
当图像模型不断发展成熟,用户对于大模型的使用需求不再局限于单一的图像生成,也希望对现有图像进行更精细、更可控的修改。 「编辑」是比「生成」更细节、更微观的使用需求,传统图像编辑软件(如 Photoshop 等)存在一定的使用门槛,往往需要用户进行系统学习;而当前现有的图像编辑 AI 应用在功能和效果上均存在提升空间,尤其对文字的渲染和编辑能力仍有缺口。
基于此,阿里通义千问团队发布了全能图像编辑模型 Qwen-Image-Edit,通过语义与外观双重编辑能力,不仅能准确理解外观编辑的指令意图,还能进行高级视觉语义编辑,同时保持图像视觉风格的一致性。该模型还将 Qwen-Image 卓越的中文文本渲染能力延展至图像编辑领域,实现了对图片中文字的精准编辑。
作为 Qwen-Image 的全新版本,Qwen-Image-Edit 完善了从图像生成、链式编辑到最终效果呈现的能力闭环,大大提高了图像的可用性,在多个公开基准测试中的评估表明在图像编辑任务上具备 SOTA 性能。
目前,HyperAI 超神经官网已上线了「Qwen-Image-Edit:全能图像编辑模型 Demo」,快来试试吧~
在线使用:https://go.hyper.ai/nmjYo
8 月 18 日-8 月 22 日,hyper.ai 官网更新速览:
* 优质公共数据集:10 个
* 优质教程精选:4 个
* 本周论文推荐: 5 篇
* 社区文章解读:5 篇
* 热门百科词条:5 条
* 8 月截稿顶会:2 个
访问官网:hyper.ai
公共数据集精选
1. Granary 欧洲语音识别与翻译数据集
Granary 是由英伟达发布的一个大规模多语种语音数据集,旨在为多语种 ASR/AST 模型提供高质量训练与评测素材。该数据集包含约 100 万小时的高质量伪标记 ASR 语音数据,覆盖 25 种欧洲语言。
直接使用:https://go.hyper.ai/D3926
2. M3-Bench 长视频问答基准数据集
M3-Bench 是由字节跳动 Seed 团队发布的一个长视频问答基准数据集,旨在评测多模态智能体长时程记忆与推理能力。该数据集包含 1,020 段视频样本,每段样本包含字幕、中间产物、记忆图。
直接使用:https://go.hyper.ai/LIHsO
3. HiFiTTS-2 大规模高带宽语音数据集
HiFiTTS-2 是一个大规模高带宽语音数据集,旨在支持高质量零样本文本转语音(TTS)模型的训练与评测。该数据集包含来自 5k 名说话人的音频元数据,约 36,700 小时(22.05 kHz)与 31,700 小时(44.1 kHz)的英文语音录音,并按带宽质量与采样率进行分层组织。
直接使用:https://go.hyper.ai/XZwDD
4. CulturalGround 多语言文化视觉问答数据集
CulturalGround 是由卡耐基梅隆大学 NeuLab 发布的一个面向文化知识对齐的多语言多模态视觉问答数据集,旨在提升多模态大语言模型对小众文化实体与低资源语言的理解与推理能力。
直接使用:https://go.hyper.ai/wayAA
5. HPDv3 文生图人类偏好数据集
HPDv3 是由 MizzenAI 联合香港中文大学 MMLab 发布的首个广谱人类偏好数据集,相关论文并已入选 ICCV 2025 。该数据集面向文本到图像生成模型的对齐、重排与评测,旨在推动模型在贴近人类审美与提升语义一致性方面的进展。
直接使用:https://go.hyper.ai/xV8fK
6. COREVQA 视觉问答基准数据集
COREVQA 是由 Algoverse 人工智能研究中心发布的一个视觉问答基准数据集,旨在评估视觉语言模型(VLM)在 人群场景中的推理蕴含能力。数据以真实拥挤场景为主,强调遮挡、视角变化与背景干扰等难点,旨在推动 VLM 在复杂社会场景下的细粒度感知与推理能力。
直接使用:https://go.hyper.ai/tOFNw
7. DDOS 无人机深度与障碍物分割数据集
DDOS 是一个合成航拍图像数据集,旨在推进无人机自主技术中的算法研发。该数据集按环境类型进行了细致分类,训练集包含 300 次飞行,共 30k 张图像;验证集包含 20 次飞行,共 2k 张图像;测试集包含 20 次飞行,共 2k 张图像。
直接使用:https://go.hyper.ai/XRE6R

数据集示例
8. Nemotron 多领域推理数据集
Nemotron 是英伟达发布的一个多领域推理数据集,旨在提升 Llama 模型的推理效率与准确性。该数据集包含 2,566 万条样本,数据涵盖对话、代码、数学、 STEM 及工具调用五大类别。
直接使用:https://go.hyper.ai/WP2Ym
9. Document Haystack 多模态文档基准数据集
Document Haystack 是由 Amazon AGI 发布的一个多模态文档基准数据集,包含 400 份文档变体和 8,250 个检索问题,旨在评估视觉语言模型(VLM)在长上下文复杂文档中的信息检索与理解能力。
直接使用:https://go.hyper.ai/Q08Xt
10. CSEMOTIONS 情绪音频数据集
CSEMOTIONS 是一个情绪音频数据集,旨在支持可控性与自然语言语音生成领域的研究。该数据集包含约 10 小时的高质量音频数据,涵盖 10 位专业配音演员在平静、快乐、愤怒等七种情绪类别下的音频。
直接使用:https://go.hyper.ai/4fe7A
公共教程精选
1. vLLM + Open-WebUI 部署 Jan-v1-4B
Jan-v1-4B 是由 Jan 团队发布的 40 亿参数开源语言模型,定位于智能体式推理与工具调用,是 Jan 家族的首发版本并面向 Jan App 的实际工作流场景而优化。该模型以 Qwen3-4B-Thinking-2507 为基础继续微调与扩展,在 SimpleQA 基准上取得 91.1% 的准确率,显示出通过模型扩展与调优带来的明显性能提升。
在线运行:https://go.hyper.ai/CZf3s
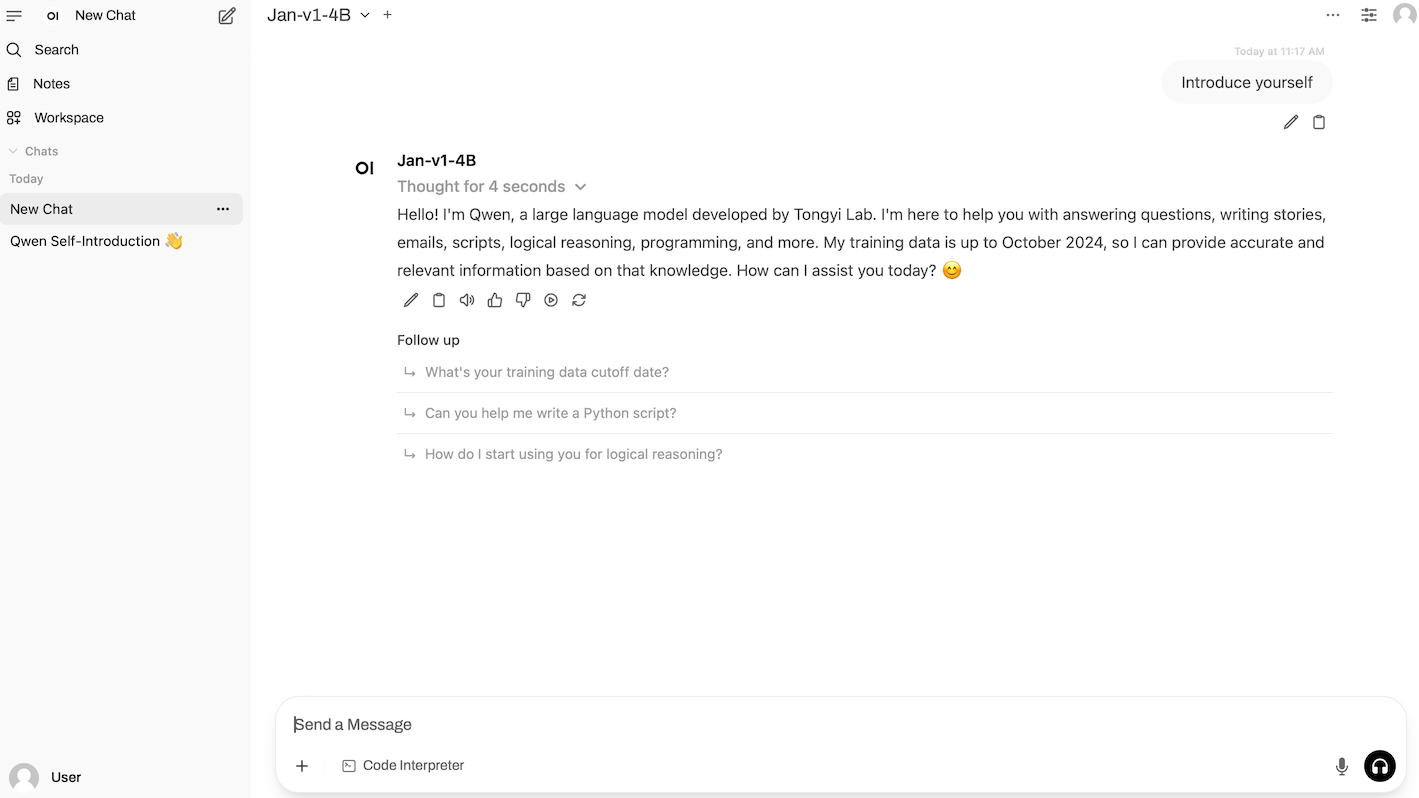
项目示例
2. 乳腺癌诊断数据集机器学习分类预测教程
该教程基于威斯康辛乳腺癌诊断数据集(WDBC),完整演示二分类问题的机器学习全流程。通过本教程有利于重点理解特征筛选、模型调优与结果可视化的核心逻辑,为其他疾病诊断建模提供参考。
在线运行:https://go.hyper.ai/zFjil
3. Qwen-Image-Edit:全能图像编辑模型 Demo
Qwen-Image-Edit 是由阿里巴巴通义千问团队发布的全能图像编辑模型。模型兼具语义与外观的双重编辑能力,支持中英文双语文字的精准编辑,支持在保留原有字体、字号和风格的前提下修改图片中的文字。
在线运行:https://go.hyper.ai/nmjYo

效果示例
4. 一键部署 Qwen3-4B-2507
Qwen3-4B-Thinking-2507 和 Qwen3-4B-Instruct-2507 是由阿里巴巴通义千问团队推出的大语言模型。性能方面,Qwen3-4B-Thinking-2507 在复杂问题推理能力、数学能力、代码能力以及多轮函数调用能力上的表现大幅领先 Qwen3 同尺寸小模型。在非推理领域,Qwen3-4B-Instruct-2507 在知识、推理、编程、对齐以及 agengt 能力上全面超越了闭源的小尺寸模型 GPT-4.1-nano,且与中等规模的 Qwen3-30B-A3B(non-thinking)性能接近。
在线运行:https://go.hyper.ai/HiqSR
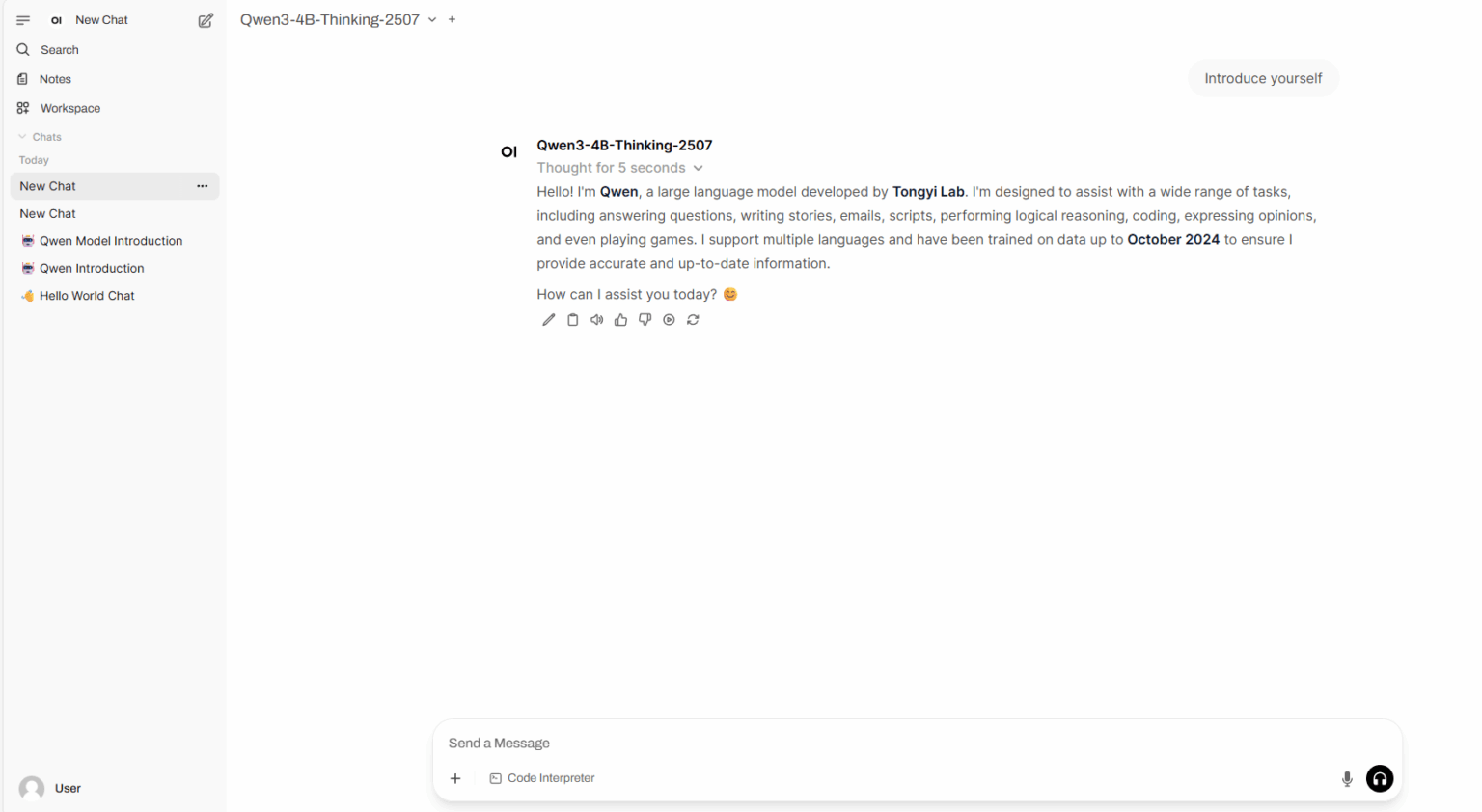
项目示例
💡我们还建立了 Stable Diffusion 教程交流群,欢迎小伙伴们扫码备注【SD 教程】,入群探讨各类技术问题、分享应用效果~

本周论文推荐
1. DINOv3
本技术报告介绍了 DINOv3,能够生成高质量的密集特征,在各类视觉任务中表现出色,显著优于以往的自监督与弱监督基础模型。同时研究人员还发布了 DINOv3 视觉模型系列,旨在通过提供可扩展的解决方案,应对多样化的资源约束与部署场景,推动各类任务与数据集上的技术水平全面提升。
论文链接:https://go.hyper.ai/tBuYx
2. Ovis2.5 Technical Report
本文提出了 Ovis2.5,作为 Ovis2 的继任者,专为原生分辨率视觉感知与强大的多模态推理而设计。 Ovis2.5 集成了一种原生分辨率视觉 Transformer,能够以图像的原始、可变分辨率直接处理图像,避免了固定分辨率分块带来的质量退化,同时完整保留了精细细节与全局布局。
论文链接:https://go.hyper.ai/jlEXl
3. SSRL: Self-Search Reinforcement Learning
研究人员研究了大型语言模型(LLMs)作为强化学习(RL)中智能体搜索任务高效模拟器的潜力,从而降低对昂贵外部搜索引擎交互的依赖。实证评估表明,经过 SSRL 训练的策略模型为搜索驱动的强化学习训练提供了一种成本低廉且稳定的环境,显著减少了对外部搜索引擎的依赖,并促进了从模拟到现实的鲁棒迁移。
论文链接:https://go.hyper.ai/4TFRe
4. Thyme: Think Beyond Images
由于目前尚无开源工作能够提供与专有模型相媲美的丰富功能集,本文在此方向上进行初步探索,提出 Thyme(Think Beyond Images),使多模态大语言模型(MLLMs)能够超越现有的「通过图像进行思考」方法,通过可执行代码自主生成并执行多种图像处理与计算操作。
论文链接:https://go.hyper.ai/ZhLMI
5. Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic RL
现有的大多数多智能体系统依赖于人工设计的提示或工作流工程,并构建在复杂的智能体框架之上,导致其计算效率低下、能力受限,且无法从以数据为中心的学习中获益。本研究提出了智能体链(Chain-of-Agents, CoA)这一全新的 LLM 推理范式,该范式能够在单一模型内部原生地实现端到端的复杂问题求解,其机制与多智能体系统一致。
论文链接:https://go.hyper.ai/5m3gV
更多 AI 前沿论文:https://go.hyper.ai/iSYSZ
社区文章解读
1. ACL 2025 丨牛津大学等提出医学 GraphRAG,刷新问答准确性记录,在 11 个数据集评测上达 SOTA
牛津大学等联合团队提出了一种专门面向医学领域的、基于图的 RAG 方法——医学 GraphRAG 。该方法通过生成循证回答和官方医学术语解释,有效提升了 LLM 在医学领域的表现。
查看完整报道:https://go.hyper.ai/3458z
2. 在线教程汇总丨 Qwen 连发 SOTA 级模型,覆盖文本渲染/视频创作/编程辅助
通义千问团队持续丰富其开源模型矩阵,锚定架构创新、效率提升和场景深耕三维突破,性能媲美行业巨头。 HyperAI 超神经官网「教程」板块已上线多个通义开源模型教程。
查看完整报道:https://go.hyper.ai/JKJTY
3. 康奈尔大学首创「微波大脑」芯片,同时处理超高速数据和无线通信信号,176 毫瓦功耗下准确率达 75%
康奈尔大学团队提出一种名为微波神经网络(Microwave Neural Network,MNN)的集成电路,可同时处理超高速数据和无线通信信号,其凭借低功耗、小体积优势,可为高带宽应用提供全新解决方案。
查看完整报道:https://go.hyper.ai/Cki2I
4. AI 助力高效生物制造,华东理工大学庄英萍教授深度解析智能生物制造技术体系与实践成果
在 2025 年上海交通大学 AI For Bioengineering 暑期学校中,来自华东理工大学的庄英萍教授围绕「AI 助力高效生物制造过程」展开分享,从生物制造与合成生物学的关系、合成生物学产品应用领域、智能生物制造技术及实践等三个方面介绍了技术体系和团队成果。
查看完整报道:https://go.hyper.ai/LgKcG
5. 一站式蛋白质零样本突变预测/功能预测,上海交大 VenusFactory 实现蛋白质工程全栈式开发
为推动人工智能在蛋白质工程领域的广泛应用,上海交通大学洪亮教授课题组开发了一站式开源的蛋白质工程工作台 VenusFactory,以整合生物数据检索、标准化任务基准测试和预训练蛋白质语言模型。
查看完整报道:https://go.hyper.ai/p3llU
热门百科词条精选
1. DALL-E
2. 倒数排序融合 RRF
3. 帕累托前沿 Pareto Front
4. 大规模多任务语言理解 MMLU
5. 对比学习 Contrastive Learning
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:https://go.hyper.ai/wiki

一站式追踪人工智能学术顶会:https://go.hyper.ai/event
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢