
摘要
隐私保护机器学习(Privacy-Preserving Machine Learning,PPML)是融合隐私计算与人工智能的核心技术范式,通过联邦学习、差分隐私、同态加密、安全多方计算等手段,在数据加密或分布式协作的前提下完成模型训练与推理,实现数据价值挖掘与隐私保护的平衡,其核心优势在于:一方面打破数据孤岛促进协同计算,另一方面通过联邦学习的分布式训练机制、差分隐私的噪声注入策略、同态加密的密文计算特性等技术路径,在训练过程中构建多层防护体系,从根本上规避训练数据的隐私泄漏风险。PPML正成为数据合规流通的关键使能器,推动“隐私增强型AI”在敏感场景的可信部署,重塑数据共享的商业逻辑,即在保护用户数据的前提下释放数据价值,实现数据驱动的创新与信任共存。
近年来人工智能技术快速发展,如燎原之火般席卷全球,影响着社会的方方面面,例如医疗诊断的精准预测、金融风控的智能决策、智能家居的语音助手等。以 Transformer 架构为核心的大语言模型更将 AI 能力推向新高度:理解复杂语境、生成高质量文本和视频、甚至完成编程、设计等创造性工作。
机器学习即服务(Machine Learning as a Service,MLaaS)的快速普及,用户和企业可以利用集中的计算服务和基础设施来构建和部署模型,轻松地利用机器学习技术解决实际问题。在训练阶段,企业会将训练数据上传到云端进行模型训练,得到训练好的模型;在推理阶段,企业将预训练模型部署在云端,用户通过通过 API 调用服务时,输入问询请求得到推理结果。以上两种模式中数据的集中化处理模式存在巨大的用户隐私风险,在此背景下,隐私保护机器学习应运而生。
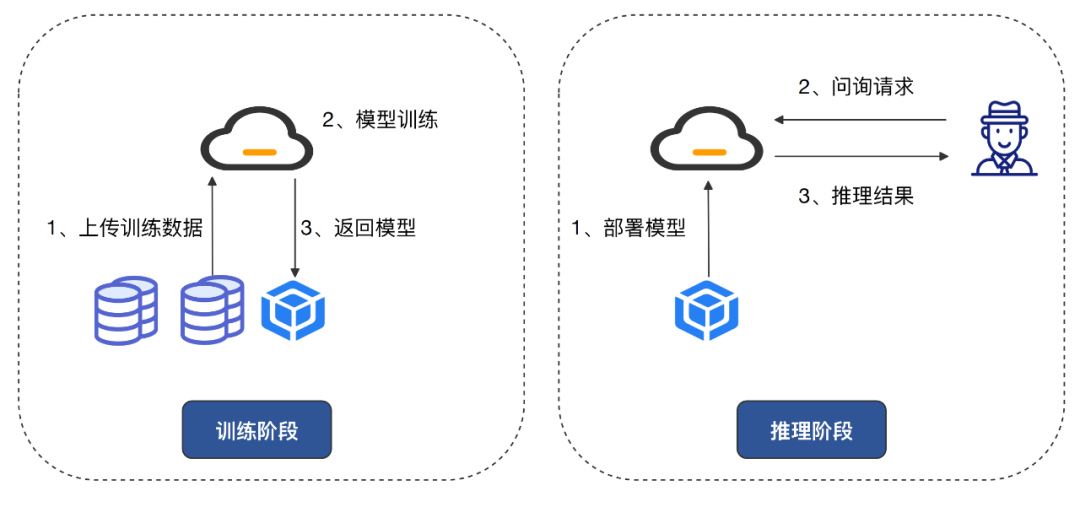
隐私保护机器学习致力于实现机器学习模型的训练阶段和推理阶段的数据隐私和安全,通过密码学、分布式计算等技术,在数据提供方、模型训练方和模型使用方之间建立信任的桥梁,进而实现“数据可用不可见”。
隐私保护机器学习PPML 可分为以下三类:
基于数据扰动技术的 PPML:侧重于平衡模型训练过程中的数据效用和数据隐私。通过在训练数据或模型参数中引入差分隐私或匿名化技术,在保证数据效用的前提下防止敏感信息泄露
基于密码学技术的 PPML:侧重于设计更高效的安全计算协议以降低计算与通信开销。基于同态加密、安全多方计算等技术为机器学习算子设计安全计算协议,提供最高等级的安全性,但同时会引入较大的计算和通信开销
联邦学习:侧重于优化算法在异构数据下的鲁棒性,提升通信效率与安全性。多个参与方在各自数据不出域的前提下共同训练一个模型,只需要在训练迭代中交互更新模型梯度
密码技术的引入为 PPML 方案提供了重要的底层支撑。依托于秘密分享(Secret Sharing,SS)、不经意传输(Oblivious Transfer,OT)、混淆电路(Garbled Circuit,GC)、同态加密(Homomorphic Encryption,HE)等密码学工具的快速迭代,通过构建面向机器学习算子的安全计算协议,实现了对算法模型端到端的安全性保障。随着密码技术的持续演进,基于密码学技术的PPML技术近十年发展迅猛,推动该领域从理论研究逐渐走向实际应用。一些具有代表性的工作如下:
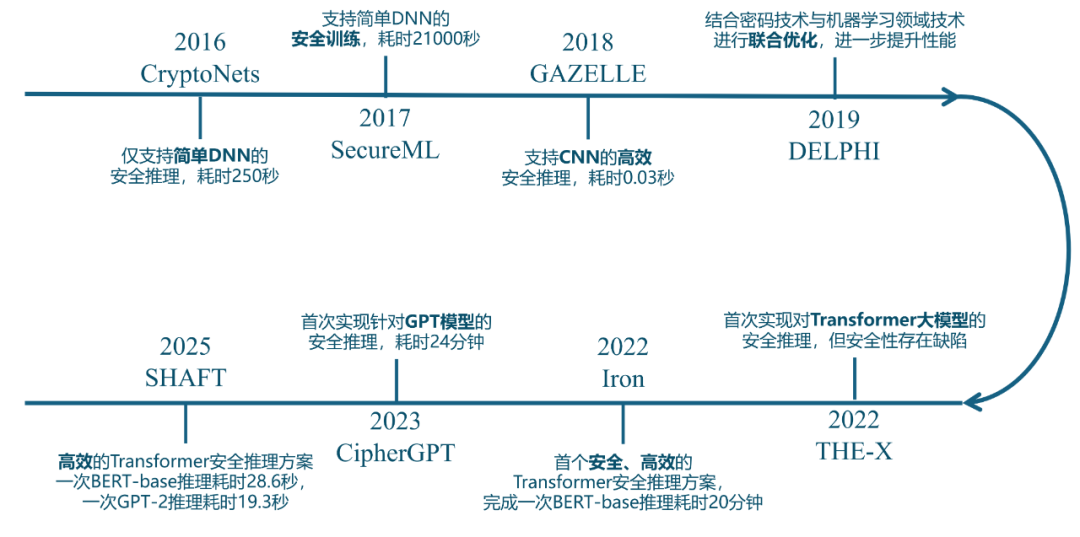
从上述发展脉络中可以看出,基于密码学的 PPML 研究主要聚焦于两个核心目标:
1)效率优化:通过算法改进与硬件加速,显著降低安全推理与训练的计算复杂度及通信成本,为PPML的规模化部署扫清技术障碍
2)功能扩展:突破模型限制,支持从安全推理到安全训练,支持从轻量级深度神经网络到基于Transformer架构的大型语言模型,提升隐私保护场景下的模型性能与泛化能力
具体围绕以上两个核心目标,近些年基于密码学的 PPML 技术开展可归纳为以下三个研究方向:
1) 协议设计 : 该方向聚焦于结合先进的密码学技术为机器学习算子设计更高效的隐私保护协议。例如,Sigma[1] 通过引入高效的函数秘密分享原语为 Transformer 中的非线性算子设计定制化协议,并将大部分开销转移到预处理阶段,端到端推理耗时相比于通用框架 Crypten[2] 优化 11.5–19.4 倍。
2)模型优化 : 该方向聚焦于结合机器学习技术降低模型的计算复杂度,采用“先简化模型结构,再部署隐私保护”的策略。例如,DELPHI[3]、MPCFormer[4] 等方案结合机器学习领域的神经架构搜索、知识蒸馏技术,在保持模型效用的同时降低模型的计算复杂度,减少非隐私计算友好的操作。
3)系统优化 : 该方向聚焦于对 PPML 方案进行系统层面的优化来降低开销、方便用户使用。例如,NEXUS[5] 使用 GPU 加速基于同态加密的 Transformer 安全推理,端到端推理耗时相比于 CPU 方案优化 42.3 倍。
现有隐私保护机器学习的解决方案主要针对机器学习算子设计定制化安全协议,但这对机器学习研究人员并不友好,他们需要手动组合多个算子的安全计算协议以构建完整的模型,无法直接使用 Pytorch、TensorFlow 等成熟深度学习框架提供的标准化工具链。为解决这一痛点,近年来研究人员提出了一系列隐私保护机器学习通用框架,这些框架通过抽象底层密码技术的细节,采用与主流机器学习框架(如 TensorFlow、Pytorch)兼容的 API 设计,使非密码学背景的研究人员能够以“黑盒”方式调用安全计算功能,从而专注于模型架构设计。
TF Encrypted 是一个基于 TensorFlow 的开源加密机器学习框架,用户在使用上和 TensorFlow 没有太大的区别,其目标是使得隐私保护机器学习技术变得可用,而不需要密码学、分布式系统或高性能计算方面的专业知识。
TF Encrypted 官网提供的矩阵乘法实例代码如下,可以看出与 TensorFlow 的使用并没有太大的区别。在代码中矩阵乘法的输入 w 通过define_private_variable 定义为 private 类型的变量,输入 x 通过修饰器@tfe.local_computation('input-provider')封装为 private 类型。在代码执行过程中 matmul 函数会调用安全计算后端的各种 MPC 协议来实现安全计算,包括 server-aided Pond、server-aided SecureNN、ABY3 等。最终通过 y.reveal() 解密得到 public 类型的数据,再通过 to_native() 函数得到具体的明文值。
# 导入 TensorFlow 和 TF Encrypted(用于安全多方计算)
import tensorflow as tf
import sys
# 需要将以下路径替换为tf-encrypted库的安装路径
sys.path.append('/path/to/tf-encrypted')
import tf_encrypted as tfe
# 定义一个本地计算函数,返回一个 2x5 的全1张量,模拟输入数据
@tfe.local_computation('input-provider')
def provide_input():
return tf.ones(shape=(2, 5))
# 定义一个 private 类型的私有变量 w(5x3 的全1矩阵),在加密状态下维护
w = tfe.define_private_variable(tf.ones(shape=(5,3)))
# 调用本地函数获取加密的输入数据 x
x = provide_input()
# 【即时执行模式】执行加密矩阵乘法:y = x @ w
y = tfe.matmul(x, w)
# 解密结果 y 并转换为普通 TF 张量
res = y.reveal().to_native()
# 【图执行模式】定义一个可重复使用的加密计算函数
@tfe.function
def matmul_func(x, w):
y = tfe.matmul(x, w) # 加密矩阵乘法
return y.reveal().to_native() # 解密结果并转为普通张量
# 调用加密函数执行计算,返回明文结果
res = matmul_func(x, w)
Crypten是由FaceBook研究团队开发的一个隐私保护机器学习框架[2],基于 PyTorch 构建,继承了 PyTorch 的许多优秀特性,使得机器学习研究人员能够使用安全计算技术轻松地对机器学习模型进行实验,在使用上和 PyTorch 几乎没有区别。例如,对于一段基于 PyTorch 的代码:
# 创建一个包含元素 [1, 2, 3] 的一维张量 x,用于表示向量或数组
x = torch.tensor([1, 2, 3])
# 创建一个包含元素 [4, 5, 6] 的一维张量 y
y = torch.tensor([4, 5, 6])
# 将张量 x 和 y 对应元素相加,结果保存在张量 z 中
z = x + y
在使用 Crypten 时只需要将其修改为
# Crypten 创建一个包含元素 [1, 2, 3] 的一维张量 x
x = crypten.cryptensor([1, 2, 3])
# Crypten 创建一个包含元素 [4, 5, 6] 的一维张量 y
y = crypten.cryptensor([4, 5, 6])
z = x + y
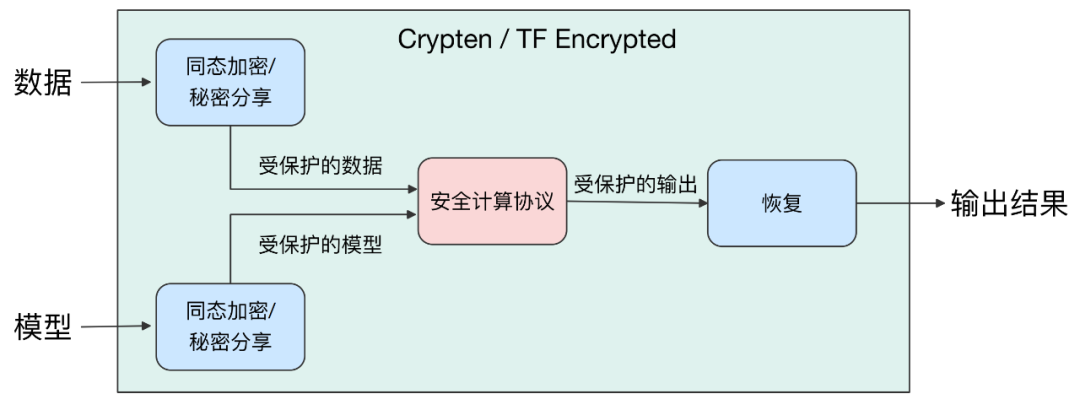
Crypten 和 TF Encrypted 的实现原理是类似的,二者分别实现了一个与 PyTorch、TensorFlow 具有相同 API 接口的库,使得用户可以以最小的代价上手使用这两个集成了密码学技术的隐私保护机器学习框架。这两个框架的高层设计概览图下图所示,将输入的数据或者模型参数通过同态加密或者秘密分享的形式进行保护,将同态密文或秘密分享值输入到安全计算后段的安全计算协议中,执行安全计算协议得到输出结果的密文形式或者分享值形式,再通过解密或分享值重构算法恢复出明文结果。
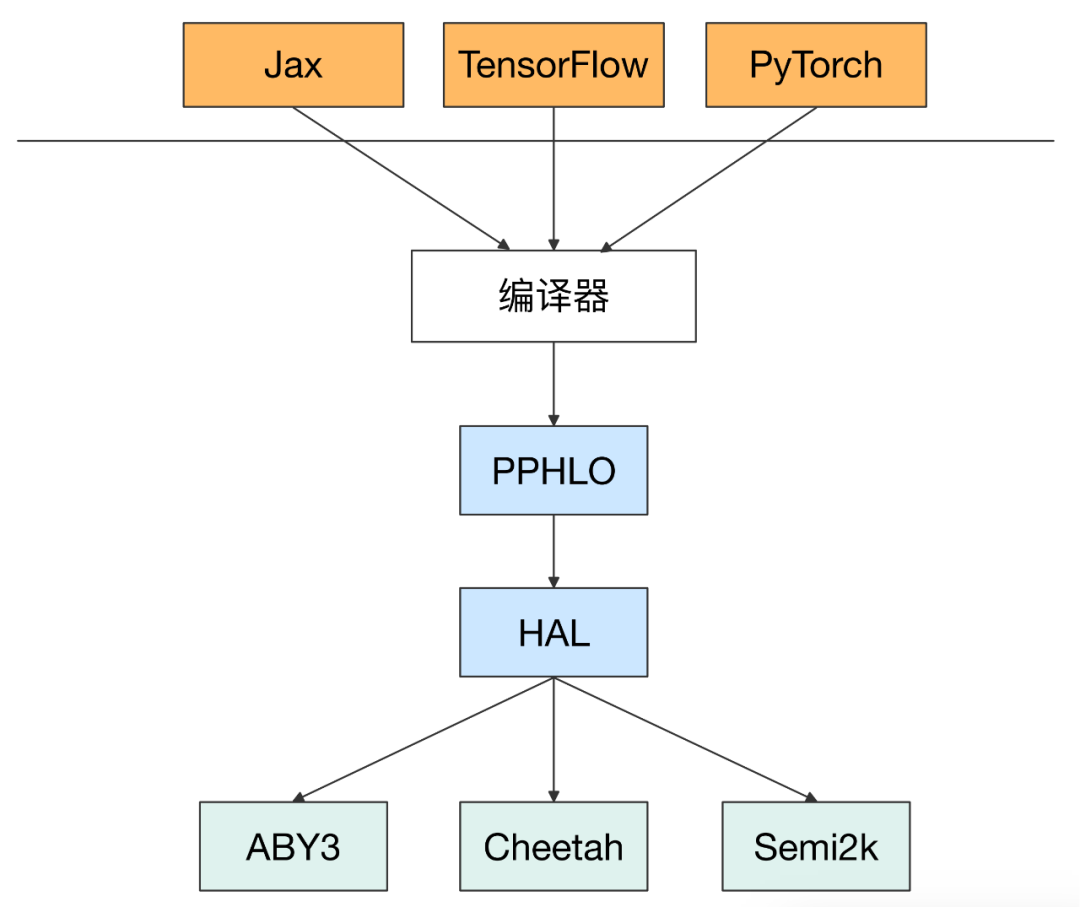
SPU 的体系结构对于 ML 研究人员和 MPC 研究人员都是友好的,一方面机器学习研究人员可以在最上层通过主流的机器学习框架进行开发,而不需要任何密码知识,另一方面 MPC 研究人员可以只在最底层开发 MPC 协议,实现特定的 API 即可支持上层应用。
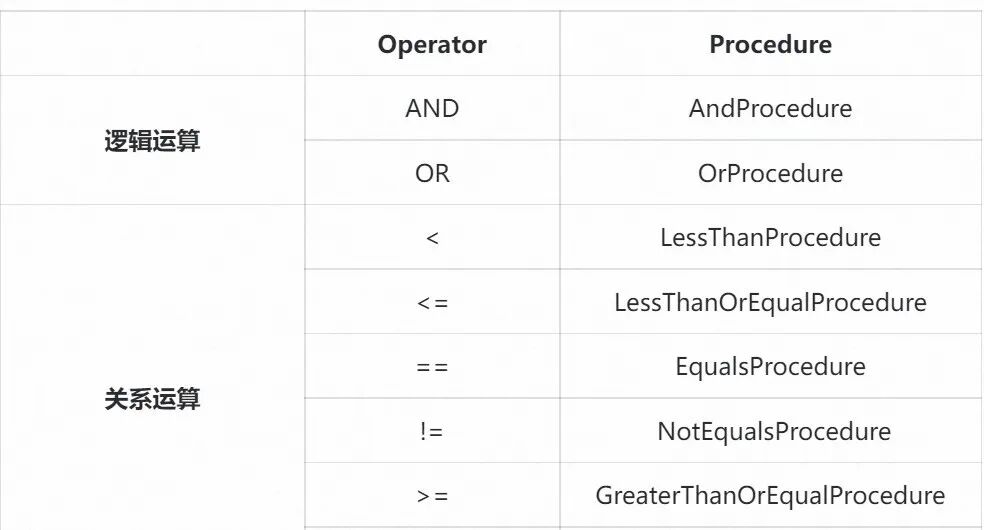
阿里妈妈营销隐私计算平台 Secure Data Hub(SDH)集成了开源隐私保护机器学习框架 Crypten,当执行的 SQL 语句中涉及到来自两个参与方的数据的密态运算时,会调用 Crypten 实现实现密态运算。SDH 目前支持常见的逻辑运算、关系运算和算术运算,能够在保证计算精度的前提下完成亿级别数据量级的密态比较和算术运算。

隐私保护机器学习搭建了隐私保护和机器学习之间的桥梁,实现“数据的可用不可见”,在实现数据隐私的前提下充分发挥了机器学习在各个领域的能动性,下面简要列出 PPML 技术在几个典型行业下的实际应用场景:
医疗诊断:基于联邦学习框架,医疗机构可跨机构协同训练疾病预测模型,在不共享原始数据前提下实现高精度诊断。通过安全多方计算/同态加密技术构建安全推理系统,使患者在数据加密状态下获得AI诊断建议,兼顾隐私保护与规模化应用
金融风控:金融机构通过联邦学习联合训练信用评分与风控模型,用户的敏感信息(收入、负债等)经同态加密后在密文上运行模型,解密输出得到风险评估结果,实现隐私保护与风险控制能力提升
广告营销:电商平台与社交媒体平台通过联邦学习、差分隐私等技术,在用户行为数据中挖掘价值,实现个性化推荐与跨平台协作,平衡精准营销需求与用户隐私合规要求
隐私保护机器学习作为隐私计算与人工智能融合的关键技术,正在重塑数据驱动的行业范式。其通过联邦学习、差分隐私、同态加密、安全多方计算等技术,在数据“可用不可见”的前提下实现模型训练与推理,解决了传统AI对数据集中化依赖的隐私悖论。在医疗、金融、教育、广告等敏感领域,PPML已从理论走向规模化落地,成为推动数据合规流通的关键技术支撑。
随着全球隐私法规的持续收紧(如GDPR、中国《个人信息保护法》),PPML的价值将进一步凸显:它不仅降低了数据共享的法律风险,还为跨机构协作提供了技术保障。未来,轻量化算法优化(如高效联邦学习框架)、硬件加速(如FPGA/GPU支持)及标准化协议的完善,将推动PPML在更多场景中普及。PPML的成熟标志着数据要素流通进入“隐私优先”时代:通过技术手段平衡数据价值与隐私权,最终构建起可信、合规、可持续的数字生态。
[1] Gupta, Kanav, et al. "Sigma: Secure gpt inference with function secret sharing." Cryptology ePrint Archive (2023).
[2] Knott B, Venkataraman S, Hannun A, et al. Crypten: Secure multi-party computation meets machine learning[J]. Advances in Neural Information Processing Systems, 2021, 34: 4961-4973.
[3] Srinivasan W Z, Akshayaram P, Ada P R. Delphi: A cryptographic inference service for neural networks[C]//Proc. 29th USENIX secur. symp. 2019, 3.
[4] Li, Dacheng, et al. "Mpcformer: fast, performant and private transformer inference with mpc." arXiv preprint arXiv:2211.01452 (2022).
[5] Zhang J, Liu J, Yang X, et al. Secure Transformer Inference Made Non-interactive[J]. Cryptology ePrint Archive, 2024.
[6] Ma J, Zheng Y, Feng J, et al. {SecretFlow-SPU}: A performant and {User-Friendly} framework for {Privacy-Preserving} machine learning[C]//2023 USeNIX annual technical conference (USeNIX ATC 23). 2023: 17-33.

💡 关于我们
阿里妈妈SDS(Strategic Data Solutions)团队 致力于用数据让商家和平台的增长战略更加科学有效。我们为阿里妈妈全线广告客户提供营销洞察、营销策略、价值量化、效果归因、隐私计算的技术服务。我们将持续在营销场景下的数据隐私安全和解决方案方向进行探索和落地,欢迎各业务方关注与合作。
📮联系邮箱:alimama_tech@service.alibaba.com
也许你还想看
隐私增强技术(PETs)综述 | 一文了解隐私计算技术发展脉络
阿里妈妈通过信通院两项“可信隐私计算评测”,隐私计算技术能力获权威认证
关注「阿里妈妈技术」,了解更多~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢