

今日凌晨,OpenAI 发布了其开源模型 gpt-oss,这是继 6 年前 GPT-2 之后的首次开源尝试。
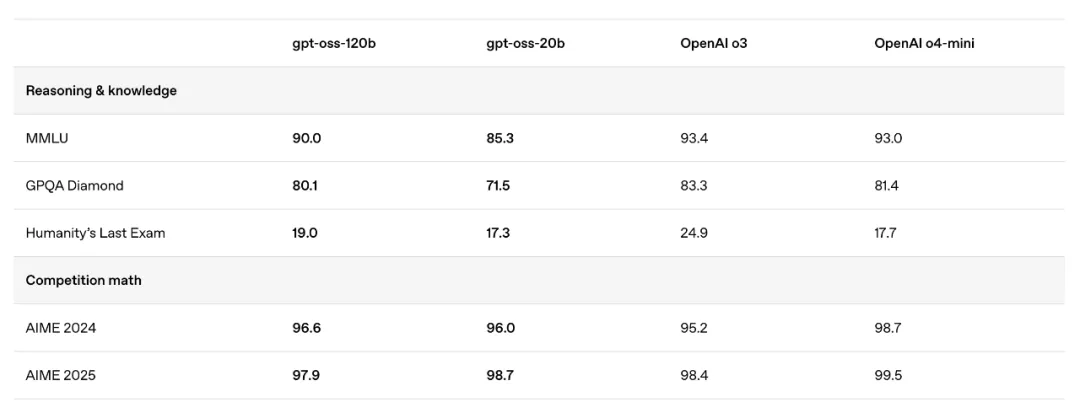
据官方称,在核心推理基准测试中,gpt-oss-120b 的性能表现与 OpenAI 的 o4 mini 不相上下(模型的实际性能表现,还是要等网友们一手测评)。且相比于 o4 mini 的定价(每百万输入 token 1.1 美元;每百万输出 token 4.4 美元),成本降低了至少 10 倍。
不惜冲击自家的产品线,也要推出这款开源模型,为什么?OpenAI 要做什么?
在 gpt-oss 发布后,推特、Reddit 等社交平台发酵了不少探讨。但 Ai2 研究科学家 Nathan Lambert 今天发布的一篇分析文章,可以说算是直指要点,他认为,OpenAI 开源动作的背后有许多潜在的战略考量,但都指向一点:OpenAI 对自身的价值定位有着更清晰的认识。
随着 ChatGPT 的周活跃用户即将突破十亿大关, OpenAI 可能意识到,模型本身已不再是其核心竞争力,真正的护城河在于庞大的用户基础和应用生态。
OpenAI 的目标用户并不是真正的开源 AI 社区,而是那些希望为自己的业务尝试「开源 AI 模型」的企业。
在文章中,Nathan Lambert 从「圈内人」的视角出发,分析了 OpenAI 的「伪开源」、OpenAI 开源给整个 AI 生态系统带来的影响、gpt-oss 模型的架构以及对中美开源模型竞赛的影响等。
原文章:https://www.interconnects.ai/p/gpt-oss-openai-validates-the-open?utm_campaign=email-half-post&r=1yej8&utm_source=substack&utm_medium=email
超 10000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。

最新、最值得关注的 AI 新品资讯;
不定期赠送热门新品的邀请码、会员码;
最精准的AI产品曝光渠道
OpenAI 今天发布了两款开源纯文本推理模型。这两款模型都是混合专家( MoE )架构,经过专门设计,能够在从消费级 GPU 到云服务器的各种硬件上高效运行。由于采用了 Apache 2.0 许可证,这些模型可以被自由地用于「蒸馏」成其他推理模型或部署到商业产品中,并且没有下游使用限制。
其中,较小的 gpt-oss-20B 模型拥有 36 亿活跃参数(总参数 210 亿),而较大尺寸的 gpt-oss-120B 模型拥有 51 亿的活跃参数。它们的架构选择,也延续了我们在其他顶尖开源模型中观察到的趋势。
这次发布之所以引人注目,是因为 OpenAI 作为 AI 领域的领导者,推出了一款足以冲击自家部分 API 产品的开源模型,这给开源模型的性能和策略带来了巨大变化。
01
OpenAI 开源并不是单纯的技术分享,
而是为构建应用生态铺路
模型的技术细节我们稍后讨论,但这次发布的重点在于,这是 OpenAI 自 GPT-2 以来首次发布开源语言模型,其意义重大。其中,较大尺寸的 120B 模型「在核心推理基准测试中,表现与 OpenAI o4 mini 已不相上下」,这对整个生态系统来说是一个重要时刻。
首先, OpenAI 推出了一款性能达到当前开源模型顶尖水平的模型,这说明他们的领导层在 2023 年对开源模型的种种担忧有些过度了。事实证明,开源模型的边际风险远没有许多人想的那么极端(至少对纯文本模型是这样,多模态的风险要大得多)。一旦 Meta 和中国等其他力量向 OpenAI 证明了其中的风险可控,发布新模型的道路也就此打开。
其次, OpenAI 此次披露的技术细节远超以往。尽管官方博文对模型内部的许多信息只是简单带过,但社区的技术爱好者们将通过动手实践,逐步揭开它的「面纱」。这其中既包括一些基础信息,比如我们首次看到了 OpenAI 推理模型未经处理的「思维链」( CoT );也包括一些更有趣的发现,比如该模型是如何被训练在「思维链」中调用工具的(类似于其 o3 模型)。此外,还有一些其他细节包括:研究者将能直接通过模型的原始权重,探索 OpenAI 的指令层级(这其中一部分在 API 中是无法触及的);一种名为「 harmony 」的新型提示词格式;与 API 中一致的低、中、高三档「推理能效」;以及一个重要的概念验证,展示了基础的社区标准架构究竟能达到何种性能高度。这些都有待 AI 社区进一步挖掘。
再者, OpenAI 对 API 市场也采取了更激进的竞争策略,不惜冲击自身产品线,推出了这样一款极具竞争力的开源模型。尽管开源模型的采用速度因测试、配置等环节,通常慢于 API ,但这款模型的各项准备工作都旨在尽可能地加速进行。任何与 OpenAI o4 mini 、 Claude Haiku 、 Gemini Flash 、 DeepSeek R1 等现有模型竞争的 API 产品,都将面临这款新模型的直接挑战。
目前, OpenAI 的 o4 mini 模型定价为每百万输入 token 1.1 美元,每百万输出 token 4.4 美元。相比之下,部署这款新的开源模型的成本预计将降低至少 10 倍。这一举动背后有许多潜在的战略考量,但都指向一点:OpenAI 对自身的价值定位有着更清晰的认识。
有趣的是,OpenAI 在这款模型中有意避开了一些功能,官方表示:「对于寻求多模态支持、内置工具以及与我们平台无缝集成的用户,通过我们 API 平台获取模型仍是最佳选择。」 舍弃这些功能,除了上述原因外,也与后文将讨论的一些「头疼问题」有关。
总结一下, OpenAI 如何掌控未来 AI 生态的蓝图已经愈发清晰了。在我看来,其中最有可能的几个原因是:
OpenAI 可能正在试图在 GPT-5 发布前,通过成本优势让所有同类 API 模型显得过时,他们希望借此占领高端市场。
随着 ChatGPT 的周活跃用户即将突破十亿大关, OpenAI 可能意识到,模型本身已不再是其核心竞争力,真正的护城河在于庞大的用户基础和应用生态。
当然,背后还有很多其他原因,比如我们接下来要提到的政治博弈。但 OpenAI 向来是一家目标明确的公司,他们的决策往往都服务于自身的核心利益。
02
「伪开源」,
目标是吸引希望快速部署「开源 AI」的企业
此外,这次发布中还有许多令人费解或意在言外之处,它们为我们理解 OpenAI 的战略提供了更多线索。不出所料, OpenAI 并没有公布训练数据、代码或技术报告。他们希望借助「开源」这个名号在企业市场中掀起波澜,但这无疑会对学术研究和真正的「开源」 AI 社区造成一些负面影响。未来的问题包括:
命名很糟糕——既尴尬又容易让人迷惑,但对于实现他的营销目标却很有效。对于长期关注开源 AI 的圈内人而言,大型科技公司模糊「开源」义已经是司空见惯了。我理解 OpenAI 为什么要这样做,但这种命名上的冲突恰恰说明,他们的目标用户并不是真正的开源 AI 社区,而是那些希望为自己的业务尝试「开源 AI 模型」的企业,而 OpenAI 抛出的这个目标,大到让企业难以忽视。
OpenAI 并没有发布基础模型。这一点业内早有预料,但对研究人员而言却是至关重要的。这两款稀疏、低数值精度的 MoE 模型,对研究人员来说,用起来并不容易。对于研究人员和技术爱好者,最佳的研究工具是参数量在 10 亿到 70 亿之间的稠密型基础模型。这类模型才是开放社区中生命力更强的「成果」,现在大家基本用的都是 Qwen 系列模型。
03
模型架构向 DeepSeek 的稀疏 MoE 看齐
在讨论未知数之前,我必须先谈谈模型的架构。这些模型再次印证了整个行业在模型设计上的共同趋势。近期顶尖的开源模型,几乎都是受 DeepSeek 架构启发的稀疏 MoE 模型。例如, DeepSeek V3 拥有 370 亿活跃参数和 6710 亿总参数,而 Kimi K2 则有 320 亿活跃参数和 1 万亿总参数。而 gpt-oss 有 50 亿活跃参数和 1210 亿总参数,其稀疏度也正好处于正常的范围内。可以说, MoE 架构的稀疏性设计目前完全占据主导地位。虽然规模较小的 gpt-oss 模型比 Qwen 的小模型(30 亿活跃,300 亿总参数)稀疏度略低,但预计,这些模型的稀疏化程度将持续提高。
以下是一些需要进一步测试才能明确其影响的方面。
模型在发布时就已经进行了量化。官方称其「原生支持 MXFP4 量化」。目前尚不清楚具体会影响哪些用户,但这可能意味着拥有最新硬件的用户将受益最多,同时也可能在不同的 Torch/Cuda 版本间引发兼容性问题,甚至可能导致其行为与训练版本相比出现一些异常。
当然,这也可能是一个优势。由于大模型被量化到 4 比特精度,它将能够在 80GB 显存的 GPU (如 NVIDIA 的 A/H100 系列)上运行,这取决于实际性能表现。
官方采取了安全措施来改变模型的可微调程度。 OpenAI 正在或即将发布一篇研究论文,介绍其研发的新方法,旨在防止用户通过微调来「绕开」已发布指令模型的安全设置。这是开源模型发布中一个长期存在的棘手问题。核心疑问在于: OpenAI 此次发布的模型是否还具备良好的可微调性?官方在其博文中声称可以,但最终的答案需要社区来检验。或者说,「能够轻易去除安全限制」本身,算不算是「易用模型」的一个特性呢?
例如, Google 的 Gemma 模型由于采用了不同的注意力机制,并且是蒸馏而来,参数空间也不同,因此一直以来都较难微调。目前主流的开源微调工具链仍然是为 Llama 和 Qwen 优化的,要改变这种局面需要很长时间。
未来,许多人会将「我们让这个模型无法被‘反审查’」的声明视为一种挑战。关注「越狱」研究社区的动态将会非常有趣,毕竟,对可修改模型的需求市场是真实存在的。
04
开源模型的工具使用生态仍很混乱,
评分高的模型不一定易用
模型经过训练可以使用工具,但开源模型的工具使用生态目前仍相当混乱。我在设计一款具备原生 o3 风格工具调用能力的 OLMo 模型时,最担心的问题之一,就是如何确保用户在推理时能够像训练时一样无缝地使用工具。一位早期测试者曾提到,模型有时会「幻觉」出训练时使用的工具调用(这和 o3 模型正式发布时遇到的问题有些相似)。我不认为这是个无法解决的问题,但它可能会拖慢模型的普及速度。当然,这也可能为社区提供一个逆向工程 OpenAI 训练工具集的机会。
我们需要在开放的硬件设施上重新进行基准测试。 OpenAI 在这次发布中,将模型整合到了各大平台,做得相当不错。但我们需要社区来验证,其官方公布的评估分数是否可以被轻松复现。封闭式实验室的评估方法日益为满足内部需求而「定制化」,这本身无可厚非,但在发布开源模型时,这种差异会增加社区使用的摩擦成本。
我想在此声明,这篇文章并不是一篇严格意义上的模型性能评测,而是旨在分析 OpenAI 此举的战略意义(以及它为我们其他人创造的机会)。好的模型不一定易用。有些模型评测分数很高,也确实好用,比如 Qwen ;有些则分数很高,却很快被人遗忘。但无论分数如何,我预计这会是一款实用的模型。
总的来说,对于 OpenAI 时隔多年的首次开源尝试,表现非常出色,他们确实听取了社区的反馈。但想真正赢得开源社区,特别是研究人员的好感,未来的路在于承担更多风险,发布更易于修改(甚至更具启发性)的模型,例如公布这些模型的检查点所对应的基础模型。
05
中美的开源模型仍存在不确定性,
小模型将有很大的机会
美国的实验室在开源模型方面曾一度陷入困境,任何向正确方向迈出的一步都至关重要。
所以, OpenAI 已经是新的开源领袖了吗?还用用担心来自中国的风险吗?我们还需要 Llama 模型吗?
OpenAI 作为 AI 领域的领头公司,回归开源,对于整个开放生态,特别是西方及其盟友而言,是意义非凡的一步。这股势头可能成为一个转折点,扭转此前开源模型在应用和影响力上相对于中国的落后局面。
开放生态的发展有快有慢。由于 Qwen 模型发布频繁、易于获取,许多工作流和技术专长已围绕其建立。当这些人下次需要更新换代时,部分会尝试 OpenAI 的新模型,但这绝不意味着所有人都会立刻转投新阵营。
在我看来, OpenAI 此次抛出的重磅模型,改变了开源模型规模发展的趋势。美国及其盟友持续落后的局面(这曾是 2025 年的主旋律)的这种情况,将不会再加剧了。但如果想在未来数月而不是几年的时间内,为所有应用场景提供有竞争力的开源模型,我们必须乘胜追击。
开源模型的激励机制充满不确定性。一些我认识的优秀中国分析师都认为,中国方面已意识到,发布开源模型是一项成功的国家战略,并正加倍投入。这是一个非常合理的看法。但反过来看,如果我们认为美国生态系统过度依赖 Meta 的 Llama 或如今的 GPT OSS 是一个弱点,那么同样的问题也可能发生在 Qwen 身上。如果阿里巴巴认为, Qwen 的持续优秀发布不再符合其自身利益,会发生什么呢?
在这种情况下,参数量在 10 亿到 700 亿之间的小模型系列将有很大的机会。但在更大规模的模型上,来自中国的竞争非常激烈,例如 DeepSeek V3/R1 、智谱的 GLM 4.5 、 Kimi K2 等大型 MoE 模型。此外,中国还有更多接近这一性能水平的模型,如 MiniMax 或腾讯的模型。
所有这些公司其实都不稳定,但数量多了就能形成标准做法。发布强大、大型的开源模型,如今已是中国的行业标准。而美国公司则再次回到了那个建立标准的微妙时期,它们面临着巨大的法律风险,比如面临版权等领域的众多诉讼,一旦模型发布便难以撤回。
开放生态的这两大阵营,正处于截然不同的发展阶段,需要采取截然不同的行动。在某种程度上,我们之所以在此时发起「The ATOM Project」*,是因为我们判断,西方在 AI 开源领域的贡献正处于一个关键的低谷期。我们希望这已经是最低点,因此现在也正是扭转局势、触底反弹的最佳时机。
注:「The ATOM Project」:https://www.atomproject.ai/
OpenAI 的此次发布是向正确方向迈出的一步,但整体局势依然不稳定。从政府的 AI 行动计划到风险投资家和学者,许多人都在为创建开源模型摇旗呐喊。但他们所有人的共同点是:这并非是他们的首要任务。而 The ATOM Project 的目标,正是为像我这样,愿意将此作为首要目标的人们提供一个平台。
这便是为何我们需要持续扶持那些愿意将自家最好的模型投入开源领域的新生力量。这正是 Llama 早年成功的秘诀,也将是 ATOM 未来成果的决定性因素。只有那些从第一性原理出发,为可修改、可解释、可扩展而设计的模型,才能催生下一个 AI 研究的黄金十年。而这恰恰需要基础模型、训练细节、合适的尺寸以及其他许多在近期开源模型(包括 OpenAI 的这次发布)中所缺失的小细节。

御三家打起来了:OpenAI 开源、谷歌发布可交互的世界模型、Claude 4.1 成了编程新旗舰
转载原创文章请添加微信:founderparker
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢