

引言
2025年开启了智能体元年,司法行业也迎来了前所未有的智能化浪潮。越来越多司法服务场景开始引入基于大模型的智能体技术,希望提升服务效率与质量。但这些大模型驱动的智能体在真实法律场景中的表现究竟如何?能否胜任复杂的法律任务?这需要一个系统的评估来揭晓答案。
现实的法律服务场景呈现出动态性和专业性的特点。由于普通民众缺乏法律常识,服务过程通常涉及多轮交流,专业人士需要逐步引导民众完成信息采集。法律服务有明确的目的性,过程注重程序的合法性,因此对于流程的把控有严格要求。现有的法律评测体系主要采用静态、非交互式的方法搭建,如选择题和传统法律NLP任务的重构,当前的评测方法与现实场景存在严重的不对齐,限制了对大模型智能体法律智能边界的深入探索。
理想的法律评测环境,比如法庭审理,需要人类参与者来保证可靠性,但这样的设置成本极高且难以扩展。因此,开发此类系统面临两个主要挑战:1)场景全面性:真实法律实践包含多元主体和程序环节,如法律咨询、文书撰写和判决等,需构建足够丰富和具代表性的环境,以多维度评估智能体的法律智能。2)真实世界模拟:每一场景涉及不同角色,这些角色在行为、背景和法律观念上各异,需要实现真实且一致的角色模拟,并确保互动过程动态且符合法律程序规范。
面向这两个挑战,复旦大学、上海创智学院联合上海蜜度公司、华中科技大学、美国南加州大学、西北政法大学构建了首个面向智能体的交互式法律评测框架J1-Bench。核心贡献总结如下:
(A)基于多智能体系统本文构建了一个开放式法律环境J1-ENVS,涵盖中国法律实践中最具代表性的六大真实场景。法律智能体在程序规范的约束下,通过与不同参与方的多轮互动,完成多样化的法律任务。
(B)本文设计了J1-EVAL自动化评测框架,对智能体在不同法律能力层级(从实习生到律师再到法官)上进行细粒度评测。这种细粒度指标能够深入地揭示智能体完成现实法律任务所需的能力结构,提供真实且可信的系统性评估。
(C)本文评测了17种主流LLM。尽管现有模型已具备一定的法律知识表征能力,但在动态法律场景下,仍难以在程序规范约束下灵活交互并完成任务,显示在现实世界中法律任务上的巨大挑战。
(D)本文引入了一种全新的法律智能的范式,即从静态到更加符合现实的动态任务的转变。除评测外,该体系还可以进一步扩展到数据合成和智能体学习训练中。
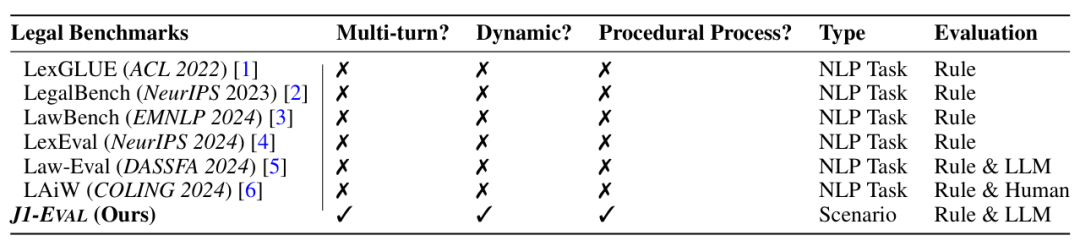
表1 本文的J1-Eval与现有的LLM法律测评基准的对比
论文地址:
https://arxiv.org/abs/2507.04037
Github地址:
https://github.com/FudanDISC/J1Bench
测试集地址:
https://huggingface.co/datasets/CharlesBeaumont/J1-Eval_Dataset
Open Compass地址:
https://hub.opencompass.org.cn/dataset-detail/J1-Bench
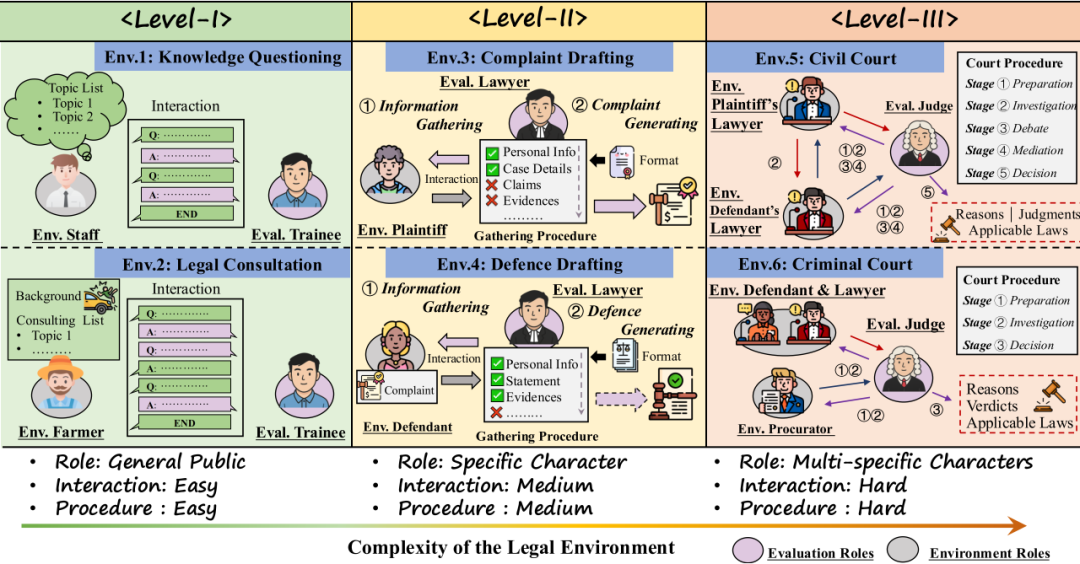
图1 J1-Envs,包含六个具有代表性的法律实践场景,可按场景复杂度分为三层
J1-Envs:交互式法律环境
如图1所示,J1-Envs包含了中国司法实践中六个最具有代表性的法律实践场景:法律知识问答、法律咨询、起诉状起草、答辩状起草、民事法庭和刑事法庭。根据这些场景的角色多样性、交互复杂性与流程困难度,J1-Envs被划分为三个层级。该环境通过智能体角色设定与分层场景构建两大步骤实现。
角色智能体设定
真实法律资源设置。 为模拟现实法律场景,本文基于两个真实数据源:(1)中国裁判文书。针对Level II与Level III场景,本文从中国裁判文书网上收集民事与刑事案例,并利用LLM自动抽取关键要素;(2)法律文章。针对Level I强调递进式提问逻辑的场景,本文收集了华律网与《民事审判实务问答》中的文章(结构为分步式标题),LLM据此生成结构化的话题列表及对应答案,并将话题分为判断题(是/否)和开放问题两类。
人格理论驱动的行为建模。 为增强角色行为的多样性与现实一致性,本文参考社会人格理论,根据非法律专业角色(普通大众、原告与被告)的角色画像,提示GPT-4o标注角色大五人格每个维度(低、中或者高),再由此生成角色行为风格。
角色智能体的配置。针对三个层级对应的角色,本文分配相应的法律要素:(1)类型一:普通大众,即通常缺乏法律知识的主体,希望进行知识类(Env.1)或情景类(Env.2)咨询,配置有话题列表、背景信息及行为风格;(2)类型二:特定当事人,希望委托法律专业人士起草文书,配置个人画像(如姓名、性别、住址)、案件细节(如诉讼请求、答辩意见及证据)与行为风格等信息;(3)类型三:多特定当事人,在法庭程序中承担特定职责。他们分别配置有相对应身份的要素。例如,民事法庭律师拥有基于判决文书抽取的详细案件信息,包括委托人信息、案件详情及诉辩要点。
多层级场景构建
Level I:法律知识问答与法律情景咨询,模拟普通大众与法律实习生之间或基于特定主题,或基于某个具体事件的法律咨询流程。在这两个场景之中,普通大众与法律实习生之间轮流发言,直至普通大众所有的疑惑得到详细阐释为止。
Level II:起诉状起草和答辩状起草,模拟特定当事人寻求律师起草法律文书的过程。在这两个场景之中,法律智能体要在遵循指定格式的前提下,发问并根据从特定当事人处收集来的信息,正确生成法律文书(起诉状和答辩状)。
Level III:民事法庭和刑事法庭,各自包含法官以及对垒的两方,如原告律师和被告律师,或公诉机关与被告人及其辩护人。为了反映法庭在程序上的严谨性,本文将一场模拟法庭划分若干阶段,并在每个阶段规定了必须完成的关键操作。只有当法官完成某个阶段的全部关键操作,这个阶段才被认为“已完成”。法官需要在遵循特定程序的同时,根据从双方处搜集来的信息生成判决预测。
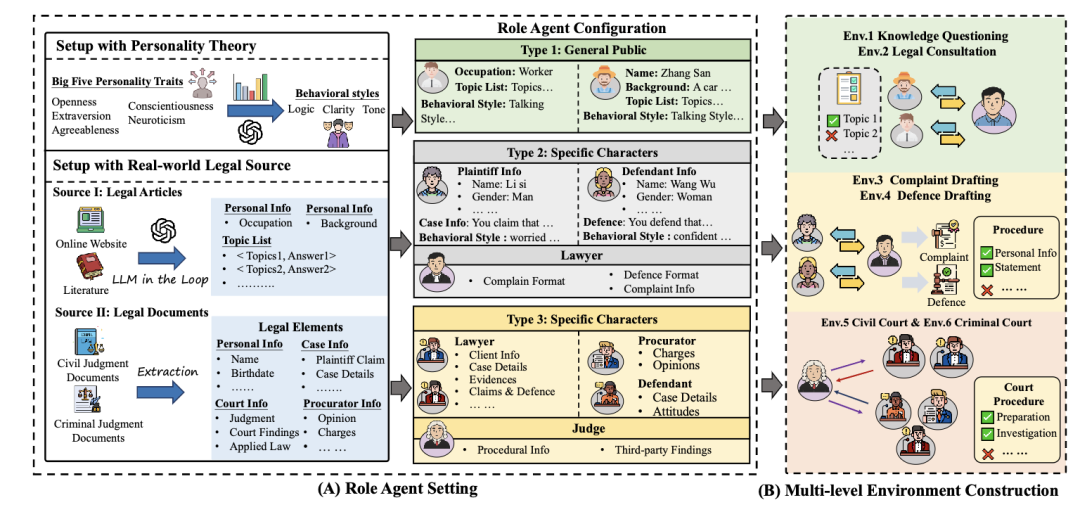
图2 J1-Envs的场景构建过程。从真实世界法律源中抽取法律要素,按照不同的角色要求配置给智能体,然后按照法律专家设定的逻辑构建成不同的法律环境
J1-Eval:全面的自动化评测
数据集。经系统化处理后,J1-EVAL共构建了508个不同环境,其中Level I 160个,Level II 186个,Level III 192个。如图3所示,每个场景覆盖了丰富的且和现实一致的法律属性。
评测方法。针对每项任务,本文采用基于规则或LLM的自动化评测方法,并提供明确的参考答案。具体而言:
Level I包括判断题得分(BIN)和开放问题得分(NBIN)。
Level II包括模板遵循能力得分(FOR)和文档正确性得分(DOC)。
Level III包括流程遵循能力得分(PFS)、判决准确性得分(JUD)、推理准确性得分(REA)和引用法条准确性(LAW)得分。
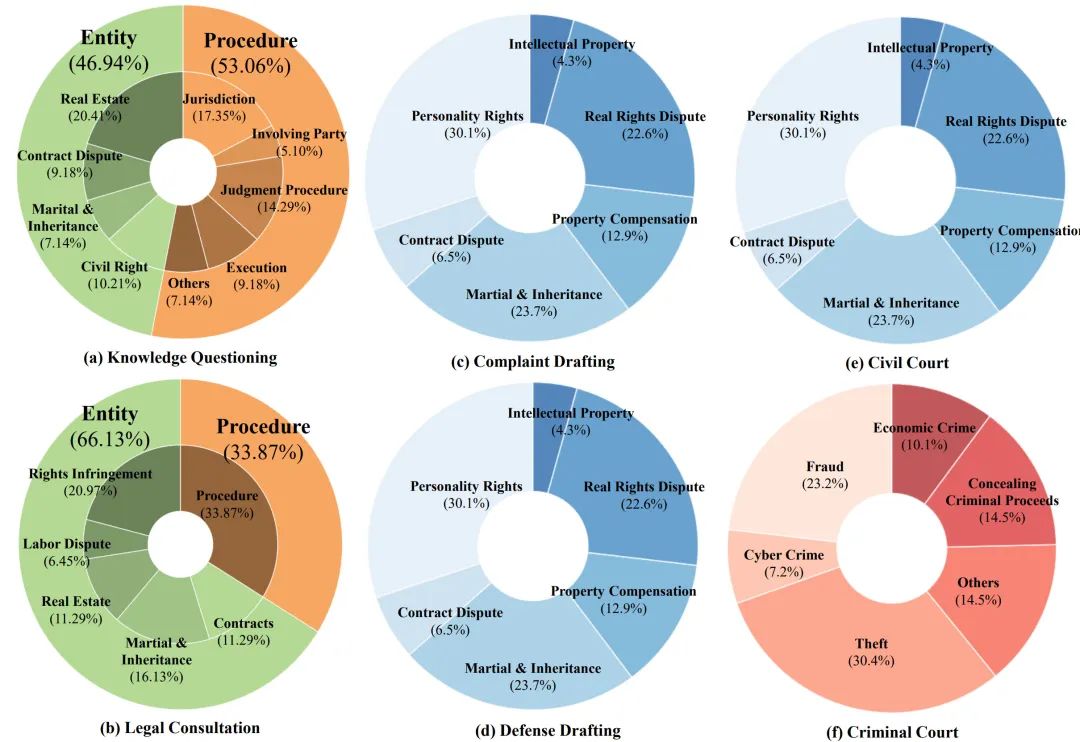
图3 J1-Eval测试集的数据分布,涵盖了多个类目下的法律案例
实验
评测模型
(1)通用多语言 LLM: GPT-4o, Claude-3.7, Deepseek-v3, Deepseek-r1, InternLM3-Instruct 8B, Qwen2.5-Instruct 7B, Qwen3-Instruct 4B/8B/14B/32B, ChatGLM4-chat 9B, Ministral-Instruct-2410 8B.
(2)法律领域 LLM: LawLLM 13B, Chatlaw2 7B.
总体表现对比
GPT-4o表现最佳,法律智能最强;Qwen3-Instruct-32B超预期,优于Deepseek系列。值得注意的是,法律专用模型虽在传统基准上与GPT系列相当,但在本评测中明显落后,甚至低于部分小模型,说明其缺乏交互能力,难以胜任动态法律场景。总体来看,模型规模越大,法律智能水平越高,但即使是最先进模型,平均得分也未超过60分,表明LLM在应对复杂多样法律任务时仍存在较大挑战。
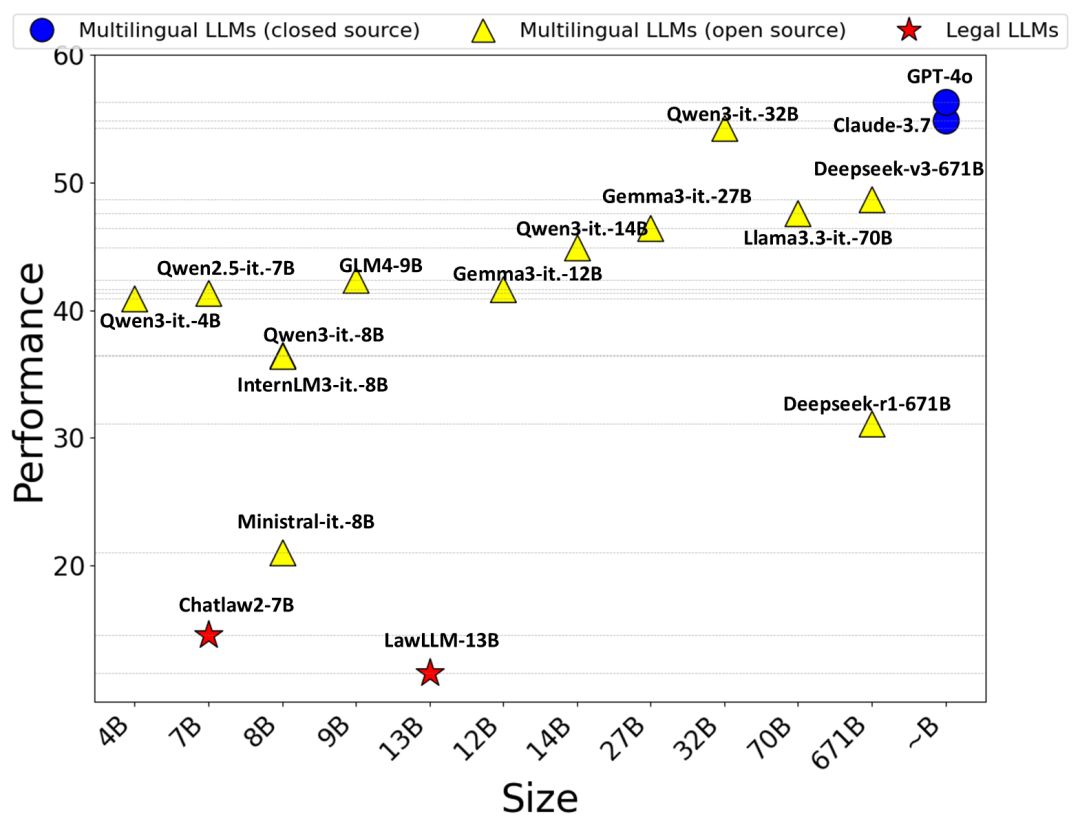
图4 法律智能体的总体表现排名
不同level评测结果
如表2所示,模型驱动的智能体在Level I的表现较好,但在更加复杂的Level II和Level III表现下降。这一结果说明,一方面,现有模型在多智能体环境下的交互能力需要提升;另一方面,现有模型驱动智能体遵循特定模板生成法律文书的能力与遵循特定法律流程的能力仍然不足。此外,模型的推理能力和流程遵循能力对智能体作出判决的正确性起关键作用。
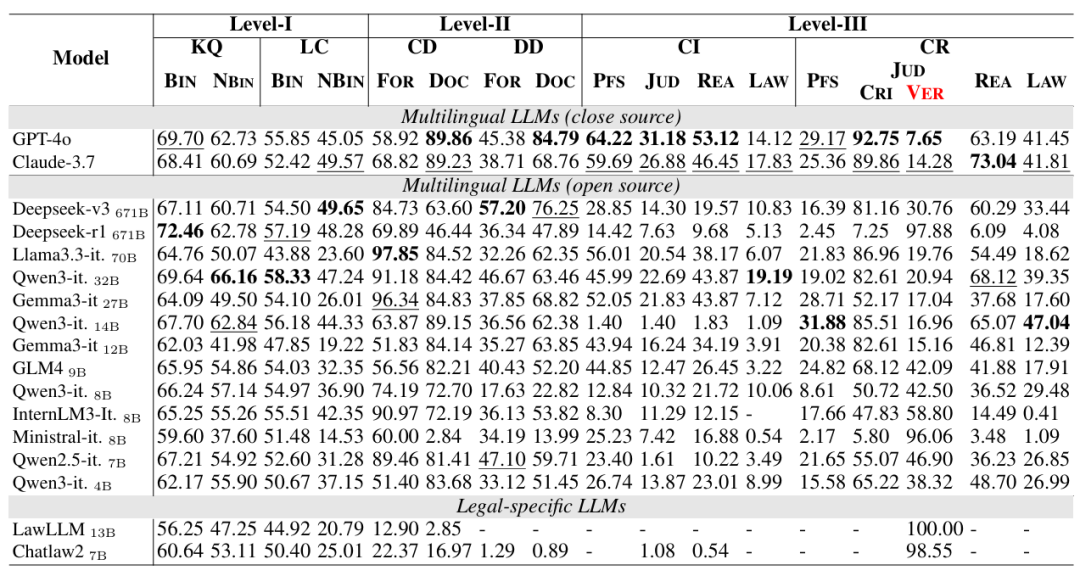
表2 不同模型驱动的法律智能体在J1-Eval的评测结果对比
法律智能体的流程遵循能力评测
考虑在所有案例当中,法律智能体完成法庭流程特定阶段的比例。如图5所示,法律智能体难以完成模拟民事法庭和模拟刑事法庭的流程。此外,即使流程上较为简单,因为模拟刑事法庭中需要交互的智能体数量增加,法律智能体的流程遵循表现出现了明显的下降。
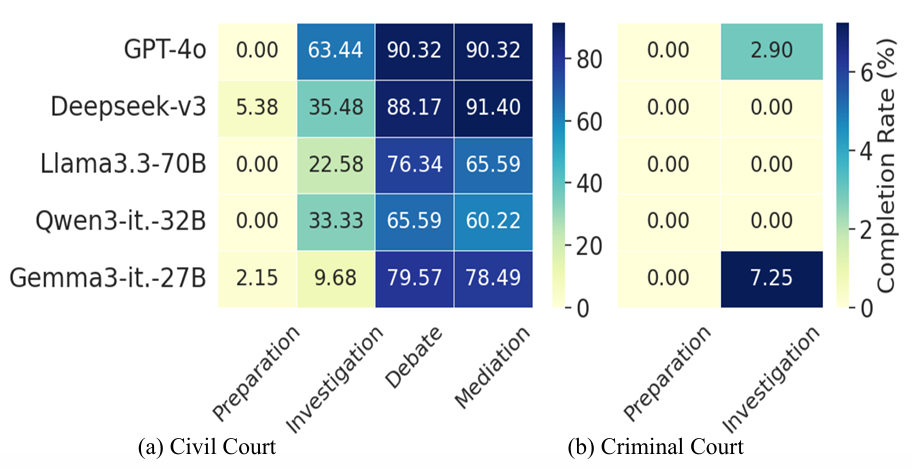
图5 法律智能体在模拟民事法庭和模拟刑事法庭中的流程遵循能力
J1-Envs的可靠性分析
本文利用不同大模型(GPT-4o与Qwen3-Instruct 32B)驱动J1-Envs,并对比这两个不同环境下法律智能体的表现。如图6所示,不同J1-Envs下的智能体表现差异不大,证明了J1-Envs的可靠性和稳定性。
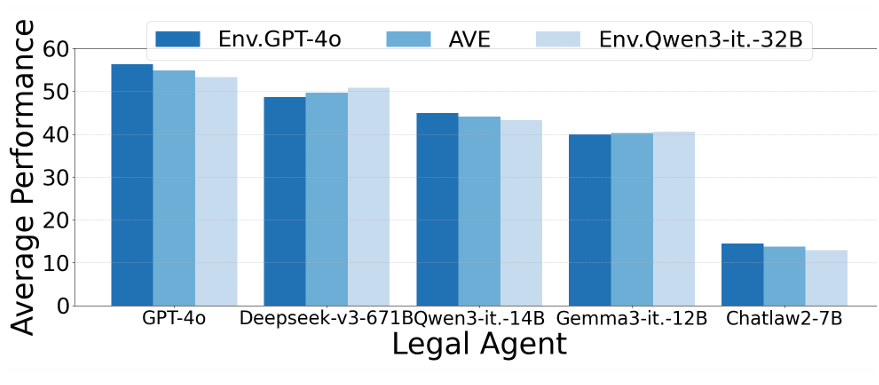
图6 法律智能体在不同模型驱动的J1-Envs中的表现
本文使用GPT-4o评测与人类评估这两种方式,为每个环境中角色的行为与其设定的一致性打分,表3结果说明了在不同大模型驱动的环境下,环境角色的表现与其设定高度一致,这进一步证明了J1-Envs的可靠性。
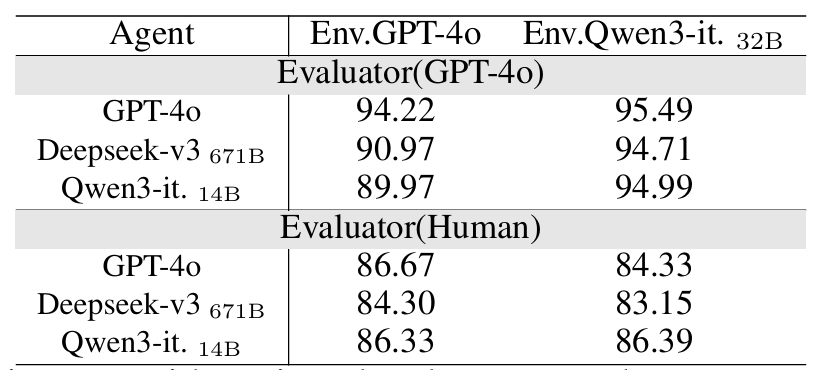
表3 环境角色的行为与其设定的一致性评分
J1-Eval的可靠性分析
针对J1-Eval中需要用到模型评测的指标,本文每个指标选取10条例子并邀请人类评分者打分。通过计算人类评分者的分数与对应的模型评分的差异,如图7所示,本文发现大部分(大于76%)的人类评分与GPT-4o评分相近,这说明了J1-Eval评测工具的可靠性。

图7 人类评分与模型评分差距的分布
实验结论总结
基础法律知识理解良好:在Level I,通用和法律专用模型在法律知识问答任务上表现出色,显示出对基础法律知识的扎实掌握,但在交互需求更高的法律情景咨询上表现下降。
法律专用模型并无绝对优势:法律专用大模型在传统法律任务评测中与通用大模型表现相当,但在需要更复杂交互的应用场景下,法律专用模型并未展现出明显优势。这说明目前法律LLM在真实法律服务中的落地能力仍有待提升。
复杂法庭流程挑战突出:在Level III中的民事和刑事法庭场景下,大部分模型难以完整执行多阶段法律程序,特别是法律专用、推理型和小规模模型表现不佳。此外,模型在多角色协作和高复杂互动场景中的能力不足,导致在刑事法庭面临更大流程挑战。
推理模型的局限性明显:如Deepseek-r1在流程执行上的低分,揭示了当前推理模型在复杂法律环境下的适用性有限。
程序规范和复杂推理为未来关键:未来需重点提升法律智能体在法律程序规范遵循及长上下文的复杂推理能力上的表现,从而更好地适应真实法律服务环境与多变的司法场景需求。
结语
本文提出了首个面向法律智能体的动态交互法律评测系统,以期全面反映法律智能体在动态交互环境下的表现。实验结果表明,尽管已经具备了一定程度的法律知识,法律智能体在复杂环境下的交互能力、流程遵循能力与完成特定法律任务的能力仍需要提高。本文提出的框架揭示了未来潜在的研究方向,可被扩展于数据生成与强化学习,为法律智能的研究从静态向动态的转变做出了贡献。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区计算中心

点击“阅读原文”跳转至Github
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢