

【论文标题】Cross-Modal Generalization: Learning in Low Resource Modalities via Meta-Alignment 【作者团队】Paul Pu Liang,Peter Wu,Liu Ziyin,Louis-Philippe Morency,Ruslan Salakhutdinov 【发表时间】2020/12/04 【论文链接】https://arxiv.org/pdf/2012.02813.pdf
【推荐理由】 本文出自卡内基梅隆大学和东京大学联合团队,针对低资源跨模态分类任务,提出了一种能够利用不同源模态数据进行高效训练的元对齐学习框架,取得了优异的泛化性能。
现实世界充斥着各种各样通过视觉、听觉、触觉和语言模态的信息。尽管目前多模态学习领域取得了一系列的进展,但是大多数工作主要关注训练和测试时使用的多模态数据相同的问题,这使得对低资源的模态学习尤为困难。
在本文中,作者提出了一种跨模态泛化算法,这种学习范式旨在训练具备以下能力的模型: (1)在目标模态上快速地执行新的任务(即元学习) (2)在满足(1)的条件下使用不同的源模态进行训练。 本文针对「在为不同的源模态和目标模态使用不同的编码器的情况下,如何保证不同模态之间的泛化」这一问题展开了研究。为此,本文作者提出了一种基于「元对齐」的解决方案,这是一种使用强匹配和弱匹配跨模态数据对齐表征空间的新方法。
在实验过程中,作者研究了三种跨模态分类任务:(1)文本到图像(2)图像到音频(3)文本到语音。在新的目标模态仅仅包含 1-10 个标注样本,且存在噪声标签的典型低资源情况下,本文提出的方法仍然可以取得很好的性能。
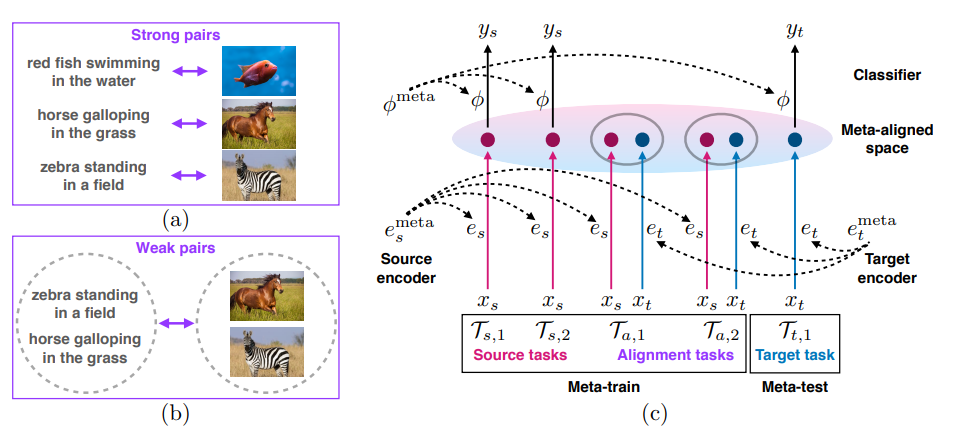
(b)为弱对齐:较为粗粒度的语义划分,更好地反映了多对多跨模态映射,可以利用互联网上的弱模态对数据(例如,视频、图片描述)(c)跨模态泛化训练算法:在元训练阶段,会使用元模态分类任务和对齐任务对元参数进行训练。元测试阶段会将训练好的元参数用于目标模态任务的小样本泛化。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢