

Stanford CS224W: Machine Learning with Graphs
https://colab.research.google.com/drive/1RgRm-xKnKObYsHGbXB9TRYUKriAj3yV5?usp=sharing&source=post_page-----ec36adb6d6a1---------------------------------------
图学习技术很难添加到现有的 ML 管道中。使用Correct&Smooth 通过在图结构上“平滑”现有预测来优化现有预测
介绍
虽然图神经网络 (GNN) 最近在学术基准测试中占据主导地位 [3],但它们在工业 ML 中尚未得到类似的采用。图数据结构和 GNN 难以扩展到大数据 [1, 6],并且与标准的监督学习工具包有很大的不同,团队需要经历一个耗时且昂贵的过程才能采用它们。因此,即使数据确实具有清晰的图形结构,它也经常被忽略或以行级手动调整特征的形式包含在内,如节点度或小图 [4]。
我们希望从行级手动设计节点特征升级到通用的图学习技术,同时对建模工作流程进行最少的更改。使用一种名为 Correct & Smooth (C&S) [1]的最新图 ML 算法,我们可以使用位于您现有监督分类器之上的后处理模块来竞争或超越 GNN。我们将在 LastFM Asia 数据集上展示该方法,其中的任务是预测社交网络中用户的家乡国家。我们将按顺序完成:
描述 LastFM Asia 数据集和转导节点分类任务
使用 PyTorch 和 PyG 从头开始实施 C&S [5]
使用 C&S 来提高现成分类器模型的性能,并与不同数据衰减下的基线进行比较。在我们的实验中,我们发现在底层 MLP 上使用 C&S 进行后处理时,准确性提高了 20%。
你可以按照 Colab 中的代码(https://colab.research.google.com/drive/1RgRm-xKnKObYsHGbXB9TRYUKriAj3yV5?usp=sharing)和结果进行作 ,也可以直接将 simple correct&smooth 安装为 python 包:
pip install https://github.com/andrewk1/correctandsmooth/archive/refs/tags/v0.0.2.zip
GitHub - andrewk1/correctandsmooth: Simple correct&smooth implementation in PyTorch.
https://github.com/andrewk1/correctandsmooth?source=post_page-----ec36adb6d6a1---------------------------------------
在 pytorch 中正确和平滑 (C&S) 的简单实现。CANDS 旨在让练习者非常快速地......
介绍我们的数据集和转导节点分类
LastFM Asia
LastFM Asia 于 [2] 推出,由 7,624 名用户和 55,612 个友好关系组成。对于每个用户,我们还有一个 128 维的特征向量,代表用户喜欢的艺术家,以及一个描述 18 个类别中的祖国的索引。目标是根据图及其艺术家偏好预测用户来自哪个国家/地区。
我们使用 PyG 中的 dataset helper 类来加载数据集。边存储为节点索引对的张量。不需要额外的处理。
这是网络的外观(图 1),使用 GraphViz 中基于 Voronoi 的技术确定节点位置。

图 1.每种颜色代表每个用户(节点)的 18 个主国家/地区之一
转导淋巴结分类
在标准的监督式学习设置中,我们使用每个用户最喜欢的艺术家的信息对他们进行分类。在转导节点分类中,我们解决了相同的分类任务,但还了解了训练时的整个图结构,包括验证和测试集节点的位置。
这在视觉上如下所示(图 2),其中我们为节点进行了随机的 train/val/test 拆分。我们始终可以看到整个网络,但在训练期间会屏蔽绿色(验证)和红色(测试)节点的类。

图 2.跨节点随机采样的 train/val/test 的 80% / 10% / 10% 拆分
在 PyTorch 和 PyG 中实施 C&S
C&S 利用了相邻节点往往具有相同标签和相似特征的模式,这个概念称为同质性。一旦我们从监督式学习器那里获得了类的预测概率分布,C&S 首先通过使用训练节点上的预测误差来“纠正”测试节点上的错误,然后通过合并附近的 ground truth 训练标签来“平滑”测试数据上的预测。
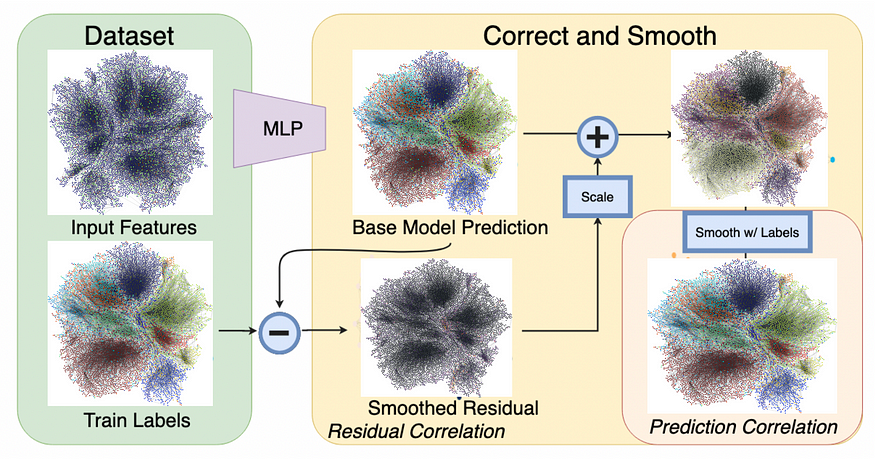
图 3.完整的 C&S 管道
我们按照论文从头开始实现 C&S,用代码解释论文中的方程。
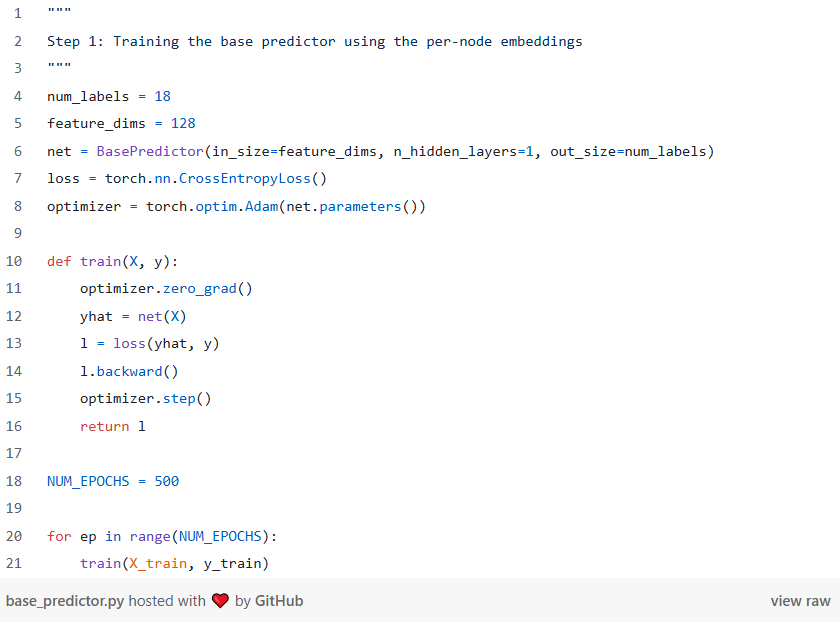
步骤 1:训练基础预测变量
第一步是获取一个基本分类器模型,该模型可以输出每个样本的类的概率分布。我们在 PyTorch 中训练一个浅层 MLP:
MLP 在验证时达到 0.696 的准确率,在测试集上达到 0.726 的准确率。虽然每个类集群中深层的节点是一致的,但该模型对具有不同国家/地区(集群边界)的朋友的用户会出错。
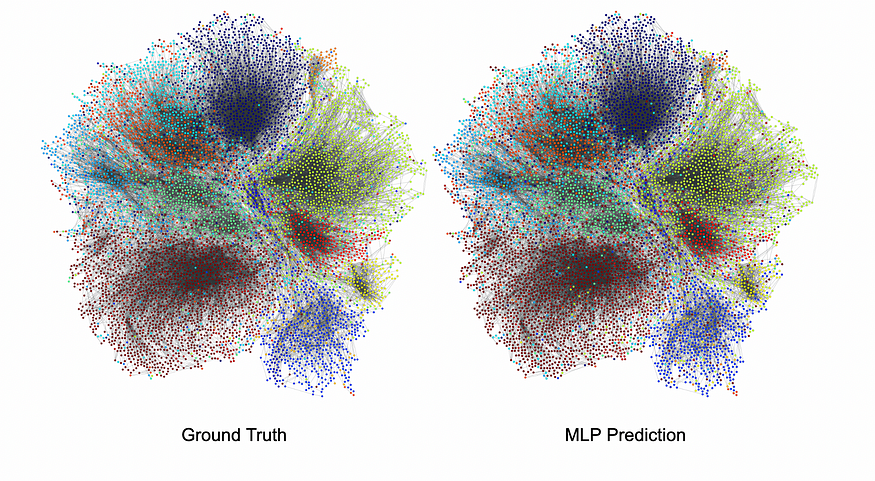
图 4.根据基本事实可视化预测
第 2 步:更正
我们首先形成一个矩阵,其中每行等于(独热编码的)标签与仅训练节点的预测类分布之间的残差。其中,“Lt”、“Lv” 和 “U” 分别是 train、val 和测试集。
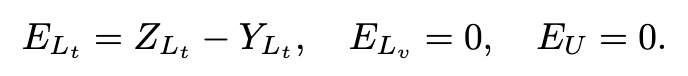
方程 1.残差方程积分
在代码中,如下所示:
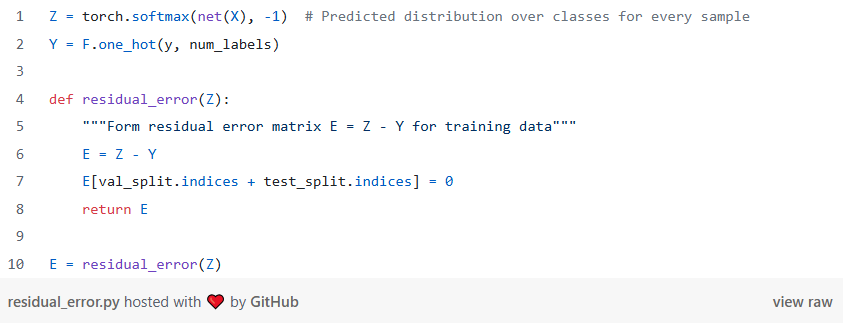
接下来,我们 “平滑” 整个图上的误差。由于同质性,我们预计相邻节点的误差呈正相关,因此对于验证/测试节点,相邻训练节点上的误差可以预测实际误差。
使用以下递归计算更正。 S 是归一化邻接矩阵,因此 SE 将为每个节点设置一个新误差,作为其相邻节点误差的加权平均值,其中程度较低(相邻节点较少)的节点将具有较高的权重(有关 S 的深入解释,请查看此 Math StackExchange 线程https://math.stackexchange.com/questions/3035968/interpretation-of-symmetric-normalised-graph-adjacency-matrix)。此处,α (alpha) 是一个超参数。
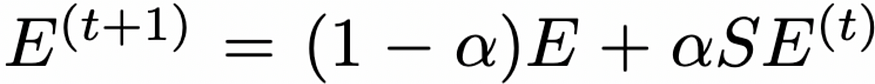
方程 2.误差平滑方程
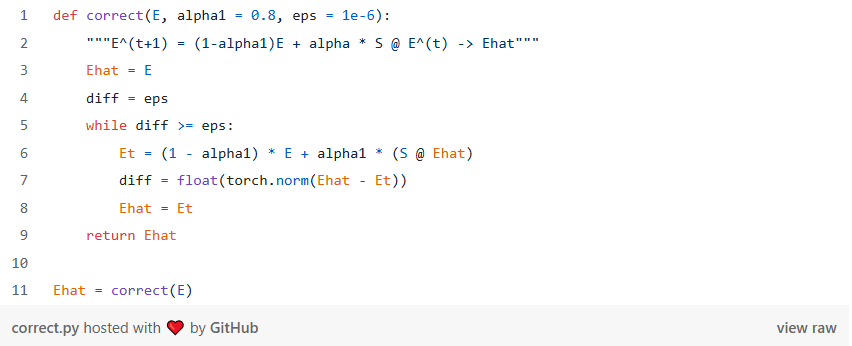
在代码中,这是一个 while 循环,我们使用 E 变化的 L2 范数来检查收敛性。
我们在正确阶段的第一步和最后一步可视化正确类别的残差误差矩阵(颜色越亮,误差越高)。根据经验,我们看到 Correct 相位将降低某些节点上的误差幅度,尽管没有太大的明显差异。

图 5.传播前后的误差放大
平滑误差后,C&S 会将新误差的大小缩放为与原始训练误差相同的刻度。将残差添加回原始预测,得到一个新的预测向量 Zr。
在代码中,我们采用每行训练误差的平均 L1 范数,然后对新的预测进行归一化和重新缩放。

第 3 步:平滑
在 Correct 步骤中,我们平滑了相邻节点上的误差。在 Smooth 步骤中,我们还将按照相同的直觉对相邻节点的预测进行平滑处理。平滑作与纠错相同,这次迭代我们的最佳猜测矩阵 G, 初始化为我们的尺度预测向量。
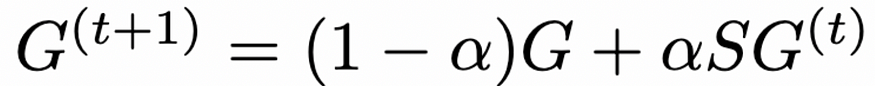
方程 3.校正平滑
该代码也与正确的步骤几乎相同:
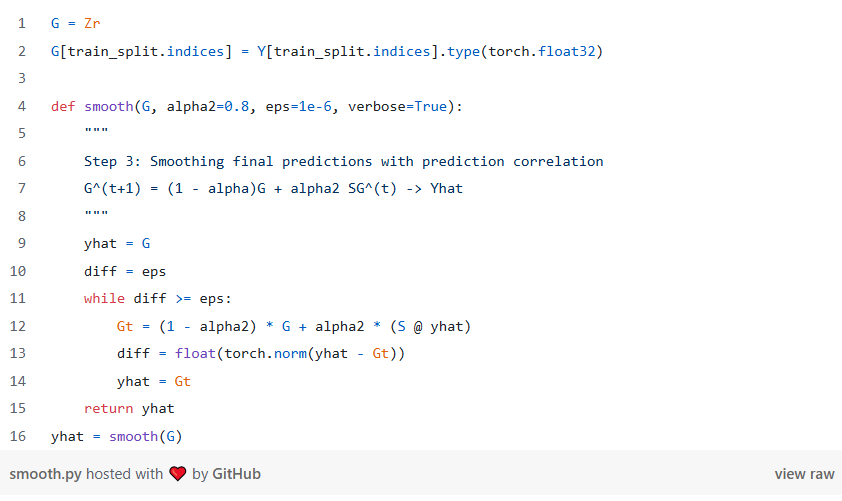
一旦我们运行了平滑步骤,我们就有了最终的预测!下面的 GIF 直观地显示了我们在平滑过程的每次迭代中的最佳猜测。我们可以看到,改变预测的节点最位于类集群之间,其中艺术家偏好本身并不能明确预测国籍。

图 6.观察预测在平滑迭代中收敛 — 注意大多数节点如何更改集群边的预测
衡量性能
我们使用准确性比较了 LastFM Asia 上 MLP 和 C&S 之间的测试集性能,包括对验证集上 alpha1 和 alpha2 选择的超参数扫描(这两者都在论文中进行了优化)。

表 1.比较 80/10/10% train/val/test 拆分运行的模型
每一步,我们都会看到准确率提高近 10%!显然,将图结构包含在这个特定的预测任务中会有巨大的收益。我们还看到了两个 alpha 变量对平滑步骤性能的重要性 — 如果您选择实施此方法,请运行超参数扫描。
理解 C&S
准确率提高 20% 值得仔细审查——为什么 C&S 在这里表现如此出色?我们认为 homophily 可以解释结果,其中测试节点附近的训练节点可以通知测试节点标签。让我们做一个简单的实验:直接在训练节点标签上运行平滑步骤,并使用结果预测验证和测试标签:
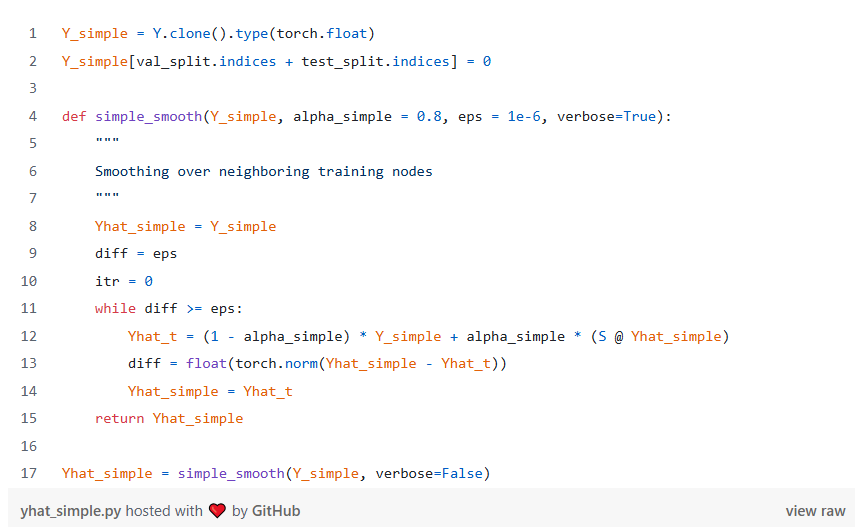
在 80/10/10% 拆分时训练标签平滑

表 2.80/10/10% train/val/test,在相邻节点上平滑训练节点标签 “Smooth Training”
一个有趣的结果 — 我们看到,只需在相邻测试节点上平滑训练标签,就几乎与 C&S+MLP 方法的性能相匹配!这验证了 C&S 的收益依赖于与附近的测试节点共享训练节点信息。
对于我们选择的 train/val/test = 80/10/10%,我们可能只需访问许多相邻的训练节点,从而允许平滑训练标签等方法工作。让我们尝试降低到 50/25/25% 并重新运行实验。我们可能预期 C&S 在这方面会跑赢大盘,因为它可以利用标的 MLP 来“填充”标签。
在 50/25/25% 拆分时训练标签平滑

表 3.在低数据状态下重新运行表 2 50/25/25% train/val/test
即使在低训练数据范围内,纯平滑也表现得非常好,完全优于 C&S 和其他学习方法!虽然我们减少了训练集中的节点数量,但我们没有改变图连接的数量。可视化数据分片,由于图连接的密度,这似乎是一个合理的结果:大多数节点最终仍然连接到训练节点!

图 8.50/25/25% train/val/test splits 密集图非常适合经典的标签平滑技术
如果我们对图中的边缘进行子采样,然后重新运行相同的模型管道,并删除 70% 的边缘,情况会怎样?这里的直觉是,我们不能依赖图的纯密度,其中测试节点将有许多训练节点来推断标签。我们的模型需要更有效地将各个特征节点和任何现有邻居组合在一起,以形成预测。
以下是这种消融的结果:
在 80/10/10% 分割和 30% 的边上训练标签平滑

表 4.0.8/0.1/0.1 分割,去除 70% 的边
结果与我们的直觉一致!C&S 在这方面显然是赢家,其准确率分别为 80% 和 70%,优于 MLP 和简单平滑基线。由于缺乏边密度,平滑基线甚至比 MLP 基线更差。然而,通过 C&S 将两个信号(用户特征和图结构)组合在一起,仍然可以使 MLP 的精度提高 10%。
结论
C&S 是一种强大的方法,可以通过两个快速简单的后处理步骤来提高您现有的分类器在图数据上的性能。在非常密集的图中,您应该尝试在训练标签上采用平滑步骤,以获得相当的准确性增益。当您的图不那么密集,或者您的测试集与训练数据没有共享许多边时,C&S 可以极大地促进监督学习者利用边结构的一些知识。所有方法的基本平滑代码都非常相似,因此值得在下一个项目中尝试所有这些方法!
简单、正确&平滑的包和 Colab
可以在此处找到该模型的打包版本:
GitHub - andrewk1/correctandsmooth: Simple correct&smooth implementation in PyTorch.
https://github.com/andrewk1/correctandsmooth?source=post_page-----ec36adb6d6a1---------------------------------------
参考
[1] Huang, Qian, et al. “Combining label propagation and simple models out-performs graph neural networks.” arXiv preprint arXiv:2010.13993 (2020).
[2] Rozemberczki, Benedek, and Rik Sarkar. “Characteristic functions on graphs: Birds of a feather, from statistical descriptors to parametric models.” Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020.
[3] https://ogb.stanford.edu/docs/leader_nodeprop/
[4] https://en.wikipedia.org/wiki/Graphlets
[5] Fey, Matthias, and Jan Eric Lenssen. “Fast graph representation learning with PyTorch Geometric.” arXiv preprint arXiv:1903.02428 (2019).
[6] Bojchevski, Aleksandar, et al. “Scaling graph neural networks with approximate pagerank.” Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢