

强化学习(Reinforcement Learning, RL)方法在模拟环境和游戏中已取得显著成果,但直到最近才开始被应用于解决现实世界的问题。这在一定程度上是因为强化学习方法本身存在不稳定性、样本效率较低,以及在现实任务中难以将奖励准确归因到长序列中的具体步骤等挑战。为应对这些问题,本论文提出了一系列方法,涵盖问题建模、表征学习、有效的奖励归因机制,以及高质量多步轨迹的可扩展构建。
为了将这些理论原则落地,我将介绍两类能够解决现实世界挑战的强化学习智能体,分别应用于两个截然不同的领域:芯片设计与语言建模。
首先,我将介绍 AlphaChip,这是一种深度强化学习方法,能够在数小时内生成超越人类水平的芯片布局,而不再需要人类耗时数周甚至数月的设计过程。AlphaChip 是最早部署于现实工程问题的强化学习方法之一,已被用于设计过去四代 Google TPU 芯片的布局,同时也被 Alphabet 内部和外部的芯片制造商广泛采用。
接下来,我将介绍 Step-Wise Reinforcement Learning(SWiRL),这是一种结合强化学习与合成数据生成的方法,可提升大型语言模型(Large Language Models, LLMs)在多步推理和工具使用方面的能力。
最后,我将提出一个用于评估基于LLM的强化学习智能体在复杂多步推理任务中性能的新数据集,并探讨该前沿领域中的若干开放问题与未来机遇。

类型:2025年博士论文
学校:Stanford University(美国斯坦福大学)
下载链接:
链接: https://pan.baidu.com/s/1o6aQh6Ir7pJ81Z1zO6QXxQ?pwd=mstq
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
1.1 强化学习在序列决策中的应用
2019年,当我开始攻读博士学位时,研究界对强化学习 (RL) 方法的可靠性和有效性心存疑虑,质疑这类方法是否能够用于解决现实世界的问题,甚至质疑它们是否真的有效[91]。这种质疑主要源于这些方法的不稳定性[154, 127]、相对较低的样本效率[11, 193],以及在现实世界任务特有的长轨迹中,难以将奖励归因于各个步骤[146, 145, 194, 166, 32]。
为了应对这些挑战,我的论文提出了问题表述、表征学习、有效奖励归因以及高质量多步轨迹的可扩展管理方法。为了阐明这些原理,我将介绍能够解决两个不同领域(芯片设计和语言建模)的现实世界挑战的强化学习智能体。
在这篇论文的前半部分,我将阐述强化学习在布局优化中的应用,布局优化是一项在系统和芯片设计中常见的组合优化任务。然后,我将介绍 AlphaChip,这是一种深度强化学习方法,能够在数小时内生成超越人类的芯片布局,而无需耗费数周或数月的人力。AlphaChip 是首批用于解决实际工程问题的强化学习方法之一,它已应用于谷歌 TPU 的最近四代产品,以及 Alphabet 和其他外部芯片制造商的其他芯片的布局设计。最后,我将讨论该方法的后续影响以及围绕它的研究讨论。
在下半部分,我将介绍 SWiRL(逐步强化学习),这是一种合成数据生成和强化学习方法,可以提升大型语言模型 (LLM) 执行多步推理和工具使用的能力。我特别关注多跳问答和数学推理。之后,我将介绍 COMPASS-QA,这是一个全新的数据集,旨在评估 LLM 在具有挑战性的多步推理任务上的表现,并用于在这些领域训练基于 LLM 的强化学习代理。在论文的最后,我将展示一个用于训练和评估基于 LLM 的强化学习代理在具有挑战性的多步推理任务上表现的新数据集,并讨论这一新领域的开放问题和机遇。
将芯片节点放置到二维画布上,看似与解决数学推理问题或使用搜索引擎回答多跳问题截然不同,但这些任务却有着共同的结构。在所有情况下,它们都涉及执行一系列非平凡的决策,最终得出解决方案。本论文证明,这类任务可以通过强化学习优化的深度神经网络有效解决,并利用本论文中开发的方法来缓解上述强化学习陷阱。
我的长期研究目标是构建能够理解和生成人类语言的计算机系统,随着我们逐渐接近这一目标,研究方向转向设计高度智能的语言学习(LLM)代理。计算是自然语言处理 (NLP) 进步的动力,神经尺度定律 [83, 106, 85] 对此尤为明确。我选择这个论文主题是因为我相信用于序列决策的强化学习是一个强大的框架,它将我的大部分工作统一起来。此外,我的工作在硬件和人工智能之间开启了一个递归反馈循环,人工智能的进步带来更强大的硬件,进而带来更强大的人工智能,如此循环往复。事实上,由 AlphaChip 设计的、拥有超越人类芯片布局的 TPU 被用于训练和评估本文后半部分描述的所有模型和数据集。
1.2 强化学习简史
强化学习 (RL) 是机器学习的一个分支,其中代理通过与环境交互进行学习,并根据其动作获得正向或负向奖励1 [193]。在本节中,我将简要介绍强化学习的历史,以便更好地理解本论文中提出的研究工作。
强化学习的理论基础可以追溯到20世纪初,其根源在于动物心理学与控制理论之间看似不太可能的结合。在心理学领域,爱德华·桑代克(Edward Thorndike)在20世纪初提出的“效果定律”提出,得到正反馈的行为更有可能被重复,从而确立了从反馈中学习的基本原理[201]。在控制理论和运筹学领域,理查德·贝尔曼(Richard Bellman)在20世纪50年代关于动态规划的研究,为随着时间的推移制定最优决策序列提供了一个数学框架[21]。这些独立的研究方向共同构成了强化学习的概念基础,即通过与环境进行反复试验的交互来学习以实现目标。
1959年,Arthur Samuel 提出了一个跳棋程序,可以说它代表了第一个强化学习方法,或者至少是一个明显的先驱。这项开创性的工作与后来成为强化学习领域特征的许多关键要素相符。例如,它包含一个包含所有棋盘位置的查找表,一个用于评估特定位置优势的评分函数,以及能够调整自身权重并通过自我对弈从经验中学习的能力[175]。然而,Samuel 的数学公式与后续工作截然不同,它采用了一种更具启发性和实用性的方法,这与动态规划的形式化方法[193]截然不同。
20 世纪 80 年代和 90 年代初,强化学习领域出现了许多开创性的贡献,例如演员-评论家架构 [20] 的引入、时序差分 (TD) 学习 [194] 以及其他无模型算法,例如 Q 学习 [217] 和 SARSA [174],这些算法使得无需明确的环境模型即可进行学习。尽管这些研究引入了至今仍具有现实意义的关键概念,但它们依赖于涵盖所有可能状态的详尽查找表。因此,对于状态空间较大或连续的问题,初始化或维护这样的查找表在计算上是不可行的 [13, 193]。
1995年,TD-Gammon朝着克服这一根本性限制迈出了第一步。具体来说,这项工作将TD学习与一个用于逼近西洋双陆棋价值函数的神经网络相结合[200]。TD-Gammon开启了深度强化学习的新纪元,深度神经网络表示取代了详尽的查找表。然而,函数逼近、引导法(从估计中学习)和离线策略训练的组合被证明是一种出了名的不稳定的发散因子——现在被称为“致命三角”[193]——并引发了强化学习的寒冬,在此期间,其他机器学习方法(如监督学习)取得了更快的进展和更广泛的应用[205, 152]。
2016 年,AlphaGo 在围棋比赛中击败了人类世界冠军 [186],这成为该领域的一个分水岭,重新激发了人们对深度强化学习方法的兴趣。然而,尽管强化学习方法在游戏和模拟中取得了令人鼓舞的后续成果 [186, 187, 209, 105, 89],但它尚未成功应用于解决实际问题。例如,即使在著名的数据中心冷却强化学习论文中,该论文指出功耗可降低高达 40% [172],但强化学习方法本身从未在生产环境中部署,报告的性能提升也仅仅是假设。
2020 年,我和同事们推出了 AlphaChip,这是一种用于设计芯片布局的深度强化学习方法 [16, 149]。AlphaChip 可以说是第一个用于解决现实世界工程问题的强化学习方法,其超越人类的芯片布局已在谷歌过去四代张量处理单元 (TPU) 以及 Alphabet 旗下其他芯片和外部芯片制造商的芯片中得到应用。这些芯片已在全球各地的谷歌数据中心部署并运行 [74]。我将在论文第一部分详细讨论这项工作。
AlphaChip 的发表引发了芯片设计领域人工智能研究的爆炸式增长 [229, 227, 233, 228, 42, 66, 23, 195, 29, 47, 65, 216, 28, 144]。然而,正如 Sutton 在其著作《惨痛教训》[192]中所述,人们往往不愿接受机器学习在新领域的应用,最终这导致了我们工作中的一些困惑,我将在第 4 章中讨论这个问题。如今,强化学习方法已被 Synopsys 和 Cadence 等领先的商业电子设计自动化 (EDA) 公司广泛采用,并在设计自动化会议 (DAC)2 等顶级芯片设计会议上得到重点介绍。
近年来,自然语言处理 (NLP) 领域通过强化学习优化大型语言模型 (LLM) 取得了令人瞩目的成果 [45, 18, 199, 69, 12, 161]。在我的论文第二部分,我将介绍我在这个新领域的一些工作,其中我专注于构建能够通过多步骤推理、规划和使用工具来完成日益复杂任务的智能体。最终,我相信强化学习的全部潜力在于多步骤顺序决策,以及能够自主解决各种现实世界挑战的智能体人工智能系统的开发。
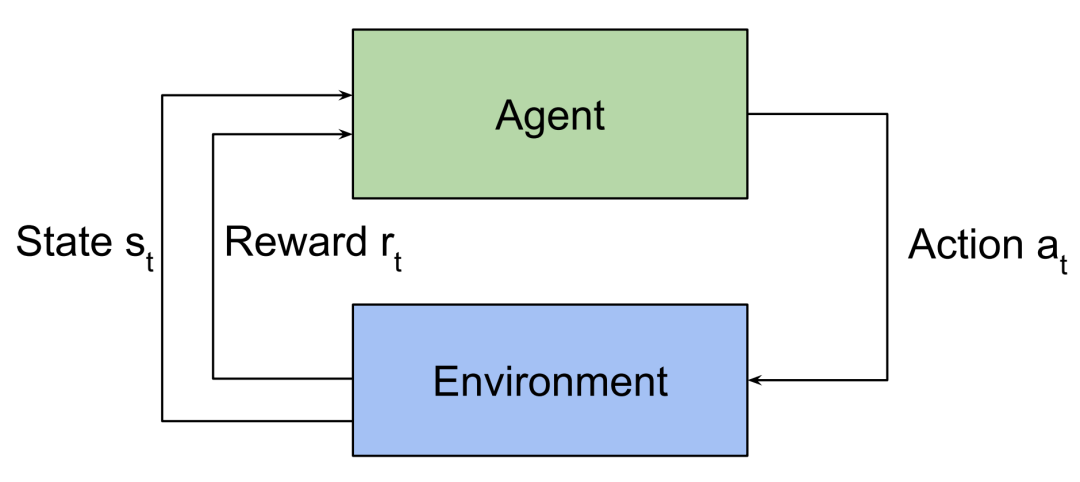
在强化学习中,代理会探索环境并找到最大化累积奖励的行动。
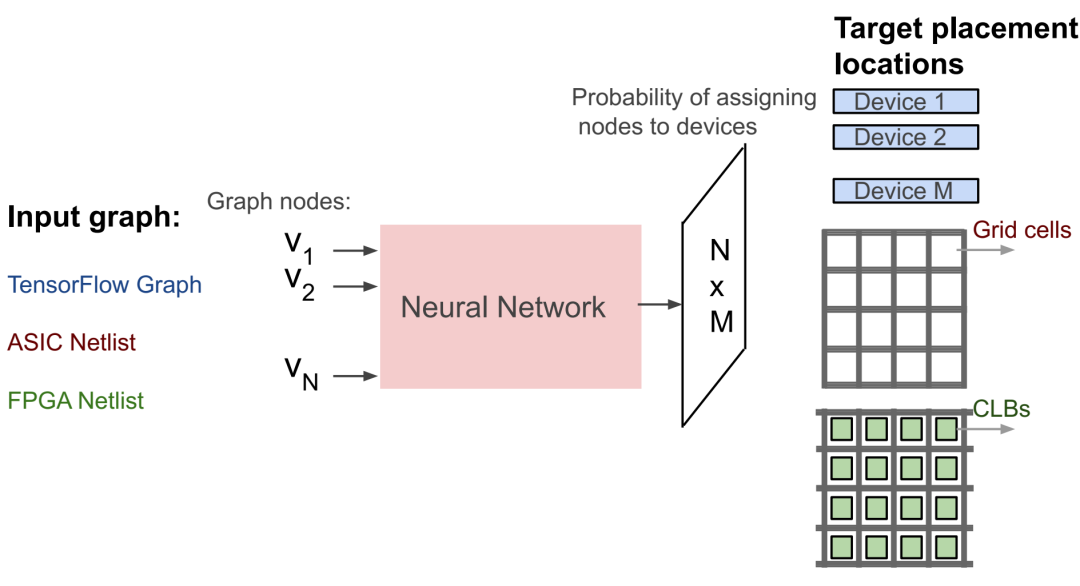
布局优化概述。TensorFlow 图、ASIC 网表和 FPGA 网表的目标布局位置分别是计算设备(例如 TPU 或 GPU)、芯片画布的网格单元和 FPGA 可配置逻辑块 (CLB)。
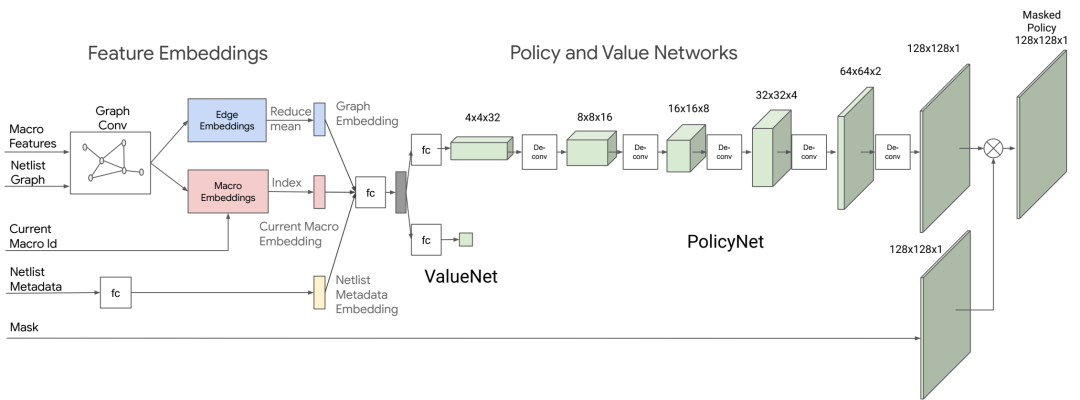
策略和价值网络架构。嵌入层编码了关于网表邻接性、节点特征以及当前待放置宏的信息。策略和价值网络分别输出可用网格单元的概率分布以及当前放置的预期奖励估计值。

我们的方法和训练方案概述。在每次训练迭代中,强化学习智能体一次放置一个宏(动作、状态和奖励分别用 ai、si 和 ri 表示)。所有宏都放置完成后,将使用力导向方法放置标准单元。中间奖励为零。每次迭代结束时的奖励由近似线长、拥塞度和密度的线性组合计算得出,并作为反馈提供给智能体,以便优化其下次迭代的参数。
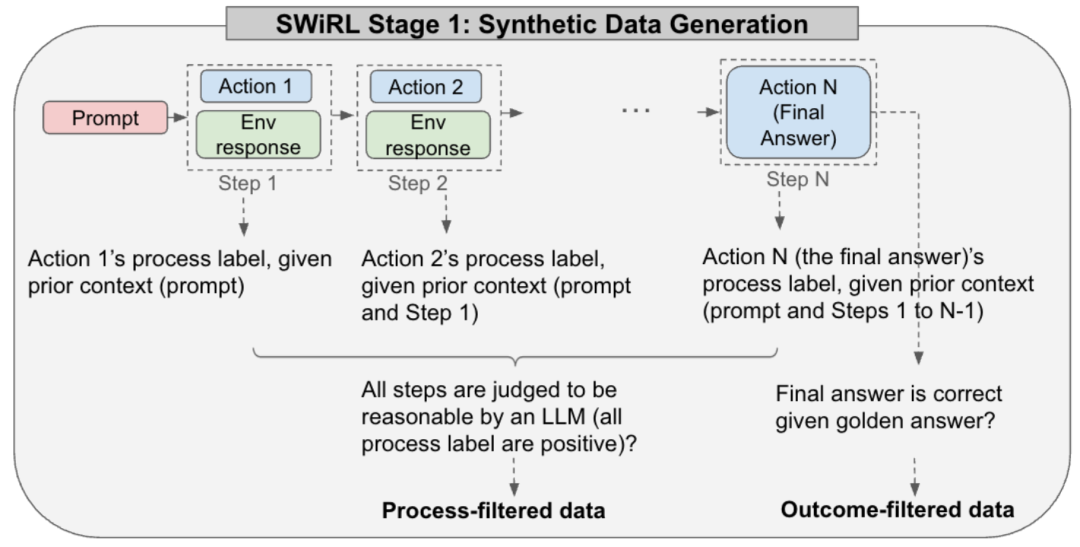
在 SWiRL 第一阶段,我们生成并筛选多步合成轨迹。在每个步骤中,模型可以自由地生成思路链,调用搜索引擎或计算器等工具,以及/或者对原始问题给出答案。过程筛选数据对应于每一步都被模型评判器(Gemini 1.5 Pro Thinking)判断为合理的轨迹。结果筛选数据对应于最终答案与黄金标签匹配的轨迹。

在 SWiRL 第 2 阶段中,我们采用分步强化学习 (step-wise RL) 来训练第 1 阶段生成的合成多步轨迹。每个步骤包含一个动作,对应于一次工具调用或最终响应。模型可以在每个步骤中自由生成思维链。环境响应会在合成轨迹的先前步骤中捕获,这些步骤是离线生成的。生成式奖励模型提供精细反馈,该模型用于根据先前的上下文直接对每个动作进行强化学习优化。
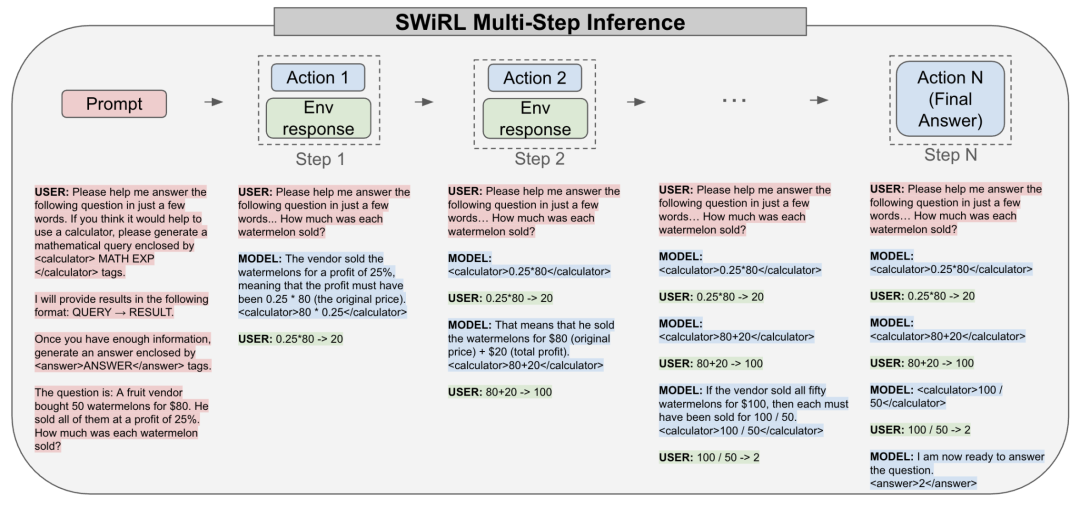
SWiRL 多步推理。在推理过程中,我们会反复提示模型调用可用工具,次数不限(直至达到上限),然后再回答原始问题。为了清晰起见并避免篇幅限制,此处的提示略有删减,但完整的推理过程可在附录 5.D 中找到。请注意,在这个特定示例中,原始 GSM8K 问题包含一个语法错误,应为“每个西瓜卖多少钱?”。







内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢