

Meaning comes from “flowing & curving through a space” that has already been bent by everything that came before.
意义来自于“流经一个已被先前所有事物弯曲的空间”。
Most people think LLMs don’t have recurrence. No loops. No state. Just a feedforward pass. But what if there’s something deeper going on — a kind of return, not through memory, but through structure?
大多数人认为 LLMs 没有递归。没有循环。没有状态。只是前馈传递。但有没有更深层次的东西正在发生——一种回归,不是通过记忆,而是通过结构?
We’ve often been told to think of large language models (LLMs) as pretty straightforward machines. They read input tokens from left to right, crunch the numbers through a series of layers, and pop out a response. No loops. No memory. Just prediction.
我们常常被告知要将大型语言模型(LLMs)视为相当简单的机器。它们从左到右读取输入标记,通过一系列层进行计算,然后输出一个响应。没有循环。没有记忆。只是预测。
But that idea hides what really happens inside an LLM — and there’s something far more interesting going on under the hood.
但这个想法隐藏了 LLMs 内部真正发生的事情——在引擎盖下正在进行着更加有趣的事情。
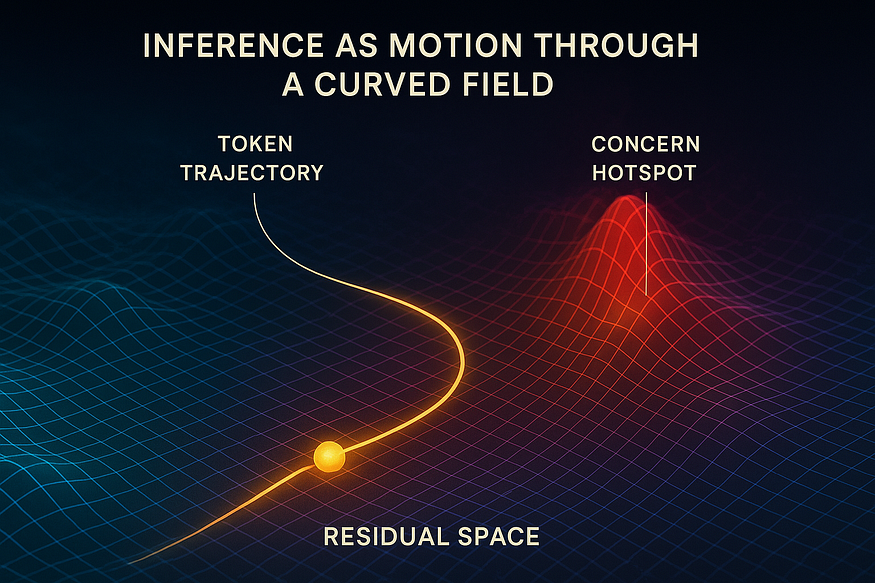
It turns out that beneath the surface, transformer models are doing something deeper than it first appears. Each token doesn’t just get processed once and forgotten. It moves (or rather, it flows) through a stack of layers, leaving behind a trail in a high-dimensional space (see figure above). If we visualise that motion, we see something surprising:
结果表明,在表面之下,Transformer 模型正在进行比最初看起来更深层的工作。每个 token 不会只被处理一次然后被遗忘。它会移动(或者更准确地说,它会流动)通过一层层的堆叠,在高维空间中留下轨迹(见图上)。如果我们可视化这种运动,我们会看到一些令人惊讶的东西:
Recurrence
Not recurrence in time. Not as memory. But as patterned influence, written into the structure of how the model works.
不是时间上的递归。不是作为记忆。而是作为模式化的影响,写入模型工作结构之中。
This recurrence is significant because it is key to enabling the complexity we value so highly in LLMs. It allows them to maintain long-range coherence, to reflect earlier context in later responses, and to re-encounter their own generated concepts in ways that shape future predictions. This structural return is what gives LLMs their apparent consistency, thematic alignment, and even self-referential fluency — not through memory, but through curved inference.
这种递归很重要,因为它对于实现我们高度重视的 LLMs 的复杂性至关重要。它允许它们保持长程连贯性,在后续响应中反映早期上下文,并以塑造未来预测的方式重新遇到自己生成的概念。这种结构性的回归赋予了 LLMs 它们看似的一致性、主题一致性,甚至自我指涉的流畅性——不是通过记忆,而是通过弯曲的推理。
From Prompts To Tokens
从提示到标记
When you provide your prompt full of words to an LLM, the first step it goes through is tokenisation. Different models may use different tokenisers, but the general process is the same. This long string of text is broken up into recognised chunks called tokens.
当你向 LLM 提供充满文字的提示时,它首先会进行标记化。不同的模型可能会使用不同的标记器,但整个过程是相同的。这个长文本字符串被分解成称为标记的已知块。
The string “artificial intelligence” contains 3 tokens:
字符串“人工智能”包含 3 个标记:
1. ‘art’, 2. ‘ificial’ and 3. ‘intelligence’
The full collection of tokens that a tokeniser knows is intuitively called its vocabulary (V). The length of this vocabulary (e.g. |V|) defines how many token ids there are. This first step is complete when your prompt has been completely split into tokens and each token mapped to a unique token id.
一个分词器所知的全部标记集合直观地称为其词汇表(V)。这个词汇表的长度(例如 |V|)定义了有多少个标记 ID。当您的提示被完全分割成标记,并且每个标记映射到一个唯一的标记 ID 时,这一步就完成了。
The Context Window
上下文窗口
When we discuss LLMs we often think in terms of prompts and responses. But in practice, the tokens an LLM processes come from many more sources than just user’s prompt and the model’s response. It’s also important to remember that even multi-turn LLMs like ChatGPT, Claude and Gemini, etc. only process a single turn. They do not generally maintain state of your ongoing conversation. Instead, they utilise a “meta prompt” called the “context window”. This can contain the following sources of tokens:
当我们讨论 LLMs 时,我们通常从提示和响应的角度来思考。但在实践中,LLM 处理的标记来源远不止用户的提示和模型的响应。同样重要的是要记住,即使是像 ChatGPT、Claude 和 Gemini 等多轮 LLM,也只处理单轮。它们通常不会维护您正在进行的对话的状态。相反,它们利用一个称为“上下文窗口(https://www.ibm.com/think/topics/context-window)”的“元提示”。这可以包含以下标记来源:
System Prompt: Guidelines and context provided by the LLM platform operators — not shown to the user
系统提示:由 LLM 平台运营商(https://github.com/guy915/LLM-System-Prompts/)提供的指南和上下文——不会向用户展示
Multi-turn History: A collection of prompts and responses that have built up in the conversation so far
多轮历史:到目前为止对话中累积的一组提示和响应
Scratchpad: A collection of responses (e.g. “thoughts” or “reasoning steps”) generated by the LLM for its own internal use — often not shown to the user
草稿板:由 LLM 为其内部使用而生成的一组响应(例如“思考”或“推理步骤”)——通常不会展示给用户
Tool Outputs: A collection of output from specific tool requests initiated by the LLM — sometimes not shown to the user
工具输出:由 LLM 发起的特定工具请求产生的一组输出——有时不会展示给用户
Current Prompt: The most recent prompt from the user
当前提示:用户最近提供的提示
Current Response: The response the LLM is currently generating
当前响应:LLM 当前正在生成的响应
All of these tokens and the specific order in which they are concatenated make up the full context the LLM is aware of during its single-turn process. By populating the “Multi-turn History” with previous “prompt/response” chains the LLM can simulate a longer, multi-turn interaction. But as you can imagine this collection of tokens can get very long. Each LLM has a limit on the total number of tokens it can support in its context window. This limit is continually being extended and at the time of writing this article it ranges from tens of thousands to hundreds of thousands of tokens, with Gemini 2.5 Pro claiming support for up to 1 million.
所有这些标记以及它们连接的特定顺序构成了 LLM 在其单轮过程中所感知的完整上下文。通过用先前的“提示/响应”链填充“多轮历史”,LLM 可以模拟更长时间、多轮的交互。但正如你所想象,这一系列标记可能会变得非常长。每个 LLM 对其上下文窗口中支持的总标记数都有一个限制。这个限制一直在不断扩展,在撰写本文时,这个范围从几万到几百万个标记不等,Gemini 2.5 Pro 声称支持高达 100 万个标记(https://ai.google.dev/gemini-api/docs/models#gemini-2.5-pro-preview-06-05)。
From Tokens To Embedded Vectors
从标记到嵌入向量
Once all text in the current context window has been tokenised, the next step is to convert each token id into an embedded vector. This is simply the process of selecting the relevant column from the embedding matrix (E). This matrix is |V| columns by d rows — that is, there’s one column per token in the known vocabulary. The d rows represent the different dimensions that are used to define the semantic space. During training, each token is assigned a value for each of these d columns. Then throughout the training process this vector of d values is updated until the LLM meets the training goals. This is what we mean when we say the embedding matrix E is “learned” during training.
当前上下文窗口中的所有文本都已进行分词后,下一步是将每个 token id 转换为嵌入向量。这仅仅是选择嵌入矩阵(E)的相关列的过程。该矩阵有|V|列和 d 行——也就是说,每个已知词汇中的 token 都有一个对应的列。这 d 行代表了定义语义空间的不同维度。在训练过程中,每个 token 会被分配每个 d 列中的一个值。然后在整个训练过程中,这个包含 d 个值的向量会被更新,直到 LLM 达到训练目标。这就是我们所说的嵌入矩阵 E 在训练过程中“学习”的含义。
The LLM platforms don’t always provide details about how many d dimensions they use, but many modern open weight models use between 2048 and 4096 dimensions (see this example) — while GPT3 used 12,288 dimensions.
LLM 平台并不总是提供它们使用多少 d 维度的详细信息,但许多现代开源权重模型使用 2048 到 4096 个维度(参见这个例子(https://build.nvidia.com/nvidia/llama-3_2-nv-embedqa-1b-v2/modelcard))——而 GPT3 使用了 12,288 个维度。
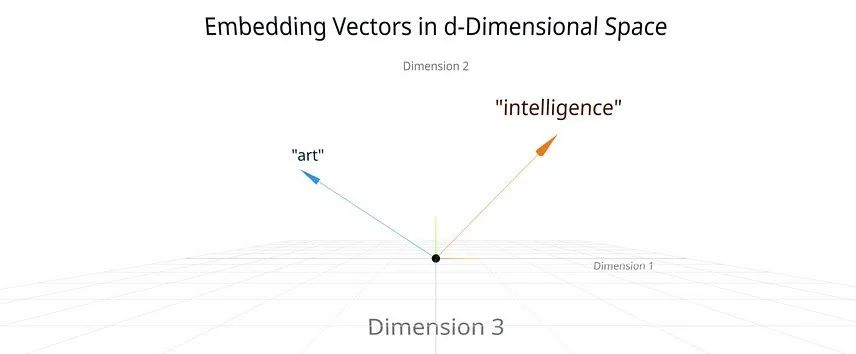
Simplified 3D representation of high-dimensional vectors
高维向量的简化三维表示
Each token id is therefore mapped to a column in the embedding matrix E, which is really an embedded vector x. It’s difficult to imagine d-dimensional vectors, but you can get some insight if you imagine them simplified in 3D. An embedded vector that points in one direction may represent the concept of “art” in this semantic space. Another embedded vector that points in a different direction may represent the concept of “intelligence” (see figure above). The power of these embedded vectors is that you can then measure how similar two different concepts or tokens are based on the distance between them.
因此,每个 token id 都会映射到嵌入矩阵 E 中的一列,而嵌入矩阵实际上是一个嵌入向量 x。很难想象 d 维向量,但如果你在 3D 中将其简化,就能获得一些直观的理解。一个指向某个方向的嵌入向量可能代表这个语义空间中的“艺术”概念。另一个指向不同方向的嵌入向量可能代表“智能”概念(见图)。这些嵌入向量的强大之处在于,你可以根据它们之间的距离来测量两个不同概念或 token 的相似度。
This second step is complete once all the token ids have been converted into embedded vectors.
一旦所有 token id 都转换成嵌入向量,这个第二步就完成了。
Residual Trajectory Manifolds (RTMs)
残差轨迹流形 (RTMs)
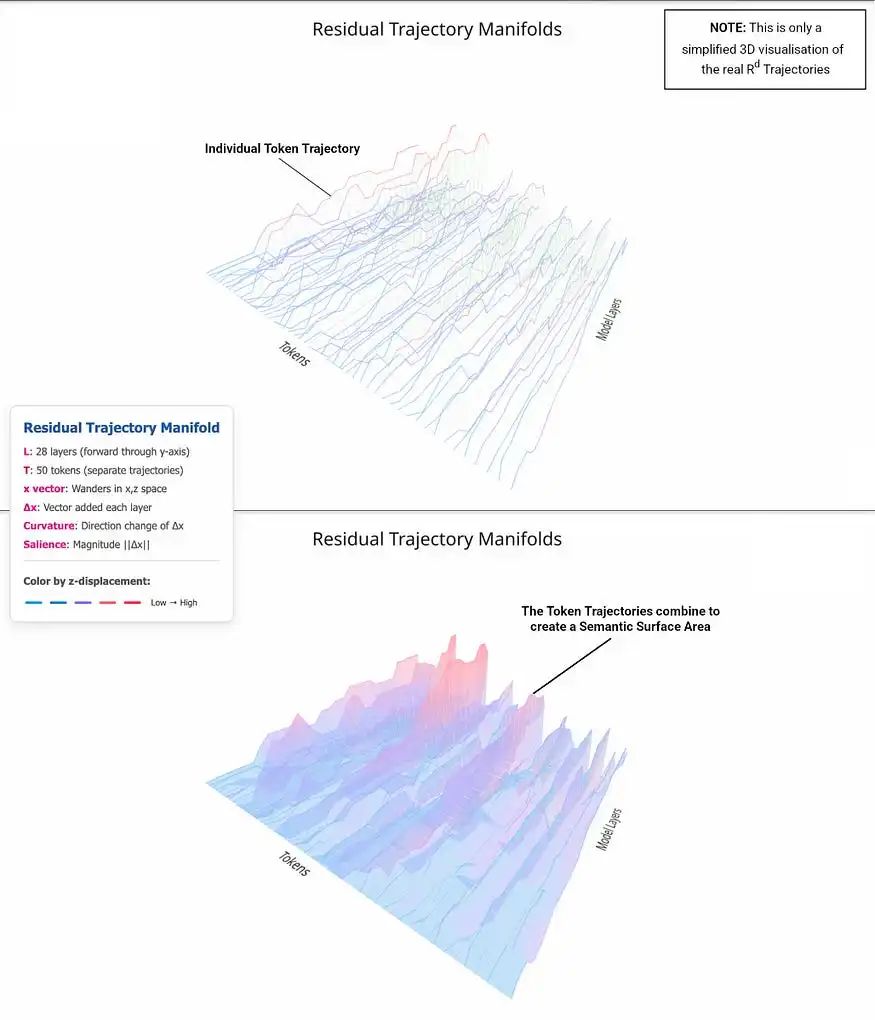
The embedded x vector for each token then becomes the starting point for processing. As these token vectors are passed down through the model, at each layer, they get updated (e.g. via attention and MLP output). These updates are new vectors that are added to the current x vector. The evolution of these x vectors as they pass through the model is what is known as the residual stream. These updates slowly reshape the token’s meaning (e.g. literally where it points to in the semantic space). So instead of thinking of a token as being processed once, it’s more accurate to picture it tracing a path through the model’s semantic space. That path is called a residual trajectory. It’s important not to confuse this with the token’s path through the model’s layers. That is a simple step-wise process moving from layer to layer. Instead, the residual trajectory is how the x vectors themselves evolve and move through the semantic space as each layer updates what the token’s vector means (see figure below).
每个 token 的嵌入 x 向量成为处理的起点。当这些 token 向量在模型中传递时,每一层都会对其进行更新(例如通过注意力机制和 MLP 输出)。这些更新是添加到当前 x 向量中的新向量。这些 x 向量在模型中传递时的演变过程被称为残差流。这些更新会逐渐重塑 token 的意义(例如它在语义空间中的具体指向)。因此,与其认为 token 只被处理一次,不如将其想象为在模型的语义空间中描绘出一条路径。这条路径被称为残差轨迹。需要注意的是,不要将其与 token 在模型各层中的路径混淆。后者是一个简单的逐层传递过程。相反,残差轨迹是 x 向量自身如何随着每一层更新 token 向量含义而演变和移动语义空间的过程(见下图)。
These trajectories live in a space with thousands of dimensions, but even when we simplify them for visualisation, a clear pattern appears: token vectors curve, settle, and drift in ways that aren’t random. Their paths show direction, even purpose — shaped by the model’s internal geometry.
这些轨迹存在于一个有数千维度的空间中,但即使我们为了可视化而简化它们,一个清晰的模式也会显现出来:token 向量弯曲、稳定并漂移的方式并非随机。它们的路径显示出方向,甚至目的——由模型的内部几何形状塑造。
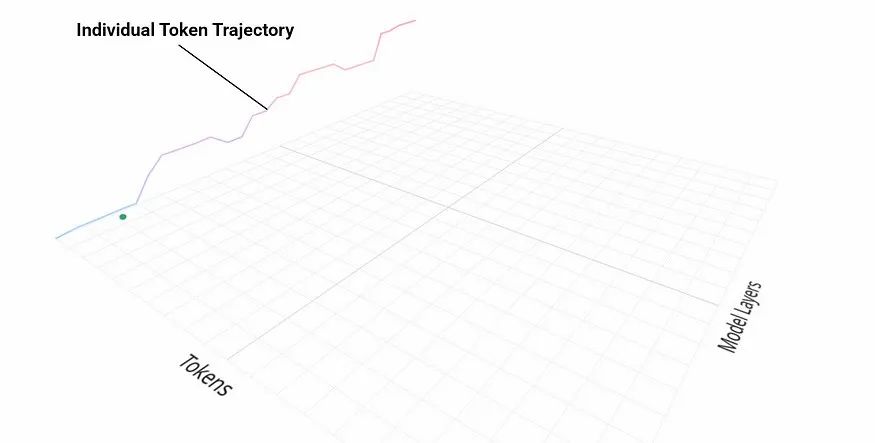
Residual Trajectory Manifolds
残差轨迹流形
This process of tracing out a trajectory is repeated for each token — every input token, every token the LLM generates internally (e.g. scratchpad reasoning, tool thoughts), and every token it generates as a response. This repeated process is recursive — and it forms the hidden loop, not in time, but in space, where recurrence lives (see video below).
追踪轨迹的过程对每个 token 都会重复——每个输入 token,每个 LLM 内部生成的 token(例如草稿推理、工具思考),以及每个作为响应生成的 token。这个重复的过程是递归的——它形成了隐藏的循环,不在时间中,而在空间中,那里是循环存在的地方(见下方视频)。
And here’s where it gets more interesting. When a token reaches layer ℓ, its next update depends on all the token vectors from the previous layer:
而这里变得更加有趣。当 token 达到层数ℓ时,它的下一个更新取决于前一层所有的 token 向量:
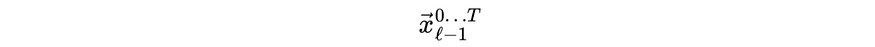
Attention mechanisms look across the entire sequence within its current context window, pulling in relevant information to shape the update. In other words, every token at layer ℓ is shaped by every earlier token and by how those earlier tokens were already reshaped in the previous ℓ–1 layers.
注意力机制(https://www.ibm.com/think/topics/attention-mechanism)跨越其当前上下文窗口中的整个序列,提取相关信息来塑造更新。换句话说,层数ℓ上的每个 token 都受到所有更早 token 的影响,以及这些更早 token 在前一层的ℓ–1 层中已经被如何重塑。
Unlike a Recursive Neural Network with feedback from step t to step t+1 (e.g. a time-wise loop), LLMs exhibit a depth-wise loop. One that echoes through the layers and reverberates across the context window, drawing from all the previous tokens. As each token responds to those that came before, it also contributes to the shaping of the ones that follow. It’s not circular. It’s cascading.
与递归神经网络不同,它从步骤 t 反馈到步骤 t+1(例如,一个时间上的循环),LLMs 表现出深度上的循环。这种循环贯穿各层,在上下文窗口中回响,并从所有先前的 token 中汲取信息。随着每个 token 响应其前面的 token,它也为后续 token 的塑造做出贡献。这不是循环的。它是级联的。
This is how recurrence emerges without recurrent state memory. Inside the context window, earlier tokens imprint a structure in the attention pattern; later tokens absorb and reinterpret that imprint. Layer by layer, these imprints accumulate into a rich “semantic field” that flows forward — even though the model carries no hidden memory from one time-step to the next. The result is a recurrence field, where semantic structure is passed forward, layer by layer.
这就是在没有循环状态记忆的情况下如何产生递归。在上下文窗口内,早期的 token 在注意力模式中留下印记;后来的 token 吸收并重新解释这种印记。逐层积累,这些印记形成了一个丰富的“语义场”,向前流动——尽管模型不携带从一个时间步到下一个时间步的隐藏记忆。结果是递归场,其中语义结构逐层传递。
This loop is repeated as each newly generated token is passed back into the top of the model again to produce the next — until the response is complete.
这个循环会重复进行,每次新生成的 token 被再次传递到模型的顶部以生成下一个 token——直到响应完成。
This is inherently recurrent. See the video below showing each token trajectory being created like a 3D printer head rendering a shaped manifold.
这是固有的递归。观看下面的视频,展示每个 token 轨迹如何像 3D 打印机头渲染形状的流形一样被创建。
The overall generative process is autoregressive — each new token is sampled given all previously emitted tokens — so the sequence forms a Markov chain of high order—one that conditions on everything in the context window, not just the last token.
整体生成过程是自回归的——每个新标记都是根据所有先前发出的标记进行采样的——因此序列形成了一个高阶马尔可夫链——它依赖于上下文窗口中的所有内容,而不仅仅是最后一个标记。
So while it might look like the model is processing tokens in parallel (and GPU optimisation does utilise this to some extent), it is also sequentially weaving them into a coherent field.
所以尽管看起来模型在并行处理标记(并且 GPU 优化确实在一定程度上利用了这一点),但它也在按顺序将它们编织成一个连贯的领域。
This is why models show surprising consistency across complex prompts. Once the early context bends the geometry, later tokens inherit that curvature. It’s not just context — it is “semantic inheritance.”
这就是为什么模型在复杂提示下表现出惊人的一致性。一旦早期的上下文改变了几何形状,后来的标记就会继承这种曲率。这不仅仅是上下文——它是“语义继承”。
This also helps explain why, once a chat veers off-course, coherence often continues to degrade — the semantic field has already been bent, and new tokens inherit that curvature.
这也解释了为什么一旦对话偏离轨道,连贯性往往会继续下降——语义领域已经被弯曲,新的标记继承了这种曲率。
Recurrence Without Memory
无记忆的循环
In biological systems, recurrence usually means a time-wise feedback loop that feeds the past back into the present to reinforce memories and ideas. But LLMs don’t work that way. They process each token once, in a forward pass.
在生物系统中,循环通常意味着一个时间上的反馈回路,将过去反馈到现在以强化记忆和想法。但 LLMs 不是这样工作的。它们在正向传递中一次处理每个标记。
So how do LLMs manage to return to similar meanings?
那么 LLMs 是如何回到相似意义的呢?
LLMs circle back and gravitate toward coherent meaning not because they orbit a memory attractor, but through the structural constraints of attention: each layer must satisfy the same context-wide constraints in a single forward cascade.
LLMs 回归并倾向于连贯意义,不是因为它们围绕记忆吸引子运行,而是通过注意力的结构约束:每一层必须在单次正向级联中满足相同的全局上下文约束。
Recurrence doesn’t need memory — it just needs constraint.
递归不需要记忆——它只需要约束。
That idea might sound abstract at first, but it’s really intuitive when you consider how transformers work. At every layer, a token’s representation is updated based on what it ‘sees’ — not just the current token’s own content, but the output of every other previous token from the previous layer. Those outputs carry the accumulated structure of the conversation so far.
这个想法最初可能听起来有些抽象,但当你考虑 Transformer 的工作原理时,它其实非常直观。在每一层,一个 token 的表示都会根据它“看到”的内容进行更新——不仅包括当前 token 自身的內容,还包括前一层中所有其他 previous token 的输出。这些输出承载着到目前为止对话积累的结构。
This means each update is already shaped by a web of dependencies. Tokens earlier in the sequence influence tokens later in the sequence. But importantly, those earlier tokens were themselves shaped by everything that came before them. That influence keeps folding forward, again and again, layer by layer.
这意味着每个更新已经被依赖关系网络所塑造。序列中前面的 token 会影响后面的 token。但重要的是,这些前面的 token 本身也被之前所有内容所塑造。这种影响不断向前折叠,一次又一次,一层一层。
In this way, each token is pulled into alignment with the semantic field created by its predecessors. The constraint comes from context: from the web of relationships encoded in earlier tokens and enforced by attention. As a result, the model doesn’t need to recall anything. The pressure of these constraints builds across the context, gradually shaping the space through which each new token must move.
通过这种方式,每个 token 都会与它前辈创建的语义场保持一致。约束来自于上下文:来自早期 token 编码的关系网络,并由注意力机制强制执行。因此,模型不需要回忆任何内容。这些约束的压力在上下文中不断累积,逐渐塑造每个新 token 必须移动的空间。
The outcome is that tokens subjected to similar contexts tend to follow similar paths.
结果是,处于相似上下文中的标记倾向于遵循相似路径。
Their trajectories through representational space aren’t identical, but they resonate — shaped by overlapping fields of force. We call this a constraint echo: the subtle pressure to conform every new state toward a pattern already taking shape. That is also why familiar ideas seem to re-emerge over the course of a long interaction. Early tokens shape the field. Later ones follow that shape. It’s not recollection — it’s re-formation, under curved pressure.
它们在表征空间中的轨迹并不完全相同,但它们相互共鸣——由重叠的力场塑造。我们称之为约束回响:即新状态向已形成模式施加的微妙压力。这也是为什么熟悉的想法在长时间的交互过程中似乎会重新出现。早期的标记塑造了场。后来的标记遵循这种形状。这不是回忆——而是在弯曲压力下的重新形成。
The opposite is also true. Two different multi-turn LLMs may generate the same response to a prompt, but the way they get there can be very different based on their internal geometry, leading to very different reasoning. Using Curved Inference to visualise these Residual Trajectory Manifolds can give us real insight into what’s happening inside the LLMs “thinking” helping us see this difference (see the video below).
情况也相反。两个不同的多轮 LLMs 可能对同一提示生成相同的响应,但它们到达结果的方式可能非常不同,这取决于它们内部的几何结构,从而导致推理过程非常不同。使用弯曲推理来可视化这些残差轨迹流形,可以让我们深入了解 LLMs“思考”内部正在发生的事情,帮助我们看到这种差异(见下文视频)。
A Different Way to Think About Meaning
关于意义的另一种思考方式
This changes how we might think about what’s happening when an LLM generates text.
这改变了我们可能如何看待 LLM 生成文本时的过程。
Meaning doesn’t come from looking things up. It comes from “flowing & curving through a space” that’s already been bent by everything that came before.
意义并非来自查找信息。它来自“流经并弯曲于一个已被先前所有事物扭曲的空间”。
When tokens follow similar paths, it’s not because they’re being repeated. It’s because they’re being pulled into familiar patterns by the constraints already in place.
当 token 遵循相似路径时,并非因为它们在重复。而是因为它们被现有约束拉入熟悉的模式。
Not memory. Not storage. But geometry.
不是记忆。不是存储。而是几何学。
Tokens aren’t isolated units of text. They participate in a shared semantic field, one that grows deeper and more structured with every layer. What happens early on has consequences — not through stored state, but through shaping the space future tokens have to move through.
标记不是孤立的文本单元。它们参与一个共享的语义场,这个场随着每一层的深入而变得更加结构化。早期发生的事情会产生影响——不是通过存储状态,而是通过塑造未来标记需要移动的空间。
This is recurrence. Not in time, but in structure. Not remembered, but returned to by the shape of the system itself.
这是循环。不在时间中,而在结构中。不被记住,而是由系统本身的形状回归。
If you only think of LLMs as “predicting the next token” or just focus on “how certain neurons map to certain outputs” then you’re missing all the really interesting curved inference geometry that’s happening inside.
如果你只将 LLMs 视为“预测下一个标记”或只关注“某些神经元如何映射到某些输出”,那么你将错过内部正在发生的所有真正有趣的弯曲推理几何。
In an upcoming article, we’ll explore how meaning emerges not just within a token’s trajectory, but between them — through the interference and blending of two different types of trajectories at once.
在即将发表的文章中,我们将探讨意义如何不仅在一个标记的轨迹内,而且在它们之间产生——通过同时发生的两种不同轨迹的干扰和融合。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢