


关键词:k-Center;欧式空间

导 读
本文是 ICML 2025 会议接收论文 Faster Approximation Algorithms for k-Center via Data Reduction 的解读。该工作由北京大学姜少峰课题组与 Bar-Ilan University 的 Arnold Filtser、Nanyang Technological University 的 Yi Li、University of Bonn 的 Anurag Murty Naredla、Athena Research Center 的 Ioannis Psarros、Indiana University Bloomington 的 Qin Zhang 合作完成,论文主要贡献者之一杨乔媛为北京大学计算机学院博士生。
本研究针对欧式空间中的 k-Center 问题,提出高效的数据约简方法。在 k 较大的场景下,该方法首次实现了近线性时间的常数近似算法,在理论与实践层面提升了高维数据的聚类效率。

← 扫码跳转论文
论文地址:https://arxiv.org/abs/2502.05888
01
问题及背景
02
核心思路
我们提出了一种基于数据约简(data reduction)的高效算法框架,其核心思想是构建
给定数据集
该方法将计算复杂度从依赖全量数据规模
03
理论结果
针对欧式空间中的
一、对于任意
二、对于任意
我们提出的两种 coreset 构建方法将欧式空间中的

04
技术概述
对于结果一,我们设计了一种基于哈希函数的 coreset 构建方法。其核心是通过定义哈希映射函数
我们采用了一致性哈希(consistent hashing)[3,4,5]作为技术基础,该技术能确保邻近点被映射到有限的哈希桶中。具体而言,我们基于随机平移网格(randomly-shifted grid)构造了新的哈希函数,并满足
对于结果二,我们提出了一种基于随机命中集(random hitting sets)的 coreset 构造方法,采用多轮迭代采样策略构建 coreset。该方法通过
05
实验验证
我们采用四个真实数据集进行实验验证,涵盖不同规模与维度特性。如表所示,各数据集的原始维度
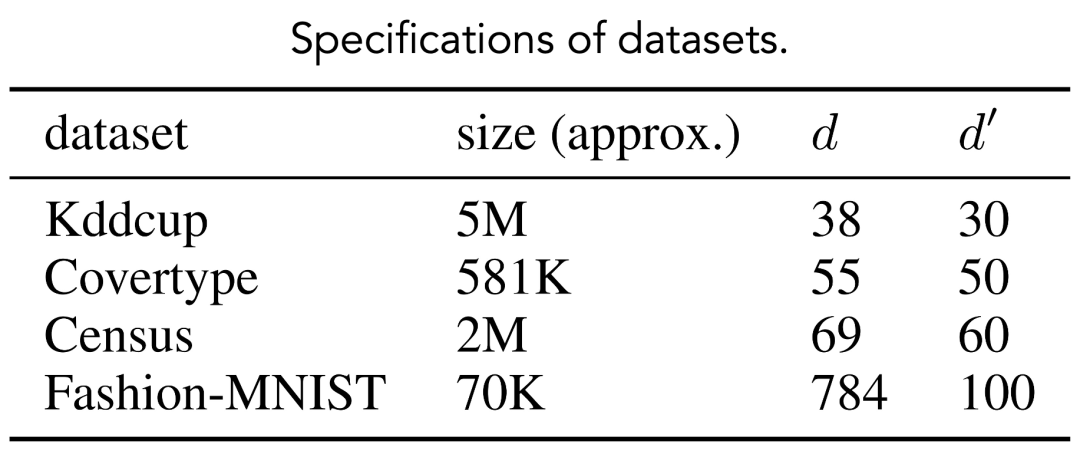
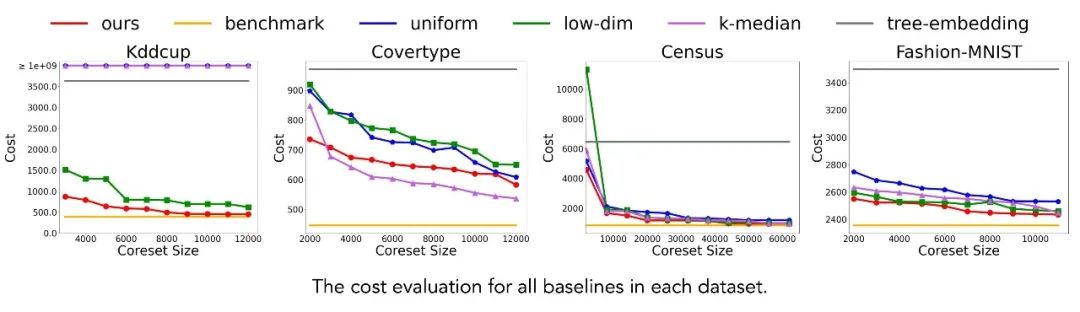
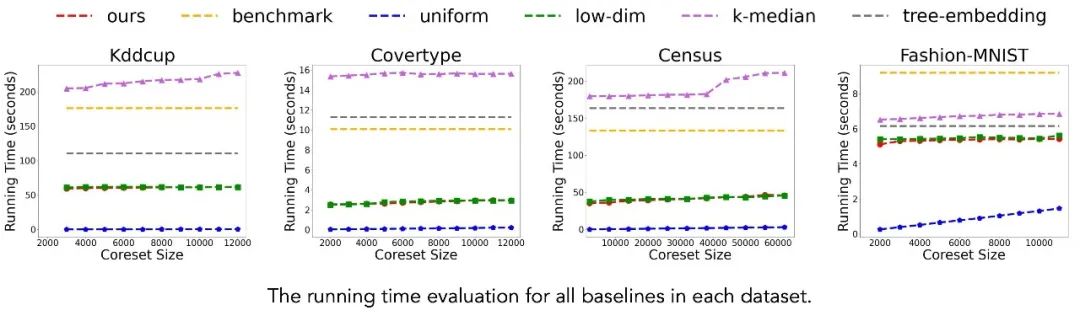
实验结果表明,本文提出的方法(ours)在所有数据集上均展现出显著优势。相比传统 Gonzalez 算法(benchmark),我们的方法在仅使用相对于原始数据集5%数据规模的 coreset 时,即可将聚类代价控制在基准方法的1.3倍以内,同时实现2-4倍的运行速度提升。
参考文献
[1] Gonzalez, T. F. Clustering to minimize the maximum intercluster distance. Theor. Comput. Sci., 38:293–306, 1985.
[2] Eppstein, D., Har-Peled, S., and Sidiropoulos, A. Approximate greedy clustering and distance selection for graph metrics. J. Comput. Geom., 11(1):629–652, 2020.
[3] Czumaj, A., Filtser, A., Jiang, S. H., Krauthgamer, R., Veselý, P., and Yang, M. Streaming facility location in high dimension via new geometric hashing. CoRR, abs/2204.02095, 2023. URL https://doi.org/10.48550/arXiv.2204.02095. see also conference version in FOCS22.
[4] Filtser, A. Scattering and sparse partitions, and their applications. ACM Trans. Algorithms, 20(4):30:1–30:42, 2024. See also conference version in ICALP20.
[5] Jia, L., Lin, G., Noubir, G., Rajaraman, R., and Sundaram, R. Universal approximations for tsp, steiner tree, and set cover. In STOC, pp. 386–395. ACM, 2005.
[6] Johnson, W. and Lindenstrauss, J. Extensions of Lipschitz maps into a Hilbert space. Contemporary Mathematics, 26:189–206, 01 1984.

图文 | 杨乔媛
PKU 姜少峰Lab

姜少峰博士,现任北京大学前沿计算研究中心助理教授、北京大学博雅青年学者,于2021年正式加入中心。他于2017年在香港大学获得博士学位,曾在以色列魏茨曼科学研究学院进行博士后研究,并曾在芬兰阿尔托大学任助理教授。他的研究方向为理论计算机科学,近期侧重于大数据算法及其在机器学习中的应用,并已在包括 STOC,FOCS,SICOMP,SODA,ICML,NeurIPS 等主流国际期刊和会议上发表论文多篇。
姜少峰Lab相关科研动态


— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

点“阅读原文”转论文链接
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢