代的嵌入模型 114
3.3 现代嵌入模型:OpenAI、Jina、Cohere、Voyage 114
3.3.1 用OpenAI的text-embedding-3-small进行产品推荐 114
3.3.2 用jina-embeddings-v3模型进行跨语言数据集聚类 116
3.3.3 MTEB:海量文本嵌入基准测试 118
3.3.4 各种嵌入模型的比较及选型考量 120
3.4 稀疏嵌入、密集嵌入和BM25 121
3.4.1 利用BM25实现稀疏嵌入 122
3.4.2 BGE-M3模型:稀疏嵌入和密集嵌入的结合 124
3.5 多模态嵌入模型:Visualized_BGE 125
3.6 通过LangChain、LlamaIndex等框架使用嵌入模型 126
3.6.1 LangChain提供的嵌入接口 127
3.6.2 LlamaIndex提供的嵌入接口 127
3.6.3 通过LangChain的Caching缓存嵌入 128
3.7 微调嵌入模型 129
3.8 小结 133
第4章 向量存储 134
4.1 向量究竟是如何被存储的 135
4.1.1 从LlamaIndex的设计看简单的向量索引 135
4.1.2 向量数据库的组件 141
4.2 向量数据库中的索引 144
4.2.1 FLAT 144
4.2.2 IVF 145
4.2.3 量化索引 146
4.2.4 图索引 147
4.2.5 哈希技术 148
4.2.6 向量的检索(相似度度量) 148
4.3 主流向量数据库 149
4.3.1 Milvus 150
4.3.2 Weaviate 150
4.3.3 Qdrant 150
4.3.4 Faiss 151
4.3.5 Pinecone 151
4.3.6 Chroma 151
4.3.7 Elasticsearch 151
4.3.8 PGVector 152
4.4 向量数据库的选型与测评 152
4.4.1 向量数据库的选型 152
4.4.2向量数据库的测评 154
4.5 向量数据库中索引和搜索的设置 155
4.5.1 Milvus向量操作示例 155
4.5.2 选择合适的索引类型 159
4.5.3 选择合适的度量标准 167
4.5.4 在执行搜索时度量标准要与索引匹配 171
4.5.5 Search和Query:两种搜索方式 172
4.6 利用Milvus实现混合检索 173
4.6.1 浮点向量、稀疏浮点向量和二进制向量 174
4.6.2 混合检索策略实现 175
4.6.3 使用Milvus实现混合检索系统 176
4.7 向量数据库和多模态检索 180
4.7.1 用Visualized BGE模型实现多模态检索 181
4.7.2 使用ResNet-34提取图像特征并检索 186
4.8 RAG系统的数据维护及向量存储的增删改操作 189
4.8.1 RAG系统中的数据流维护与管理 189
4.8.2 Milvus中向量的增删改操作 190
4.8.3 向量数据库的集合操作 191
4.9 小结 192
第5章 检索前处理 194
5.1 查询构建——Text-to-SQL和Text-to-Cypher 196
5.1.1 Text-to-SQL——自然语言到SQL的转换 196
5.1.2 Text-to-Cypher——从自然语言到图数据库查询 206
5.1.3 Self-query Retriever——自动从查询中生成元数据过滤条件 210
5.2 查询翻译——更好地阐释用户问题 216
5.2.1 查询重写——将原始问题重构为合适的形式 216
5.2.2 查询分解——将查询拆分成多个子问题 218
5.2.3 查询澄清——逐步细化和明确用户的问题 221
5.2.4 查询扩展——利用HyDE生成假设文档 226
5.3 查询路由——找到正确的数据源 229
5.3.1 逻辑路由——决定查询的路径 231
5.3.2 语义路由——选择相关的提示词 232
5.4 小结 234
第6章 索引优化 236
6.1 从小到大:节点-句子滑动窗口和父子文本块 237
6.1.1 节点-句子滑动窗口检索 238
6.1.2 父子文本块检索 240
6.2 粗中有细:利用IndexNode和RecursiveRetriever构建从摘要到细节的索引 243
6.3 分层合并:HierarchicalNodeParser和RAPTOR 246
6.3.1 使用HierarchicalNodeParser生成分层索引 247
6.3.2 使用RAPTOR递归生成多层级索引 249
6.4 前后串联:通过前向/后向扩展链接相关节点 252
6.5 混合检索:提高检索准确性和扩大覆盖范围 255
6.5.1 使用Ensemble Retriever结合BM25和语义搜索 255
6.5.2 使用MultiVectorRetriever实现多表示检索 259
6.5.3 混合查询和查询路由 261
6.6 小结 262
第7章 检索后处理 263
7.1 重排 264
7.1.1 RRF重排 264
7.1.2 Cross-Encoder重排 269
7.1.3 ColBERT重排 271
7.1.4 Cohere重排和Jina重排 273
7.1.5 RankGPT和RankLLM 276
7.1.6 时效加权重排 277
7.2 压缩 279
7.2.1 Contextual Compression Retriever 280
7.2.2 利用LLMLingua压缩提示词 281
7.2.3 RECOMP方法 285
7.2.4 Sentence Embedding Optimizer 287
7.2.5 通过Prompt Caching记忆长上下文 288
7.3 校正 288
7.4小结 296
第8章 响应生成 298
8.1 通过改进提示词来提高模型输出质量 299
8.1.1 通过模板和示例引导生成结果 299
8.1.2 增强生成的多样性和全面性 300
8.1.3 引入事实核查机制以提升真实性 301
8.2 通过输出解析来控制生成内容的格式 302
8.2.1 LangChain输出解析机制 302
8.2.2 LlamaIndex输出解析机制 302
8.2.3 Pydantic解析 303
8.2.4 Function Calling解析 304
8.3 通过选择大模型来提高输出质量 304
8.4 生成过程中的检索结果集成方式 306
8.4.1 输入层集成 308
8.4.2 输出层集成 309
8.4.3 中间层集成 309
8.5 Self-RAG 310
8.6 RRR:动态生成优化 312
8.7 小结 315
第9章 系统评估 316
9.1 RAG系统的评估体系 317
9.1.1 RAG的评估数据集 317
9.1.2 检索评估和响应评估 318
9.1.3 RAG TRIAD:整体评估 319
9.2 检索评估指标 320
9.2.1 精确度 321
9.2.2 召回率 321
9.2.3 F1分数 322
9.2.4 平均倒数排名 322
9.2.5 平均精确度 322
9.2.6 逆文档频率加权精确度 323
9.2.7 文档精确度和页面精确度 323
9.3 响应评估指标 325
9.3.1 基于n-gram匹配程度的指标 325
9.3.2 基于语义相似性的指标 327
9.3.3 基于忠实度或扎实性的指标 328
9.4 RAG系统的评估框架 329
9.4.1 使用RAGAS评估RAG系统 329
9.4.2 使用TruLens实现RAG TRIAD评估 332
9.4.3 DeepEval:强大的开源大模型评估框架 333
9.4.4 Phoenix:交互式模型诊断分析平台 335
9.5 小结 335
第 10章 复杂RAG范式 337
10.1 GraphRAG:RAG和知识图谱的整合 338
10.2 上下文检索:突破传统RAG的上下文困境 339
10.3 ModularRAG:从固定流程到灵活架构的跃迁 340
10.4 AgenticRAG:自主代理驱动的RAG系统 343
10.5 Multi-Modal RAG:多模态检索增强生成技术 344
10.6 小结 345
参考文献 346
后记 一期一会 348
......

在留言区参与互动发送(我想要一本赠书)
并点击转发朋友圈,邀好友助力点赞你的留言
我们将选点赞率最高的1名读者获得赠书1本
时间以公众号推文发出24小时为限
记得扫码加号主微信,以便联系邮寄地址哦
欢迎自购或向图书馆荐购

微信群


内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢