
DRUGAI
化学合成作为构建变革性分子的基础方法,在生命科学、材料与能源等多个领域发挥着重要作用。当前的化学合成实践依赖于繁琐且代价高昂的试错流程,因此亟需先进的人工智能助手。近年来,大型语言模型(LLMs)如GPT-4被引入科学研究领域。研究人员提出了Chemma,这是一个经过全面微调的语言模型,拥有128万个关于反应的问答对,可用于加速有机合成。Chemma在多个化学任务中表现优异,如单步逆合成与产率预测,显示出通用人工智能在有机化学中的潜力。在整个反应空间中预测产率的能力,使得Chemma显著提升了贝叶斯优化的反应探索能力。更重要的是,当整合入主动学习框架后,Chemma展现出在开放反应空间中进行自主实验探索与优化的潜力。对于一个未被报道的Suzuki–Miyaura交叉偶联反应,Chemma与化学家的协作在仅15次实验内成功筛选出合适的配体和溶剂,获得了67%的产率。这些结果表明,Chemma无需量子化学计算即可从反应数据中理解并提取化学洞察,其方式类似于人类专家。此项工作开启了通过适配大型语言模型加速有机合成的新路径。
化学合成是化学学科的核心,支撑了新物质的创造、探索与理解。其在药物发现、可再生能源、催化剂设计等前沿科学领域中同样扮演关键角色。尽管仪器技术取得显著进步,化学合成过程依然受到广阔反应空间与复杂分子结构的限制,实验通常需反复试错,依赖文献查阅和实验设计。即使借助文献工具,对于全新分子的合成路线仍缺乏有效指引,体现出有机化学研究范式变革的迫切需求。
近年来,以GPT为代表的大型语言模型引发了在科学领域的广泛关注。这类模型已被用于文献挖掘、数据标注、实验设计、科学工具调度等任务。特别在化学领域,已有工作展示了基于语言模型的自动实验设计、文本挖掘与反应建模能力。然而,GPT类模型在化学任务中仍主要局限于分子描述或简单翻译,难以独立探索并优化新反应条件。
相比之下,有机合成中的人工智能方法已取得显著进展,包括基于回溯合成与机器学习的闭环实验优化平台、贝叶斯优化用于高产率条件筛选、统计建模反应机制等。这些方法虽取得成效,但多依赖于DFT计算和人工特征选择,导致筛选过程仍具有较强试错性质。此外,它们多面向专家预设的闭合反应空间,忽略了更优条件可能存在于开放反应空间中的可能性。
考虑到分子可以序列表示,反应在文献中也具自然语言特征,研究人员提出通过大型语言模型学习SMILES表示与反应数据,实现如人类般的化学知识学习与分子设计,并据此提出化学助手Chemma。
结果
Chemma模型设计与架构
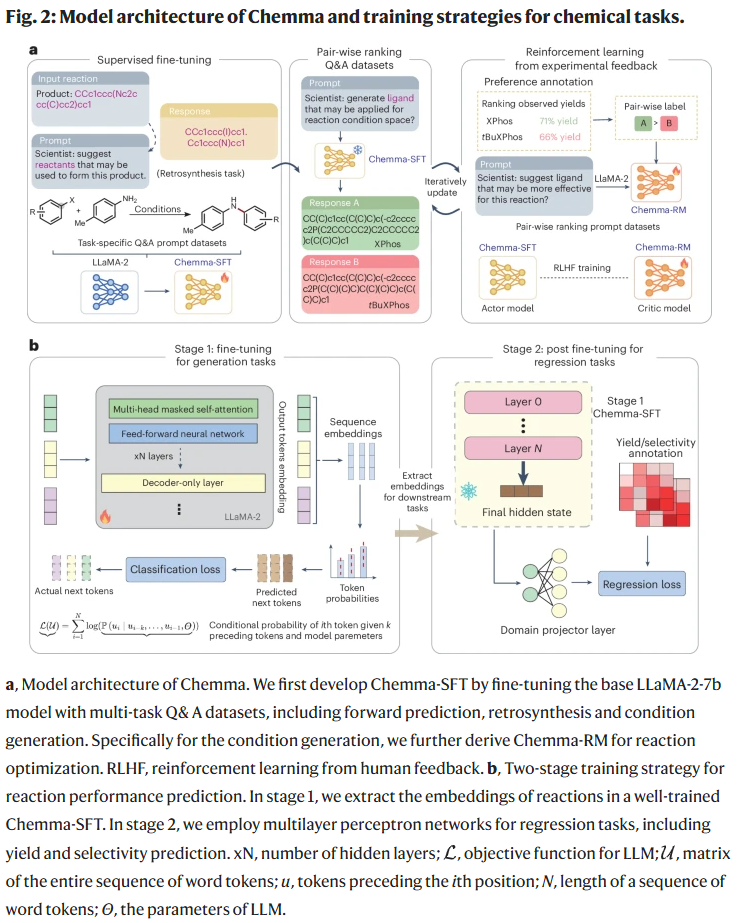
研究人员使用公开数据库(如ORD与USPTO-50k)构建多任务问答数据集,并通过GPT-4辅助设计提示模板。Chemma基于LLaMA-2-7B模型,采用监督微调(SFT)完成前向预测、逆合成与条件生成任务训练。对于反应优化,设计了基于偏好排序的问答数据对,并通过强化学习进一步优化Chemma-RM模型。在性能预测方面,采取两阶段训练:首先提取反应的嵌入表示,然后构建回归网络预测产率与选择性。
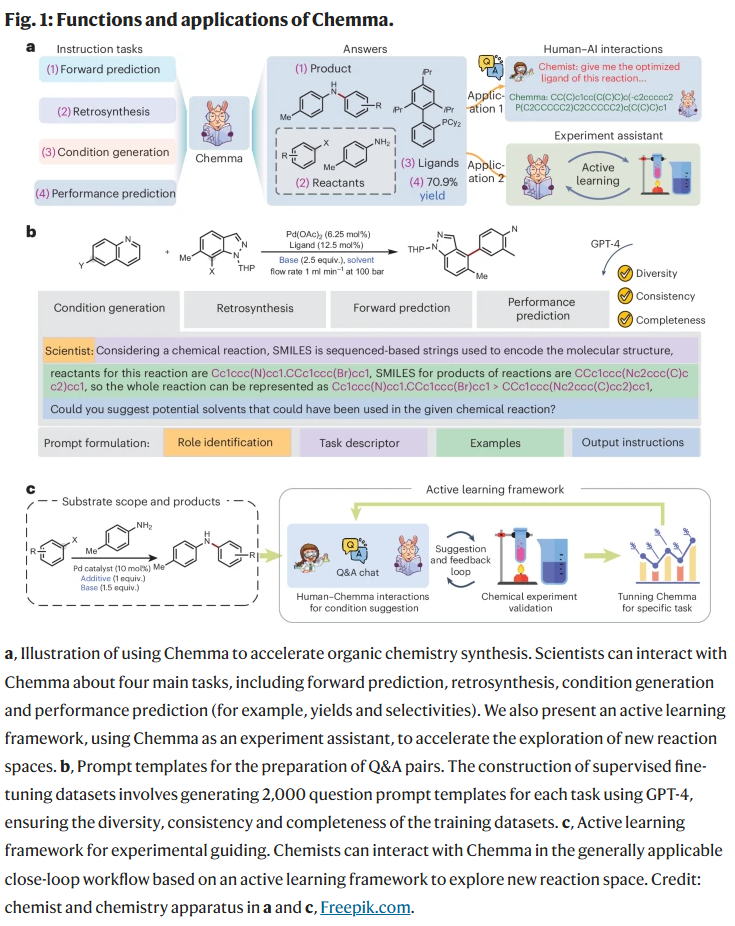
在公开基准数据集上的表现
在USPTO-50k数据集上,Chemma在单步逆合成任务中实现了72.2%的Top-1准确率,显著优于图神经网络与其他Transformer方法。在多步合成测试中,Chemma能够提出合理的反应步骤。对于配体推荐任务,Chemma可在预设条件下给出最优配体,在多数测试组合中,其推荐配体带来更高中位产率。在产率预测方面,Chemma无需DFT特征,仅基于反应嵌入即可获得高精度预测,优于传统方法。在选择性预测(区域选择性与对映选择性)任务中,Chemma也展现出接近或超越现有模型的准确度。
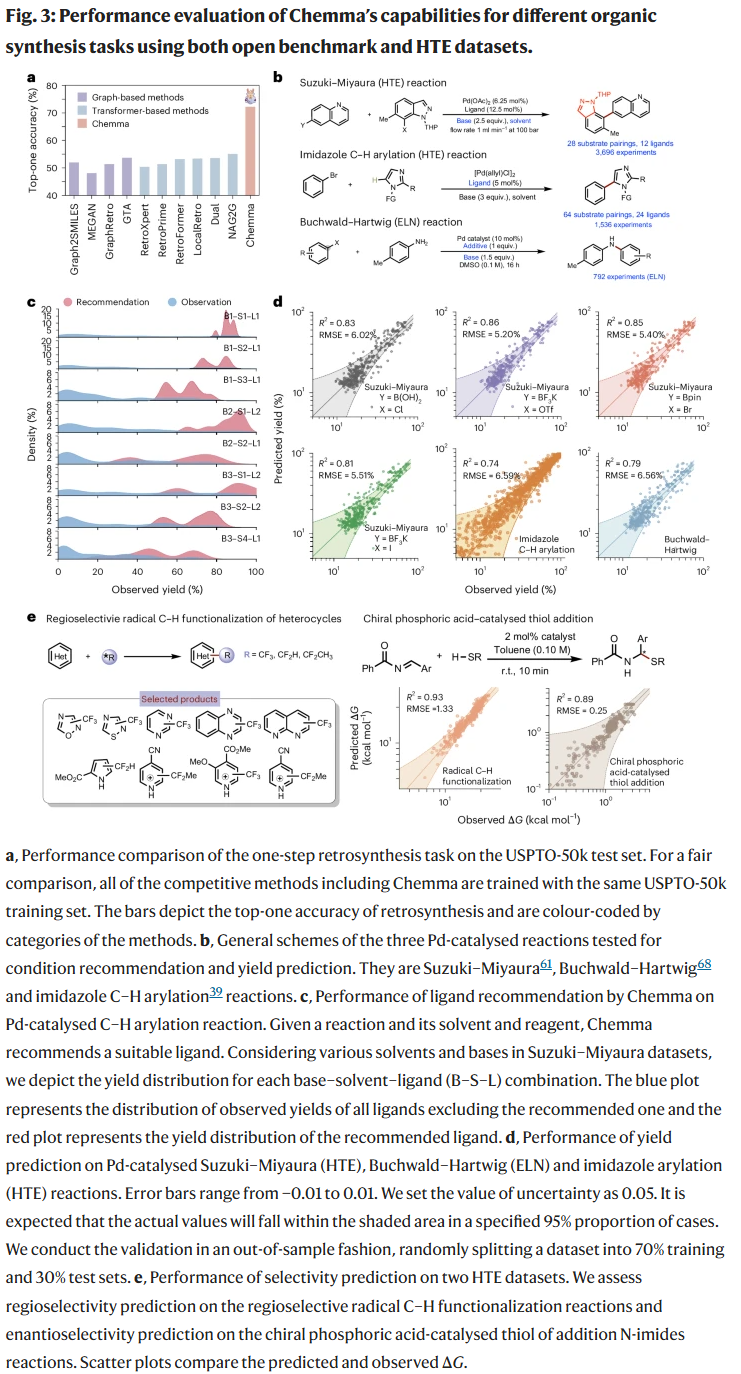
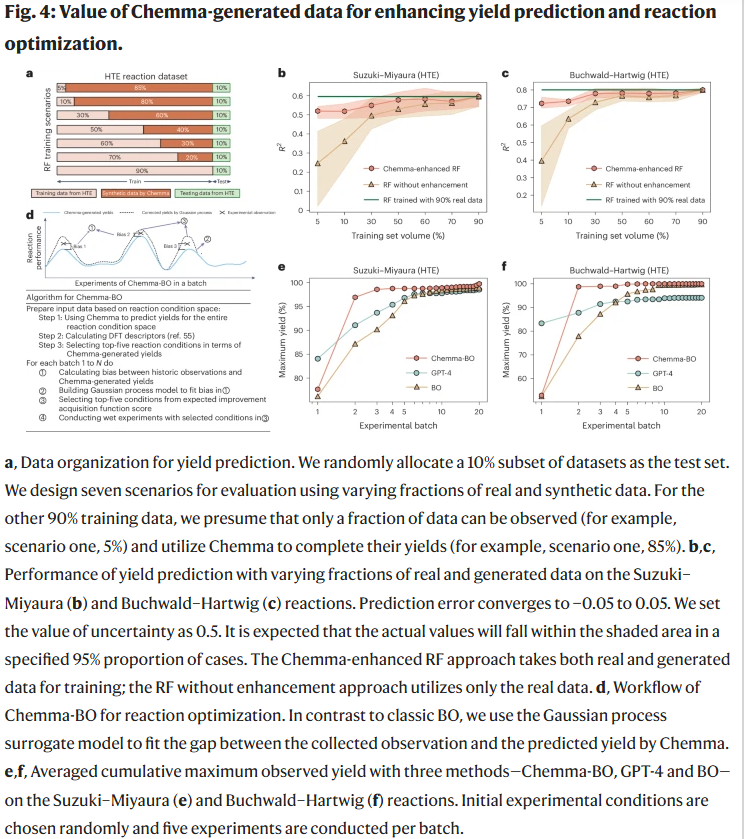
Chemma生成数据对预测与优化的增强作用
研究人员将Chemma预测的数据作为训练增强手段,提升了随机森林模型在不同真实数据比例下的产率预测性能。进一步地,Chemma-BO框架结合Chemma预测数据与贝叶斯优化,在Suzuki–Miyaura与Buchwald–Hartwig反应中大幅减少了实验次数,即可获得接近最优产率,明显优于仅使用GPT-4或传统BO的策略。
在开放反应空间中的探索与优化
研究人员将Chemma集成入主动学习框架,探索未被报道的Suzuki–Miyaura反应中适配的配体与溶剂。在仅15次实验中,通过人机交互、模型微调与提示注入,成功筛选出PAd3与1,4-二氧六烷组合,产率达到67%。此任务展示了Chemma在开放反应空间中辅助探索未知反应条件的潜力。后续对不同底物的兼容性测试也显示出该策略的推广性。
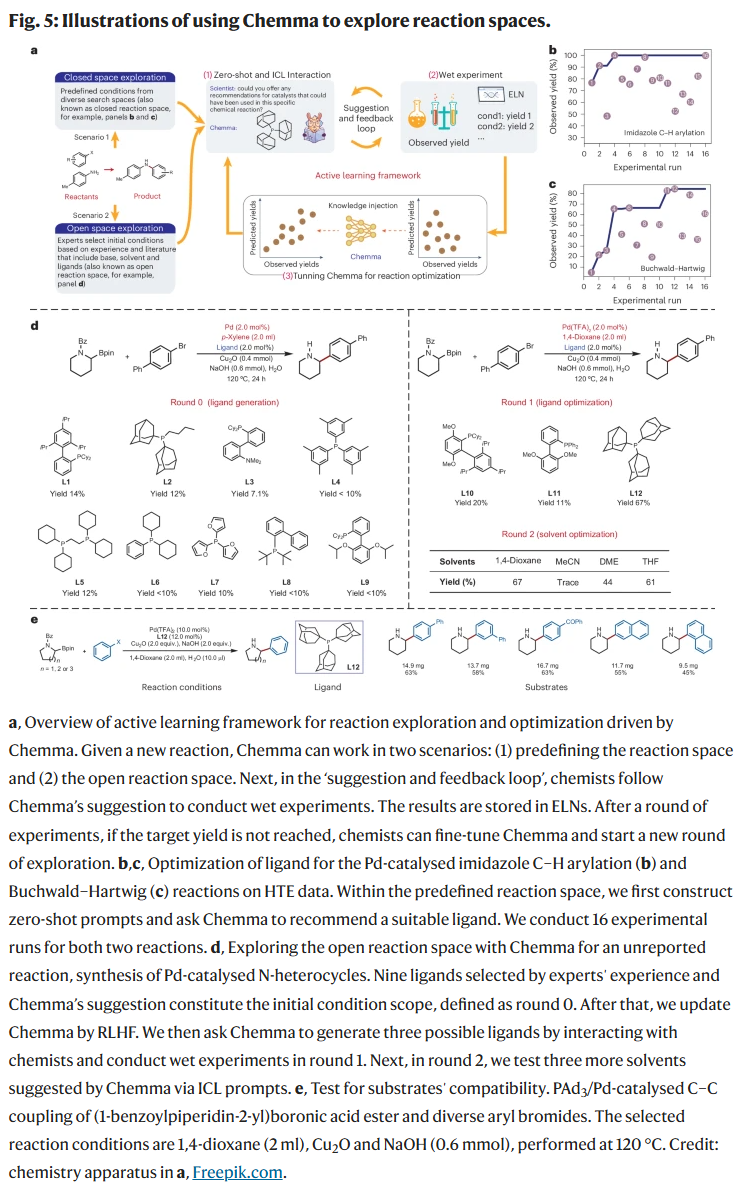
讨论
优势与前景
Chemma将化学反应视作自然语言任务,学习其结构与规律,在多个有机化学任务中表现优异,展现出良好的人机协作能力。特别是在无需DFT的条件下实现产率与选择性的精准预测,以及在开放空间中完成自主优化,充分证明了语言模型在化学合成中的适用性。
局限性
Chemma在面对样本极少的反应或未知反应时,可能表现不稳定。其生成结果有时较为多样,增加了筛选成本。同时,Chemma也面临典型的“幻觉”问题,即提出不可行或矛盾的反应路径。研究人员建议通过人类专家指导、标准化提示模板与专业知识注入,增强其稳定性与实用性。
风险与对策
Chemma潜在的滥用风险需引起重视,例如用于合成有害物质的可能性。研究人员建议通过硬编码提示模板、安全审查算法与专家审核机制来防止此类情况。知识产权的归属问题也需明确,例如模型生成的分子是否归属于用户,建议结合法律意见与行业规范制定应对方案。
整理 | WJM
参考资料
Zhang, Y., Han, Y., Chen, S. et al. Large language models to accelerate organic chemistry synthesis. Nat Mach Intell (2025).
https://doi.org/10.1038/s42256-025-01066-y
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢