
中国电信研究院联合中心科研团队:清华大学 CoAI 课题组发布了RCO(Refinement-oriented Critique Optimization),一项旨在训练批评模型以实现更优改进的创新框架。该研究致力于解决现有大型语言模型(LLMs)在批评能力方面存在的局限性,特别是如何生成最有效、能够真正引导模型响应优化的批评意见。
该研究工作已收到第63届国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称 ACL)的录用消息,将被收录于“Findings of ACL 2025”。ACL 年会是计算语言学和自然语言处理领域的国际排名第一的顶级学术会议,由国际计算语言学协会组织,每年召开一次,在中国计算机学会(CCF)推荐会议列表中被列为 A 类会议。ACL 2025 将于2025年7月27日至8月1日在奥地利维也纳举行。
随着大型语言模型(LLMs)的快速发展,它们在评估和生成自然语言反馈方面的能力日益突出,能够提供深刻的反馈并识别各种任务中的缺陷。然而,目前对何种自然语言反馈最能有效改进模型响应,以及如何生成此类反馈的研究相对有限。现有的方法主要训练模型生成自然语言反馈用于辅助评估,而非将其与原始模型的改进过程联系起来,这导致了批评模型只能够作为一个好的裁判,而非能帮助学生进步的好老师。
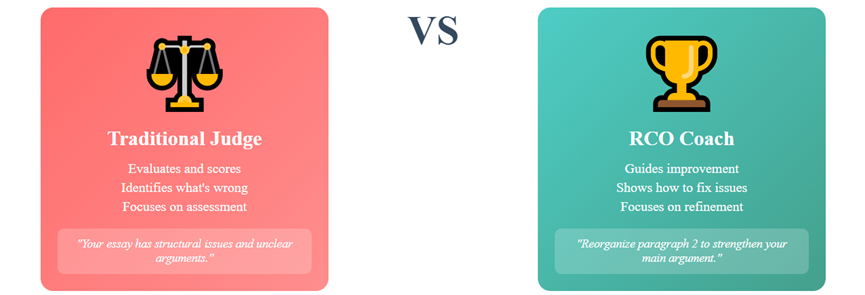
图1:传统方法和RCO的形式化对比:传统方法更倾向于训练一个裁判,RCO则倾向于训练一个老师
为了弥补这一空白,我们引入了RCO,一种新颖的训练范式,通过利用“批评效用”(Critique Utility, CU)来训练批评模型。RCO 使用一个批评-改进的循环,其中由批评模型生成的自然语言反馈将引导原始模型改进其输出的初始答案。CU 量化了这些改进的有效性,并作为训练批评模型的奖励信号。通过关注那些能够带来更好改进的反馈,RCO 确保了有意义的改进驱动型反馈得到奖励。

图2:RCO的特色在于RCO训练批评模型使其生成那些能够带来更好改进的反馈
RCO作为一种以改进为导向的自然语言反馈优化框架,具有以下显著特点:
聚焦于有效改进:RCO通过将自然语言反馈与模型改进的实际效果挂钩,确保模型学习生成能够带来有意义提升的反馈。通过关注改进结果,RCO消除了对直接批评偏好评估的需求,并奖励那些能够带来更好改进的反馈。
新颖的监督机制:我们提出了一种基于改进响应偏好的新颖监督方案,无需直接评估自然语言反馈的质量,同时奖励能够带来有意义改进的反馈。
广泛的任务评估:RCO在对话生成、摘要、问答、数学推理和代码生成等五项任务中进行了严格评估,结果显示其在反馈质量和改进能力方面均显著优于现有方法。
卓越的性能提升:实验结果表明,RCO显著提升了批评模型的性能,在多个基准测试中均优于现有方法。
RCO的构造过程如图3所示,主要包括数据收集和训练过程。
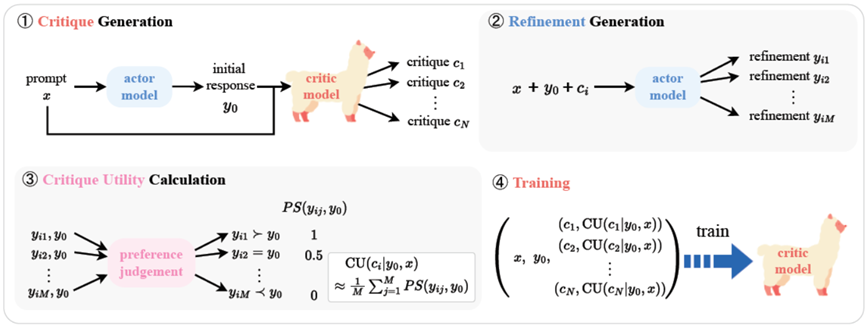
图3:RCO的数据收集和训练框架
数据收集
训练数据的收集包括以下步骤:
1. 我们从五种任务(对话生成、摘要、问答、数学推理和代码生成)的14个数据集中收集了共计10,000个独立问题;
2. 使用4种actor模型(LLAMA-2-7B-Chat, LLAMA-2-13B-Chat, LLaMA-2-70B-Chat, LLaMA-3-8B-Instruct)为这些提示生成初始答案;
3. 使用基座模型为每个初始答案生成N个自然语言反馈;
4. actor模型会根据接收到的评论生成M个不同的改进答案;
5. 然后,通过比较改进答案与初始答案的偏好,计算批评效用(CU);
6. 最后通过数据筛选,选择8,000个问题及它们的所有反馈和CU值作为训练数据,训练基座模型成为批评模型。
训练目标推导
RCO的目标是通过批评效用奖励生成的反馈。我们使用一个最小二乘误差目标作为训练目标,优化模型以最大化反馈的效用。相比传统基于偏好的学习方法,我们的训练目标能更有效地利用标量奖励值,使批评模型学习到更细致的奖励表示,从而提升整体模型性能。

图4:RCO的训练目标,其中Z_{\beta}为归一化常数
总体性能
我们的综合评估表明,经过 RCO 训练的批评模型在多个维度上始终优于所有基线方法。RCO 在批评效用(CU)和响应质量分数(RQS)指标上均取得了显著提升。这一性能优势在所有基础模型架构和尺寸上都得到了验证,证明了我们训练范式的有效性。值得注意的是,经过 RCO 训练的较小型模型(例如LLaMA-2-7B-Chat)甚至超越了其较大的对应模型(例如LLaMA-2-70B-Chat),显示出强大的参数效率。性能提升在数学推理和代码生成任务中尤为显著。
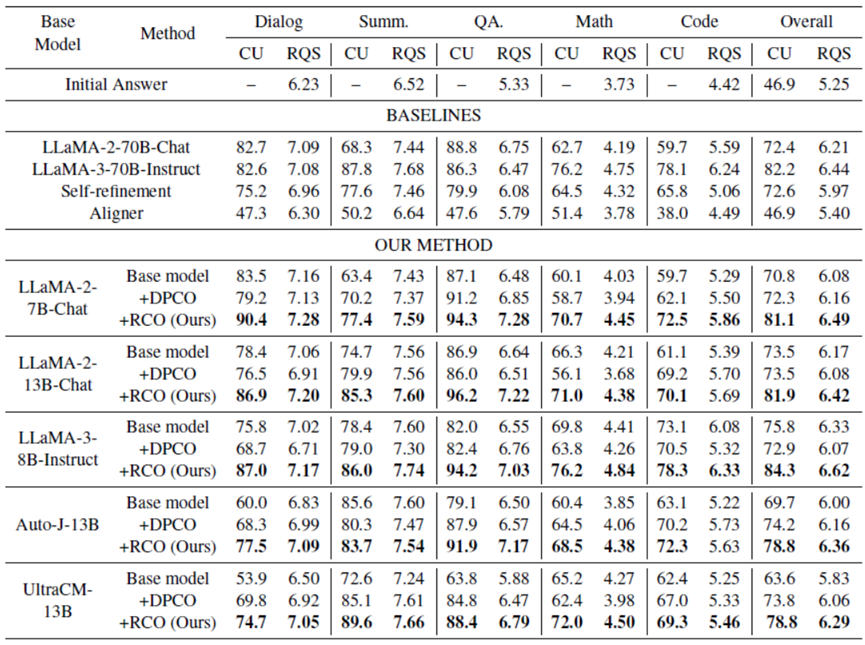
图5:RCO的训练结果与传统的方法以及更大尺寸的模型基准相比提升显著。DPCO指通过传统方法直接标注自然语言反馈的偏好(Direct Preferences of Critiques Optimization)
人工评估
在人工评估中,我们主要关注性能最佳的 LLaMA-3-8B-Instruct 基座模型,并将其与基准版本、LLaMA-3-70B-Instruct 模型以及使用传统DPCO方法训练的模型进行比较。评估结果如图6所示,RCO始终在反馈和基于这些反馈生成的改进答案质量上表现出卓越的性能。该结果突显了我们方法在训练模型成为一个好“老师”这一方面的有效性。
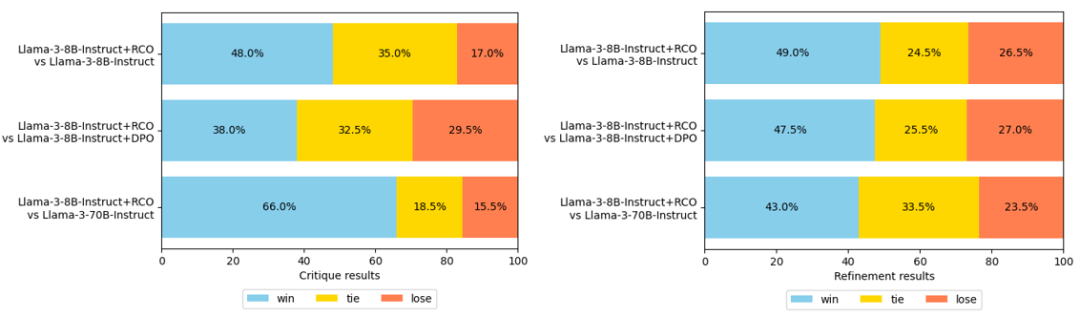
图6:RCO和基准方法的人工评估结果。左侧的图为对反馈的直接偏好评估,右侧的图为对修改后答案的偏好评估
一个有趣且值得深入探究的发现是,人类对反馈的偏好与基于这些反馈生成的改进结果的偏好并不总是保持一致。
为了进一步探究我们的方法为何能生成更有效的自然语言反馈以改进执行模型,我们进行了一项分析:要求人工评估者从以下四个选项中选择他们偏好某一反馈的主要原因:“反馈更准确和正确(Accuracy)”、“反馈提供了对初始答案中错误的更彻底分析(Thoroughness)”、“反馈更清晰、结构更好(Clarity)”和“反馈提供了建设性建议或详细的修改步骤(Constructiveness)”。图7的结果清楚地表明,我们的方法擅长生成不仅正确、清晰、结构良好,而且能提供建设性、可行性建议或详细修改步骤的反馈,这些步骤易于执行模型遵循。相比之下,依赖于 LLM 标注的反馈对偏好的 DPCO 方法,通常会产生分析更丰富、更彻底的反馈,但往往提供模糊或不够具体的建议。此外,DPCO 偶尔会生成不正确的反馈或错误识别反馈的目标。这些发现强调了我们方法在训练批评模型以生成精确、有用的反馈方面的有效性,显著增强了原始模型的迭代改进能力。
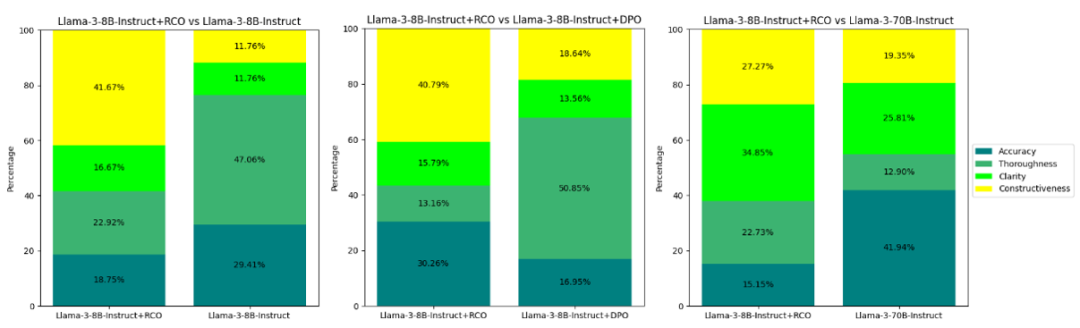
图7:在人工评估反馈质量的基础上,要求标注员给出每个偏好标注的原因。以上是选择情况的统计结果
相关代码和数据已发布,欢迎关注和使用。
代码及数据仓库链接:https://github.com/publicstaticvo/critique
欢迎大家关注和使用我们的评估基准,也欢迎大家向我们提出各种反馈和建议!
清华大学CoAI课题组主页:http://coai.cs.tsinghua.edu.cn
联系邮箱:dailyyulun@163.com(余天枢)、xiangchao@chinatelecom.cn(项超)
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢