
DRUGAI
Materials Project(材料项目,简称 MP)自2011年正式启动,旨在通过高通量计算和开放数据推动材料发现。十余年后,Materials Project 已成为全球超过60万名材料研究人员的重要工具。本篇观点文章系统介绍了该平台如何作为一个数据平台与软件生态,塑造了数据驱动材料科学的研究格局。
研究人员阐述了可持续软件与计算方法如何在日益开放与协作的环境中,加速了材料设计。同时,文章呈现了MP在功能材料理解与发现中的关键案例。为了满足不断扩展的用户群体,MP在数据架构、云计算资源和交互式网页应用等技术基础设施方面也进行了全面升级。最后,研究人员展望了未来发展机遇,认为更易获取、易理解的材料数据将推动材料知识的民主化,培育一个更加开放与协作的科研共同体。

2011年,研究人员正式启动了Materials Project(MP),旨在利用高通量计算与开放数据加速材料的发现。十多年过去,MP已经发展成为全球超过60万名材料研究人员广泛使用的关键工具。
本文全面回顾了Materials Project如何作为一个数据平台与软件生态系统,引领数据驱动材料科学的变革。研究人员介绍了该平台如何通过可持续的软件开发与计算方法,推动材料设计的同时,也实现了代码开源化与协作方式的多样化。随后,文章展示了MP在功能材料发现与理解中的典型案例,并介绍了其为满足日益增长的用户群体所做的技术基础设施更新,包括数据架构、云计算资源与交互式网页应用。
研究人员进一步提出未来的发展愿景:更易获取、易理解的材料数据将加速知识民主化,培育一个更加开放、协作的材料科学研究共同体。
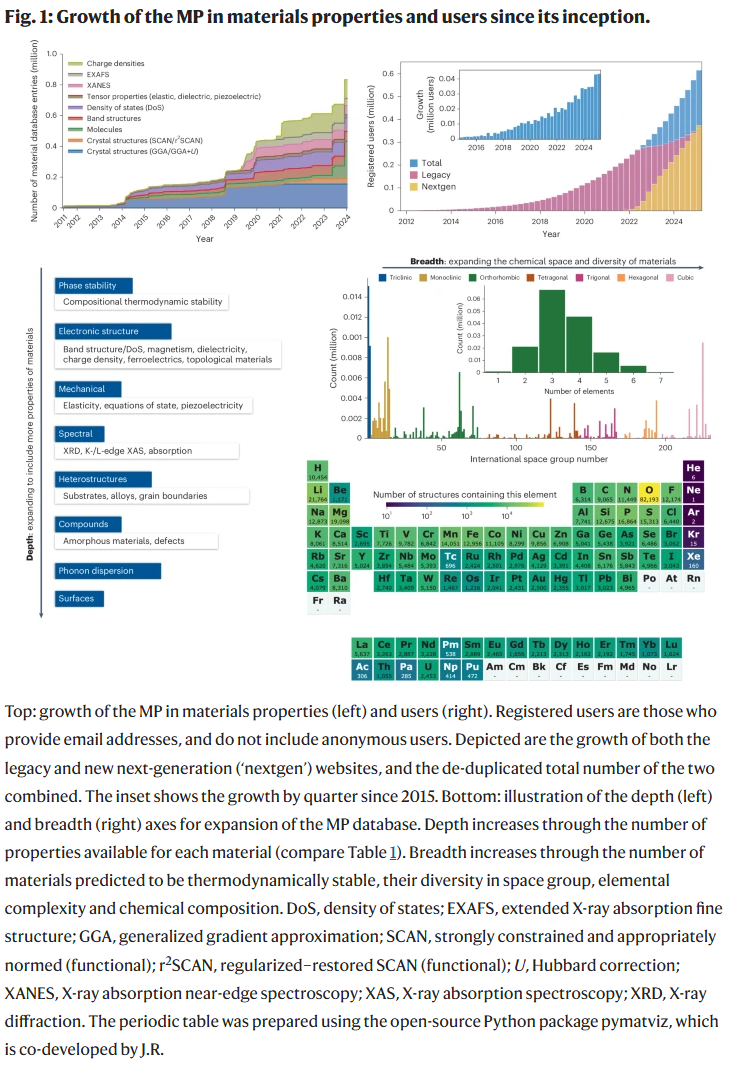
MP数据库
Materials Project最核心的产出是其对无机晶体结构及其性质的大规模数据库。此外,还包括了分子数据、文献中提取的合成路径、电池材料特性、有机金属框架以及催化数据等多个子库。
该数据库的建设可从两个维度理解:广度和深度。广度指的是材料种类的多样性,深度则涉及每种材料所记录的属性种类。MP通过自动化计算流程,显著提升了数据的深度。这些流程均经过严格的基准验证,与实验数据对照,以确保数据的准确性与可复用性。
目前,MP已覆盖178,000余种材料,涵盖超过51,000种化学系统和200多个空间群,涵盖几乎全部元素。其结构与化合物信息多源于现有权威实验数据库,辅以自然语言处理对文献信息的挖掘。
MP平台
除了构建数据库,MP还发展成为一个支持数据分析、共享与可视化的开源平台。平台由一整套软件库支持,涵盖了高通量计算工作流管理、数据提取与加载、分析与可视化,以及网页端与API接口。
MP的生产级计算流程主要基于VASP软件,但平台最新的atomate2框架也支持与其他第一性原理代码的协同运作。所有数据都通过软件库自动转换为可查询与解释的形式,进一步支持交互式图形展示与下游建模。
这一切建立在开源软件与社区协作的基础上,体现了现代科学向可复现与共享的开放转型。

材料发现中的MP应用
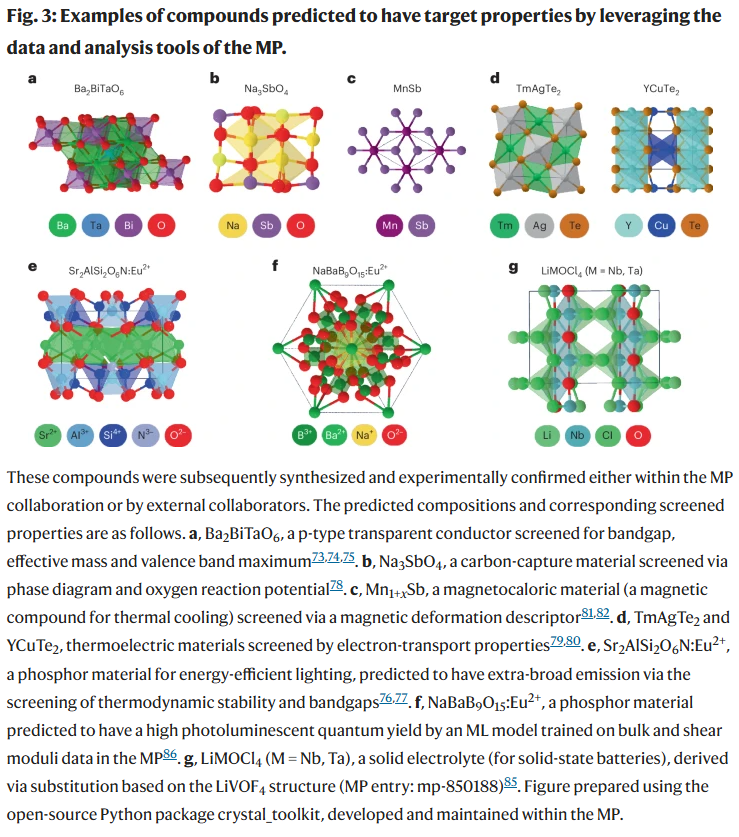
尽管材料从设计到商业化通常周期漫长,MP已在多个方向实现了从理论预测到实验合成的突破,包括新材料的发现与已有材料在新领域的再利用。
在材料筛选中,研究人员常使用数据库筛选满足性能标准的候选材料,这一策略已广泛应用于电池、光电器件、压电材料、热电材料、光催化剂、碳捕获、量子材料等多个方向。近期,研究趋势开始聚焦于“反向设计”——即从目标性能出发,反推出合适的结构与组成。
MP也逐步建立了用于绘制相图、化学势图与Pourbaix图等在线工具,使研究人员更直观地探索热力学景观与环境相关性。
人工智能与机器学习中的MP
MP为机器学习提供了高质量、可复用的大型数据基础,使得图神经网络、生成模型、主动学习等方法得以有效应用。其数据涵盖热力学、弹性、电子结构、磁性、吸收光谱等,构成材料模拟的全栈数据体系。
MP通过严格的计算流程标准化所有数据,所有属性都可被复现并且具有可验证性。例如,其核心工作流程采用r2SCAN泛函,确保在大规模自动化运行中的数值稳定性。
这些标准化的数据流极大降低了模型训练的门槛,也成为开发通用材料ML模型(如图神经网络势能函数)的关键资源。
社区治理与用户参与
MP高度重视社区建设,成立了Materials Project基金会,推动平台的可持续治理。平台采用开源治理模式,所有代码更新、决策与审查过程公开进行。
用户不仅能使用数据,也可以通过MPContribs系统贡献数据与交互式工具。上传数据与平台主库并列展示,增强了数据的多样性与可访问性。这些机制使研究人员能共享实验与计算成果,最大程度地实现数据复用。
为了降低使用门槛,MP还提供了在线文档、示例代码与视频教学,支持各类科研人员通过编程方式访问和分析数据。
挑战与展望
尽管数据驱动研究带来诸多机遇,材料设计仍面临四大挑战:
第一性原理精度限制:模拟方法在描述缺陷、振动等现实系统复杂性方面仍存在差距;
计算规模受限:部分现象需更长时间或更大尺度模拟;
数据偏倚问题:文献中常忽略失败实验与负例反应;
合成可行性预测仍是难点:理论稳定性并不等于合成可行。
为应对上述问题,MP正开发模拟无序体系的新方法,建立结构近似分类机制,并强化元数据标准化。此外,MP也联合自然语言处理、自动化实验室等技术,努力整合更多高质量实验与失败数据。
总结
过去十年,MP在数据范围、精度与基础设施方面不断演进。研究人员通过构建FAIR数据体系,推动了机器学习与数据驱动方法的发展,使材料研究进入“第四范式”。
展望未来,研究人员计划进一步提升计算精度、拓展属性覆盖范围、探索更复杂的相空间,并推动材料可合成性的预测。MP将持续拥抱开放、鼓励社区贡献,以网络效应提升数据发现力与分析深度。
研究人员强调,推动数据驱动材料研究不仅需要高质量数据和算法,也需科研人员提升计算与数据科学素养。在此基础上,MP希望成为不仅提供数据的平台,更是引领科学前沿的重要引擎。
整理 | WJM
参考资料
Horton, M.K., Huck, P., Yang, R.X. et al. Accelerated data-driven materials science with the Materials Project. Nat. Mater. (2025).
https://doi.org/10.1038/s41563-025-02272-0
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢