
PK-Sim学习笔记
本文章对当前AI预测ADME参数进行了详细的总结,主要涵盖以下几个方面的内容:
pKa的预测
logD的预测
溶解度的预测
渗透性的预测
代谢稳定性的预测
蛋白结合率的预测
这几个方面是PBPK建模中非常重要的理化参数,也是目前大家追求的AI-PBPK方向的一个着手点,通过AI来预测理化参数,进而建立PBPK模型;也可生成PBPK模型,通过模型生成数据,利用数据再和AI结合,从理化参数预测PK数据。
文章很长,有兴趣的朋友可以去阅读原文:https://www.sciencedirect.com/science/article/pii/S1359644625001357?via%3Dihub#ab005。尽量简短来进行分享,通过几个问题梳理整篇文章:
AI能不能帮助做ADME决策
近几年,人工智能和机器学习在药物发现领域被吹得火热,尤其是在 ADME预测上。但很多项目负责人会问:“模型结果能直接改变我的决策吗?”

图1. ADME QSAR模型在实际药物发现过程中的作用
药物发现不同阶段,对 ADME 的需求差异巨大。早期在于发现,后期在于精准,所以一个模型不可能从头用到尾。目前对于AI在医药领域的应用也从两方面出发,一个是需求驱动,一个是数据驱动。前者是先确定项目目标,然后去获取针对性的实验数据,根据数据选择最合适的建模方法;后者是先有一大堆数据,想办法建模,再看这个模型能不能用在项目上。
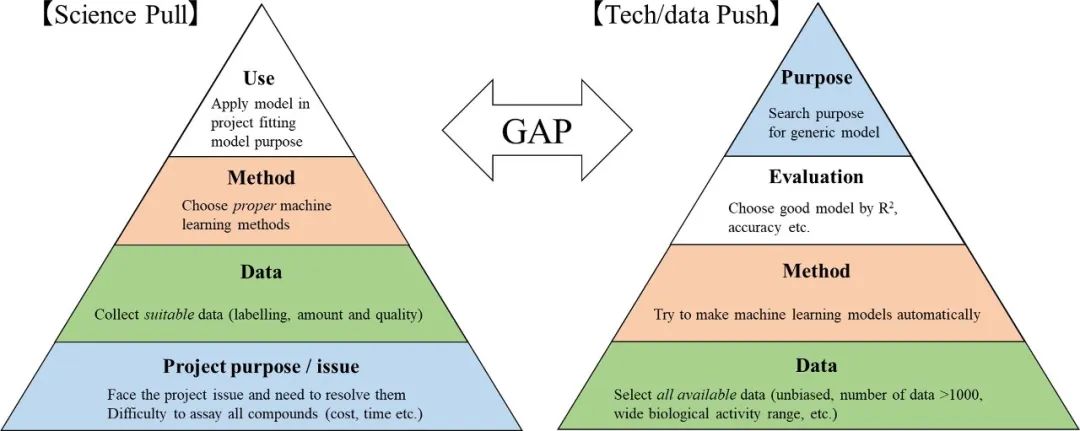
图2. 药物发现中模型构建的驱动因素
所以就会出现有好的模型,可能没有用,也可能出现,有好的数据,没人会建模。在临床前的应用中,很多失败的案例在于“搞AI的”和“搞DMPK的”语言不通,只有做到使得AI从项目需求出发,与实验紧密结合,才能辅助决策。
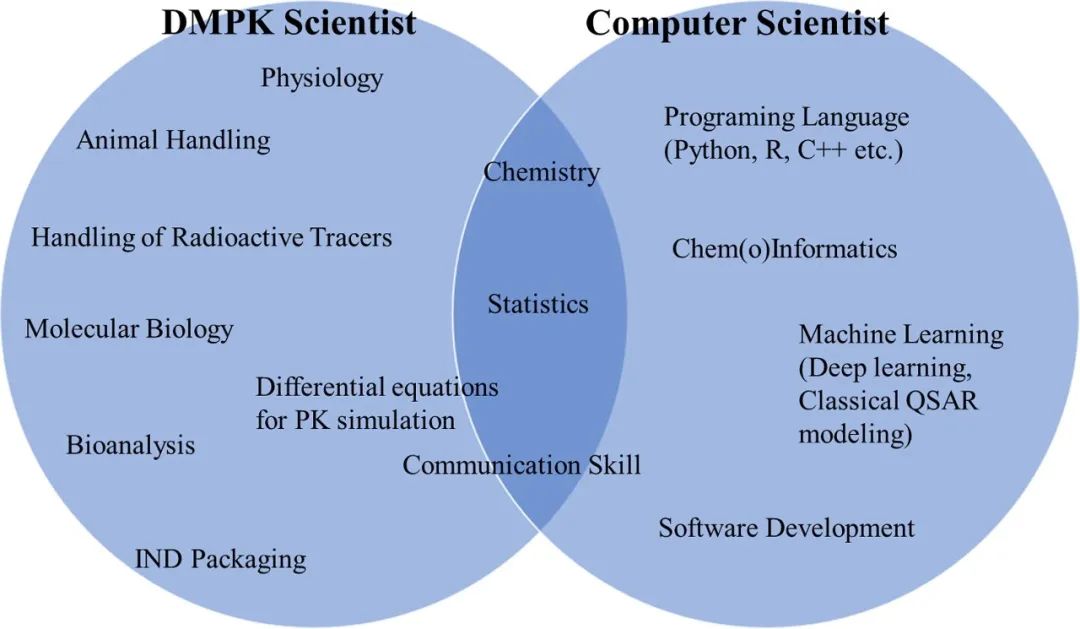
图3. DMPK 和计算机科学家的知识/技能分布
AI在pKa和logD方面预测的优势以及目前应用情况
众多ADME参数中,pKa 和 logD 是最基础的理化性质,也是在 AI 预测中表现最稳定的指标。因为它们受物理定律支配,实验误差较小。
pKa决定分子的电荷状态,影响其在肠道中的溶解度,膜渗透性以及靶点结合等。而logD是衡量分子在水/油之间分配倾向的主要参数,对药物的吸收、分布、代谢影响非常大,大家有过PBPK建模经验便知道,大部分拟合需要调整logP值。
过往pKa的预测方法多依赖于实验数据,传统基于物理化学定律的模型(如量子化学计算、Hansch 方程等),或基于小规模实验数据的线性回归/多元回归。数据集规模较小,在小分子范围内有一定的可用性,但 RMSE 常 > 1.0;化学空间覆盖不足时,外部数据预测性能显著下降。
现今可采用图卷积神经网络大规模建模,通过集成学习结合实验数据混合建模,可使得RMSE<1.0。典型的思路在于利用估算的pKa扩充数据集,提高模型的覆盖率,以及采用GCNN捕捉分子结构-电离性的复杂关系。但估算值虽能扩容数据集,但可能引入系统性偏差,需要高质量外部验证。
对于logD的预测,过往采用QSAR模型以及实验积累的大量logD实验值,可实现在内部化学空间内预测可靠,RMSE<0.4,但外部化学空间适应性差。而现在采用计算值(估算 logD)与实验值结合,实现低成本数据扩充。并引入色谱保留时间等间接实验参数,提高模型信息量。且采用多任务学习框架,将 logD 与相关理化性质(logP、pKa)联合建模。显著提高模型预测能力。
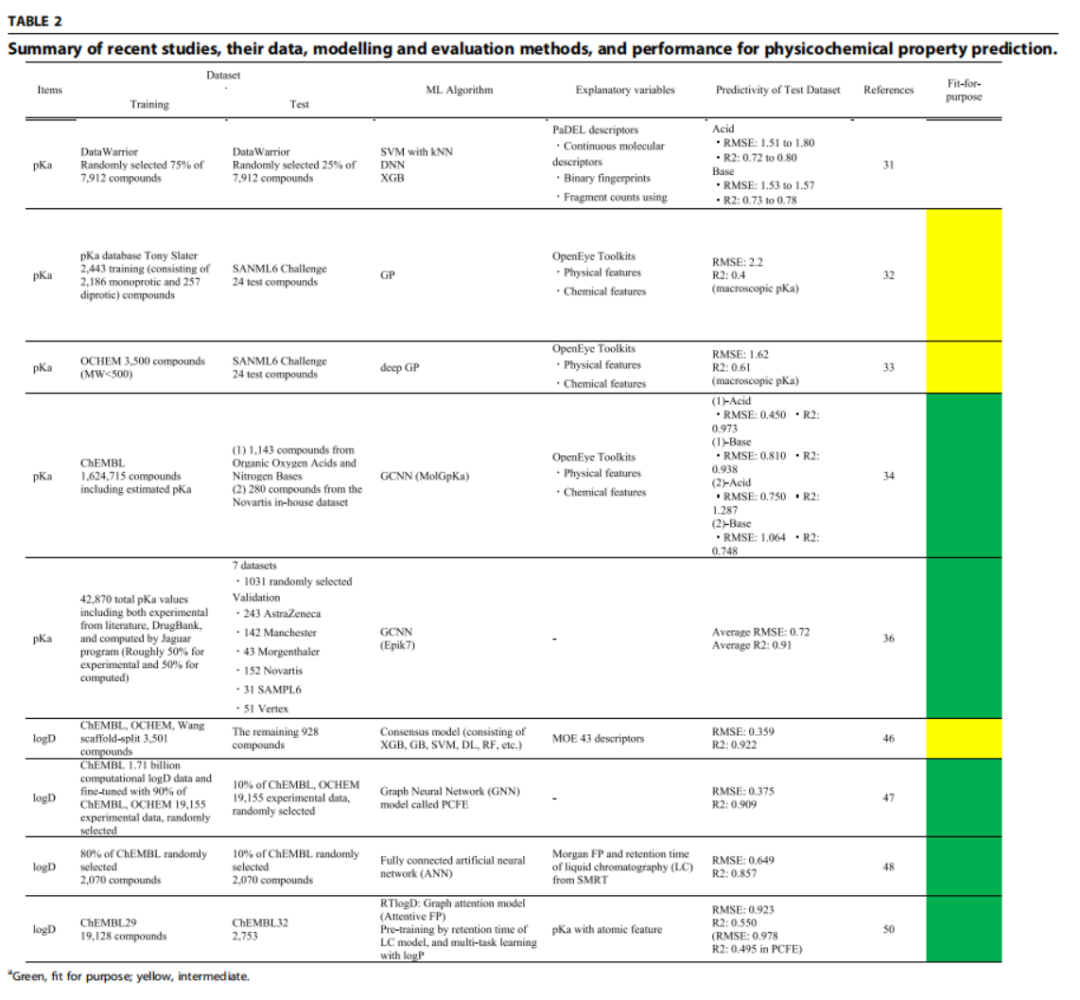
AI在溶解度和渗透性方面预测的优势以及目前应用
溶解度和渗透性也是一对经常一起出现的名词。溶解度相当于药物进入体内的“入场券”,渗透性更是除了进入体内的入场券外,更是药物发挥作用的“决定因素”。
但不同实验室测出来的溶解度可能相差数十倍,主要是因为实验条件(溶剂、温度、孵育时间)差异将导致数据结果相差很大。DMSO 和 Dried-DMSO 模型在早期药物发现阶段较可靠;FaSSIF 模型在后期阶段预测吸收情况有价值。
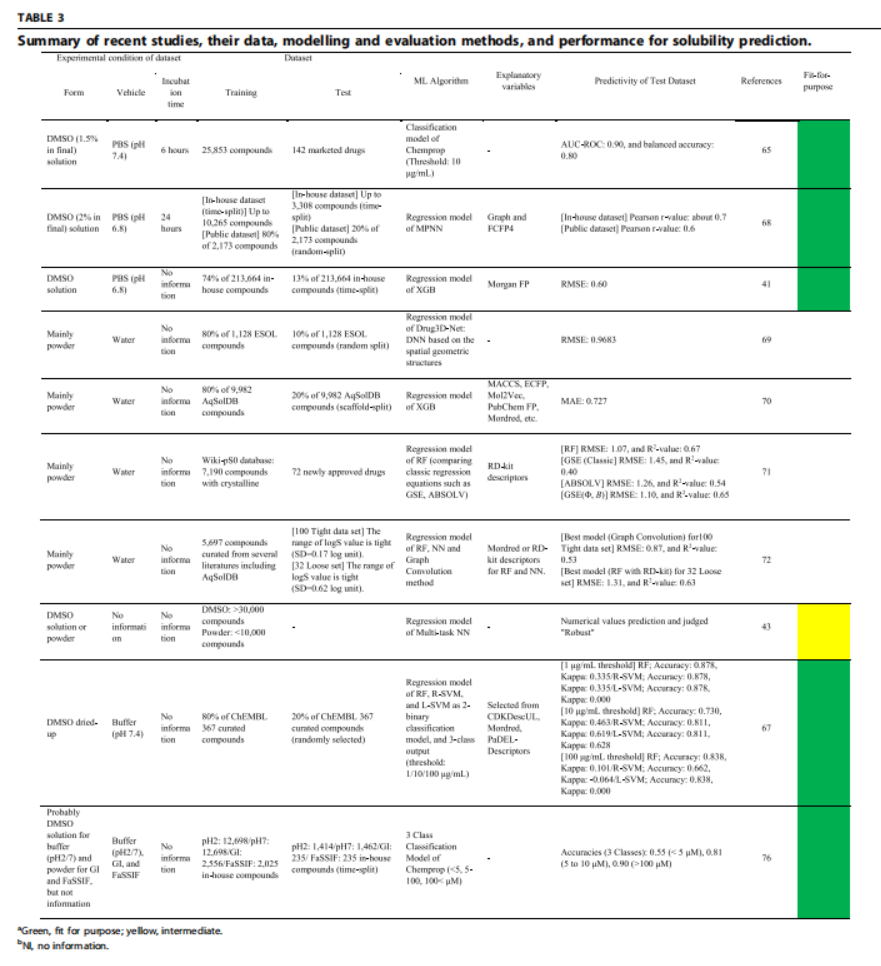
S同样渗透性目前的三大主流实验PAMPA、Caco2和MDCK这几种方法测出来的也不尽相同,用来预测参数也应各有侧重。如在早期高通量筛选阶段,可用PAMPA小数据集+分类模型进行筛查,被证明具有中等的预测性,后期可用Caco-2/MDCK内部大数据集,结合随机森林、Chemprop等分类模型可实现预测AUC>0.85。
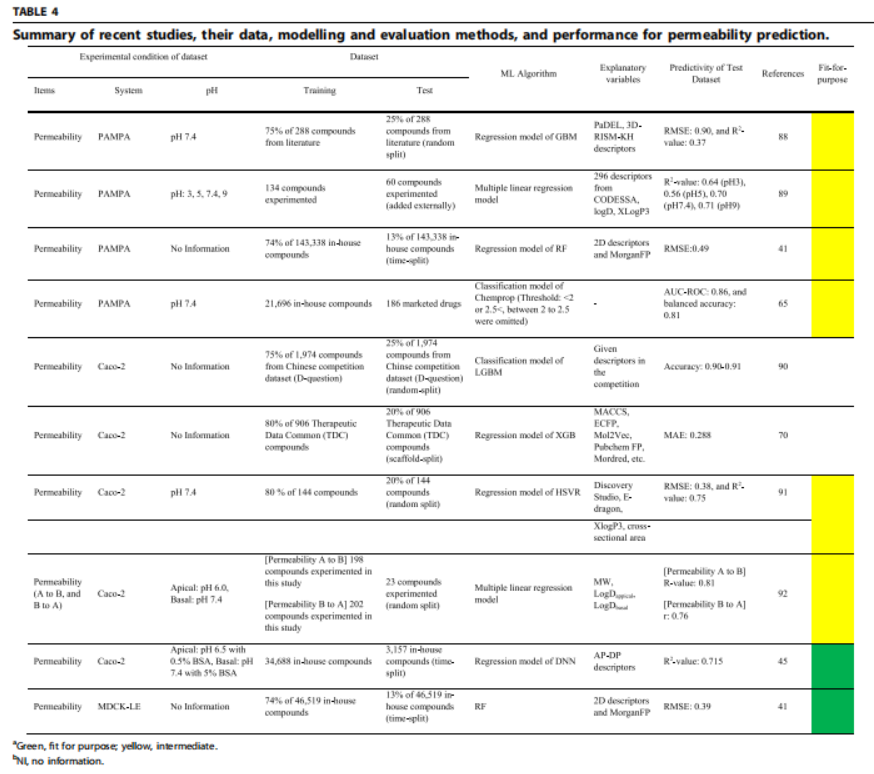
这两个部分的预测还是在于原始高质量数据的积累难度高,实验室间的差异大,导致数据差异大,模型泛化能力弱。
AI在蛋白结合率上的预测优势以及目前应用情况
在药物研发中,只有未结合的药物才能真正作用于靶点。血浆蛋白结合率(PPB)和未结合分数(fup)直接决定了体内自由药物浓度,影响药效、剂量设计、药物相互作用风险以及安全边际。另一个重要指标是微粒体未结合分数(fu,mic),它与代谢稳定性数据结合后,能更准确地预测体内清除率,因此在早期筛选阶段需求很高。
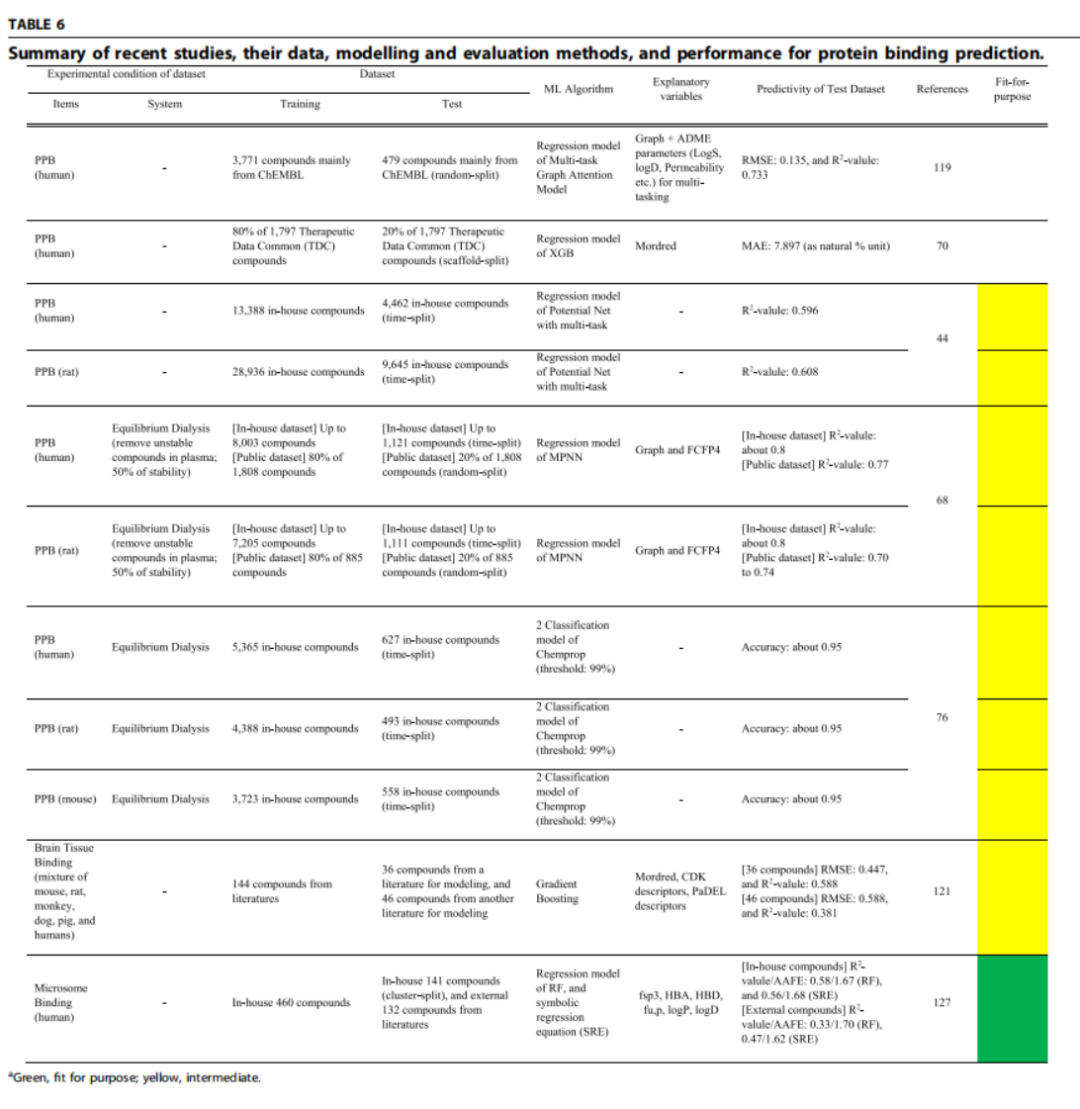
而PPB数据容易获得(平衡透析 + RED 装置可高通量测定),所以模型多、精度高(大公司内部模型 R 值可达 0.8)。但它更多是提供背景信息,而不是决定是否进入下一轮筛选的关键指标。fu,mic直接关系到 CLint 校正,影响代谢预测的准确性。在药物发现早期,有成千上万化合物需要这个数据,但受实验条件影响大(如微粒体蛋白浓度差异、低于定量限的数据丢失),目前预测模型的稳定性还不够。
药企目前利用大规模内部数据,结合多任务学习(同时建模人类和动物数据)显著提升了 PPB 预测的跨物种适用性;针对高蛋白结合化合物的“专门分类模型”也大幅减少了预测误差放大问题。fu,mic 方面,经典理化参数回归对高脂溶性化合物表现差,新的机器学习模型正在尝试引入更多结构特征和条件变量,但要想达到稳定高精度,仍需更多统一条件的大数据集支撑。
在早期筛选阶段,优先利用 fu,mic 模型,因为它和代谢稳定性结合,能在早期阶段帮助淘汰风险分子。做剂量预测或药效分析时,PPB 模型能提供重要参考,尤其是高蛋白结合化合物时,要用专门模型校正误差。
参考资料
[1] Handa K, Hirano M, Kageyama M, Bender A. Computational approaches to DMPK: A realistic assessment of current methods and their practical impact. Part I: Physicochemical and in vitro properties. Drug Discov Today. 2025 Aug;30(8):104422. doi: 10.1016/j.drudis.2025.104422 . Epub 2025 Jun 30. PMID: 40602659 .
扫码添加好友


PK Sim学习笔记
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢