

摘要
在瞬息万变的现实世界中,人工智能(AI)需要在时间紧迫、反馈稀缺的场景下迅速学习并做出精准决策,如搜索救援、灾难响应和医疗急救等高风险任务。然而,传统强化学习受限于稀疏奖励和高维视觉输入的复杂性,难以高效应对动态环境。人类引导的机器学习虽能通过反馈提升AI能力,但离散信号的粗糙性和高昂的人工成本限制了其应用。如何在降低人类负担的同时,让AI在复杂任务中实现实时、持续的优化?杜克大学与陆军研究实验室提出的GUIDE框架给出了突破性答案。GUIDE不仅在寻宝、捉迷藏等任务中展现出超越传统方法的性能,还为搜救机器人、医疗辅助等领域的人机交互与协同绘制了技术蓝图。本文将带你了解这一创新框架,揭示其在AI与人类的协作应用上的未来可能。
关键词:人工智能,人机交互,实时反馈,自主进化

班崭丨作者
Ava丨审校
如果你对大模型时代,人机如何交互与协作感兴趣,那强烈推荐你加入集智俱乐部最近策划的「大模型时代下的人机交互与协同」读书会。


论文题目:GUIDE: Real-Time Human-Shaped Agents
论文链接:https://neurips.cc/virtual/2024/poster/95640
为什么需要实时人类引导
为什么需要实时人类引导
在现实世界中,许多任务(如搜索救援、灾难响应和医疗急救)要求人工智能(AI)在时间紧迫、环境反馈稀疏的条件下快速学习并决策。传统强化学习(RL)方法在这些场景中常因两大瓶颈表现不佳:其一是稀疏奖励困境,即成功信号极少(例如仅在找到目标时获得奖励),导致智能体探索效率低下;其二是高维视觉输入的挑战,即从原始图像中提取有效特征并关联长期决策太过复杂。尽管人类引导的机器学习(Human-in-the-Loop)通过整合人类反馈来增强AI学习能力,但现有方法仍存在显著局限。例如,模仿学习或偏好反馈仅能提供“好/中/差”三类离散信号,无法传递细腻的行为指导;同时,这些方法依赖预先收集的离线数据集,难以适应动态环境变化,且持续的人工标注成本高昂。更关键的是,人类反馈本身受个体差异(如认知能力、反应速度)影响,其质量参差不齐。
如何设计一个既能有效减少人工输入的需求,又能允许持续训练的强化学习框架?
连续反馈与自动化模拟的双重创新
连续反馈与自动化模拟的双重创新
针对这一挑战,杜克大学与陆军研究实验室团队提出了GUIDE框架(Grounding Real-Time Human-Shaped Agents)。该框架通过两大技术创新实现了人机协作的突破。首先,连续反馈机制重新定义了人机交互模式:训练者通过鼠标在界面中连续滑动(而非点击按钮)实时评估智能体行为,反馈值范围从-1到1连续可调(图1)。这一设计不仅显著提升了人类反馈的信息密度(图2),还以更自然的交互方式减少操作干扰,保持训练流程连贯。

图1. 作者提出的GUIDE是一种新颖的实时人类引导智能体框架,无需人工培训即可实现持续反馈和不断改进。
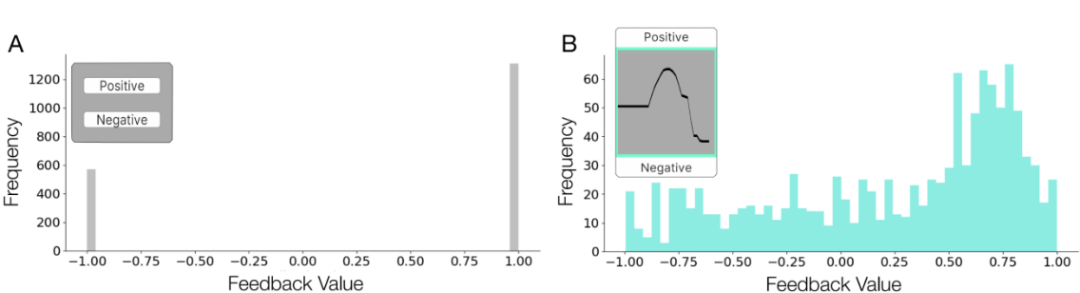
图2. 与传统的离散反馈(A)相比,同一实验对象在同一任务中提供的连续反馈(B)包含更丰富的信息。
其次,反馈模拟器的引入实现了从“人工指导”到“自主进化”的平滑过渡。在人类引导阶段,系统将连续反馈转化为密集奖励,与稀疏环境奖励融合驱动策略优化;进入自动化阶段后,神经网络模拟器在线学习人类反馈模式,逐步替代人工输入(图3)。关键技术层面,作者采用最先进的强化学习实现方法,对Deep TAMER (Training an Agent Manually via Evaluative Reinforcement)进行了改进,实现了处理连续动作空间的actor-critic框架,结合模型架构(即目标网络软更新, target net soft update)和优化策略(即Adam优化器代替随机梯度下降)方面的进展,不仅将Deep TAMER扩展到连续动作和最新的强化学习实践中,还保持了将实时人类反馈整合到学习过程中的核心方法。
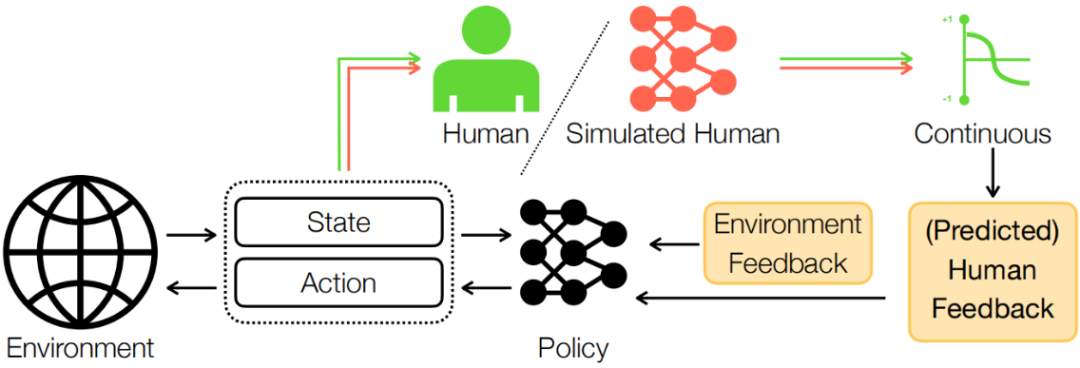
图3. GUIDE框架包括两个阶段: 在人工指导阶段,人工培训师会观察智能体的状态和行动,并提供实时、持续的反馈。反馈值被转化为每一步的密集奖励,并与环境奖励相结合。与此同时,作者训练一个人类反馈模拟器,该模拟器会接收状态和行动对(state-action pair),并对反馈值进行回归。在自动引导阶段,训练的模拟器会代替人类提供反馈,以继续改进策略,从而有效减少人类的工作量和认知负荷。
为验证框架有效性,研究团队在视觉导航(寻宝)、多体对抗(捉迷藏)和运动控制(保龄球)三类任务中展开系统性实验(图4)。结果显示,在仅接受10分钟人类反馈加10分钟自动化训练的条件下,GUIDE在寻宝任务中的成功率较DDPG(Deep Deterministic Policy Gradient)基线最高提升30%,在相同的人类指导时间下,较改进版c-Deep TAMER提升50%。值得注意的是,在动态对抗的捉迷藏任务中,智能体能够快速逼近专家设计的启发式奖励上限,且GUIDE达到基线相同性能所需的训练时间缩短一半,展现出显著的计算效率优势。
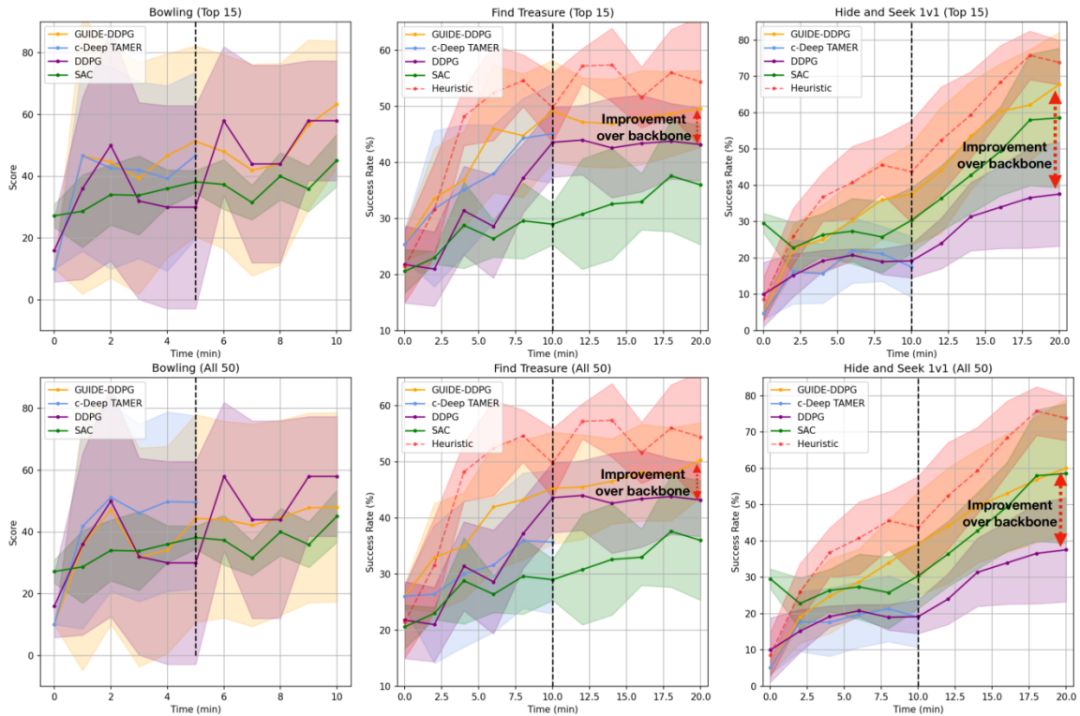
图4. GUIDE性能评估。在具有挑战性的任务(寻宝和捉迷藏任务)中,GUIDE的表现始终优于所有其他基线。
评估人类引导机器算法的一个重要方面是该方法对不同人类训练者的稳健性。当人类反馈模式发生改变时,通用的算法应仍能保持强大的性能。然而,通常由于人类参与者的规模限制(N < 10),之前的方法往往很少讨论这个方面。在图5中,所有普通用户(未经训练,N = 50)的平均成功率都大大超过了RL基准线,同时在具有挑战性的寻宝任务和捉迷藏任务中,成功率也超过了经过大幅增强的c-Deep TAMER。
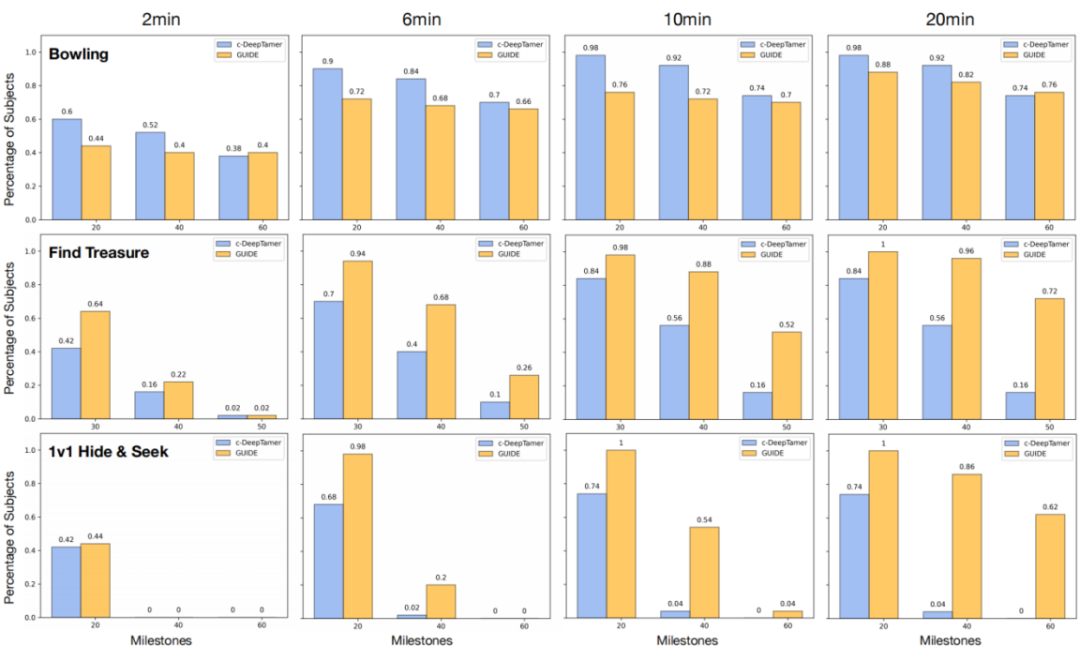
图5. GUIDE框架对个体差异的强稳健性。从左到右,显示了模型性能随训练时间的变化情况。在每个子图中,X轴是以任务得分量化的训练里程碑,Y轴表示在给定时间内能够训练智能体达到里程碑的人类比例。
从实验室到真实世界的挑战
从实验室到真实世界的挑战
尽管取得显著进展,GUIDE框架仍存在改进空间。当前实验集中于中等规模环境,超大规模部署(如城市级导航)的可行性尚未验证;人类反馈的异构性(如反应速度差异)可能影响训练稳定性,而反馈模拟器的黑箱特性潜藏奖励偏移风险。展望未来,研究团队提出三方面发展方向:通过整合语音、手势等多模态输入提升交互自然性;开发自适应延迟校准机制以匹配不同用户的认知负载;引入可解释AI技术监控模拟器决策逻辑,构建伦理安全屏障。这些改进将推动框架从实验室向真实世界应用跨越。
GUIDE框架的核心价值在于开创了人机协同的新范式。通过连续反馈与模拟替代的双阶段设计,它既能在10分钟指导内实现显著性能提升,降低人类负担,又通过自动化模块平衡自主性与可控性。这项工作不仅为稀疏奖励下的实时决策任务提供了高效解决方案,更为搜救机器人、医疗辅助系统等关键领域的人机协作绘制了技术蓝图。随着后续研究的深入,这种融合人类直觉与机器效率的混合智能体系,有望在复杂现实场景中释放更大潜能。
「大模型时代下的人机交互与协同」
读书会
集智俱乐部联合中国科学技术大学教授赵云波、华东师范大学副教授吴兴蛟两位老师共同发起「大模型时代下的人机交互与协同」读书会。本次读书会将探讨:
人类智能和机器智能各自的优势有哪些?智能边界如何?如何通过更有效的标注策略和数据生成技术来解决数据稀缺问题?如何设计更加高效的人机协作系统,实现高效共赢的效果?如何提高机器决策的可解释性与透明性,确保系统的可信度?如何通过多模态协作融合不同感知通道,应对复杂的决策任务?
读书会7月4日开始第一次分享,每周六进行,预计持续约8周,具体时间社群通知,诚挚邀请领域内研究者、寻求跨领域融合的研究者加入,共同探讨。

详情请见:人类与机器的智慧碰撞:人机协同的智能时代读书会启动
6. 探索者计划 | 集智俱乐部2025内容团队招募(全职&兼职)
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢