
随着大模型参数规模不断攀升,用户对于 AI 的使用需求逐渐分化:一方面需要高性能模型来处理复杂任务,另一方面也迫切希望在低算力环境下获得轻量、实用的对话体验。在长文本对话和日常任务场景中,传统大模型不仅需要高算力支持,还容易出现响应延迟、上下文丢失或生成不连贯的问题,使得「能用、好用、跑得动」的轻量模型成为亟需解决的痛点。
基于此,Google 推出了轻量级指令微调模型 Gemma-3-270M-IT,仅有 2.7 亿参数,却能在单卡 1GB 显存环境下流畅运行,显著降低了本地部署的门槛。同时,它支持 32K tokens 上下文窗口,使其能够胜任长文本对话和文档处理任务。通过针对日常问答与简单任务的专项微调,Gemma-3-270M-IT 既保持了轻量化的高效运行,又兼顾了对话交互的实用性。
Gemma-3-270M-IT 展示了另一种发展路径:在「更大更强」的浪潮之外,通过轻量化与长上下文支持,为边缘部署与普惠应用提供新的可能性。
目前,HyperAI超神经官网已上线了「vLLM + Open WebUI 部署 gemma-3-270m-it」,快来试试吧~
在线使用:https://go.hyper.ai/kBjw3
8 月 25 日-8 月 29 日,hyper.ai 官网更新速览:
* 优质公共数据集:12 个
* 优质教程精选:4 个
* 本周论文推荐: 5 篇
* 社区文章解读:6 篇
* 热门百科词条:5 条
* 9 月截稿顶会:5 个
访问官网:hyper.ai
公共数据集精选
1. Nemotron-Post-Training-Dataset-v2 后训练数据集
Nemotron-Post-Training-Dataset-v2 是英伟达基于既有后训练语料扩展推出的版本。该数据集将 SFT 与 RL 数据扩展到五种目标语言(西/法/德/意/日),覆盖数学、代码、 STEM(科学、技术、工程和数学)、对话等场景。
直接使用:https://go.hyper.ai/lSIjR
2. Nemotron-CC-v2 预训练数据集
Nemotron-CC-v2 在原有英文网页语料基础上,新增了 2024–2025 年的 8 个 Common Crawl 快照,并进行全局去重与英文过滤;同时使用 Qwen3-30B-A3B 对网页内容进行合成重述,并补充多样化问答,进一步翻译到 15 种语言,用于强化多语言逻辑推理与通用知识预训练。
直接使用:https://go.hyper.ai/xRtbR
3.Nemotron-Pretraining-Dataset-sample 采样数据集
Nemotron-Pretraining-Dataset-sample 包含从完整的 SFT 与预训练语料的不同组成部分中选取的 10 个代表性子集,内容涵盖高质量问答数据、专注于数学领域的提取内容、代码元数据及 SFT 风格指令数据,适用于检阅和快速实验。
直接使用:https://go.hyper.ai/xzwY5
4. Nemotron-Pretraining-Code-v1 代码数据集
Nemotron-Pretraining-Code-v1 是基于 GitHub 构建的精选大规模代码数据集。该数据集经过多阶段去重、许可证强制执行和启发式质量检查过滤,包含 11 种编程语言的 LLM 生成代码问答对。
直接使用:https://go.hyper.ai/DRWAw
5. Nemotron-Pretraining-SFT-v1 监督式微调数据集
Nemotron-Pretraining-SFT-v1 面向 STEM、学术、逻辑推理与多语言场景,由高质量数学和科学素材扩展生成,并结合研究生层级的学术文本与已指令微调的 SFT 数据,构造出复杂多选题与解析题(含完整解答/思路),覆盖数学、代码、通识与逻辑推理等多类任务。
直接使用:https://go.hyper.ai/g568w
6. Nemotron-CC-Math 数学预训练数据集
Nemotron-CC-Math 是一个以数学为重点的高质量大规模预训练数据集。该数据集包含 1,330 亿 Token,在保留方程与代码版式结构的同时,将数学内容统一为可编辑的 LaTeX 格式,首次在 Web 规模上可靠覆盖多种(含长尾)数学格式。
直接使用:https://go.hyper.ai/aEGc4
7. Echo-4o-Image 合成图像生成数据集
Echo-4o-Image 数据集由 GPT-4o 生成,包含约 17.9 万条样本,涵盖 3 种不同的任务类型:复杂指令执行(约 6.8 万);超现实幻想生成(约 3.8 万);多参考图像生成(约 7.3 万)。每条样本为 2×2 图像格,分辨率为 1024×1024,包含图像路径、特征(属性/主体)与生成 prompt 的结构化信息。
直接使用:https://go.hyper.ai/uLJEh

数据集示例
8. We-Math2.0-Standard 视觉数学推理基准数据集
We-Math2.0-Standard 围绕 1,819 条精定义的知识原理建立统一标签空间,对每道题进行显式原理标注与严格策展,从而在整体上实现广泛且均衡的覆盖,特别补强以往代表性不足的数学子领域与题型。数据集采用双重扩展设计,每题多图和每图多题。
直接使用:https://go.hyper.ai/VlqK1

数据集概览
9. AgentNet 桌面操作任务数据集
AgentNet 是首个大规模桌面计算机使用智能体轨迹数据集,旨在支持与评测跨平台的 GUI 操作智能体与视觉-语言-动作模型。数据集包含 22.6K 条人工标注的电脑使用任务轨迹,覆盖 Windows / macOS / Ubuntu 三大系统与 200+ 个应用/网站,场景涉及办公、专业、日常、系统四类。
直接使用:https://go.hyper.ai/3DGDs
10. WideSearch 信息搜集基准数据集
WideSearch 是首个专为「广域信息搜集」设计的智能体评测基准数据集。该基准包含研究团队从真实用户查询中精心挑选并手工清洗出 200 个高质量问题(100 个英文问题、 100 个中文问题),这些问题来自 15 个以上的不同领域。
直接使用:https://go.hyper.ai/36kKj
11. MCD 多模态代码生成数据集
MCD 包含总计约 59.8 万条/对高质量样本,以指令跟随格式组织,覆盖多种输入模态(文本、图像、代码)与输出模态(代码、答案、解释),适用于多模态代码理解与生成任务。数据包含:增强型 HTML 代码、图表、问答、算法。
直接使用:https://go.hyper.ai/yMPeD
12. Llama-Nemotron-Post-Training-Dataset 后训练数据集
Llama-Nemotron-Post-Training-Dataset 是一个大规模后训练数据集,旨在提升 Llama-Nemotron 系列模型在后训练阶段(如 SFT 、 RL)的数学、代码、通用推理与指令跟随等能力。该数据集整合了监督式微调与强化学习阶段的数据。
直接使用:https://go.hyper.ai/Vk0Pk
公共教程精选
1. 微软 VibeVoice-1.5B 重新定义 TTS 技术边界
VibeVoice-1.5B 是新型文本到语音(TTS)模型,能生成富有表现力、长篇幅、多说话者的对话式音频,如播客。VibeVoice 能够在保持高保真度的同时高效处理长序列音频,并支持合成长达 90 分钟的语音,最多可包含 4 位不同说话者。
在线运行:https://go.hyper.ai/Ofjb1
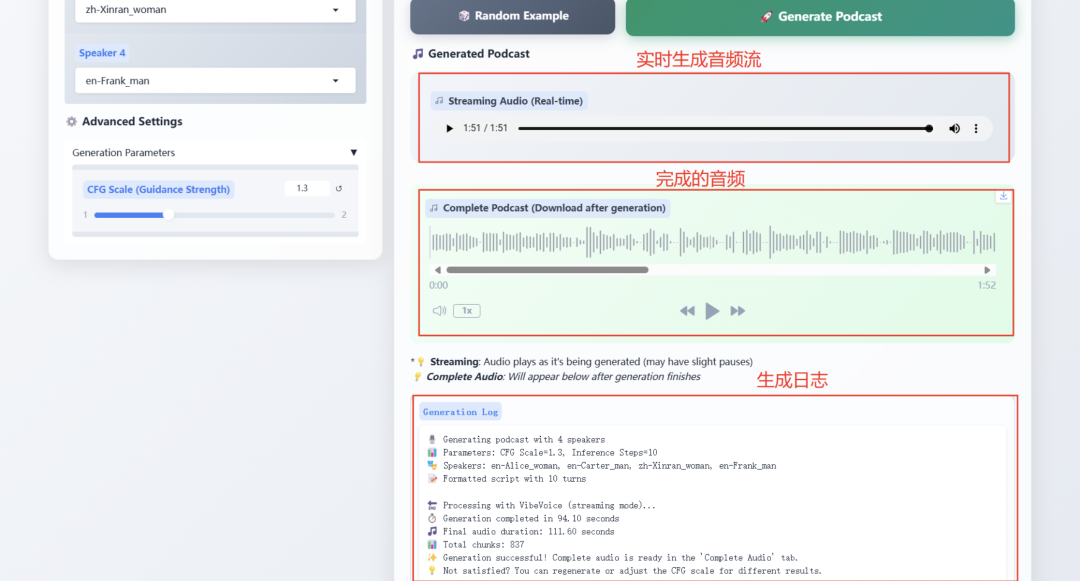
项目示例
2. vLLM + Open WebUI 部署 NVIDIA-Nemotron-Nano-9B-v2
NVIDIA-Nemotron-Nano-9B-v2 创新性融合 Mamba 高效长序列处理和 Transformer 强语义建模的能力,仅以 90 亿(9B)参数就实现了 128K 超长上下文支持,在边缘计算设备(如 RTX 4090 级 GPU)上的推理效率与任务性能,可对标同参数规模的前沿模型。
在线运行:https://go.hyper.ai/cVzPp
3. vLLM + Open WebUI 部署 gemma-3-270m-it
gemma-3-270m-it 基于 270M(2.7 亿)参数构建,专注于高效对话交互与轻量化部署。该模型轻量高效,仅需单卡 1GB + 显存即可运行,适合边缘设备与低资源场景。模型支持多轮对话,针对日常问答、简单任务指令进行专项微调;专注文本生成与理解,且支持 32k tokens 上下文窗口,可处理长文本对话。
在线运行:https://go.hyper.ai/kBjw3
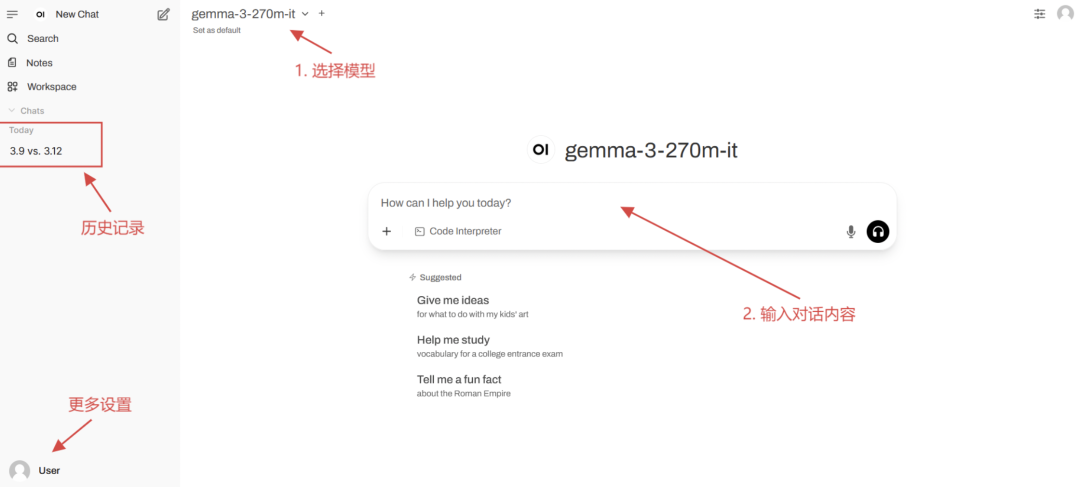
项目示例
4. vLLM+Open WebUI 部署 Seed-OSS-36B-Instruct
Seed-OSS-36B-Instruct 使用了 12 万亿(12 T)tokens 进行训练,并在多个主流开源基准测试中取得了出色的表现。其最具代表性的特性之一是原生长上下文能力,最大上下文长度可达 512k tokens,能够在不损失性能的情况下处理超长文档和推理链。这一长度是 OpenAI 最新 GPT-5 模型系列的两倍,大约相当于 1600 页文本。
在线运行:https://go.hyper.ai/aKw9w

项目示例
💡我们还建立了 Stable Diffusion 教程交流群,欢迎小伙伴们扫码备注【SD教程】,入群探讨各类技术问题、分享应用效果~

本周论文推荐
1. Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVR
本文提出一种自博弈变分问题合成策略,用于改进大语言模型的 可验证奖励强化学习。传统 RLVR 虽能提升 Pass@1,但因熵塌缩导致生成多样性下降,限制了 Pass@k 表现。SvS 通过基于正确解合成等价变分问题,缓解熵塌缩,维持训练多样性。
论文链接:https://go.hyper.ai/IU71P
2. Memento: Fine-tuning LLM Agents without Fine-tuning LLMs
本文提出了一种适应性大语言模型智能体的新型学习范式,该方法无需对底层 LLM 进行微调。现有方法往往存在两种局限:要么过于僵化,要么计算开销巨大。研究团队通过基于记忆的在线强化学习实现了低成本的持续适应,将这一过程形式化为记忆增强型马尔可夫决策过程(M-MDP),并引入神经案例选择策略来指导动作决策。
论文链接:https://go.hyper.ai/sl9Yj
3. TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling
本文提出了 TreePO,一种自引导的 rollout 算法,它将序列生成过程视为树状搜索过程。TreePO 由动态树采样策略和定长片段解码组成,利用局部不确定性来生成额外分支。通过在公共前缀上摊销计算开销,并在早期剪枝低价值路径,TreePO 在保持或增强探索多样性的同时,有效降低了每次更新的计算负担。
论文链接:https://go.hyper.ai/J8tKk
4. VibeVoice Technical Report
本文提出了一种新型语音合成模型 VibeVoice ,基于 next-token diffusion 可生成多说话人长篇语音。其提出的连续语音分词器相比 Encodec 压缩率提升 80 倍,在保证音质的同时大幅提高长序列处理效率。模型支持在 64k 上下文内合成长达 90 分钟、最多 4 人 的对话语音,真实还原交流氛围,并超越现有开源与商业模型。
论文链接:https://go.hyper.ai/pokVi
5. CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
本文提出了 CMPhysBench,这是一个用于评估大语言模型在凝聚态物理领域能力的新型基准。CMPhysBench 由 520 多道研究生水平的精心整理的问题组成,涵盖了凝聚态物理的代表性子领域和基础理论框架,例如磁学、超导、强关联系统等。
论文链接:https://go.hyper.ai/uo8de
更多 AI 前沿论文:https://go.hyper.ai/iSYSZ
社区文章解读
1. 以结构/序列/功能之间的关系重新定义蛋白质语言模型的分类:李明辰博士详解蛋白质语言模型
在上海交通大学主办的第三届「AI for Bioengineering 暑期学校」中,上海交通大学自然科学研究院洪亮课题组博士后李明辰以「蛋白质与基因组基础大模型」为主题,向大家分享了蛋白质与基因组基础大模型的最新研究进展和技术突破。
查看完整报道:https://go.hyper.ai/Ynjdj
2. 推理速度快50倍,MIT团队提出FASTSOLV模型,实现任意温度下的小分子溶解度预测
麻省理工学院研究团队结合化学信息学工具与全新有机溶解度数据库 BigSolDB,在 FASTPROP 与 CHEMPROP 模型架构的基础上进行了改进,使模型能够同时输入溶质分子、溶剂分子及温度参数,直接对 logS 进行回归训练。在严格的溶质外推场景下,相较 Vermeire 等人的 SOTA 模型,优化后模型的 RMSE 降低了 2–3 倍,推理速度提升最高达 50 倍。
查看完整报道:https://go.hyper.ai/cj9RX
3. 售价3499美元,英伟达Jetson Thor实现机器人与物理世界的实时智能交互
英伟达宣布 Jetson AGX Thor 开发套件正式上市,起售价 3499 美元,量产模块 Thor T5000 也已面向企业客户开放供应。 Jetson AGX Thor 被称为「机器人大脑」,目标是赋能制造、物流、交通、医疗、农业、零售等行业的数百万台机器人。
查看完整报道:https://go.hyper.ai/1XLXn
4. 多模态模型加速新材料与工业应用匹配,无需完整晶体结构即可预测材料性质
加拿大多伦多大学化学工程与应用化学系的研究团队,提出了一种多模态机器学习方法,该方法利用 MOFs 合成后即可获得的信息:PXRD 和合成中使用的化学物质,识别出了那些在与最初报道的应用不同的领域具有潜力的 MOFs,该研究加速了 MOFs 的合成与应用场景的连接。
查看完整报道:https://go.hyper.ai/cqX1t
5. 提升科学数据可用性,中科院张正德团队提出基于智能体的 AI-Ready 数据加工和供给方案
在 2025CCF 全国高性能计算学术大会上,高能物理研究所计算中心 AI4S 负责人张正德研究员,从目前大装置科学数据状态出发,系统阐述了针对数据的高效、高质量 AI-Ready 化构建方案,以及智能体和多智能体框架在数据标注和供给的应用。
查看完整报道:https://go.hyper.ai/u7F9L
热门百科词条精选
1. DALL-E
2. 倒数排序融合 RRF
3. 帕累托前沿 Pareto Front
4. 大规模多任务语言理解 MMLU
5. 对比学习 Contrastive Learning
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
https://go.hyper.ai/wiki
9 月截稿顶会
9 月 2 日
7:59:59
VLDB 2026
9 月 2 日
19:59:59
PPoPP 2026
9 月 4 日
19:59:59
MobiCom 2026
9 月 12 日
19:59:59
ESEC / FSE 2026
9 月 12 日
19:59:59
CHI 2026
一站式追踪人工智能学术顶会:https://go.hyper.ai/event

以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!
关于 HyperAI超神经 (hyper.ai)
HyperAI超神经 (hyper.ai) 是国内领先的人工智能及高性能计算社区,致力于成为国内数据科学领域的基础设施,为国内开发者提供丰富、优质的公共资源,截至目前已经:
* 为 1800+ 公开数据集提供国内加速下载节点
* 收录 600+ 经典及流行在线教程
* 解读 200+ AI4Science 论文案例
* 支持 600+ 相关词条查询
* 托管国内首个完整的 Apache TVM 中文文档
访问官网开启学习之旅:
https://hyper.ai/





内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢