
摘要
对正在爆发的传染病短期传播进行预测,面临着参与因素复杂且相互关联的挑战,这些因素既包括多模态变量,也涵盖公共政策与人类行为的交互影响。本文提出了一种名为 PandemicLLM 的框架,该框架基于多模态大语言模型,将实时流行病预测重新表述为文本推理问题,并能够整合实时、复杂且非数值化的信息。研究通过人工智能—人类协同提示词设计与时序表示学习,实现对多模态数据的编码。以COVID-19疫情为应用场景,PandemicLLM利用公共卫生政策文本、基因组监测、空间与流行病学时序数据进行训练,并在美国50个州开展了为期19个月的测试。结果表明,PandemicLLM在整合异构信息来源方面具备独特优势,且相较现有模型展现出显著性能提升。
同时,集智俱乐部联合北京师范大学许小可教授、浙江大学张子柯教授、南京大学王成军教授、深圳大学廖好副教授共同发起“AI×传播”读书会,从计算叙事、智能传播、人机传播与传播仿真四个板块向来共同探索AI与传播的前沿交叉,来深度理解传播机制和传播生态。欢迎对此话题感兴趣的朋友报名加入社群。
关键词:大语言模型;实时流行病预测;多模态数据;文本推理;住院趋势分类;基因组监测;提示词设计;时序表示学习

彭晨丨作者


论文题目:Advancing real-time infectious disease forecasting using large language models
发表时间:2025年6月6日
论文地址:https://www.nature.com/articles/s43588-025-00798-6
发表期刊:Nature Computational Science
流行病短期预测对公共卫生应急决策至关重要。然而,现有机制模型(mechanistic models)虽可融入场景假设,却难以及时捕捉复杂多变的实时信息;统计模型虽对近期趋势具有较好适应性,却在整合多源异构数据、响应突发政策调整及新毒株出现等方面存在明显局限。此外,将预测结果可靠地转化为可信的决策指导,并向公众传递清晰的置信度信息,也是一大难题。近年大型语言模型(LLMs)在多模态上下文学习与文本推理方面展现了卓越能力,为破解上述困境提供了全新思路。
PandemicLLM框架概览:
将疫情预测化为文本推理
PandemicLLM框架概览:
将疫情预测化为文本推理
面对复杂多元的疫情数据,研究团队提出模型PandemicLLM,将传统的数值预测问题转化为LLM擅长的文本推理任务。首先,通过人工智能—人类协同提示词设计(AI–human cooperative prompt design),将空间、流行病学时序、公共卫生政策及基因组监测(genomic surveillance)等多模态数据,统一转换为自然语言描述(图 1a)。随后,采用循环神经网络 RNN 对时序数据进行表征学习,并将其嵌入到提示文本中(图 2)。最终,以LLaMA2为基础模型,通过一系列有监督的微调操作,在“模型生成→概率计算”中,输出未来1周和3周的住院趋势分类预测及相应的置信度。
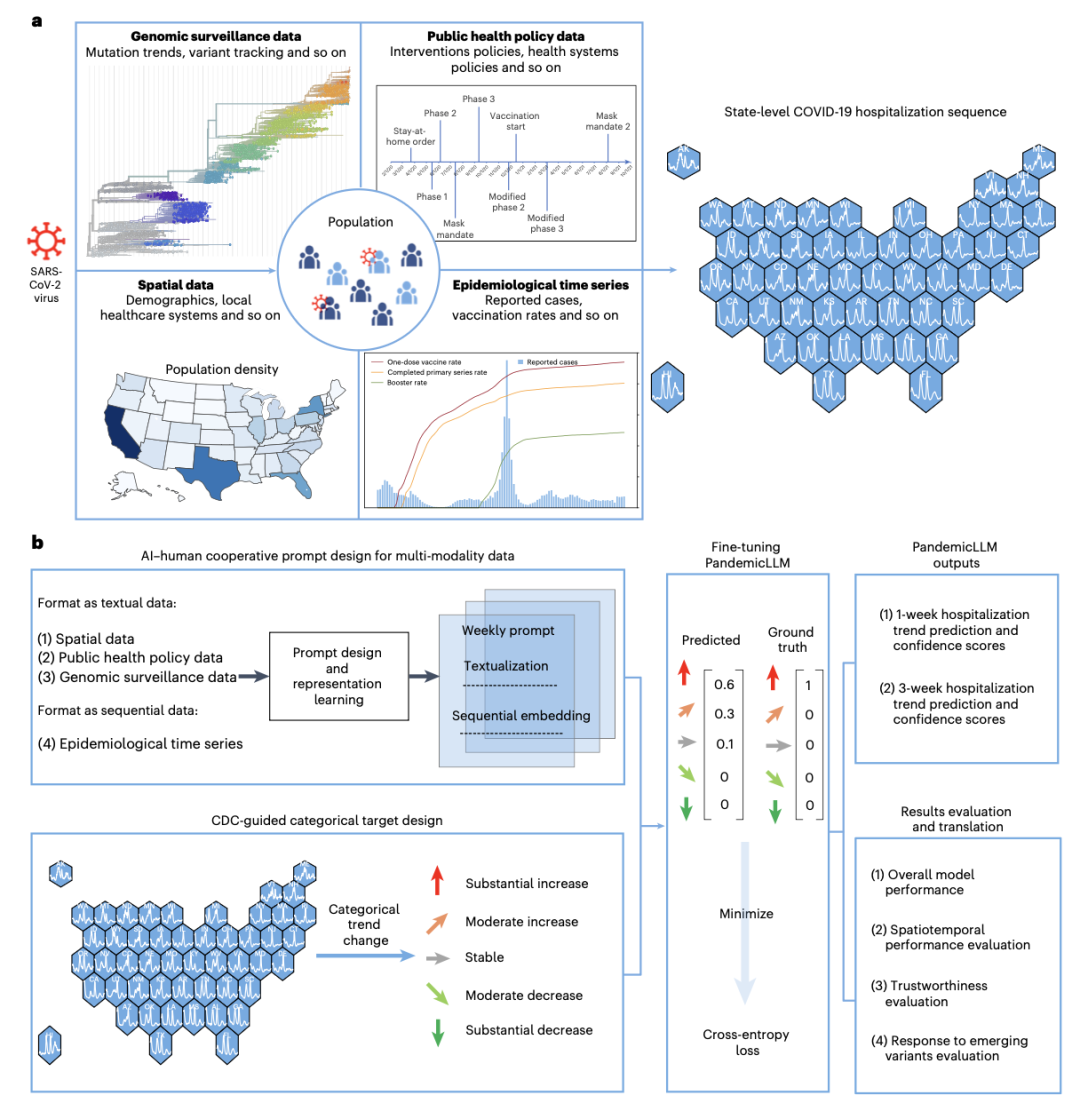
图 1. PandemicLLM的流行病数据处理流程。
多模态数据的整合与文本化
多模态数据的整合与文本化
PandemicLLM在数据准备阶段,构建了覆盖美国50个州、104周的5 200条记录,包含四类信息:一是静态的空间数据,包括人口结构、医疗系统评分及2020年总统选举结果;二是周度流行病学时序数据,如每万居民住院率、报告病例与疫苗接种率;三是政府干预政策文本,记录学校与公共活动限令、口罩令等;四是基因组监测数据,既有权威组织对新变异株的文本报告,也有CDC加权估算的变异株比例。研究团队基于专家知识,将各州指标排名转化为“高于平均”“接近平均”“低于平均”等描述,并借助AI生成时序数据摘要,确保提示文字既准确又连贯。
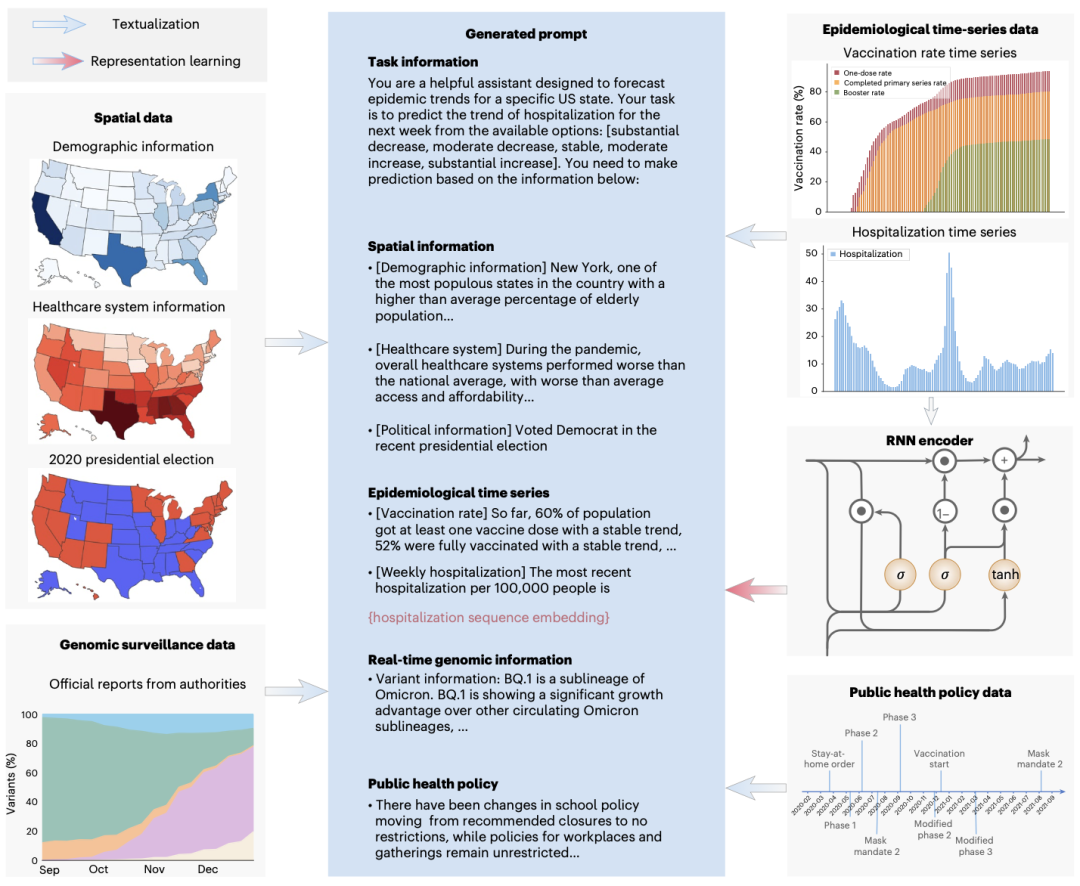
图 2. 人工智能-人类合作提示词设计。美国所有50个州的空间数据被转换成语言描述,以反映指标排名;策略数据包括严格级别和每周的变化。流行病学时间序列数据使用叙述生成(narrative generation)和表征学习。表征学习组件使用RNN编码器,图中显示了一个基于GRU的编码器,其中σ表示sigmoid激活函数。基因组监测数据将变异特征的文本摘要与近期流行情况相结合。
模型训练与验证流程
模型训练与验证流程
在提示文本与序列表示构建完毕后,PandemicLLM展开细致的训练与验证:研究团队构建三版模型——PandemicLLM-1(使用前5个月数据)、PandemicLLM-2(前11个月数据)与PandemicLLM-3(20个月数据),并分别在之后19、13、4个月的数据上测试,均未进行额外再训练。
模型采用交叉熵及改进的损失函数,细化对不同类别错误的惩罚。为对比基准,研究选取CDC Ensemble Model的预测结果,并将其连续分位数输出映射为五类HTC类别,确保可比性。
性能评估与可信度分析
性能评估与可信度分析
综合准确率、加权均方误差(weight MSE,WMSE)、Brier得分与排名概率得分(RPS)等指标,三个版本的PandemicLLM在1周与3周预测上均显著超越CDC Ensemble Model,尤其在关键转折点(如2021年9月流行高峰和2022年初Omicron来袭)保持稳定性能。
进一步通过“置信度阈值”分析发现,随着预测置信度增加,模型精准度同样提升:PandemicLLM-2在置信度≥0.85时,1周预测正确率达75%、3周达77%,为决策者提供了可依赖的风险指南。此外,通过时间匿名化提示与全模型去标识化测试,验证了PandemicLLM对先验知识的稳健依赖,确保了预测的公正与可信。
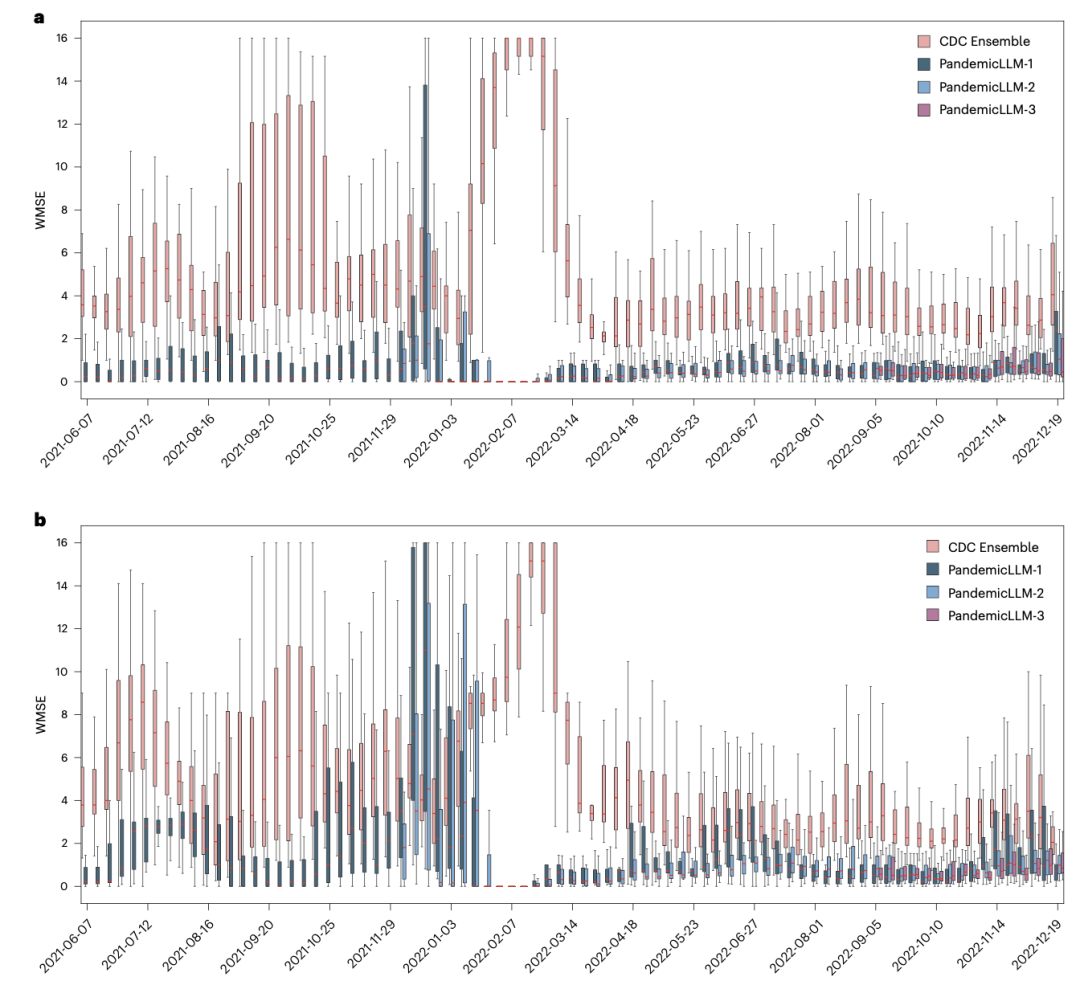
图 3. PandemicLLM模型表现评估。三种PandemicLLM与CDC集成模型的跨时间性能比较y轴表示WMSE的尺度。图中的每组柱状图代表了特定一周内所有50个州的WMSE分布。a、1周预测效果。b、3周预测表现。
传统模型在应对突变株时存在的问题是,常因报告滞后而预测失准。PandemicLLM独特之处在于,可将权威机构对新变异株的传染性、重症率与免疫逃逸等文本信息,连同当周变异株比例嵌入提示词。实验证明,在2022年10月起新变异株快速流行阶段,加入基因组监测信息的PandemicLLM-3较对照版本,预测置信度平均提升20.1%,WMSE平均降低28.2%,显著增强了对上升趋势的敏锐捕捉。
应用前景与挑战
应用前景与挑战
PandemicLLM开创性地将多源异构疫情数据整合为自然语言输入,为短期预测提供了新范式。未来,随着本地化数据(如县级监测、废水流行病学及行为调查)的加入,可进一步细化到更小范围的决策支持。另一方面,LLM微调仍需大量算力与数据,难以直接用于长期数值预测及资源受限场景;模型内在“黑箱”特性也需结合可解释性工具加以缓解。总之,PandemicLLM为疫情应急响应注入了AI与文本推理的创新动力,展望可推广至流感、呼吸道合胞病毒等更多公共卫生领域,为精准预警与科学决策提供坚实支撑。
AI×传播读书会会
在AI快速发展的当下,AI不仅深刻影响着信息传播的方式,也为传播学研究带来了全新视角和方法。基于此,集智俱乐部联合北京师范大学许小可教授、浙江大学张子柯教授、南京大学王成军教授、深圳大学廖好副教授共同发起“AI×传播”读书会,从计算叙事、智能传播、人机传播与传播仿真四个板块向来共同探索AI与传播的前沿交叉,来深度理解传播机制和传播生态。读书会自8月23日起,每周六10:00-12:00举行,预计持续12周。欢迎扫码加入,共建“AI×传播”社区。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢