
AI技术已取得飞速发展,而大语言模型(LLM)正在引领这场技术革命。本书基于MLOps最佳实践,提供了在实际场景中设计、训练和部署LLM的原理与实践内容。本书将指导读者构建一个兼具成本效益、可扩展且模块化的LLM Twin系统,突破传统Jupyter Notebook演示的局限,着重讲解如何构建生产级的端到端LLM系统。
本书涵盖数据工程、有监督微调和部署的相关知识,通过手把手地带领读者构建LLM Twin项目,帮助读者将MLOps的原则和组件应用于实际项目。同时,本书还涉及推理优化、偏好对齐和实时数据处理等进阶内容,是那些希望在项目中应用LLM的读者的重要学习资源。
阅读本书,读者将熟练掌握如何部署强大的LLM—既能解决实际问题,又能具备低延迟和高可用的推理能力。无论是AI领域的新手还是经验丰富的从业者,本书提供的深入的理论知识和实用的技巧,都将加深读者对LLM的理解,并提升读者在真实场景中应用它们的能力。
本书旨在确保尽可能多的人不仅能使用大语言模型(LLMs),还能对其进行调整、微调和量化优化,最终使其达到可部署于现实场景的高效状态。
——Julien Chaumond,Hugging Face首席技术官兼联合创始人
本书为任何希望深入掌握大语言模型实践技能的人士提供了无价指南。
——Antonio Gulli,谷歌高级总监

年份:2025
出版社:人民邮电出版社、异步图书
书籍汇总:
链接: https://pan.baidu.com/s/1FFw_24YdJIUfLGunRGT_7g?pwd=9at9
链接: https://pan.baidu.com/s/1wp1sxh_p5Cv9dI5OpBaSCg?pwd=2arp

在留言区参与互动发送(我想要一本赠书)
并点击转发朋友圈,邀好友助力点赞你的留言
我们将选点赞率最高的1名读者获得赠书1本
时间以公众号推文发出24小时为限
记得扫码加号主微信,以便联系邮寄地址哦

关注我们丨文末赠书
谷歌云在其Next 2025大会上宣布了众多真实世界的生成式AI应用案例,这一举措彰显了AI工程化从概念落地迈向跨行业、跨职能的规模化生产部署的显著进展。这些案例广泛覆盖金融、零售、医疗保健等十余个主要行业,并依据行业特性和AI智能体类型系统分类,构建出清晰的应用图谱,体现了AI工程化在不同领域的深度融合与定制化开发。
例如,在金融服务领域,AI工程化助力实现实时欺诈检测、客户服务革新、银行任务自动化及信贷审批加速;在零售行业,则通过AI工程化提升个性化购物体验、优化库存与需求预测、自动化生成产品描述,并通过AI智能体提供专家级购物指导;在医疗保健领域,AI工程化加速了药物发现进程、实现了个性化患者监护、优化了临床文档工作流程,并通过海量数据分析辅助医疗诊断,全面推动了医疗行业的智能化升级。
同时,当前的软件开发岗位正经历从“代码实现者”向“AI系统构建者”的范式转变,在ACL(国际计算语言学协会年会)这一自然语言处理领域的顶级学术盛会上,AI对软件开发岗位的重塑效应得到了充分展现。会议聚焦LLM(大语言模型)工程化实践,通过展示从学术研究到工业落地的完整转化路径,揭示了生成式AI技术如何驱动传统软件开发向AI原生领域深度延伸。
例如,基于Hugging Face生态的模型部署方案、RAG(检索增强生成)技术优化,以及偏好对齐微调等前沿议题,不仅要求开发者掌握LLM全生命周期管理能力,更推动其构建从数据采集、模型训练到推理优化的端到端工程化思维。
这些讨论印证了软件开发岗位正从单一编码转向AI系统架构设计,需要从业者同步精进提示工程、模型评估及MLOps(机器学习运维)实践等跨领域能力,以适应生成式AI时代的岗位转型需求。
因此,在数字化浪潮席卷各行业、智能化需求井喷式增长的背景下,LLM技术已成为企业数字化转型、业务智能化升级的关键驱动力,从互联网科技巨头到传统行业领军企业,都在积极布局应用LLM,催生出算法研发、工程落地、产品创新等多元岗位需求,且岗位薪资水平高、晋升空间大、跨界融合机会多,从业者既可投身前沿技术研究以推动技术边界拓展,也可深入行业应用以赋能千行百业,职业成长性与发展潜力均十分突出。
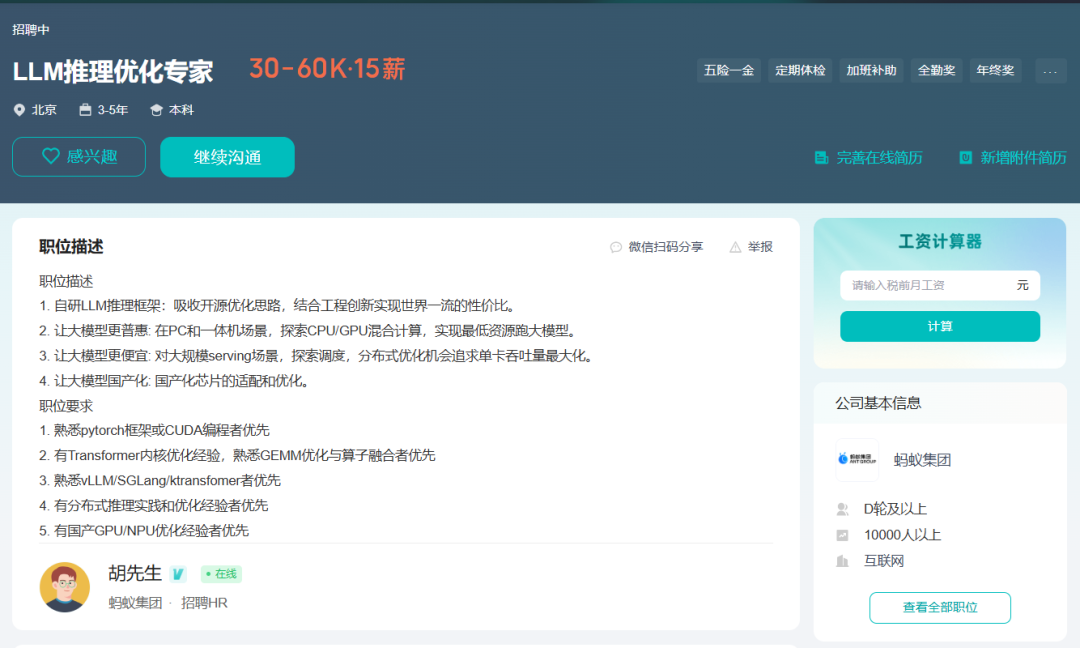
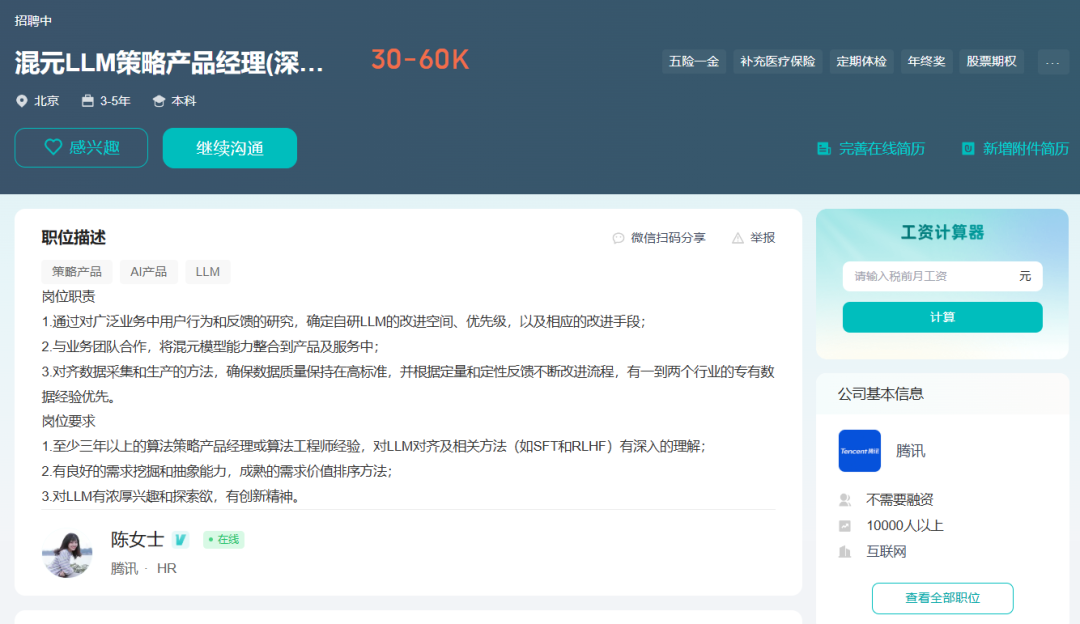
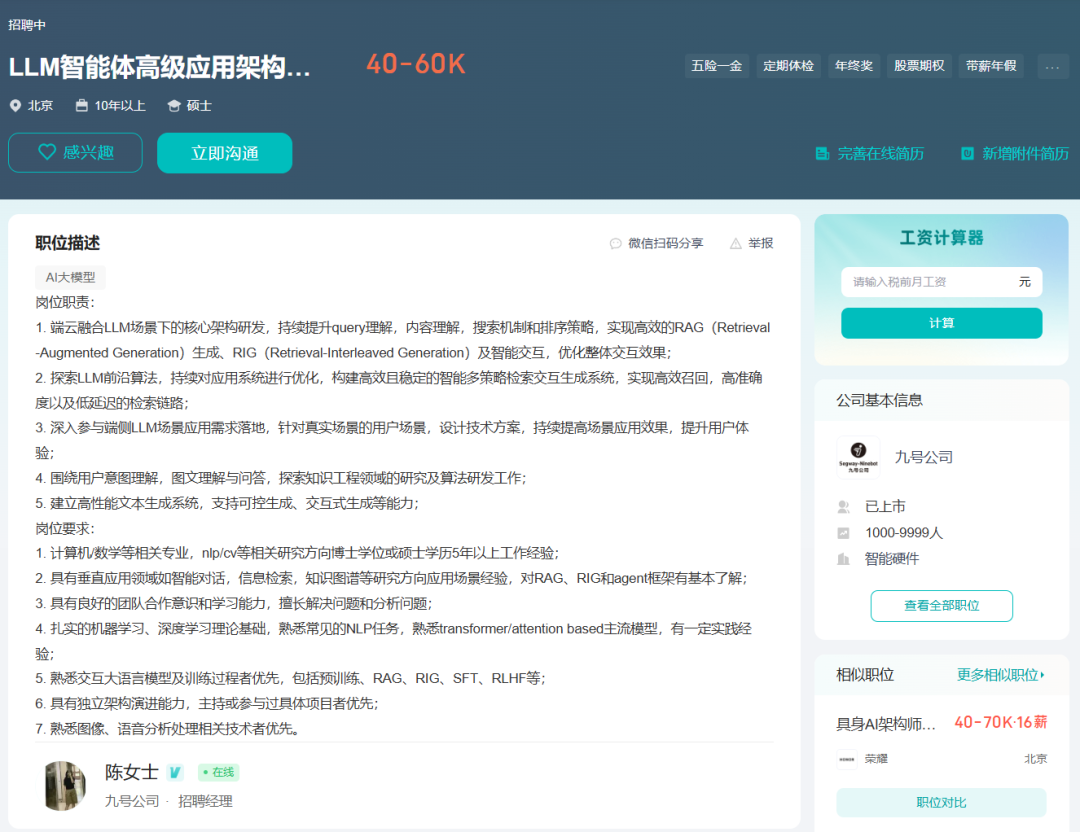
对于渴望深入学习LLM技术,并在实际工作中大展身手的人来说,一本全面、实用的指导书籍至关重要。《大语言模型工程师手册:从概念到生产实践》正是这样一本不可多得的佳作。

《大语言模型工程师手册:从概念到生产实践》英文原书上市后受到一众好评,美亚评分4.5分。这本书深入浅出,从基础概念讲起,带领你逐步了解LLM技术的原理和发展脉络。
它不仅涵盖了数据准备、模型选择与设计、训练与调优等关键环节,还详细介绍了如何在AWS上部署高级LLM和RAG应用程序,以及如何利用LLMOps最佳实践来确保模型在生产环境中稳定运行。书中通过丰富的实践示例,让你能够亲自动手,在实践中深化对LLM技术的理解和掌握。

▼点击下方,即可购书
《大语言模型工程师手册:从概念到生产实践》由资深机器学习工程师保罗·尤斯廷与Liquid AI后训练负责人马克西姆·拉博纳共同撰写。
保罗·尤斯廷在生成式AI、计算机视觉和MLOps领域有超7年实战经验,曾任职多家企业并推动大型神经网络生产落地,现作为DecodingML创始人搭建专业机器学习教育平台;
马克西姆·拉博纳拥有巴黎理工学院机器学习博士学位及谷歌AI/ML开发者专家认证,是开源社区活跃贡献者,在GitHub上开设课程、开发工具并创建了多个前沿模型。


▲保罗·尤斯廷(Paul Iusztin) 马克西姆·拉博纳(Maxime Labonne)
这本书的译者是腾讯云技术专家孟凡杰和清华大学计算机系博士方佳瑞。两位译者凭借各自在AI技术领域的深厚造诣,强强联合,以严谨的态度和专业的素养对原著进行了精准翻译。
他们不仅确保了技术术语准确无误,还充分考虑了中文读者的阅读习惯和知识背景,既保留了原著的专业性和权威性,又具有很高的可读性,为广大AI技术爱好者和从业者提供了优质的学习资源。
零基础友好:开启大型语言模型学习之旅
在人工智能蓬勃发展的当下,LLM无疑是备受瞩目的前沿技术。然而,对于众多零基础的爱好者而言,想要踏入这个领域却常常感到无从下手,本书的出现为零基础学习者打开了一扇通往LLM世界的大门。
本书从Python环境配置这一基础环节入手,详细讲解每一个步骤,即使你没有任何AI经验,也能轻松跟上节奏。随后,逐步引导你完成AWS云端部署,让你无须前置AI经验,就能将LLM部署到实际环境中,真正实现从理论到实践的跨越。

真实项目驱动:打通LLM全链路
本书以真实项目——LLM Twin(克隆写作风格的AI系统)为驱动,带你完整地经历数据工程、微调、部署的全链路过程。通过这个项目,你不仅能深入理解LLM的各个技术环节,还能掌握如何将它们有机结合起来,构建一个具有实际应用价值的AI系统。这种以项目为导向的学习方式,可以让你在实践中积累经验,真正做到学以致用。


MLOps工业级实践:
打造可复现、可监控的系统
MLOps是确保机器学习模型在生产环境中稳定、高效运行的关键。本书深入介绍了MLOps的核心概念和实践方法,并集成Hugging Face、ZenML、Comet ML等先进的工具链,帮助你打造可复现、可监控的生产级系统。无论是RAG优化、DPO偏好对齐,还是模型量化、实时推理等企业级应用痛点,书中都进行了详细的讲解和实战演示,让你能够轻松应对各种挑战。

前沿技术全覆盖:紧跟行业发展步伐
LLM技术更新换代迅速,本书紧跟行业发展步伐,全面覆盖了当前的前沿技术。从多模态数据处理到大规模预训练模型的优化,从模型压缩到边缘计算中的应用,书中都进行了深入的探讨和实践。通过学习本书,你将掌握最前沿的LLM技术,为未来的职业发展打下坚实的基础。

配套资源丰富:自学无忧
为了帮助你更好地学习和掌握LLM技术,本书配备了丰富的配套资源。书中不仅有详细的配套视频教程,可以让你通过生动形象的讲解和实际操作演示,轻松理解复杂的技术概念;
还有源码和拓展资料,让你可以在实践中进一步巩固所学知识,拓展自己的技术视野。有了这些丰富的配套资源,你就能轻松自学并掌握LLM技术。
无论你是零基础的AI爱好者,还是希望提升自己技术水平的从业者,本书都是你学习LLM的最佳选择。它将带你从零开始,逐步掌握LLM的核心技术和应用方法,开启你的AI进阶之路。
立即行动,开启你的LLM工程化之旅!
随着技术的不断进步和应用场景的持续拓展,LLM技术将在全球科技公司的推动下迎来更加广阔的发展前景。从智能家居到自动驾驶,从医疗健康到金融服务,LLM技术将深刻改变我们的生活方式,为人类社会带来一个更加智能、高效的未来。
《大语言模型工程师手册:从概念到生产实践》不仅是一本技术手册,更是一本引领你走进LLM世界的宝典。通过学习本书,你将能够全面掌握LLM的设计、训练、优化及部署等关键技能,为未来的AI项目开发打下坚实基础。
同时,结合当下最新的技术趋势和环境变化,本书也为你提供了前瞻性的思考和探索方向。在未来的AI领域,LLM必将发挥更加重要的作用,而掌握LLM技术的工程师也将成为推动这一进程的中坚力量。
不要错过这个提升自我、拥抱AI未来的绝佳机会!立即购买《大语言模型工程师手册:从概念到生产实践》,开启你的LLM工程化学习之旅吧!让我们一起,用代码创造未来,用AI改变世界!
【目录】
第 1章 理解LLM Twin的概念与架构 1
1.1 理解LLM Twin的概念 1
1.1.1 什么是LLM Twin 2
1.1.2 为什么构建LLM Twin 3
1.1.3 为什么不使用ChatGPT(或其他类似的聊天机器人) 4
1.2 规划LLM Twin的MVP 5
1.2.1 什么是MVP 5
1.2.2 定义LLM Twin的MVP 5
1.3 基于特征、训练和推理流水线构建机器学习系统 6
1.3.1 构建生产级机器学习系统的挑战 6
1.3.2 以往解决方案的问题 8
1.3.3 解决方案:机器学习系统的流水线 10
1.3.4 FTI流水线的优势 11
1.4 设计LLM Twin的系统架构 12
1.4.1 列出LLM Twin架构的技术细节 12
1.4.2 使用FTI流水线设计LLM Twin架构 13
1.4.3 关于FTI流水线架构和LLM Twin架构的最终思考 17
1.5 小结 18
第 2章 工具与安装 19
2.1 Python生态环境与项目安装 20
2.1.1 Poetry:Python项目依赖与环境管理利器 21
2.1.2 Poe the Poet:Python 项目任务管理神器 22
2.2 MLOps与MLOps工具生态 23
2.2.1 Hugging Face:模型仓库 23
2.2.2 ZenML:编排、工件和元数据 24
2.2.3 Comet ML:实验跟踪工具 33
2.2.4 Opik:提示监控 34
2.3 用于存储NoSQL和向量数据的数据库 35
2.3.1 MongoDB:NoSQL数据库 35
2.3.2 Qdrant:向量数据库 35
2.4 为AWS做准备 36
2.4.1 设置AWS账户、访问密钥和CLI 36
2.4.2 SageMaker:训练与推理计算 37
2.5 小结 39
第3章 数据工程 40
3.1 设计LLM Twin的数据采集流水线 41
3.1.1 实现LLM Twin数据采集流水线 44
3.1.2 ZenML流水线及其步骤 44
3.1.3 分发器:实例化正确的爬虫 48
3.1.4 爬虫 50
3.1.5 NoSQL数据仓库文档 59
3.2 采集原始数据并存储到数据仓库 67
3.3 小结 71
第4章 RAG特征流水线 73
4.1 理解RAG 73
4.1.1 为什么使用RAG 74
4.1.2 基础RAG框架 75
4.1.3 什么是嵌入 78
4.1.4 关于向量数据库的更多内容 84
4.2 高级RAG技术概览 86
4.2.1 预检索 87
4.2.2 检索 90
4.2.3 后检索 91
4.3 探索LLM Twin的RAG特征流水线架构 93
4.3.1 待解决的问题 93
4.3.2 特征存储 94
4.3.3 原始数据从何而来 94
4.3.4 设计RAG特征流水线架构 94
4.4 实现LLM Twin的RAG特征流水线 101
4.4.1 配置管理 101
4.4.2 ZenML流水线与步骤 102
4.4.3 Pydantic领域实体 109
4.4.4 分发器层 116
4.4.5 处理器 117
4.5 小结 125
第5章 监督微调 127
5.1 构建指令训练数据集 127
5.1.1 构建指令数据集的通用框架 128
5.1.2 数据管理 130
5.1.3 基于规则的过滤 131
5.1.4 数据去重 132
5.1.5 数据净化 133
5.1.6 数据质量评估 133
5.1.7 数据探索 136
5.1.8 数据生成 138
5.1.9 数据增强 139
5.2 构建自定义指令数据集 140
5.3 探索SFT及其关键技术 148
5.3.1 何时进行微调 148
5.3.2 指令数据集格式 149
5.3.3 聊天模板 150
5.3.4 参数高效微调技术 151
5.3.5 训练参数 155
5.4 微调技术实践 158
5.5 小结 164
第6章 偏好对齐微调 165
6.1 理解偏好数据集 165
6.1.1 偏好数据 166
6.1.2 数据生成与评估 168
6.2 构建个性化偏好数据集 171
6.3 偏好对齐 177
6.3.1 基于人类反馈的强化学习 178
6.3.2 DPO 179
6.4 实践DPO 181
6.5 小结 187
第7章 LLM的评估方法 188
7.1 模型能力评估 188
7.1.1 机器学习与LLM评估的对比 188
7.1.2 通用LLM评估 189
7.1.3 领域特定LLM评估 191
7.1.4 任务特定LLM评估 193
7.2 RAG系统的评估 195
7.2.1 Ragas 196
7.2.2 ARES 197
7.3 TwinLlama-3.1-8B模型评估 198
7.3.1 生成答案 199
7.3.2 答案评估 200
7.3.3 结果分析 204
7.4 小结 207
第8章 模型推理性能优化 208
8.1 模型优化方法 208
8.1.1 KV cache 209
8.1.2 连续批处理 211
8.1.3 投机解码 212
8.1.4 优化的注意力机制 214
8.2 模型并行化 215
8.2.1 数据并行 215
8.2.2 流水线并行 216
8.2.3 张量并行 217
8.2.4 组合使用并行化方法 218
8.3 模型量化 219
8.3.1 量化简介 219
8.3.2 基于GGUF和llama.cpp的模型量化 223
8.3.3 GPTQ和EXL2量化技术 225
8.3.4 其他量化技术 226
8.4 小结 227
第9章 RAG推理流水线 228
9.1 理解LLM Twin的RAG推理流水线 229
9.2 探索LLM Twin的高级RAG技术 230
9.2.1 高级RAG预检索优化:查询扩展与自查询 233
9.2.2 高级RAG检索优化:过滤向量搜索 239
9.2.3 高级RAG后检索优化:重排序 240
9.3 构建基于RAG的LLM Twin推理流水线 243
9.3.1 实现检索模块 243
9.3.2 整合RAG推理流水线 249
9.4 小结 254
第 10章 推理流水线部署 255
10.1 部署方案的选择 256
10.1.1 吞吐量和延迟 256
10.1.2 数据 256
10.1.3 基础设施 257
10.2 深入理解推理部署方案 258
10.2.1 在线实时推理 259
10.2.2 异步推理 260
10.2.3 离线批量转换 260
10.3 模型服务的单体架构与微服务架构 261
10.3.1 单体架构 261
10.3.2 微服务架构 262
10.3.3 单体架构与微服务架构的 选择 264
10.4 探索LLM Twin的推理流水线部署 方案 265
10.5 部署LLM Twin服务 268
10.5.1 基于AWS SageMaker构建LLM 微服务 268
10.5.2 使用FastAPI构建业务 微服务 282
10.6 自动缩放应对突发流量高峰 285
10.6.1 注册缩放目标 287
10.6.2 创建弹性缩放策略 287
10.6.3 缩放限制的上下限设置 288
10.7 小结 289
第 11章 MLOps与LLMOps 290
11.1 LLMOps发展之路:从DevOps和 MLOps寻根 291
11.1.1 DevOps 291
11.1.2 MLOps 293
11.1.3 LLMOps 296
11.2 将LLM Twin流水线部署到云端 299
11.2.1 理解基础架构 300
11.2.2 MongoDB环境配置 301
11.2.3 Qdrant环境配置 302
11.2.4 设置ZenML云环境 303
11.3 为LLM Twin添加LLMOps 313
11.3.1 LLM Twin的CI/CD流水线 工作流程 313
11.3.2 GitHub Actions快速概览 316
11.3.3 CI流水线 316
11.3.4 CD流水线 320
11.3.5 测试CI/CD流水线 322
11.3.6 CT流水线 323
11.3.7 提示监控 327
11.3.8 告警 332
11.4 小结 332
附录 MLOps原则 334

在留言区参与互动发送(我想要一本赠书)
并点击转发朋友圈,邀好友助力点赞你的留言
我们将选点赞率最高的1名读者获得赠书1本
时间以公众号推文发出24小时为限
记得扫码加号主微信,以便联系邮寄地址哦
欢迎自购或向图书馆荐购

微信群


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢