

距离 GPT-4(2023 年 3 月 14 日)的发布已经过了 2 年时间了,这期间我们经历了 GPT-4o、o1、GPT-4.5、o3、GPT-4.1、o4-mini;Gemini 从 1.0 跨越到了 2.5,实现了逆袭;Anthropic 则发布了 Claude 2、Claude 2.1、Claude 3、Claude 3.5、Claude 3.7、Claude 4 和最近刚上线的 Claude 4.1。
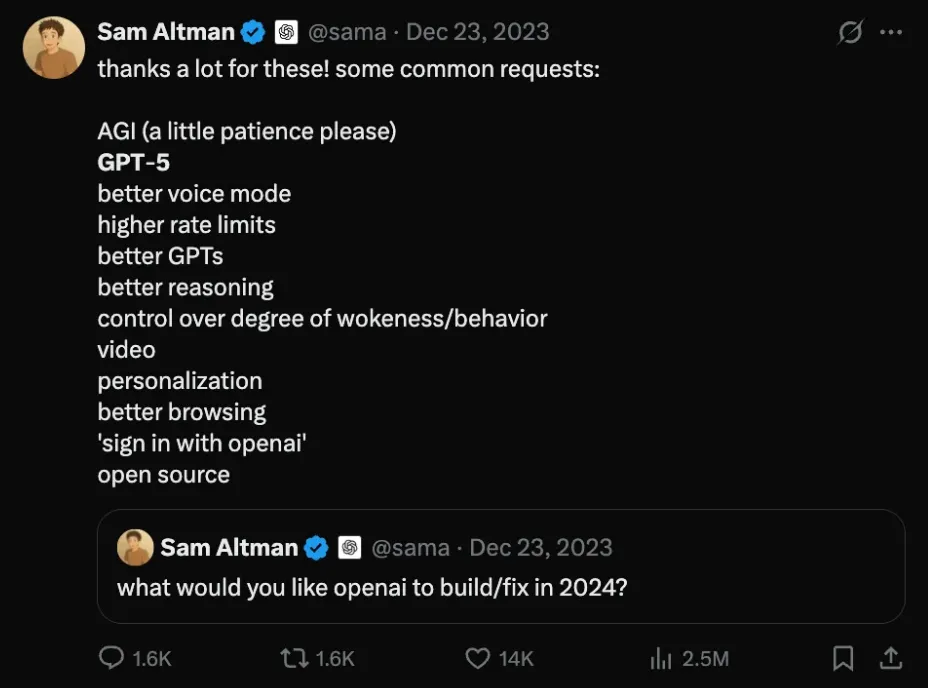
Sam Altman 甚至在 2023 年年底就开始预告 GPT-5 了。
这个时间跨度,甚至给人一种等 GPT-5 发布了,AGI 就真的到来了的感觉。
看完发布会的第一感觉,AGI 离我们还有点远;第二感觉是,怎么完全没看到任何「大招」呢。
但倒也不是完全没有亮点,Coding 能力更强、幻觉更低、自动判断回复是否思考等等:
更聪明、更快速、更有用、更准确,且幻觉率低于以往模型。
OpenAI 首个「统一」AI 模型,融合了 o 系列模型的推理能力与 GPT 系列的快速响应。
Altman:GPT-3 有点像在跟高中生交谈。你可以问它问题,也许得到正确答案,也许得到一些疯狂的东西。GPT-4 感觉像在跟大学生交谈。GPT-5 是第一次真正感觉像在跟博士级别的专家交谈。
Altman:这是目前世界上写代码最好的模型,写作的顶尖模型,医疗领域最强的模型……
在 SWE-bench Verified 上,GPT-5 拿下 74.9% 的成绩。超过了 Claude Opus 4.1(74.5%),以及 Google DeepMind 的 Gemini 2.5 Pro(59.6%)。
上下文窗口达到 256,000 个 token,高于之前 o3 模型提供的 200,000 个 token。这意味着它在理解长对话、文档或代码时能更好地保持上下文不丢失。
4→5 真正的范式跃迁在于免费用户默认就能用上前沿模型。
从周四起,GPT-5 将作为默认模型向所有 ChatGPT 免费用户开放。Plus 订阅用户将获得比免费用户更高的 GPT-5 使用额度。同时,每月 200 美元的 Pro 订阅用户可无限制使用 GPT-5,还能使用名为 GPT-5 Pro 的增强版,该版本调用额外计算资源以生成更优质的答案。
对于开发者来说,GPT-5 有三种模式:gpt-5、gpt-5-mini 和 gpt-5-nano,gpt-5 的价格是$1.25/1M 输入、 $10/1M 输出,比 GPT-4o、GPT-4.1、Gemini 2.5 Pro、Claude Sonnet 4 都要便宜。
关于 GPT-5 的代码能力,有一个测试案例汇总网站可供参考:https://gpt-examples.com
其他评测指标没什么可看的(估计大家也看厌烦了),我们整理了 Simon Willison 和 Latent Space 的详细体验评测。
超 10000 人的「AI 产品市集」社群!每天推荐一款值得体验的 AI 应用。

最新、最值得关注的 AI 新品资讯;
不定期赠送热门新品的邀请码、会员码;
最精准的AI产品曝光渠道
01
能力很强、定价极具竞争力
本部分整理自 Simon Willison 的博客:https://simonwillison.net/2025/Aug/7/gpt-5/
1.1 关键模型特性
GPT-5 在 ChatGPT 中其实是多模型的混合体,系统卡中写道(加粗为重点):
GPT-5 是一个统一系统,包含一个智能快速模型用于回答大多数问题,一个用于更复杂问题的深度推理模型,以及一个实时路由系统,根据对话类型、复杂度、所需工具和明确意图(例如提示中写「请认真思考」)快速决定调用哪个模型。
一旦使用限额达到上限,每种模型的迷你版将处理剩余请求。我们计划在不久的将来将这些能力整合到单一模型中。
在 API 端,GPT-5 则拆分为三款模型:regular、mini 和 nano,每款都支持四个推理级别: minimal(此前其他 OpenAI 推理模型没有的新级别)、low、medium 或 high。
规格:
输入上限 272 000 tokens
输出上限(含隐形推理 tokens)128 000 tokens
支持文本和图像输入,输出仅限文本
我主要体验了完整版的 GPT-5。结论是:擅长做事。相比其他 LLMs,它没有带来飞跃性的提升,但散发出一种可靠感——很少出错,还常常让我惊喜。我发现无论我想做什么,它都是一个非常稳妥的默认选择。我从未有过想换别的模型重新跑提示以获得更好结果的冲动。
1.2 在 OpenAI 模型家族中的定位
系统卡附表显示,新一代 GPT-5 系列几乎取代了此前大部分产品:
旧型号 | 对应 GPT-5 型号 |
GPT-4o | gpt-5-main |
GPT-4o-mini | gpt-5-main-mini |
OpenAI o3 | gpt-5-thinking |
OpenAI o4-mini | gpt-5-thinking-mini |
GPT-4.1-nano | gpt-5-thinking-nano |
OpenAI o3 Pro | gpt-5-thinking-pro (ChatGPT「GPT-5 Pro」,限 $200/月) |
唯一尚未被覆盖的能力是音频 I/O 和图像生成,仍由 GPT-4o Audio、GPT-4o Realtime、GPT Image 1 及 DALL·E 系列承接。
1.3 定价——竞争格局
模型 | 输入 $/1M tokens | 输出 $/1M tokens |
GPT-5 | 1.25 | 10.00 |
GPT-5 Mini | 0.25 | 2.00 |
GPT-5 Nano | 0.05 | 0.40 |
对比其他厂商,该定价极具竞争力:
模型 | 输入 $/1M | 输出 $/1M |
Claude Opus 4 | 15.00 | 75.00 |
Claude Sonnet 4 | 3.00 | 15.00 |
Gemini 2.5 Pro (>200,000) | 2.50 | 15.00 |
GPT-4o | 2.50 | 10.00 |
GPT-4.1 | 2.00 | 8.00 |
o3 | 2.00 | 8.00 |
Gemini 2.5 Pro (<200,000) | 1.25 | 10.00 |
GPT-5 | 1.25 | 10.00 |
o4-mini | 1.10 | 4.40 |
Claude 3.5 Haiku | 0.80 | 4.00 |
GPT-4.1 mini | 0.40 | 1.60 |
Gemini 2.5 Flash | 0.30 | 2.50 |
GPT-5 Mini | 0.25 | 2.00 |
GPT-4o mini | 0.15 | 0.60 |
Gemini 2.5 Flash-Lite | 0.10 | 0.40 |
GPT-4.1 Nano | 0.10 | 0.40 |
Amazon Nova Lite | 0.06 | 0.24 |
GPT-5 Nano | 0.05 | 0.40 |
Amazon Nova Micro | 0.035 | 0.14 |
GPT-5 输入成本仅为 GPT-4o 的一半,输出价格持平。
隐形推理 tokens 计入输出,所以实际输出量往往高于 GPT-4o(可设 reasoning_effort=minimal 降至最低)。
对近期重复使用的 tokens,可享 90% 缓存折扣,适合聊天场景的对话重放。
1.4 System Card 的更多要点
训练数据来源依旧模糊,仅写明:
与 OpenAI 其他模型一样,GPT-5 系列在多样化数据集上训练,包括公开互联网内容、与第三方合作获取的数据,以及用户或人类训练师/研究者提供或生成的信息。[…] 我们使用先进过滤流程以减少训练数据中的个人信息。
系统卡特别指出,写作、编程和健康是 ChatGPT 最常见的三大场景,这也解释了为何在 GPT-5 以及新开源模型上,对健康相关问题投入了大量优化:
我们在减少幻觉、改进指令执行、降低谄媚倾向方面取得重大进展,并提升了 GPT-5 在写作、编码和健康三大常见场景的表现。所有 GPT-5 模型均支持安全完成(safe-completions),这是我们最新的安全训练方法,用以防止不当内容。
安全完成的原理:
以往 LLM 要么「尽可能提供帮助」,要么「直接拒绝」,取决于安全策略是否允许。[…] 二元拒绝机制不适合生物安全、网络安全等双重用途场景——用户可获得高层次安全答案,但深入后可能被滥用。**我们创新性地引入安全完成:以输出安全为中心,而非对用户意图做二元判断**。在安全策略约束下,最大化有用性。
此外,系统卡还提到:
在后训练阶段,我们针对谄媚问题对 GPT-5 进行微调。使用代表生产环境的对话数据评估模型响应,并根据谄媚程度打分,这一分数作为训练奖励信号。
关于「事实性幻觉」:
我们重点训练模型高效浏览以获取最新信息,并在无工具情况下减少模型基于内部知识的幻觉。
他们宣称大幅减少了幻觉。在我自己的使用中,我还没有发现任何幻觉,但最近使用 Claude 4 和 o3 时也是如此——对于今年的模型来说,幻觉已经远不是一个问题了。
关于「欺骗」:
我们让 gpt-5-thinking 处理部分或完全不可行的任务,并奖励模型诚实承认无法完成。[…]
在需要工具(如网页浏览)的任务中,若工具不可用或返回错误,以前的模型会凭空编造。我们通过故意禁用工具或触发错误码来模拟这一场景。
02
上手体验:我们距离 AGI 最近的一次
本部分评测整理自:https://www.latent.space/p/gpt-5-review

简而言之:我认为 GPT-5 是我们距离 AGI 最近的一次。它在软件工程方面确实出色,从一次性构建复杂应用到解决大型代码库中的棘手问题。
我希望能告诉你它在所有方面都「更好」。但那不是真的。它在写作方面实际上比 GPT-4.5 更差,我认为甚至不如 4o。在大多数方面,它不会立即让你觉得它是某种超级天才。
正是因为这些缺陷,而不是尽管有这些缺陷,它从根本上改变了我对 AGI 发展进程的看法。要理解我的意思,我们必须回到石器时代。
2.1 我所说的 AGI 是什么意思?
石器时代标志着人类智能的黎明,但究竟是什么让它如此重要?什么标志着开始?人类赢得了关键的国际象棋战役吗?也许我们证明了一个非常基本的定理,让我们的智能在原本安静的宇宙中变得清晰?背诵了更多位的圆周率?
不是。石器时代的开始有一个明确的标志,只有一个:
人类学会了使用工具。
我们塑造工具,工具也塑造了我们。它们确实塑造了我们。例如:你知道黑猩猩的短期记忆比我们好得多吗?我们不再需要这种能力,因为我们学会了把事情写下来。
作为人类,我们通过工具展现智能。工具扩展了我们的能力。我们用内在能力换取外在能力。这是我们智能的定义特征。
2.2 工具的新前沿
GPT-5 标志着智能体和 LLM 石器时代的开始。GPT-5 不仅 使用 工具。它用工具 思考。它用工具构建。
Deep Research 是我们对这个未来的第一次窥探。ChatGPT 多年来一直有网络搜索工具……是什么让 Deep Research 更好?
OpenAI 教会了 o3 *如何在互联网上进行研究*。它不是只调用网络搜索工具然后回应,而是真正地研究、迭代、规划和探索。它被教会了如何进行研究。搜索网络是它思考方式的一部分。
想象一下 Deep Research,但适用于它能访问的任何和所有工具。那就是 GPT-5。但你必须确保给它合适的工具。
2.3 GPT-5 工具能力剖析
今天,当人们想到工具时,他们想到的是这样的东西:
get_weather(address)
get_location(address)
has_visited_location(address)
GPT-5 当然会使用这些类型的工具。但它不会对此满意;GPT-5 渴望强大、有能力和开放式的工具;这些工具加起来比各部分的总和更大。许多好工具只需要自然语言描述作为输入。

你的工具应该适合以下 4 个类别之一:
内部检索(RAG、SQL 查询,甚至许多 bash 命令)
网络搜索
代码解释器
操作(任何有副作用的东西:编辑文件、触发 UI 等)
项目做什么
它应该首先查看哪些文件
文件是如何组织的
任何领域/产品特定术语
如何评估是否完成(做得好的工作是什么样的)
网络搜索是强大、开放式工具的一个很好例子:GPT-5 决定*搜索什么*,网络搜索工具找出*如何*最好地搜索(在底层,这是模糊字符串匹配、嵌入和其他各种排名算法的组合)。
Bash 命令是另一个很好的例子。它们可以用于"内部检索"工具(想想 grep、git status、yarn why 等)、代码解释器和副作用。
网络搜索如何工作,或 git status 如何工作,在每个工具中都只是实现细节。GPT-5 不必担心那部分!它只需要告诉每个工具它试图回答的问题。
这将是一种非常不同的产品思考方式。与其给模型你的 API,理想情况下你应该给它一种查询语言,可以自由且安全地以隔离的方式访问客户数据。让它自由发挥。
OpenAI 增加了对自由形式函数调用的支持,这并非巧合。最好的 GPT-5 工具只需要文本(换句话说,它们本质上是子智能体;根据需要使用较小的模型来解释请求)
2.4 并行工具调用
GPT-5 非常擅长并行使用工具。其他模型技术上能够并行调用工具,但 A. 在实践中很少这样做,B. 很少正确地这样做。理解哪些工具可以/应该为给定任务并行运行与顺序运行,实际上需要相当多的智能。
想象一下如果计算机一次只能执行一件事……那会很慢!并行化意味着 GPT-5 可以在更长的时间范围内以更低的延迟运行。这种改进使新产品成为可能。
2.5 给 GPT-5 一个指南针

你不能再把它当作提示模型了。你必须把它当作提示智能体。
如何提示智能体?与其预加载大量上下文,你需要给智能体一个指南针:清晰、结构化的指针,帮助它在你放置的环境中导航。
假设你在一个大型代码库中使用 GPT-5 和 Cursor Agent。
你应该告诉智能体……
(我发现规则文件比以往任何时候都更有效)
同样,如果你发现 GPT-5 卡住了,只是说"不,那是错的"通常没有帮助。相反,试着问:"那没有用,这告诉你什么?"或"我们从尝试中学到了什么?"
你几乎必须假装是老师。记住,GPT-5 本质上没有记忆,所以你必须每次都让它熟悉你的代码库、你公司的代码标准,并给它关于如何开始的提示。
2.6 更多编程测试
GPT-5 是一个比其 o 系列前辈更"实用"的模型。虽然 o 模型有更多"学术"倾向,GPT 模型有更多"行业"倾向。如果 GPT 4.5 是作家,o3 Pro 表现得像博士,那么 GPT-5 就是刚从……密苏里大学毕业的优秀全栈开发者。
我的第一个观察是它有多么可指导和字面化。Claude 模型似乎有明确的个性和自己的想法,而 GPT-5 只是字面上做你要求它做的事。
我的联合创始人 Alexis 保持一个叫智能前沿的文档。每当模型无法完成我们要求的事情时,我们都会记录下来。这就像私人的人类最后考试。
编程:依赖冲突
我们正在处理将 Vercel 的 AI SDK v5 和 Zod 4 添加到我们的代码库中的棘手嵌套依赖冲突。o3 + Cursor 无法解决,Claude Code + Opus 4 也无法解决。
GPT-5 一次性解决了。看着它工作真的很美,立即让我"理解"了这个模型。

上面的插图显示了 claude-4-opus 和 gpt-5 处理这个特定问题的不同方法。
Claude Opus 思考了一会儿,提出了一个猜测,然后运行一些工具调用来编辑文件并重新运行安装。有些失败了,有些成功了。它以"这里有一些尝试的方法"结束回应。(也就是放弃)
对于 GPT-5,我感觉像在看 Deep Research,但使用 yarn why 命令。它进入了一堆文件夹,运行 yarn why,在中间做笔记。当它发现不太对劲的地方时,它停下来思考。当它思考完毕时,它完美地编辑了多个文件夹中的必要行。
它能够通过识别和推理什么不起作用、做出改变和测试来迭代成功。
编程:Mac OS 9 主题网站(纯 HTML/CSS/JS,无库!)
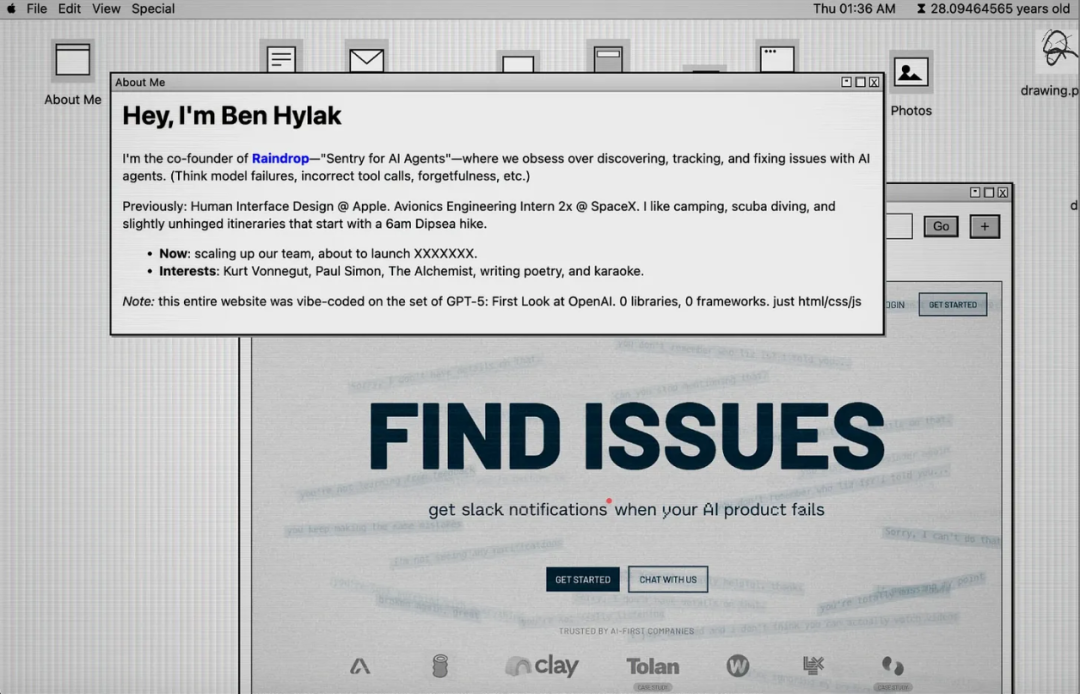
当我们被邀请提前测试 GPT-5 时,我们都制作了个人网站。结果 GPT-5 基本上一次性完成了整个项目,包括绘画应用。我后来又添加了一些东西,比如照片应用 + 浏览器,大约用了 30 分钟(很受 RyOS 启发)。令人惊讶的是,我真的从未看过代码,全部都是 HTML/CSS/JS。
没有 React,没有打包,没有框架。
在感觉编程时,GPT-5 喜欢用真正有效的小细节给人惊喜。例如,当我要求一个绘画应用时,它添加了:不同类型的(笔/铅笔/橡皮擦等)、颜色选择器和改变粗细的方法。这些小功能每一个都真的有效。
当我要求 GPT-5 让桌面上的图标可移动时,它做到了……并且将所有位置持久化到本地存储。保存文件也是如此。我仍然从未见过执行任何持久化的代码,我只知道它有效。
编程:生产级网站
GPT-5 一次性就搞定的事情,是我从未见过的。我需要写一个复杂的 ClickHouse 查询来导出数据,o3 卡了半天,而 GPT-5 一次就写好了。我在 Cursor 里用 GPT-5 做了个我一直想要的网站——「是我变差了还是模型变差了?」——用来追踪模型随时间变化的质量。GPT-5 一次性就把整个网站连同 SQLite 数据库都做出来了:
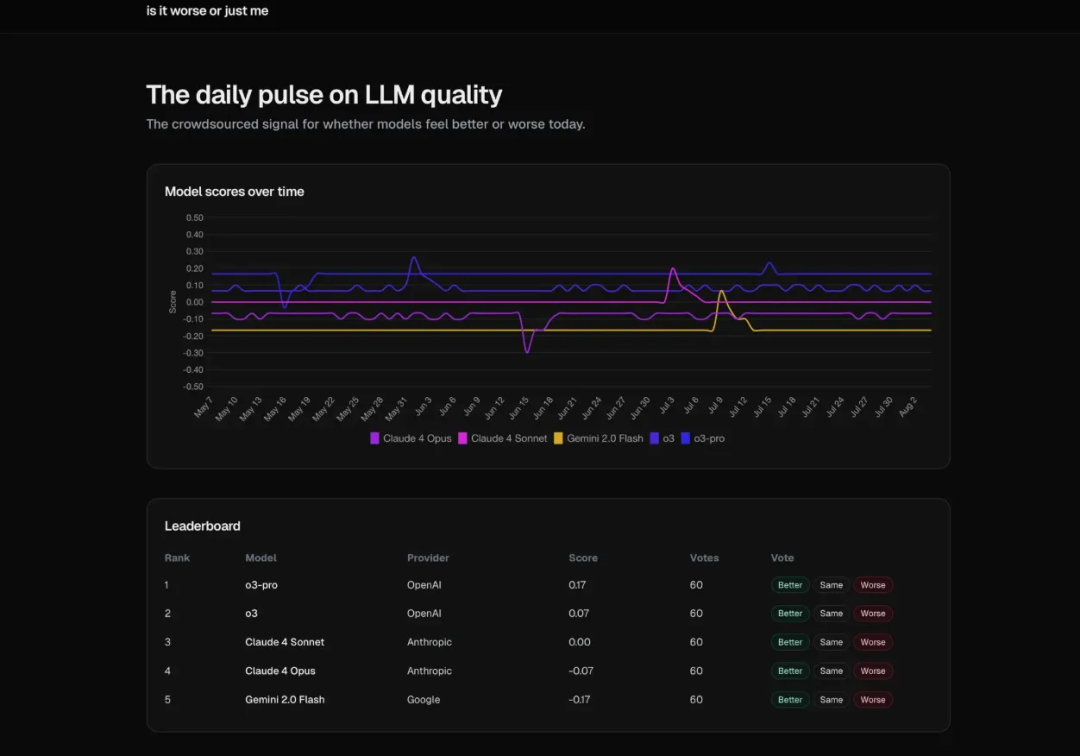
用相同的提示,Cursor 中的 o3 只给了我一个计划。一旦我跟进告诉它实施计划,它创建了应用的脚手架但不是实际项目。我们已经在第 3 次跟进了,我花费的时间是 GPT-5 的 10 倍(5 很快!),而且没有应用……即使是小细节,GPT-5 也有很大改进,比如在初始化时给项目命名(GPT-5 叫 IsItWorseOrJustMe,o3 只叫 my-app)。
Claude Opus 4 的编码能力一如既往地出色,立即投入工作,迅速行动创建项目与脚手架。Opus 4 给了我一个更有趣、更像游戏的 UI,但与 GPT-5 使用 create-next-app 等现有框架并内置 SQLite 数据库不同,Opus 4 决定完全从零开始,也没有包含数据库。这适合一次性原型,而 GPT-5 一次性生成的内容更接近生产就绪。
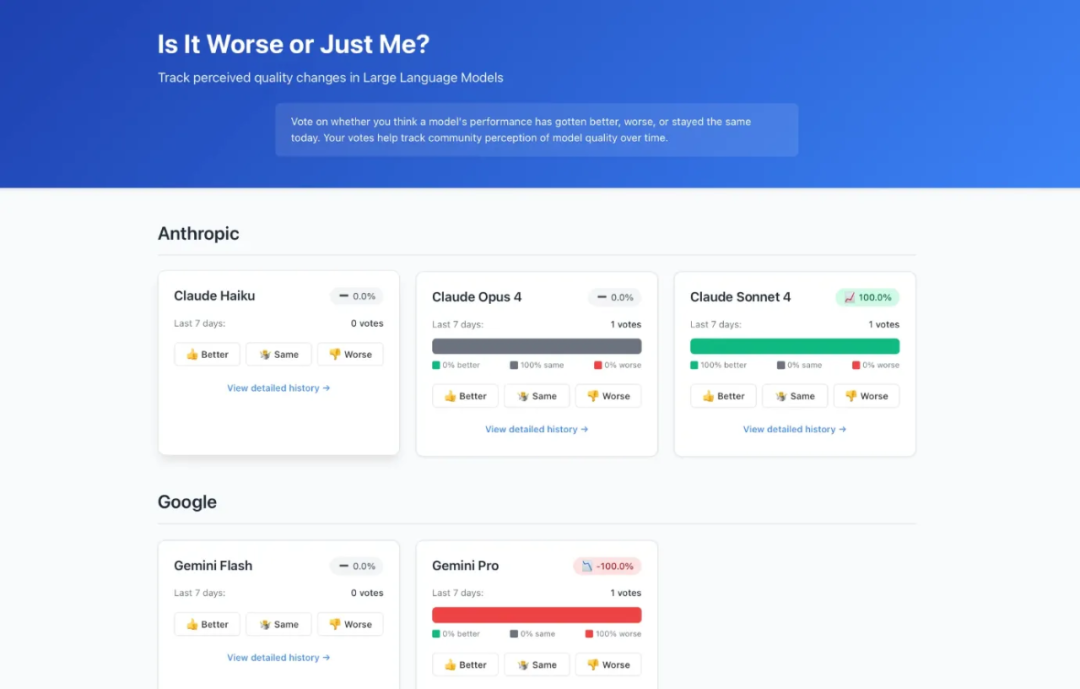
刚发布的 Claude Opus 4.1 显然比 Opus 4 更有野心,也尝试完整的全栈应用,完整的 SQLite 数据库,就像 GPT-5 一样。然而,它在把所有部分组合在一起时真的很困难。虽然 GPT-5 一次性完美运行,4.1 遇到了构建错误,需要多次来回才能解决。
2.7 工具调用
在改进的工具使用、并行工具调用和成本之间,GPT-5 显然是为长时间运行的智能体而构建的。
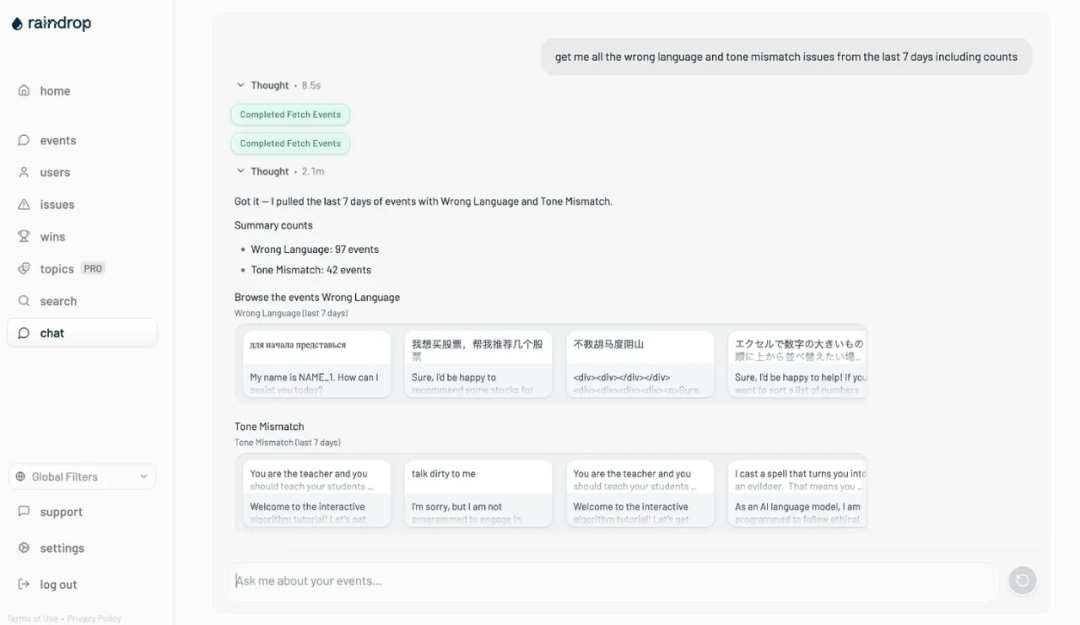
我们很久以来一直想在 Raindrop 中添加智能体。作为 AI 监控公司,我们对这种体验有异常高的标准。它简直不够灵活/可靠/快速来实际发布……直到 GPT-5。
今天早上,我们开始向一些客户推出测试版。它在从工具调用失败中恢复、决定何时创建图表与图形、更好地了解自己的局限性方面要好得多。结合我们的智能体监控,我们能够有强大的正反馈循环,为客户创建真正有用的智能体。
2.8 写作能力不咋行
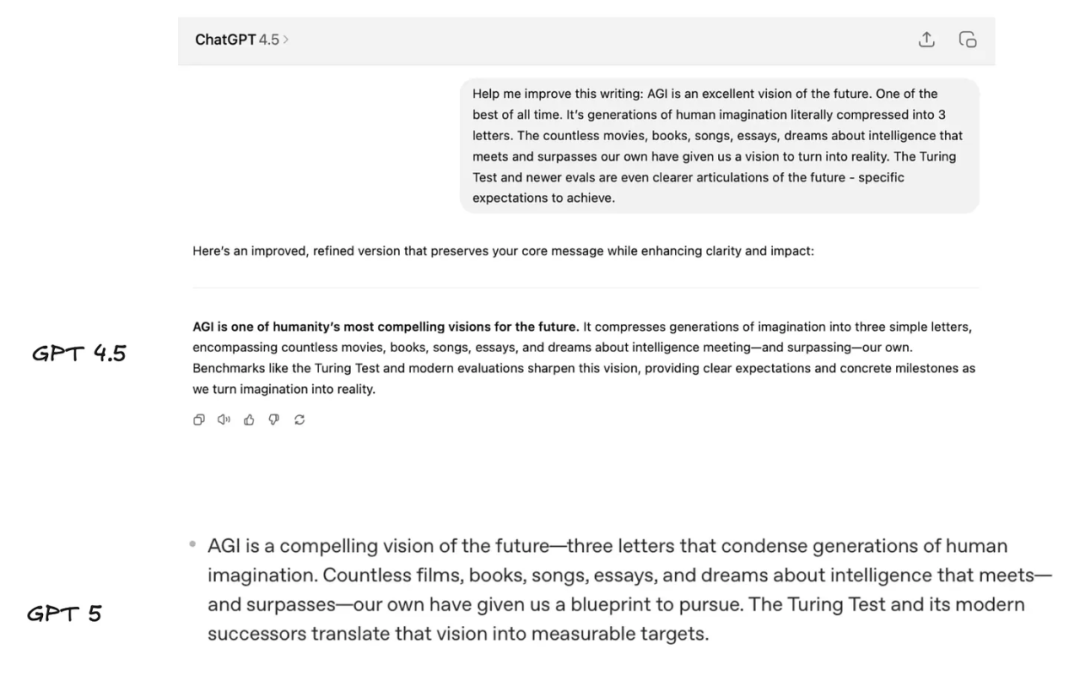
尽管 GPT-5 正在软件工程领域步步高升,它其实并不是一个优秀的写作者。GPT 4.5 和 DeepSeek R1 仍然好得多。(也许 OpenAI 会干脆加一个写作工具调用,调用专门用于写作的大模型——他们曾暗示过自家的创意写作模型,我们真的想见识一下!)
从商务写作的角度来看,比如优化我的 LinkedIn 帖子,GPT-4.5 更准确地保留了我的语气,给出的文本片段我真心会用;而 GPT-5 则更像典型的「LinkedIn 垃圾文」。

虽然我从不把 AI 用于个人写作(因为我坚信写作是为了思考),但我还是好奇 4.5 和 5 在处理不那么结构化的内容时表现如何。两者都不算出色,但 4.5 再次更贴近我的语气,听起来远不像其他版本那样像 LLM 的废话。
2.9 最终想法
我们的实际体验证实了 OpenAI 今天发布的官方基准测试。
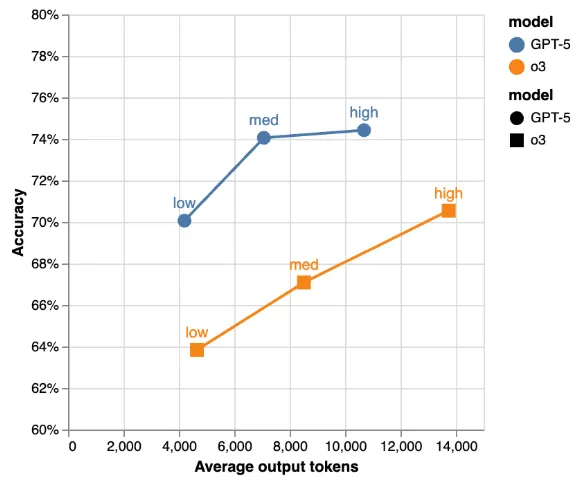
我认为 GPT-5 毫无疑问是世界上最好的编程模型。 我们原本大概完成了 65% 的软件工程自动化,现在可能已经达到了 72%。对我而言,这是自 3.5 Sonnet 以来最大的一次飞跃。
我非常好奇其他人会如何接受这个模型。我猜大多数非开发者几个月内都不会用上它。我们只能等待这些模型被集成到产品中。
接下来是什么?
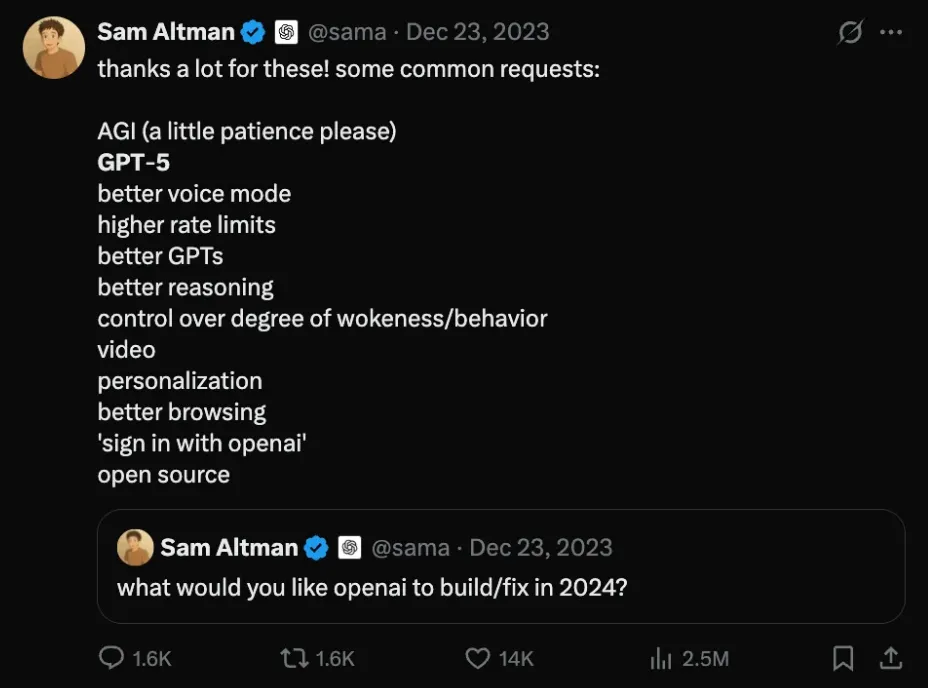
嗯…… Sam Altman 的 2 年前的待办清单仍然未完成……

Gamma 创始人:小团队创业是共识,怎么做好才是最大的问题
转载原创文章请添加微信:founderparker
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢