
⚠️ 本文不构成任何法律意见或建议。
人工智能法:
https://eur-lex.europa.eu/eli/reg/2024/1689/oj/eng
GPAI 行为准则 (Code of Pratice):
人工智能法:
https://eur-lex.europa.eu/eli/reg/2024/1689/oj/eng
GPAI 行为准则 (Code of Pratice):
https://digital-strategy.ec.europa.eu/en/policies/contents-code-gpai
GPAI 指南:
https://digital-strategy.ec.europa.eu/en/library/guidelines-scope-obligations-providers-general-purpose-ai-models-under-ai-act
训练数据公开摘要模板:
https://digital-strategy.ec.europa.eu/en/news/commission-presents-template-general-purpose-ai-model-providers-summarise-data-used-train-their
欧盟《人工智能法》已于 2024 年 8 月 1 日正式生效,确立了一套基于风险的监管规则,用来决定哪些人工智能系统和通用人工智能(GPAI)模型可以在欧盟市场销售和部署,以及具体的方式。该法律将分阶段实施,直至 2027 年 8 月全面落地。并且自 2025 年 8 月 2 日起,所有在欧盟市场投放 GPAI 模型的提供者,都必须遵守一系列合规要求,无论企业是否设立在欧盟境内。对于在 2025 年 8 月 2 日之前已进入欧盟市场的 GPAI 模型,其提供者必须在 2027 年 8 月 2 日之前完成合规。
对开源社区来说,这是一个好消息 —— 欧盟《人工智能法》为研究人员和开源开发者提供了更便捷的合规路径,甚至在一定情况下实现自动合规。许多为科学研究目的而开发 GPAI 模型的研究人员,并不在该法规的适用范围之内,非商业活动下的开发同样如此。对于那些确实落入欧盟《人工智能法》适用范围的模型,如果以自由和开源许可证方式发布,其开发者也可以部分豁免。这些豁免条款体现了监管方对开放式开发的价值与潜力的认可,同时也确保了必要的责任追究。不过,在现实中是很难判断这些豁免在何种情况下、以及在多大程度上适用。
本指南的核心目标是帮助解答这些问题,并为研究人员和开发者在使用或开发开源 GPAI 模型时,提供一个清晰易懂的入门途径。我们将带你逐步了解关键定义、相关义务,以及开源豁免条款,并说明开源提供者如何依据欧盟委员会的官方指导来实现合规,例如 GPAI 行为准则,GPAI 指南和训练数据公开摘要模板。
如果你时间有限,可以使用我们制作的交互式应用,它可以帮助你快速获得整体概览。👉 https://huggingface.co/spaces/hfmlsoc/os_gpai_guide_flowchart
如果你需要更多关于《人工智能法》的指导,我们还在 Hugging Face 和 Linux 基金会发布了面向开源开发者的一般性指南供参考。
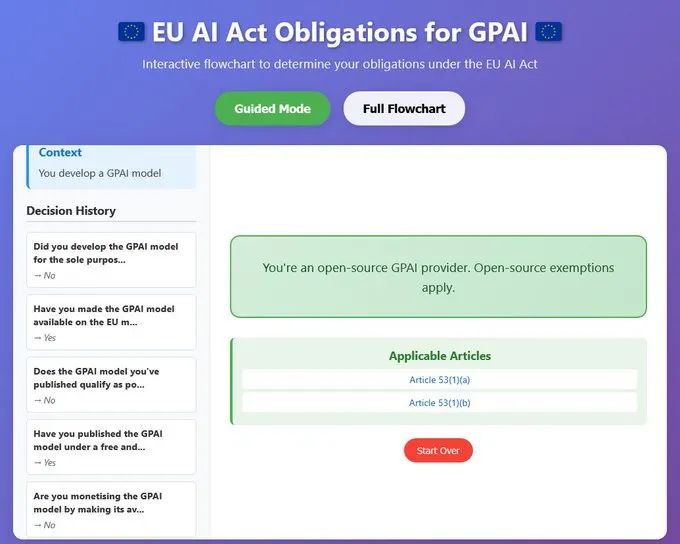
👉 https://huggingface.co/spaces/hfmlsoc/os_gpai_guide_flowchart
这个应用程序可以帮助开源开发者评估他们的 GPAI 模型项目是否使其符合《人工智能法》下“GPAI 模型提供者”的定义。如果是,那么有哪些相关义务需要遵守。你也可以在 Hugging Face Space 中查看更全面、更独立的版本。
理解对 GPAI 模型提供者的要求 如果仅为研究目的开发 GPAI 模型,算是提供者吗? 如果微调或修改了另一提供者的 GPAI 模型,算是提供者吗? 什么是“GPAI 模型”? 什么是“GPAISR 模型”? 什么情况下开发者会被认定为 GPAI 模型的“提供者”? 理解 GPAI 模型提供者的开源豁免 我是否符合开源豁免条件? 哪些义务包含在开源豁免之内? 理解适用义务对应的合规要求 第 53 条 (1a-b):透明度与文档 第 53 条 (1c):版权 第 53 条 (1d):训练数据文档 第 55 条:GPAISR 模型的安全性与保障 下一步与行动呼吁
摘要 (TL;DR): 《人工智能法》中的 GPAI 模型这一术语,大致相当于人们常说的“基础模型”。通常来说,如果一个模型能够在广泛任务上表现良好,能生成文本或其他形式的媒体,并且其累计训练计算量达到或超过 1023 浮点运算(FLOPs),那么它很可能会被归为《人工智能法》中的 GPAI 模型。
《人工智能法》将 GPAI 模型分为两类:一般的 GPAI 模型,以及具有系统性风险的 GPAI 模型(GPAISR,见下一节)。根据 其第 3 条第 63 款 的定义,GPAI 模型是指:“人工智能模型,包括那些通过大规模自监督方式训练、具备显著通用性,并能够胜任多种不同任务的模型,无论其在市场上的投放方式如何,该类模型都能够被集成到各种下游系统或应用中。但仅用于研究、开发或原型阶段、且尚未进入市场应用的模型不属于此范围。”
根据 GPAI 指南的说明,判断一个模型是否属于 GPAI 模型的参考标准是:其训练计算量超过 1023 浮点运算(FLOPs),且具备生成语言(文本或语音)、文本生成图像或文本生成视频的能力。 指南指出,这一阈值大致相当于训练一个拥有十亿参数规模的模型所需的计算量(在大规模数据上进行训练)。指南还给出了在适用范围内和不在适用范围内的模型示例(见表 1)。
- 一个专门用于下棋或玩电子游戏的模型,训练所使用的计算量为 1024 FLOPs。 - 一个专门用于气象模式或物理系统建模的模型,训练所使用的计算量为 1024 FLOPs。 |
表 1:符合或不符合 GPAI 模型定义的示例(来源:欧盟委员会,GPAI 指南)
请注意,GPAI 模型与《人工智能法》中的“人工智能系统(AI systems)”定义不同 —— “人工智能系统”的定义见 《人工智能法》第 3 条第 1 款。根据序言第 97 条,虽然 GPAI 模型是人工智能系统的重要构建模块,但它们本身并不是人工智能系统。
要成为一个人工智能系统,模型必须与额外的组件结合,例如用户界面或其他功能模块,从而实现交互和部署。根据你提供的是 GPAI 模型、人工智能系统,还是两者兼有(例如,将 GPAI 模型集成到用户界面),适用的法律要求可能会不同。
当提供者同时提供通用人工智能模型(GPAI)与具体人工智能系统(AI systems)时,相关要求将同时适用。而针对人工智能系统的要求,则取决于该系统可能带来的风险强度与风险范围。本指南未涵盖这些进一步的要求。
摘要 (TL;DR): 具有系统性风险的 GPAI 模型(GPAISR)大体上等同于所谓的“前沿模型”(Frontier models),即当前市场上最先进的 GPAI 模型。如果一个模型符合《人工智能法》对“高影响能力”的定义,或者其训练计算量超过 1025 FLOPs,那么该模型将被视为 GPAISR。
根据 《人工智能法》第 51 条第 1 款,如果 GPAI 模型符合以下两个条件之一,就会被归类为具有系统性风险:
具备“高影响能力”,这些能力与当前最先进模型中记录的能力相当或更强,并且是通过适当的技术工具、方法学、指标和基准测试进行评估的。 根据欧盟委员会作出的决定,它具备与“高影响能力”等同的能力或影响,这一判断基于《人工智能法》正文中提供的一系列标准(见附件 XIII: https://eur-lex.europa.eu/eli/reg/2024/1689/oj#anx_XIII),例如模型的规模、在基准和评估中的表现,以及其在整个欧盟的使用广泛程度。
当 GPAI 模型的累计训练算力超过 10^25 次浮点运算时,即可推定其具备高影响力能力。目前,这一门槛主要适用于处于人工智能前沿的模型,例如 GPT-4o、Grok 4 或 Mistral 2 Large。GPAI 指南 对这一算力阈值的设定,旨在用于识别具备高影响力能力的通用人工智能模型。为了确保《人工智能法案》能够与技术前沿保持同步,欧盟委员会可能会随着时间推移,对性能指标和算力阈值进行调整。
虽然所有达到该阈值的模型都必须向欧盟委员会进行通报,依据《人工智能法》 序言第 112 条,开发者也可以提交证据,“证明由于其特定特性,该通用人工智能模型在特殊情况下并不构成系统性风险”。例如,如果模型在 《行为准则》(Code of Practice)安全与保障章节附录 1.3.1 中列出的能力低于其他非 GPAISR 模型,那么这一例外机制可能适用。此类情形对一些主要作为研究成果而开发的超大规模模型中,可能具有实际意义。
摘要 (TL;DR): 无论是否设立在欧盟境内,如果同时满足以下两个条件,都会被视为 GPAI 模型的提供者:1)开发了一个 GPAI 模型,或由他人代开发;2)将其投放至欧盟市场。这意味着你本人或你所在的组织将其提供用于分发,或在欧盟的商业活动中使用,无论是有偿还是无偿。在撰写本指南时,关于在此语境下何为“商业活动”的确切界限仍存在一定不确定性。尽管相关欧盟法规表明,其适用范围不太可能涵盖个人“业余开发者”的工作,也不会自动包括开发者在 GitHub 或 Hugging Face 等平台上以 FOSS(自由及开源软件)许可证形式、且未进行商业化的共享成果,但最终的认定仍可能需要根据具体情况逐案决定。
《人工智能法》在 第 3 条第 3 款 中对 GPAI 模型的提供者定义为:“自然人或法人、公共机构、代理机构或其他组织,在其名义或商标下开发人工智能系统或 GPAI 模型,或委托他人开发人工智能系统或 GPAI 模型,并将其投放市场或投入使用的,无论是有偿还是无偿。”第 3 条 将“投放市场”定义为“首次在欧盟市场上提供人工智能系统或 GPAI 模型”(第 3 条第 9 款);并将“在市场上提供”定义为“在商业活动过程中,为在欧盟市场分销或使用而提供人工智能系统或 GPAI 模型,无论是有偿还是无偿”(第 3 条第 10 款)。
简单来说,根据欧盟法律,当一项产品首次在欧盟市场上被提供时,即被视为“投放市场”。此后,任何进一步的供应(例如从一个分销商到另一个分销商,或到最终用户)都被称为“在市场上提供”。 序言第 97 条(注:在欧盟法律中,序言为法律条款提供非约束性的解释)进一步说明:“GPAI 模型可以通过多种方式投放市场,包括通过代码库、应用程序接口(API)、直接下载,或实体拷贝等形式。”
“商业活动”的概念对于理解在什么情形下构成在欧盟市场投放一个模型或系统至关重要;这一概念比单纯的“向欧盟公民提供”更具针对性。虽然在《人工智能法》的适用范围内,关于 AI 模型的具体认定尚未做出,但 《蓝皮书》(Blue Guide)—— 关于欧盟产品规则实施的指南(https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=oj:JOC_2022_247_R_0001) 被设计为立法框架下的一般性指导文件。根据《蓝皮书》: “商业活动被理解为在与商业相关的背景下提供商品。如果非营利组织在这样的背景下运作,也可能被视为从事商业活动。这一认定只能根据具体情况逐案决定,需要考虑供应的规律性、产品的特征、供应者的意图等因素。原则上,慈善机构或业余爱好者的偶发性供应,不应被视为发生在与商业相关的背景下。”
作为另一项参考,可以考虑欧盟的《网络弹性法案》(CRA)。CRA 中说明了生产自由和开源软件的个人或组织是否应被归为该法案中的“制造商”。CRA 的序言第 18 条 部分指出: “……被认定为自由及开源软件(FOSS)的数字元素产品的提供行为,如果其制造商未对其进行商业化,不应被视为商业活动。” 虽然《网络弹性法案》的措辞可能对《人工智能法案》的解释不具备约束力,但其中的这一表述以及其他相关措辞确实指向一种理解,即在FOSS 许可下提供的软件,并不总是、也并非本质上就应当被视为《网络弹性法案》意义下的“商业活动”,特别是在生产者未对其进行“商业化”的情况下。这可能意味着,在《人工智能法案》的适用中,也会采取类似的处理方式。
同样需要特别注意的是,《人工智能法》具有域外适用效力,这意味着它适用于那些将 GPAI 模型投放欧盟市场的提供者,而不论其是否设立在欧盟境内或第三国。设立或位于第三国的提供者,必须在将 GPAI 模型投放欧盟市场之前,指定一家设立在欧盟的授权代表。然而,正如下文进一步讨论的,这一义务并不适用于以自由和开源许可证方式提供 GPAI 模型的提供者,除非这些模型构成系统性风险。
摘要 (TL;DR): 仅为科学研究与开发而开发的 GPAI 模型,不适用《人工智能法》,因此享有豁免。
如果仅出于科学研究与开发目的开发 GPAI 模型,根据《人工智能法》,不会被认定为提供者,因此不受其义务约束。这意味着,当 GPAI 模型的开发主要目的是将模型及相关数据作为科研成果发布时,特别是在学术机构和非营利环境中,欧盟《人工智能法》不会施加任何额外要求。第 2 条第 6 款 规定:“本条例不适用于专门为科学研究和开发的唯一目的而开发和投入使用的人工智能系统或人工智能模型,包括其输出。”
根据 序言第 25 条,在产品导向型研究过程中进行的测试和开发活动同样不在《人工智能法》的适用范围之内,尽管这种豁免在模型于测试过程中被投放市场或投入使用时终止。序言第 109 条 进一步说明,虽然为科学研究目的开发 GPAI 模型的开发者享有豁免,但应鼓励他们自愿遵循提供者的相关义务。
摘要 (TL;DR): 如果你以某种方式微调 GPAI 模型,并显著改变了模型,那么你可能需要在可行范围内遵守对提供者的要求。一个经验法则是:如果微调所用的计算量超过基础模型训练计算量的三分之一,就会属于这种情况。
只有在修改导致模型的通用性、能力或系统性风险发生显著变化时,才会被视为 GPAI 模型的提供者。所谓“显著变化”的阈值是:修改所需的训练计算量超过原始模型训练计算量的三分之一。
如果无法确定这一数值(例如原始提供者没有披露训练计算量),GPAI 指南 解释说,应使用替代阈值:对于 GPAI 模型,是 1023 FLOPs 阈值的三分之一;对于 GPAISR 模型,是 1025 FLOPs 阈值的三分之一。
如果对模型的修改使你被认定为提供者,那么在第 53 条中的要求仅限于你所做的修改,这意味着只需记录微调过程、新的训练数据以及所做的更改即可。此外,若 GPAI 模型提供者设立在第三国,则在将其投放欧盟市场之前,必须通过书面授权委任一名在欧盟设立的授权代表的义务同样适用,除非该经微调或修改的GPAI模型符合开源豁免条件。
被认定为 GPAI 或 GPAISR 模型的“提供者”意味着该模型受到《人工智能法》的规范,并需遵守第 51 条 至 55 条 所规定的多项义务。然而,如果 GPAI 模型在投放欧盟市场时是以自由和开源许可证发布的,则可以免除其中部分要求。理解自己在《人工智能法》下的义务的下一步,就是弄清这些豁免的适用范围。
要符合开源豁免条件,你必须同时满足以下三个条件:
(允许访问、使用、修改和再分发)。
不允许:带有“仅限研究”、“禁止商业用途”或其他使用限制的许可证。 例外:在 FOSS 许可证中,若与安全相关的使用限制是成比例的,则可能是允许的(参见 CoP 第 84 段)。
不允许:对访问收费、与付费服务捆绑、基于广告的分发,或以收集用户数据作为访问条件。
摘要 (TL;DR): 如果你以自由和开源许可证发布 GPAI 模型,并附带足够的文档,同时不对模型进行商业化,那么你将部分豁免于 GPAI 开发者的相关要求。
要符合 GPAI 模型的开源豁免条件,第 53 条第 2 款 和 GPAI 指南明确规定,你必须同时满足以下三个条件:
GPAI 模型必须以自由和开源许可证发布,并允许访问、使用、修改和分发该模型。 参数(包括权重)、模型架构信息以及模型使用信息必须公开可得。 GPAI 模型不得以收费方式提供,也不得以其他方式商业化。
对于自由和开源许可证的定义,通常包括广泛使用的宽松型软件许可证,如 Apache 2.0 和 MIT,以及宽松型模型许可证,如 OpenMDW。根据 GPAI 指南的解释,必须同时满足四项权利(即访问、使用、修改和分发),才算作自由和开源许可证(第 78 段)。因此,带有使用限制的许可证(例如“仅限研究”、“可接受使用限制条款”、“商业条款”)不符合自由和开源许可证的要求(第 83 段)。不过,指南在后续说明中补充道,如果出于公共安全、安保或基本权利存在重大风险的担忧,许可方在某些领域可以设置特定的、适度的、与安全相关的使用限制,这是可以被允许的(第 84 段)。
如果 GPAI 模型以收费方式提供或以其他方式商业化,它将无法享受开源豁免。根据 GPAI 指南,商业化的情形包括:将模型的获取与任何形式的支付挂钩;要求用户从提供者处购买其他产品或服务(例如技术支持或培训服务);在开发者托管的平台上强制观看广告;或提供者接收和/或处理个人数据。序言第 103 条 进一步澄清:“通过开放式存储库提供人工智能组件本身不应构成商业化”,但其界限取决于在模型的分发或使用过程中是否采用了额外的商业化策略。
摘要 (TL;DR): 如果你符合开源豁免条件,你仍然需要提供训练数据的详细文档,并证明你遵守了欧盟的版权法。但你无需满足向欧盟委员会或下游用户提交更详细文档的要求,也不需要在欧盟指定授权代表。
《人工智能法》对 GPAI 模型提供者的义务采取分级方式(见表 3)。第 53 条和 54 条 规定了一些适用于所有 GPAI 模型的基线义务 —— 但以自由和开源许可证发布的 GPAI 模型可免除其中部分义务(见表 3 左上角象限)。除此之外,更严格的义务(见第 55 条)适用于 GPAISR 模型的提供者,而这些模型不享有任何开源豁免。
| 使用自由和开源许可证 | 未使用自由和开源许可证 | |
|---|---|---|
| 通用人工智能 (GPAI) | 部分豁免 (例如:OLMo 2) | 不豁免 (例如:Llama 3-8B) |
| 具有系统性风险的通用人工智能 (GPAISR) | 不豁免 (目前暂无示例) | 不豁免 (例如:GPT-4.5) |
表 3:不同类别 GPAI 模型的义务与豁免概览
我们在表 4 中总结了 GPAI 和 GPAISR 模型提供者的各项义务,以及开源豁免是否适用。
| 义务 | 开源 GPAI 模型 | 开源 GPAISR 模型 | 官方指导 |
|---|---|---|---|
| 第 53 条 (1a): | |||
| 第 53 条 (1b): | |||
| 第 53 条 (1c): | |||
| 第 53 条 (1d): | |||
| 第 54 条: | |||
| 第 55 条 (1a-d): |
表 4:GPAI 模型提供者的义务、开源豁免与官方指导
摘要 (TL;DR): 开源 GPAI 模型的提供者必须遵守欧盟版权法,并使用人工智能办公室(AI Office)的模板发布训练数据摘要,同时可豁免于透明度和文档要求。开源 GPAISR 模型的提供者必须遵守第 53 至 55 条中的所有要求。《行为准则》(Code of Practice)为遵守大部分义务提供了自愿性指导,其中包括关于透明度和文档、版权合规以及管理系统性风险的安全与安保要求的措施。
我们在此根据《人工智能法》文本本身,以及欧盟官方指导文件 《行为准则》(Code of Practice)、GPAI 指南,以及训练数据公开摘要模板,对开源 GPAI 开发者的合规要求和措施做简要概述。
请注意,这并非法律意见,而是为你提供参考,帮助你了解如果你被认定为 GPAI 模型提供者,哪些条款可能适用于你,以及你可以采取哪些措施来合规。正如前文所述,仅为研究目的开发和分发的 GPAI 模型完全豁免。
本指南中的大部分指引来自 《行为准则》(Code of Practice),该准则是一个自愿性框架,旨在帮助 GPAI 和 GPAISR 模型提供者履行合规义务。一旦得到欧盟成员国和欧盟委员会的认可,选择自愿签署该准则的提供者可以将其作为证明自身合规的一种方式。这意味着,《行为准则》是遵守《人工智能法》针对 GPAI 模型规则的一种途径,但未选择遵循《行为准则》的提供者,仍需以其他他们认为合适的方式履行相关义务。无论如何,是否合规最终将由相关主管机构进行评估。
为方便参考,以下列出开源 GPAI 模型提供者必须采取的措施清单,以符合其要求:
适用于开源 GPAI 模型提供者的义务
1. 第 53 条 (1)(c):版权法合规
提供者必须制定并实施一项规则以确保遵守欧盟版权法。虽然《人工智能法》并未规定政策的具体形式,但 CoP 提供了一种可能的合规路径,即通过以下方式加以落实:
制定一份书面的版权政策文件并实施。建议公开发布该文件,但不是强制要求。
如果你使用网络爬虫自行收集数据,只能收集合法可访问的内容,并避免使用欧盟官方列出的侵犯版权的网站资源。
如果你使用网络爬虫自行收集数据,应遵守 robots.txt 文件和其他机器可读的权利保留声明,并按照最新的标准执行。
在模型文档中加入说明,提醒下游用户不得将模型用于侵犯版权的用途,符合欧盟法律要求。
实施适当且相称的技术保障,防止模型生成复制训练数据中受版权保护的内容。
指定一个联络点,供权利人提交关于不符合上述措施的充分证据投诉。
2. 第 53 条 (1)(d):训练数据摘要
必须使用 AI 办公室提供的模板,来公开发布训练数据摘要:
在官方网站和分发平台上发布该摘要。
包含一般的模型信息、使用的数据集以及数据处理步骤。
当使用额外数据(如微调数据)时,更新该摘要。
如果训练数据与另一个模型版本共享,应在摘要中标注该共享情况。
截止日期:如果你的模型在2025 年 8 月 2 日之前已投放市场,你需要在2027 年 8 月 2 日完成合规。如果你的模型在2025 年 8 月 2 日或之后投放市场,你必须立即合规。
⚠️注意: 如果你的模型被归类为 GPAISR,则必须遵守第 53 条、第 54 条和第 55 条的所有义务。
摘要 (TL;DR): 开源 GPAI 模型提供者如果公开共享模型架构信息并使用符合自由和开源要求的许可证,即可豁免于对透明度的要求;而开源 GPAISR 模型提供者则不享有豁免,可以参考《行为准则》透明度章节中的指导。对于经过微调或修改的开源 GPAISR 模型,只有当修改所需的计算量超过原始模型训练计算量的三分之一时,才会触发这些要求,并且其责任仅限于记录所做的具体修改。
开源 GPAI 模型的提供者可以豁免于透明度要求,因此不必遵循《行为准则》透明度章节中的措施或填写相关表格。开源 GPAISR 模型的提供者则不享有豁免,可以遵循 《行为准则》透明度章节,其中概述了三项措施,用于记录和共享模型开发、能力与局限性等关键信息。
这些措施包括:
公开用于申请访问文档的联系方式; 在相关方提出请求时,向 AI 办公室、市场监管机构和下游用户提供和开放相关文档; 确保文档保持更新、安全保存,并在模型投放欧盟市场后保留 10 年。
为简化合规流程,透明度章节提供了一份模型文档表格,用于收集有关模型的所有必需信息,包括模型属性、分发方式、许可证、用途、训练过程、训练数据、计算资源以及能耗等。这使得提供者更容易整理所需文档,同时确保监管机构和下游 AI 系统提供者能够获取理解模型能力并履行自身监管义务所需的信息。
如果我对现有的 GPAI 或 GPAISR 模型进行微调,该怎么办? 正如前文所述,只有当你的修改导致模型的通用性、能力或系统性风险发生显著变化时,你才会被认定为提供者。如果通过这一计算你被认定为提供者,透明度章节进一步明确,你的文档与透明度义务应相应地仅限于你所做的修改或微调部分,因为你可能无法获取或控制基础模型的开发过程。
摘要 (TL;DR): 《版权章节》为开源 GPAI 或 GPAISR 模型的提供者提供了指导,其中包含五项措施,每项措施都配有强制要求和鼓励性行动,帮助提供者建立一项符合欧盟版权及相关权利法律的政策。
GPAI 和 GPAISR 模型的提供者均不享有豁免,必须制定一个规则以遵守欧盟关于版权和相关权利的法律。《行为准则》的版权章节概述了五项措施,供提供者实施以履行其义务。在表 5 中,我们总结了该章节中每项措施对应的要求和鼓励性行动。
| 措施 | 要求 | 鼓励性行动 |
|---|---|---|
| 措施 1.1 | ||
| 措施 1.2 | - 将欧盟持续更新的侵权网站列表中列出的网站排除在爬取活动之外。 | |
| 措施 1.3 | - 向权利人提供有关网络爬取实践的透明度。 - 对于搜索引擎提供者:避免对表达权利保留的网站进行惩罚性处理。 | |
| 措施 1.4 | - 在可接受使用政策或模型文档(如开源 GPAI 模型的模型卡)中,加入禁止侵权用途的条款。 | |
| 措施 1.5 | - 建立投诉机制。 |
表 5:《行为准则》版权章节中的措施、要求和鼓励性行动(来源:欧盟委员会,通用人工智能模型行为准则之版权章节)
摘要 (TL;DR): GPAI 和 GPAISR 模型的提供者必须使用 AI 办公室提供的模板,公开发布其训练数据摘要,包括模型基本信息、所使用的数据集以及数据处理方面的信息。摘要必须以简明的叙述形式撰写,并在模型投放欧盟市场时,发布在官方网站和分发渠道上。**
AI 办公室发布了一份模板,供 GPAI 和 GPAISR 提供者制作并公开一份足够详细的训练数据摘要,这是第 53 条 (1d) 所要求的义务。该摘要必须在提供者的官方网站和所有分发渠道(例如开放代码库)上公开发布,在模型投放欧盟市场时同步上线。
这一摘要的目的是提高关于 GPAI 模型训练所使用数据的透明度(涵盖从预训练到后训练的所有阶段,包括模型对齐和微调),其中也包括受欧盟版权法及相关权利保护的文本和数据,同时确保保护商业机密和保密的商业信息。
该模板包含三个部分——模型基本信息、主要使用的数据集以及相关的数据处理方面,并提供了简明的填写说明,以帮助提供者以简便和统一的方式提交所需信息。参考案例可见 SmolLM3 的训练数据公开摘要:https://huggingface.co/spaces/hfmlsoc/smollm3-eu-data-transparency
《说明公告》提供了以下补充说明,帮助填写该模板:
摘要应当全面而非技术性细节导向,并以简明的叙述形式撰写,确保相关方和公众都能理解。 为了保护商业机密,不同数据源适用不同的披露要求——对于许可数据,仅需有限细节;对于私有数据集,提供一般性描述即可;对于公开可用数据集,则需要全面披露。 如果不同模型或不同版本的训练数据相同,可以为它们共用同一个摘要,但需明确说明该摘要涵盖哪些模型和版本。如果模型使用了不同训练数据且无法共享摘要,则每份摘要只需记录修改原始模型时使用的新增训练数据(例如微调数据集),并引用和链接到原始模型的摘要。 如果以某种方式微调或修改 GPAI 模型,从而被认定为 GPAI 模型的提供者(如上所述),只需记录修改中使用的新增训练数据,并引用原始模型的摘要。 如果在已投放市场的 GPAI 模型上继续使用额外训练数据进行训练,则必须每六个月更新一次摘要,或者如果新增数据对摘要内容有实质性影响,则需尽早更新,以先到者为准。 如果在 2025 年 8 月 2 日之前已将 GPAI 模型投放市场,那么对于这些模型,必须在 2027 年 8 月 2 日之前完成合规。
摘要 (TL;DR): 《行为准则》的安全与保障章节概述了 10 项承诺,开源 GPAISR 模型的提供者可以遵循这些承诺,以履行第 55 条规定的要求。这些要求基于比例原则设计,会根据系统性风险和提供者的能力进行调整,并为中小企业(SMEs)和中型初创企业(SMCs),包括初创公司,提供简化的合规路径。**
虽然目前尚无开源 GPAISR 模型,但如果未来出现,开源 GPAISR 模型的提供者将受制于第 55 条 (1a-d) 所规定的额外安全与保障义务。如果你被认定为此类模型的提供者,《行为准则》的安全与保障章节概述了 10 项承诺,你可以通过遵循这些承诺来在整个模型生命周期内管理系统性风险并履行相关义务。这些承诺包括但不限于:
风险管理框架: 必须制定书面的流程,以便在 GPAISR 模型的整个开发生命周期中识别和评估系统性风险;在关键触发点(如开发里程碑或计算阈值)进行评估,并建立监测系统收集社区反馈和事故报告。 风险评估: 必须遵循结构化的方法来识别潜在危害(例如有害内容生成、安全漏洞、社会影响),然后制定详细的危害情景,并使用既定的安全基准进行评估。 安全缓解措施: 必须实施保护措施,包括训练数据过滤、输入/输出监测、微调模型以拒绝特定请求、为用户提供安全工具,以及使用分级访问控制(例如 API 限额、用户审核)。 安全措施: 必须针对外部攻击者和内部威胁设定安全目标,并实施技术保障,例如安全的分发方式、访问控制和未授权修改的监测机制。 文档: 必须维护技术报告,涵盖模型架构、能力、训练方法和使用场景,包括风险评估、缓解措施和外部评估;在风险评估发生实质性变化时,需在 5 个工作日内进行更新并向监管机构通报。你必须自文档创建之日或重大事故发生之日起(以较晚者为准),至少保存该文档 5 年。 组织结构: 必须建立明确的风险管理角色,分配足够的资源用于安全职能,并推动健康的风险文化。
这些承诺围绕着两个比例原则进行设计:
合规措施应与模型所带来的实际系统性风险相匹配,确保低风险情境不会触发不必要的繁琐流程。 要求应考虑到提供方的规模与能力,并为中小型企业(SMEs)和中型小市值企业(SMCs),包括初创公司,明确规定简化的合规途径。例如,签署《行为准则》(CoP)的中小企业(SMEs)或中型小市值企业(SMCs),可依据第 56 条第 5 款 免于定期向人工智能办公室报告的义务,但仍可自愿选择遵守。
开发者可以利用若干开源工具来遵循这些措施。例如,在风险评估与模型评估方面,开源框架如 LM Evaluation Harness、lighteval 和 Inspect 能够实现标准化的大语言模型(LLM)评估,而像 Weights & Biases 这样的平台则提供实验跟踪工具,用于模型的持续监测。
在安全缓解方面,开发者可以利用数据策划工具或红队测试框架,同时 NIST 人工智能风险管理框架 提供了负责任的模型开发与部署最佳实践。 在文档要求方面,开发者可以继续使用他们已经熟悉的 模型卡(model cards) 和 数据集卡(dataset cards)。
🚨 鉴于针对 GPAI 模型提供者的相关要求将于 2025 年 8 月 2 日开始实施,我们必须加快提升社区对这些要求的理解和认知。通过向他人介绍这些规定并分享本指南,你可以帮助社区更好地提前做好准备,共同迎接新规的到来!
🛠️ 加入讨论! 我们正在构建关于合规工具与最佳实践的后续资源,但我们需要你的意见,使其真正有用。无论你是对本指南有疑问、想要分享工具和工作流程,还是希望帮助识别尚存的空白点,都欢迎联系!让我们携手合作,帮助社区为《人工智能法案》的合规做好准备。
本指南由 Hugging Face、Mozilla 基金会 和 Linux 基金会 的研究人员合作撰写,作者包括:Cailean Osborne、Maximilian Gahntz、Lucie-Aimée Kaffee、Bruna Trevelin、Brigitte Toussignant 和 Yacine Jernite。我们还特别感谢 Steve Winslow 的审阅与宝贵建议。文中观点仅代表各位作者个人,不一定反映其所在机构的立场。
英文原文: https://huggingface.co/blog/yjernite/eu-act-os-guideai
原文作者: Lucie-Aimée Kaffee, Cailean Osborne, Maximilian Gahntz, Bruna Trevelin, Brigitte Tousignant, Yacine Jernite
译者: Adeena
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢