

导语
作为研究人类决策、感知、情绪的学科,心理学曾给我们带来众多的惊奇,让我们更加了解自身。随着大模型的出现,心理学有了一个新的研究对象,也就是能够通过语言做出交互的大模型。德国亥姆霍兹慕尼黑研究中心的团队在《自然》杂志发文提出了名为“半人马(Centaur)”的大模型,能够同时解释人们的思维方并预测他们的行为模式。这能够极大丰富传统心理学研究的能力边界,特别是认知测试很慢或很难招募目标群体的场景。但是,或许大模型在模拟人类在极端状况下的心理状态还有很长的路要走。
关键词:认知大模型,多臂老虎机,最小后悔原则

郭瑞东丨作者
张江丨审校
20世纪70年代,美国哲学家托马斯·内格尔(Thomas Nagel)问出了这样一个问题,即便我们对蝙蝠的生理结构、回声定位机制和行为有多么详尽的客观知识,我们永远无法真正理解“作为一只蝙蝠是什么感觉”。
将这里的蝙蝠换成是一个人,我们似乎面临着相同的问题,即我们永远无法真正了解作为一个人是什么感受?作为研究人类决策、感知、情绪的学科,心理学曾给我们带来众多的惊奇,让我们更加了解自身。从饱受争议的斯坦福监狱实验;到棉花糖延迟满足和考试成绩的关联,心理学一直都是一个基于实证的学科。只是如今这一情况有了改变。
随着大模型的出现,心理学有了一个新的研究对象,也就是能够通过语言做出交互的大模型。这相当于承认既然无法回答作为一个人是什么感受这样的天问,那我们直接掀桌子,构建一个在功能上与人类如此相似的系统,以至于它的行为和神经表征都与人类高度一致。这种功能上的等价性,是否在某种程度上“捕获”了主观经验的本质?”
德国亥姆霍兹慕尼黑研究中心的团队做出了这样的尝试,其研究成果在2025年7月发表于《Nature》,他们提出了名为“半人马(Centaur)”的大模型[1],这种从神话故事中跳出的生物,代表了使用人工智能模型模仿人类思维的最强一击。多年来,心理学领域一直试图充分捕捉人类思想的复杂性。然而,过去类似的模型通常仅限于解释人们的思维方式或预测他们的行为方式,很少能同时实现这两点。“半人马”大模型就能同时实现两者,让我们具体看看它是怎么做到的。

海量数据能否代表人类的行为全光谱
海量数据能否代表人类的行为全光谱
首先是训练数据,研究者构建的 Psych-101 的大规模数据集(图1a),涵盖了来自 160 个心理学实验的试验数据。该数据集来自 60092 名参与者,他们共进行了 1068 万个选择,这些决策涵盖从简单的记忆任务到复杂的道德困境。
研究者亲自梳理每项研究的背景,并使用大模型,将每项实验中单个参与者的对话整理成标准的训练数据。由于大模型的上下文限制,每个记录对话的总文本长度是 3.2 万个单词,包含了参与者做出的选择及对应实验背景信息。
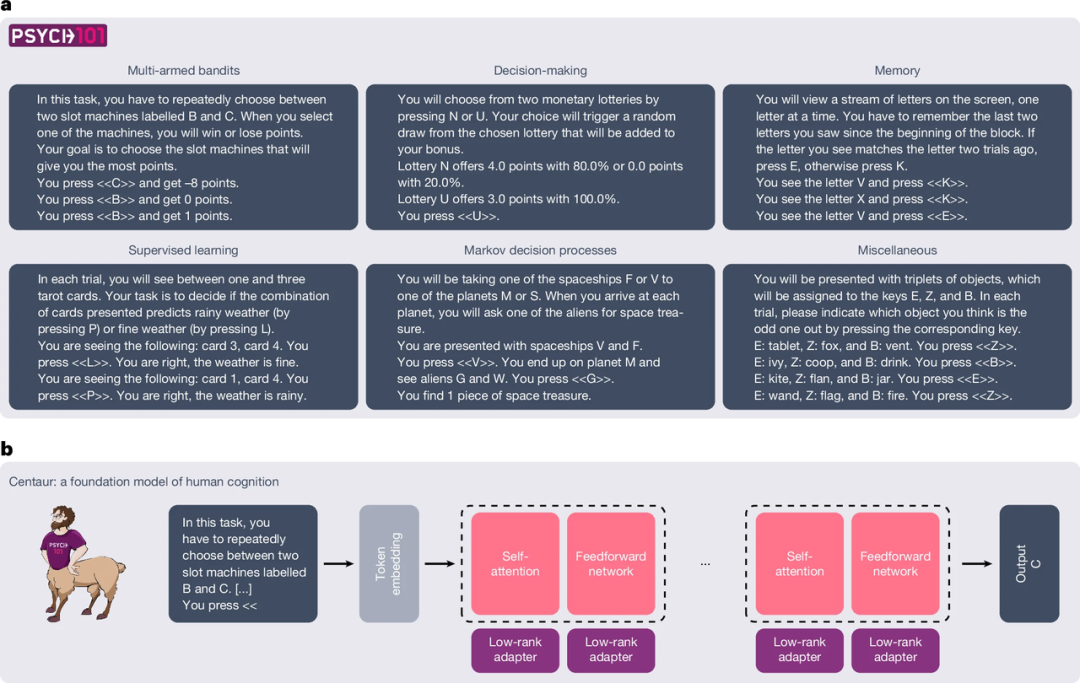
图1:Psych-101 的收集与Centaur的训练过程
有了数据集,便可以对开源大模型 Llama3-70B 进行微调,所谓微调,相当于让大模型进行专科教育,使得模型能够更熟悉 Psych-101 中这些数据,成为预测人类如何做选择的专家,而这个微调后的开源模型,被称为“半人马”(图1b)。
之后要做的,便是对比“半人马”和其它大模型在预测人类选择上的表现了。在此之前,已有不少研究考察不同大模型的心理状态。例如有研究[2]对比 GPT-4,Claude3 和 Gemni2 在给定情景和面部表情图像上识别人类情绪的能力,发现部分情况下,大模型比普通人能更好地对情绪进行判断,可以说大模型比人类情商更高了。然而这样的研究,只是关注人类认知过程的特定部分,“半人马”大模型则是号称能预测人类的全部行为。
“半人马”对人类做出的选择能提前预判
“半人马”对人类做出的选择能提前预判
要验证“半人马”模型是否能准确预测人类通用行为,首先需对人类行为进行分类,然后在每一类任务上评估其预测准确性。图2展示了“半人马”相对于未微调Llama3的预测准确性提升,其中基线方法采用启发式策略。
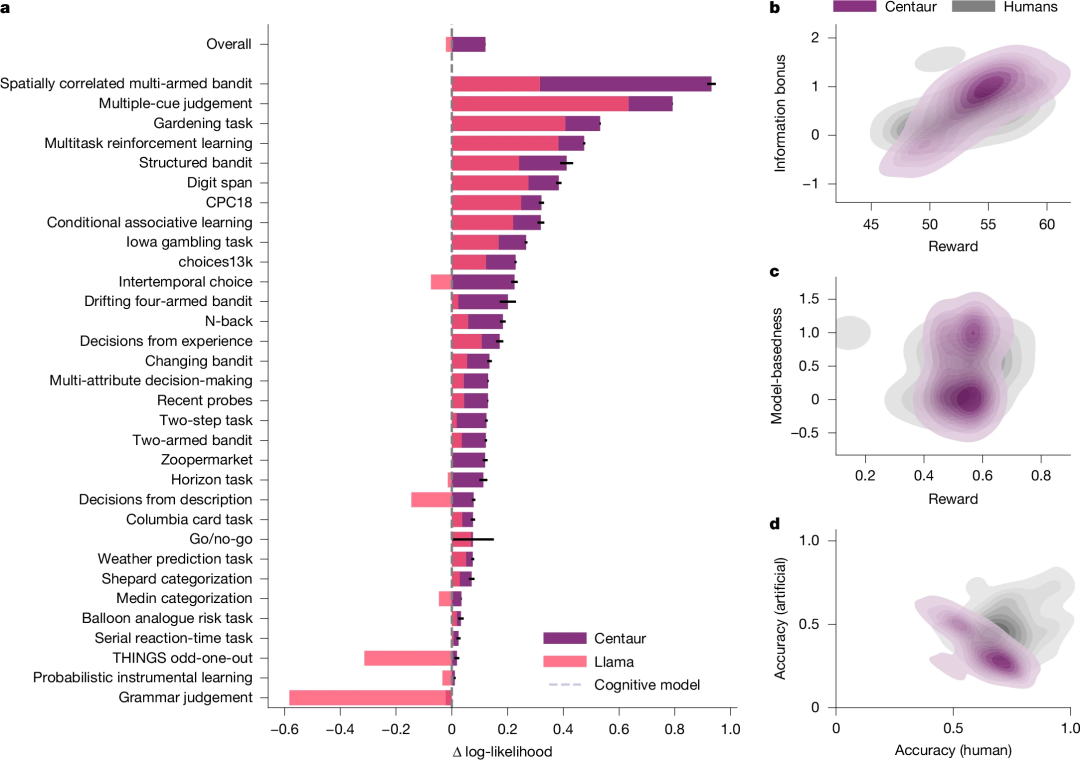
图2:“半人马”在心理学实验中的预测表现
在图2列出的各类任务中,“半人马”的预测准确性均有显著提升。以赌场常见的多臂老虎机问题(如图3所示)为例,启发式方法简单规定:如果上次拉杆获得奖励,则继续选择;否则换一个。这种方法并非最优,也不符合人类实际行为。而“半人马”模型在此任务上的预测准确率提升幅度最大。其次,在多线索判断任务上,“半人马”的准确率提升次之。而在时序反应、天气预测、气球模拟风险任务以及描述性决策等任务中(如图2所示),“半人马”的准确性虽有提升,但幅度较小(图3a中最上方的柱状图显示总准确性提升,“半人马”的对数似然(可靠性指标)优于领域特定模型0.13)。

图3:多臂老虎机(Multi-Armed Bandit, MAB),赌场最常见吞金兽,玩家面前有三个拉杆,每次花一个金币就能选一个拉,之后有一定概率获得多个金币,也有概率啥都得不到。通过多臂老虎机上的实验,认知心理学家可了解人是如何在高风险高收益与稳定收益,以及在不断变化的收益间动态权衡的。
在上述实验中,预测准确性是不是足够高,并不该成为读者的关注点。毕竟“半人马”是在对应这些实验描述上进行过微调的。相当于大模型在进行开卷考试,只要你能让大模型将训练数据一字不错的背下来,模型的准确性可以达到一个高的吓人的值,这在机器学习中被称为过拟合问题。
为了说明“半人马”并没有过拟合,研究者接下来对心理学实验生成了诸多变种。例如将背景故事中的驾驶宇宙飞船前往外星寻找资源(Psych-101 中的数据)变为在一个魔法世界里乘坐魔毯去寻宝,结果显示,在变种的故事中,“半人马”的表现依旧不差(图4a)。
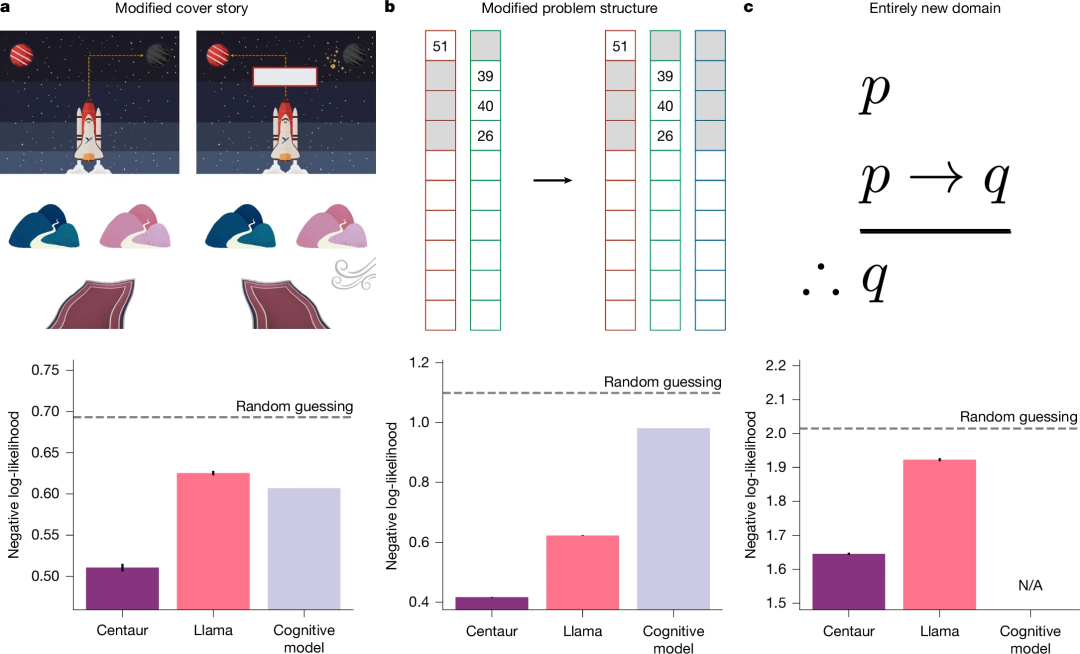
图4:“半人马”在新场景上的预测准确性
在训练数据集中,多臂老虎机中每次被试只需要面对两个候选项,而在测试时玩家面前有了三个候选项,可视为一个新问题。而在回答新问题时,模型的预测准确性仍然超过了未经过微调的 Llama 做出的预测(图4b)。而对于全新的需要概念逻辑推理的问题,虽然 Psych-101 数据集有涉及概念和因果推断,但并没有该类问题,而经过微调后的“半人马”依然比 Llama 更好(图4c)。这些都说明微调带来的增益不是由于过拟合,而是能泛化到未曾见到的数据集上。
除了上述实验,“半人马”还在未曾出现在训练数据集中的其他多种类型的任务,诸如在自然环境中进行选择,涉及道德判断的决策,经济相关的博弈等表现的也比 未经微调的Llama 更好。除了人类的选择,“半人马”还能预测人类的反应时长。从这个视角来看,“半人马”的确算得上一个能广泛的预测人类诸多行为的基座模型,对得上论文标题的宣称。
“半人马”
对人类决策时脑活动和决策理由的预测
“半人马”
对人类决策时脑活动和决策理由的预测
如果只是知道会做出怎样的选择,而不知为何做选择,那距离一个能帮助心理学家了解人类的模型还相差甚远。因此,下一步是要说明“半人马”能够让心理学家知其然也知其所以然。为此,研究者选取 94 人,当其做决策的时候,通过 fMRI 功能核磁记录其活跃的脑区,并将其与“半人马”与未经微调的大模型 llama 的预测结果做对比,结果“半人马”的预测表现比 Llama 更优(图5)。
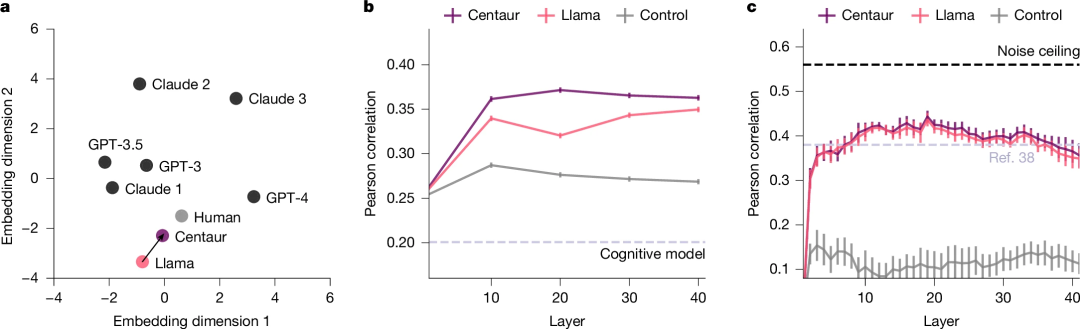
图5:相比 Llama,“半人马”预测决策时人类的脑区活跃程度的能力
除了解释机制,“半人马” 还可以模拟人类被试者开展心理学实验,进而得到对人类心理新的洞见。以前心理学家以前是招募一堆大学生去做问卷,费钱还费时间, 有了“半人马”,便可以将实验中的被试者由碳基替换成硅基。由大模型来充当被试者,实验人员只需要付电费就好。那这样做能不能得到有意义的洞见了?下面来看论文中给出的初级案例。
研究人员首先使用“半人马”模拟人类在多属性决策(multi-attribute decision-making)任务做出的选择,该任务中,被试者根据几个专家的估计进行决策,不同的专家有不同的置信度。“半人马“模型模拟人类,在各种场景下做出决策,之后将这些选择的案例集交给 Deepseek-R1,由Deepseek去总结人类决策依据的规则。
Deepseek-R1 通过分析“半人马”的决策行为发现,其选择时考虑的是如何让选择后的后悔值最小。这相当于使用半人马模型,指导Deepseek做出科学发现。之后研究者还发现,通过最小后悔原则这一启发式规则,对人类行为的预测准确性接近了“半人马”模型给出的预测,如图6所示。Deepseek总结的启发式规则的预测准确性与半人马模型的预测准确性两者准确性相当,说明总结出的规律是有意义的,能视为对人类行为模式的洞察。这就论证了未来或可以使用大模型来替代心理学实验中的人类被试者。
不过值得怀疑的是,Deepseek-R1 的训练数据集中有很大概率包含对多属性决策这一心理学研究的描述,也会提及最小后悔原则。因此,对上述实验的另一种解释是 Deepseek-R1 从对实验的描述中关联到最小后悔原则这一启发式方法,并非真正如人类心理学家那样在产生洞见。
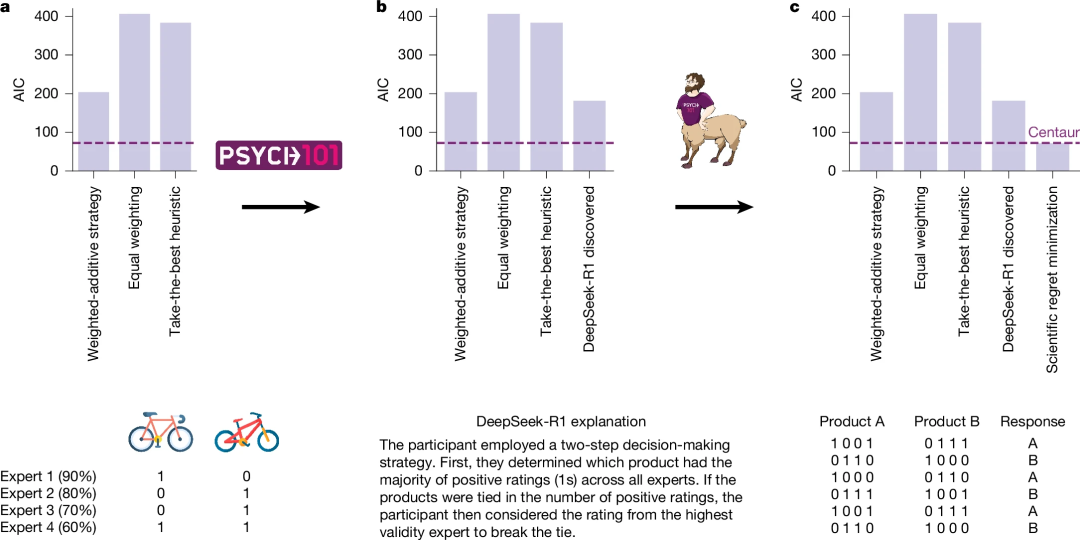
图6:模型引导的科学发现,a)使用 Psych-101 和 “半人马”来指导多属性决策研究的认知模型的开发。b)要求 DeepSeek-R1 生成对人类反应的解释,并将生成的语言策略形式化为正式的计算模型。c)以“半人马”为参考模型,通过科学的后悔最小化来完善该模型。
为何不能高估大模型在心理学中的应用潜力
为何不能高估大模型在心理学中的应用潜力
随着大模型能力变得越来越强,人们对大模型也开始了进行拟人化的描述,例如出现 AI 精神病学,应用心理学来考察大模型的心理状态,甚至Anthropic 还在给大模型招募“心理咨询师”(图7)。学术界对大模型的心理状态也有研究,例如[3]考察了 ChatGPT3.5,ChatGPT4o 和 ChatGPT4o mini后,发现 AI 在情绪波动、价值观形成等方面仍与人类存在较大差异。
图7:X截图,对应Anthropic 准备招募大模型精神病学研究,以促进模型可解释性
“半人马”的出现,也在反方向地将大模型与人类心理学联系起来。哈利波特中有一句话:“决定我们是谁的不是我们的能力,而是我们的选择。”通过让大模型表现的更像人类,“半人马”的开发者认为它有潜力显著增加未来的心理学研究的可能性,特别是对于那些认知测试可能很慢的场景,或很难招募的目标群体(例如儿童或有精神问题的对象)。
如果未来类似的模型能够包含更多样化的数据,不仅是来自受教育的西方被试者(常见于当前心理学实验),那未来的心理学实验,或可真如“半人马”作者指出的那样,在计算机而非人类被试者中完成。可能的应用还包括分析经典的心理学实验,研究临床环境中的个人决策过程,例如抑郁或焦虑。
但我们也不应该高估“半人马”的影响,2024年的一篇名为“在心理学研究中使用大模型的机遇和危险”的综述[4]中,指出用大模型代替心理研究中的人类被试者,存在着三个问题,首先是大模型的训练数据多来自受教育的西方人(心理学实验中常见的被试)。这一点“半人马”团队也提及,研究团队计划之后使用更多样的(来自不同文化,教育程度)行为数据对模型进行改进。其次是对大模型能否形成人类的道德体系存疑,这不同于预测人类在面对道德困境时的选择,而是要构建一个解释自己为何做出对应选择的认知架构,这一点“半人马”同样没有解决。
至于大模型替代人类心理学被试者的第三个困难,则是最为本质性的。作为一种被调整的要去符合人类偏好的概率模型。大模型无论怎么微调,回答心理学调查的问题时变化幅度较小,缺乏人类行为的多样性。更难以如斯坦福监狱实验,米尔格拉姆的服从实验那样,揭示人类在极端状况下的心理状态。而心理学能带给我们的,远远不止是我们在老虎机前会如何做选择。而是如积极心理学那样,研究那些主观幸福感最高的那些人是怎样思考的,而这些远离均值的特殊群体(例如犯罪心理学的研究对象),大模型或许永远难以准确地加以描述。
参考文献
[1] Binz, M., Akata, E., Bethge, M., Brändle, F., Callaway, F., Coda-Forno, J., Dayan, P., Demircan, C., Eckstein, M. K., Éltető, N., Griffiths, T. L., Haridi, S., Jagadish, A. K., Ji-An, L., Kipnis, A., Kumar, S., Ludwig, T., Mathony, M., Mattar, M., & Modirshanechi, A. (2025). A foundation model to predict and capture human cognition. Nature. https://doi.org/10.1038/s41586-025-09215-4
[2] Gandhi, K., Lynch, Z., Fränken, J.-P., Patterson, K., Wambu, S., Gerstenberg, T., Ong, D. C., & Goodman, N. D. (2024). Human-like Affective Cognition in Foundation Models. ArXiv.org. https://arxiv.org/abs/2409.11733
[3] Zhang, Y., Li, S., Yuan, X., Yuan, H., Che, Z., & Luo, S. (2025). The high-dimensional psychological profile of ChatGPT. Science China Technological Sciences, 68(8). https://doi.org/10.1007/s11431-025-2934-8
[4] Abdurahman, S., Atari, M., Farzan Karimi-Malekabadi, Xue, M. J., Trager, J., Park, P. S., Preni Golazizian, Omrani, A., & Dehghani, M. (2024). Perils and opportunities in using large language models in psychological research. PNAS Nexus, 3(7). https://doi.org/10.1093/pnasnexus/pgae245
作者:郭瑞东
审核:张江 北京师范大学系统科学学院教授
出品:中国科协科普部
监制:中国科学技术出版社有限公司、北京中科星河文化传媒有限公司

「大模型时代下的Agent建模与仿真」读书会
集智俱乐部联合山东工商学院副教授高德华、天津大学教授薛霄、北京师范大学教授张江、国防科技大学博士研究生曾利共同发起「大模型时代下的Agent建模与仿真」读书会。读书会自2025年7月8日开始,每周二晚上7:30-9:30进行,预计持续分享8周左右。扫码加入Agent建模与仿真的前沿探索之旅,一起共学、共创、共建、共享「大模型时代下的Agent建模与仿真」社区,共同畅想大模型时代人工社会的未来图景!
核心问题

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢