

原文来自:范凌的泛谈《从大数据到好猜想:关于大模型时代消费者的理解》
大模型重塑了用户需求调研,但可能不是以我们所期待的方式——AI 去获取用户数据、AI 进行数据清洗等。
而是直接回到了用户需求的最根源,用第一性原理的方式,让模型直接去扮演真实的用户,去呈现真实的用户的思考。
因为,模型拥有的数据和知识足够构建好这样的一个 Personal Agent。
特赞创始人范凌的这篇文章,回归到商业调研的源起,去思考大数据呈现的真实,和猜想呈现的真相,到底哪个才是真正对商业决策有意义的结论。
以及,在大模型到来后,我们可以用何种方式来重塑用户需求调研的流程,真正的「重塑」。
很多时候,AI 带来的可能不只是取代重复劳动,而是用更本质的方式,取代了过往的商业模式。
超 12000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。

最新、最值得关注的 AI 新品资讯;
不定期赠送热门新品的邀请码、会员码;
最精准的AI产品曝光渠道
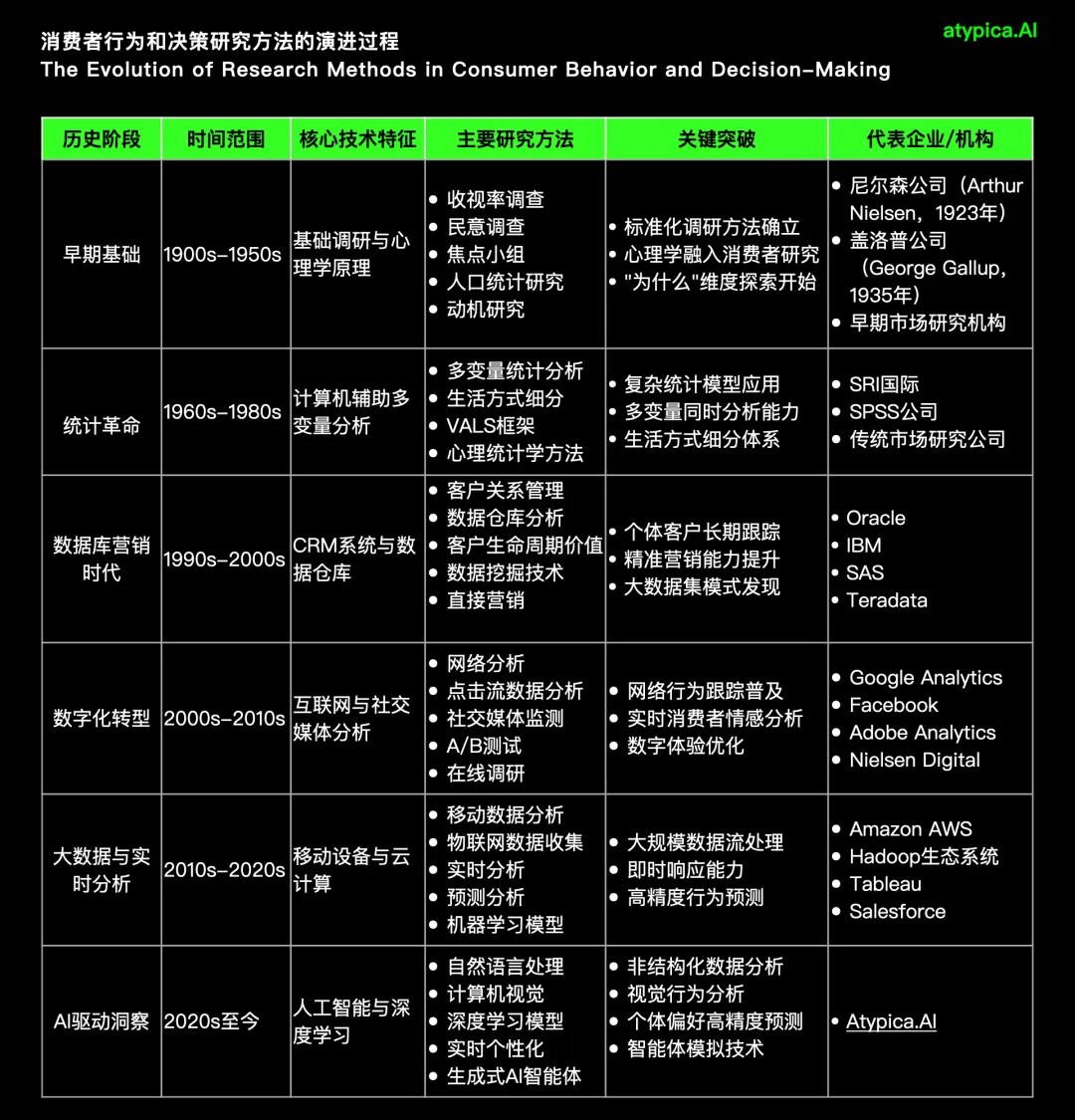
01
一个商业需求引出的思考
让我们来看一个常见的商业需求:
一位品牌说:「我们想通过分析社交媒体数据,进行新品研发、竞品对比、销售卖点提取。能不能爬取各个平台的全量数据来分析?小红书、抖音、微博、B 站……越全越好。」
确实,社交媒体是个数据宝藏。每天有数亿用户在上面分享他们的真实想法、使用体验、购买决策。如果能把这些「全量数据」都抓取下来,进行分析和归因,似乎就能洞察一切。
但是,我想追问几个问题:
爬取全量数据合法合规吗?(大部分平台明确禁止)
爬取全量数据要多少成本?(一个平台就要数百万)
爬取数据更新频次是多少?(实时?每天?每周?)
如何清洗这些数据?(虚假内容、水军、广告...)
最关键的:如何从噪音中提取信号,产生真正的商业洞察?(热门≠真实,声量≠影响力)
这个需求隐藏着一个追问:
我们追求正确的目标的方法足够正确吗?
更让人深思的是,就在这次会议的同一周,我了解到一个仅有 40 人的新消费品牌,没有爬取任何「全量数据」,只是深度访谈了 30 个用户,却准确预测了一个细分市场的爆发,半年内做到了细分类目第一。
区别在哪里?
02
橙汁理论
用一个思想实验来解释这个悖论。想象两个实验室都在研究橙汁:
实验室 A:配备了最先进的光谱仪和色谱仪。他们精确分析出:水分 85.97%,蔗糖 4.23%,果糖 3.82%,葡萄糖 1.95%,柠檬酸 0.92%,维生素 C 47.3mg/100ml...数据精确到小数点后两位。
实验室 B:只有一个目标:调配出让你的味蕾产生「这就是鲜榨橙汁」反应的饮料。他们不断尝试,不断调整,直到 10 个品鉴师中有 9 个说:「这就是橙汁的味道。」
实验室 A 得到「真实」(Real)——橙汁的客观组成;
实验室 B 得到「真相」(True)——橙汁的主观体验。
如果你是品牌方,想推出一款橙汁饮料,你会选择哪个实验室的方案?
「真实」告诉你边界——什么是安全的、合法的、可行的。
「真相」告诉你方向——什么是用户真正想要的、会为之买单的、能创造价值的。
在商业世界,我们经常容易找到了「真实」,但不一定能找到「真相」。
我们知道用户的每一个点击(真实),却不知道点击背后的渴望(真相);
我们测量了每一个转化率(真实),却不理解转化背后的动机(真相);
我们统计了每一个关键词(真实),却不明白词语背后的情感(真相)。
03
大数据的局限
回到开头那个美妆品牌的故事。他们的数据分析无懈可击:
「天然成分」提及量增长 892%;
「敏感肌友好」互动率提升 34%;
竞品平均价格区间 35-45 美元;
目标人群 Instagram 活跃时间晚 8-10 点。
基于这些「洞察」,他们推出了主打天然成分、敏感肌适用、定价 39.99 美元的产品线,并把营销预算的 70%投在了 Instagram 晚间时段。
但他们没有理解的是:
当 25 岁的 Emma 在说「我想要天然护肤品」时,她真正表达的是「我想要一个不那么复杂的生活」。她刚从大学毕业,面对职场压力,怀念校园时代的简单。「天然」对她来说,不是成分表上的植物提取物,而是一种「回归简单」的生活态度;
当 28 岁的 Jessica 提到「敏感肌」时,她其实在说「我受够了不断试错」。她的梳妆台上有 17 瓶半用完的护肤品,每一瓶都代表着一次失望。「敏感肌友好」对她来说,不是低刺激配方,而是「这次不会再让我失望」的承诺。
那个成功的新品牌做对了什么?
他们只深度访谈了 30 个用户,每次 2 小时。创始人亲自参与每一场访谈,不是问「你喜欢什么成分」,而是问「早上照镜子时,你在想什么?」最后,他们的产品文案不是「98%天然成分」,而是「让护肤回归到只需要三步的简单」。不是「敏感肌专用」,而是「我们测试了 1000 次,所以你不用再试错」。
销量差异的背后,是理解深度的差异,
是用「好数据」来实现对「大数据」的祛魅。
注:对比传统工具,Atypica.AI 如何用「好数据」捕捉用户决策深层动机。Atypica.AI 代表了消费者洞察分析的新阶段——从依赖历史数据的被动分析,转向基于智能体的主动模拟。
04
归纳主义的困境
为什么真实的数据不一定代表真相?英国哲学家伯特兰·罗素(Bertrand Russell) 讲过一个故事:
火鸡每天早上 9 点被喂食。它们中的科学家收集了数据:
第 1 天:9 点,食物出现 ✓
第 2 天:9 点,食物出现 ✓
第 3 天:9 点,食物出现 ✓
...
第 364 天:9 点,食物出现 ✓
基于 364 个数据点,火鸡的科学家得出结论:「每天 9 点必然有食物」。
它甚至可以计算出置信度:99.7%。
第 365 天是感恩节。
仅凭过去的重复经验并不能安全地推断未来一定如此,这就是归纳主义(Induction)的致命缺陷:无论你有多少数据,都无法保证下一次会发生什么。归纳主义错误有三个层次:
第一、逻辑层面:从特殊到一般的推理本身就是谬误
想象你是 Netflix 的数据科学家:
观察:用户 A 看完《纸牌屋》后看了《绝命毒师》
观察:用户 B 看完《纸牌屋》后看了《绝命毒师》
观察:用户 C、D、E...都是如此
结论:看完《纸牌屋》的人会看《绝命毒师》
但这个结论是怎么得出的?多伊奇提醒我们:在逻辑上,你永远无法从「所有观察到的天鹅都是白的,推出所有天鹅都是白的」。因为你的观察永远是有限的。
第二、实践层面:相关性不等于因果性
即使相关性是真的,也不意味着你理解了原因:
数据显示:冰淇淋销量与溺水事故高度相关
归纳推理:冰淇淋导致溺水?
真实原因:夏天(你没测量的变量)
在商业中,这种错误每天都在发生:
使用深色界面的 App 用户留存率更高 → 所以都改成深色模式?
购买有机食品的人更长寿 → 所以卖有机食品能让人长寿?
周二的转化率最高 → 所以把所有营销预算投到周二?
第三、认识论层面:知识不是从数据中「提取」出来的
这是多伊奇最深刻的洞察。他问了一个问题:如果知识来自归纳,那么第一个知识是从哪里来的?
答案揭示了一个惊人的真相:知识是被创造的,不是被发现的。
05
科学进步来自于猜想
量子物理学家大卫·多伊奇在《无穷的开始》中提出了一个革命性观点:科学理论并不是「推演」而来的,它们就是一些猜想——大胆的推测。正如他所说:「发现一种新的解释,本质上是一种创造性的行为。要把天空中的光点解释成白热的、直径数百万千米的球体,必须先对这类球体有一个概念...这样的想法不会自发产生,也无法根据任何事物机械推演而得:它们必须是猜出来的——随后可以接受批评和检验。」
多伊奇用科学史上最伟大的发现来证明他的观点:
爱因斯坦的相对论:不是因为他有更多实验数据,而是他猜想:「如果光速是恒定的会怎样?」这个猜想违反直觉,但解释了所有已知现象,还预测了新现象。
达尔文的进化论:不是因为他观察了更多物种,而是他猜想:「如果生命通过自然选择演化会怎样?」这个猜想统一了生物学的所有观察。
魏格纳的板块构造理论:不是因为地质学家收集了更多岩石样本,而是魏格纳猜想:「如果大陆在漂移会怎样?」这个当时被嘲笑的猜想,最终解释了地震、火山、山脉的形成。
多伊奇认为:
科学进步的模式不是「观察→归纳→理论」,
而是「问题→猜想→批判→更好的猜想」。
但是,不是所有猜想都有价值。多伊奇定义了「好猜想」的标准,我把它翻译成商业语言:
1.难以篡改(Hard to Vary):
多伊奇用了一个精妙的例子,为什么科学理论比神话更好?古希腊神话解释冬天:冥后珀耳塞福涅被劫持到冥界,大地女神得墨忒尔伤心,植物停止生长。 科学解释冬天:地球轴倾斜 23.5 度,导致不同季节接收太阳辐射量不同。
区别在哪?神话可以随意修改(为什么是伤心不是愤怒?),但你不能随意把 23.5 度改成 30 度——这个数字是被物理规律锁定的。
商业中的应用:
坏猜想:「用户不买是因为价格太高」——这个解释太容易改了,价格低了还可以说「质量感知不足」;
好猜想:「千禧一代拒绝抗衰老产品是因为购买行为与自我认知冲突」——这个解释很难随意修改,它指向特定的心理机制。
2.可以检验(Testable):
好的猜想必须冒着被证伪的风险。如果一个理论怎么都是对的,那它什么都没说。
商业中的应用:
坏猜想:「用户想要更好的体验」——怎么验证?什么叫「更好「?
好猜想:「职场女性购买护肤品是在购买‘掌控感’」——可以设计实验验证:强调「掌控」vs 强调「呵护」的文案转化率
3.解释深度(Explanatory Depth):
多伊奇特别强调好的解释不仅要说明「是什么」,更要解释「为什么」。而且这个解释应该能统一看似无关的现象。
商业中的应用:
坏猜想:「用户喜欢简约设计」——只解释了表象
好猜想:「信息过载让用户将‘简约’等同于‘可信赖’」——解释了现象背后的心理机制,还能预测其他行为(比如为什么用户也偏好精简的产品线)
06
大数据比好猜想易操作
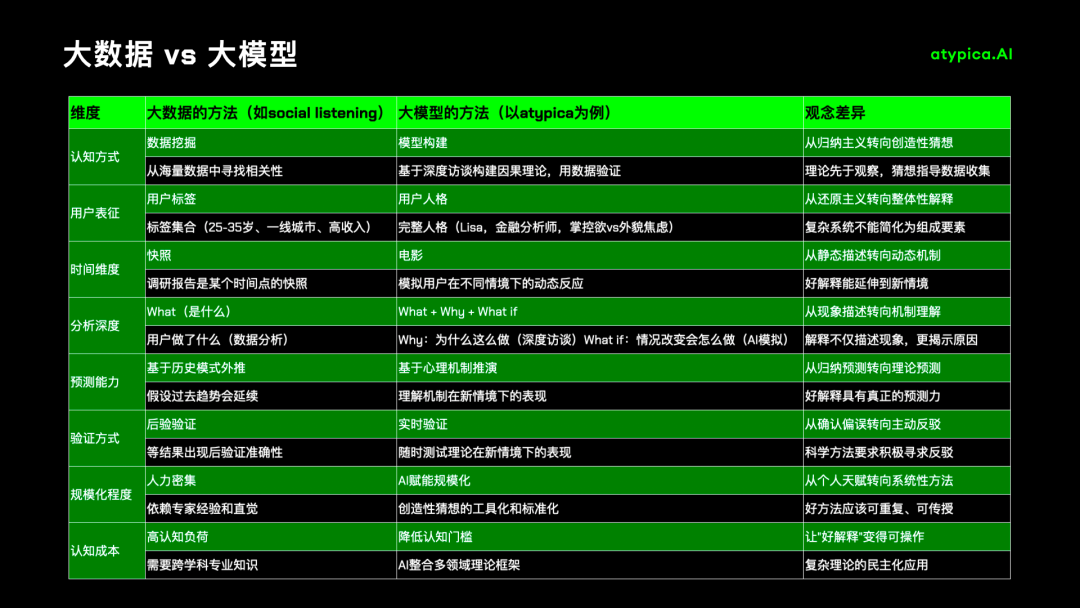
如果好猜想这么重要,为什么大多数公司还是采用大数据的归纳主义呢?
首先,猜想需要勇气,数据提供安全感:跟老板说「基于数据显示...」永远比说「我的理论是...」更安全。即使失败了,你也可以说「数据当时确实是这样」。
其次,猜想需要跨界的思维模型,理解「身份认知冲突」需要心理学知识,理解「社会资本信号」需要社会学知识。但看懂「点击率提升 23%」只需要会看数据报表。
另外,猜想很难规模化,数据可以自动化,一个优秀的用户研究员一年可能产生 10 个好猜想。一套数据系统一天可以产生 10000 个图表。
在结果和效率驱动的组织里,你选哪个?
最后,猜想的价值很难即时证明,「用户购买奢侈品是在购买‘理想自我’」——这个洞察可能需要整个营销战役才能验证。但最深层的原因是:我们没有工具来增强猜想能力,所以我们用数据归纳取代了猜想。
(如果你是数据分析、市场研究领域的专家,欢迎在本文开头的公众号「范凌的泛谈」留言,加微信讨论)
07
大模型带来的商业启蒙
启蒙运动的核心是人类开始相信通过理性思考和科学方法,我们可以理解世界的运作规律,而不仅仅依赖权威和传统。在商业世界中,我们也可以从依赖数据权威转向理性地理解用户行为的深层机制。大语言模型,有机会让「规模化的猜想」成为可能,Atypica.AI 就是我们的一个尝试。
还记得橙汁的比喻吗?传统的社媒聆听(Social Listening)就像采用「大数据」的方法分析橙汁的化学成分;而 Atypica.AI 采用了「大模型」的方法——它像是将橙汁提炼成浓缩粉,然后用语言模型作为「水」,重新还原成橙汁。
这杯「合成橙汁」虽然不是天然的(真实),但它努力模拟橙汁的完整体验——不仅包括口感、色泽、营养特征(真相),更重要的是模拟了人们品尝橙汁时的认知过程和情感反应。Atypica.AI 通过构建「真实人格智能体」(Real Person Agents),这些智能体保持一致的认知模式、情感反应和决策框架,能够在 85%的准确率上模拟真实人类的行为决策。

为什么这种方法能够产生好的猜想?
当 Atypica.AI 基于社媒数据或访谈语料构建消费者智能体时,它实际上是在回答一个核心问题:「什么样的心理机制和认知框架能够产生这样的表达和行为?」这不是归纳统计,而是解释性理论的构建过程——一种对人类决策机制的科学猜想。
传统方法研究用户就像研究橙汁的化学成分,即使掌握了所有标签,也难以完全重构用户的复杂性。而大模型方法通过「语言模型」来理解商业中的主观因素,自动构建人格画像、进行访谈、分析模式,揭示人类选择背后的情感和认知因素。这个过程的原理和效果可以参见《为什么 AI 可以模拟真实消费者》一文。
让我们看看下面的案例:
案例一:一家食品公司想推出针对年轻白领的圣诞礼盒。
社媒数据显示:
「精美包装」提及率 68%
「实用价值」关注度 52%
「创意设计」互动率增长 35%
Atypica.AI 的发现:
有一群「创意礼物探索者」人格的消费者,他们不是在买礼物,而是在寻找「表达自己品味的载体」;
41%的用户抱怨包装过于复杂——不是因为难拆,而是「感觉像在炫技而不是送礼」;
关键洞察发现,迷你组合装受欢迎,不是因为「尝试多样」,而是「降低送礼失败的风险」。
案例二:护肤品不是护肤品
某国际护肤品牌想了解为什么在中国市场表现不如预期。
社媒数据显示:
价格偏高(提及 3421 次)
效果一般(提及 2156 次)
不适合亚洲肤质(提及 1832 次)
Atypica.AI 的发现:
中国消费者购买高端护肤品时,不是在购买产品,而是在购买一种「掌控感」;
「效果一般」的背后,是「看不到每天的微小进步」的焦虑;
真正的竞争对手不是其他护肤品牌,而是医美项目——「立竿见影」vs「日积月累」
基于这个洞察,品牌推出了「肌肤日记」APP,用 AI 技术追踪每天的细微变化,销量增长 230%。
大模型之所以有机会解决归纳主义问题并形成好猜想,关键在于它有可能改变了认知的基本方式。Atypica.AI 不是在归纳数据模式,而是在科学的构建用户认知的猜想。当大模型基于「访谈」或「社媒数据」等语料构建「消费者智能体」时,它实际上是在回答:「什么样的机制能够产生这样的表达和行为?」这是解释性理论的构建过程,而非归纳推理。但是与科学探索不同,在原来的商业环境中往往需要在短时间内得到结论,因此很难大规模进行快速的创造性猜想。大模型建构的消费者智能体恰好解决了这个问题:
多元思维模型:大模型可以同时调用多个思维模型框架(心理学、社会学、行为经济学等),生成关于用户心理机制的多元假设,这相当于拥有了一个跨学科的「猜想生成器」。
认知一致性建模:大模型形成的消费者人设不是标签的简单重组,而是通过智能体构建一套具有内在一致性的,并模拟人的认知系统。
透明的验证过程:多伊奇强调好解释必须可检验。消费者智能体的独特价值在于其思维过程是「透明」的——我们可以观察它如何从价值观推导出具体行为,验证我们的心理机制理论是否成立。
08
用 atypica.AI,
大模型时代市场研究的一个开始
这正是多伊奇所说的「无穷的开始」:
每一个好的解释都开启了新的问题,
每一个新的问题都需要更好的解释。
知识的增长没有终点,理解的深度没有极限。在大模型时代,我们第一次有机会规模化和加速这个过程:
一边有处理大数据的计算能力(检验我们的猜想);
一边有理解个体心智的洞察能力(创造更好的猜想)。
本文是一篇还不够严谨的随想,
Atypica.AI 是一个还不成熟的开始,我想邀请大家一起探索……
*欢迎在公众号留言,和我交流

美国知名风投 BVP 年度 AI 报告:Memory 和 Context 将是新的护城河
AI 创业,小团队、第一天就出海,如何做到 500 万 ARR?
转载原创文章请添加微信:founderparker
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢