

现代强化学习 (RL) 系统捕捉到了关于人类普遍问题解决的深刻真理。在新数据能够低成本模拟的领域,这些系统能够揭示远超人类能力的序列决策策略。社会面临着许多需要这种技能才能解决的问题,但这些问题通常发生在新数据无法低成本模拟的领域。在这种情况下,我们可以从现有数据中学习模拟器,但这些模拟器只能近似正确,并且在训练分布之外进行查询时可能会出现病态错误。因此,我们训练智能体的环境与我们希望部署智能体的真实世界之间不可避免地存在偏差。处理这种偏差是零样本强化学习的主要关注点,在零样本强化学习中,智能体必须在零次练习的情况下推广到新的任务或领域。虽然在理想化环境中执行零样本强化学习的方法已经取得了令人瞩目的进展,但如果要在真实世界中复制这些结果,还需要开展新的研究。在本文中,我们认为,要做到这一点,我们需要克服(至少)三个约束。首先,数据质量约束:现实世界的数据集规模小且同质化。其次,可观测性约束:现实世界中的状态、动态和奖励通常只能部分观察到。第三,数据可用性约束:并非总是能够预先假设可以访问数据。本文提出了一套在这些约束条件下执行零样本强化学习的方法。在一系列实证研究中,我们揭示了现有方法的缺陷,并论证了我们用于弥补这些缺陷的技术。我们相信,这些设计使我们距离能够应用于解决现实世界问题的强化学习方法更近了一步。


论文题目:On Zero-Shot Reinforcement Learning
作者:Scott Jeen
类型:2025年博士论文
学校:University of Oxford(英国牛津大学)
下载链接:
链接: https://pan.baidu.com/s/16JpZLG20IgLYrFtHowilbg?pwd=gcuk
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
引言
1.1自动化问题解决
社会通过解决问题而进步。人脑出现了问题解决问题的能力是唯一通用的[81,82],因此我们是唯一有能力的进展迅速[270]。我们解决问题的能力是如此宝贵,以至于我们竭尽全力为我们构建自动解决问题的工具,所以我们可以将这种能力集中在其他地方[11]。古埃及的水钟这是一个早期的例子。一个容器里装满了水,还有一个小孔打开以允许水以恒定流速流出。不断变化的水通过容器内部的刻度测量的液位表示时间。毫无疑问,自动化计时使埃及人能够集中精力对其他问题给予宝贵关注,这些问题的解决方案进一步推动了进展。此后,许多其他人也纷纷效仿。古腾堡印刷机自动划线,巴贝奇的分析引擎(本可以)自动算术,福特的装配生产线自动化制造,肖克利的晶体管自动化电子,以及伯纳斯-李的万维网自动信息分发。每个工具将人类从不断扩大的问题中解放出来。这个时间表的自然下一步是朝着元问题解决器的方向发展,这是一种解决非元问题的工具只有一个问题,但代表人类的许多问题。
设计这样一个工具一直是人工智能的长期目标(AI)研究[230]。在早期对象征性AI1[251,252,293]和机器学习[149,67,225,373,40,34,244],深度学习已经成为主导范式[114,203]。典型的监督学习设置训练深度神经网络(DNN),用于预测数据集中数据点的标签。训练包括用反向传播更新网络的权重[292]和随机梯度下降[289,39]以最小化预测误差由损失函数计算。该配方彻底改变了图像识别[204,205,187,140,86],机器翻译[335,15],语音识别[148、359],以及自然语言处理[235,361,83,43],并导致了创造流畅的聊天机器人[2,347,348]和图像生成器[150,291,279]在他们获释之前,这是不可想象的。
这些工具中的每一个都会返回一个动作来响应输入。当当看到一只长脖子的斑点动物的照片时,图像识别系统返回单词“长颈鹿”。当被要求将“oùest la gare?”翻译成在英语中,翻译系统返回短语“火车站在哪里?”。当被问及生命的意义时,语言系统会返回数字“42” [3].然而,我们面临的最困难的问题需要时间上的延长行动顺序。考虑物理学家在尝试时面临的问题解释意外的实验结果。他们可能会先检查他们的设备已按预期设置,没有出现故障。如果检查通过,他们可能会花几个小时检查和重写转换其代码的代码测量到人类可读的结果。如果他们的结果保持可重复性,他们可能会花几天时间重新阅读推动实验的文献,并与同事讨论结果。如果找不到解释,他们可能会得出现有理论不足的结论,并在接下来的几个月里,甚至数年,开发新的理论来解释结果。原则上,a模型可以用监督学习来训练,以模仿这一序列但是,为了成功,该模型需要访问广泛的动作数据集,理想情况下,对物理学家可能做出的所有决定进行编目每个决策的质量根据其对实现目标的帮助程度进行排名解释结果。策划这样的数据集不仅不切实际,而且众所周知,很难手动为成功的结果分配分数在时间上延伸的序列中做出正确的决定[236,337,285]。
另一种选择是让模型与世界互动,以发现有用的信息自主决策序列,这是强化的关注点学习(RL)[363,232,336,32]。在这里,决策代理进行交互在解决问题的环境中依次进行。代理人被告知通过奖励实现高级目标,其任务是学习行动的顺序使他们的总和最大化。Deep RL——传统组件的建模具有DNN的RL代理[238,10,211]帮助创建了展示卓越的顺序决策能力。这些系统已被证明能够掌握国际象棋、围棋和将棋等完美信息游戏[319,322,320,309],节拍专家人类在扑克、星际争霸和外交等不完全信息游戏中[362,19,268,42],在很短的时间内设计出最先进的计算机芯片技术娴熟的专家[237],比人类工程解决方案更精确地控制核聚变反应堆[76,314],并取代排序和矩阵乘法计算机科学家50年来没有改进过的算法[228,98]。
综合考察这些进展,我们发现强化学习框架抓住了一些关于人类普遍问题解决的深层真理。事实上,一些人认为,这些相似之处如此深刻,以至于强化学习是我们元问题求解器的必要组成部分 [155, 336, 64, 153]。Silver 等人的假设总结了这一观点:
奖励就足够了 [323]。智能及其相关能力可以理解为,服务于智能体在其环境中行动时最大化奖励。
1.2 未兑现的承诺
鉴于这些进展和诸多说法,人们会期望强化学习智能体无处不在,为人类解决一个又一个问题。但我们显然尚未实现这样的未来。但原因何在?如果强化学习智能体可以控制托卡马克装置,为什么它不能控制我的中央供暖系统?如果强化学习智能体能在扑克牌游戏中击败我,为什么它不能在高尔夫游戏中击败我?如果强化学习智能体可以发现新的排序算法,为什么它不能发现新的药物?要回答这些问题,我们需要探索强化学习样本效率低下的后果 [395]。
智能体通常需要数十亿次环境交互才能获得难题的解决方案 [362, 322]。这种规模的数据相当于许多人一生的学习过程,因此我们认为强化学习智能体相对于人类学习而言是样本效率低下的。如果智能体手动从物理世界收集这些数据,将花费数百年的时间,因此这些数据必然来自非物理的模拟世界。
完美模拟器4利用已知的环境底层物理原理,合成生成这些数据。例如,《太空侵略者》的物理原理是人类设计的,因此强化学习智能体可以模拟该游戏,并根据需要玩足够长的时间才能掌握它[28]。法拉第定律解释了聚变反应堆内等离子体的行为[147],因此可以用来模拟等离子体对智能体提出的不同控制策略的响应[61]。线性代数定律解释了应用于矩阵的运算如何改变矩阵的形式,因此可以用来模拟智能体提出的不同方案下的矩阵变换[98]。但是,对于大多数实际问题,完美模拟器的设计并不容易,因为我们无法用一套通用方程组来简洁地概括它们的物理原理。偶尔,我们可以[61, 69]做到这一点,但即使在这种情况下,工程师也可能需要数月甚至数年的时间来配置模拟器,使其忠实地复制现实。事实上,这项工作的一个核心假设是,构建完美的模拟器来解决现实世界的问题的成本高得令人望而却步。
接受这一点,我们就可以从数据中学习模拟器。在这里,我们不需要从第一原理理解数据生成过程的规则,而是可以训练一个模型来生成现实数据分布。事实上,最近在这方面已经取得了许多进展,特别是在机器人操作[383, 93]、自动驾驶[152]、蛋白质折叠[172, 1]和游戏[45, 56, 123, 234]的学习模拟方面。例如,我们可以想象为一个中央供暖系统配备传感器,在一段时间内收集数据,并训练一个模型来模拟锅炉控制、空气温度和能耗之间的关系。然而,这样的模拟器并不完美,由于两个原因,它们缺乏完美模拟器的精度。首先,对于复杂的高维问题,可能的行为空间非常大,因此很难基于有限的数据集进行建模 [31]。因此,模型必然会在数据集无法解释的场景下做出错误的预测 [244, 114]。其次,模型包含有限的参数,这些参数是随机优化的,这意味着即使拥有完整的数据,其预测也只能近似正确 [114]。因此,我们想要训练代理的学习世界与代理将要部署的现实世界之间必然存在偏差。
这种偏差起初或许并不值得我们担心。如果学习到的模拟器近似正确,那么强化学习智能体是否也能学习到近似正确的行为?然而,即使模拟与现实之间存在微小的偏差,也可能导致传统的强化学习技术 [402] 偏离正轨,因为这些技术对训练环境的特性存在众所周知的偏见 [398, 65, 173]。而要利用现实世界的经验来消除这种偏见,可能需要数百万次的进一步交互,有时甚至是不可能的 [219, 218]。事实上,这些智能体会非常仔细地检查其训练环境,以至于它们可以利用其中的弱点来获取高额奖励 [62, 325, 186],并暴露源代码中的未知错误 [280, 356]。因此,在学习到的模拟器中简单地训练传统的强化学习智能体,无法像那些依赖完美模拟的研究那样,在现实世界中取得超越人类的表现。
1.3 未来之路
因此,强化学习是一种类似于人类的顺序决策模型,但现有方法样本效率低下,需要大量的预训练数据。每个成功的强化学习应用背后都有一个提供这些数据的完美模拟器,但期望这些数据能够解决大多数现实世界的问题是不现实的。可行的替代方案是使用从环境中收集的数据来学习模拟器,但这些数据在最好的情况下也只是近似正确的,在最坏的情况下,当在训练分布之外进行查询时,则会出现严重的错误。传统的强化学习代理无法快速处理模拟的、错误的训练环境与真实的、正确的部署环境之间的差异。如果我们的目标是朝着元问题求解器的方向发展,那么我们应该在这个系统的哪个环节进行干预?
在本论文中,我们选择在最后阶段进行干预。我们的目标是构建能够快速适应训练和部署环境差异的智能体设计。这将我们直接置于零样本强化学习[181]这一新兴领域,该领域的目标是开发能够在零次练习的情况下适应新场景的智能体。近期的优秀工作使我们更接近这一目标。尤其相关的是将前向后向表示[354]和通用后继特征[37]应用于零样本强化学习。近期研究表明,这些方法理论上可以通过训练来解决环境中的任何下游任务,并且在测试时仅需少量数据来指定任务[355]。从经验上讲,这些方法可以返回许多简单问题的解,其性能与在训练期间即可了解任务的传统强化学习方法一样好。
下文介绍的大部分工作都涉及为类似的方法配备工具,使其不仅能解决玩具问题,还能解决现实世界的问题。我们认为,现实世界问题至少存在三个重要的约束条件,这些约束条件决定了解决方案空间:
1. 数据质量约束:现实世界的数据集规模小且同质化。
2. 可观测性约束:现实世界的状态、动态和奖励很少能够完全观测。
3. 数据可用性约束:现实世界的问题并不总是能够预先提供训练数据。
约束 1 是由于现实世界数据集必然由现任智能体或控制器生成,而这些智能体或控制器的优化目标是任务性能,而非数据集大小、异构性或表达能力 [88]。约束 2 的出现是因为智能体通过有限的传感器观察世界;因为环境的物理特性在数据收集和策略执行之间会发生变化;或者因为奖励在执行操作后不会立即传达给智能体 [88]。约束 3 的理由有两方面。第一点如前所述;许多现实世界问题无法用一组通用方程式来简洁地概括,因此无法完美地模拟。第二点是,许多我们感兴趣的现实世界问题可能无法由现有的系统控制,而我们可以从中提取历史数据日志6。
这项研究的核心理念是:要将强化学习技术应用于解决现实世界的问题,它必须能够零样本地解决任务,同时至少要满足以下约束条件之一。更准确地说,我们力求捍卫以下几点:
论文
可以构建强化学习代理,以零样本方式解决未知任务,同时满足数据质量、可观测性或数据可用性约束。
1.4 论文结构与贡献
我们将在后续章节中推进我们的论文。首先,我们将回顾第二章中的相关背景材料。这包括对强化学习问题的正式描述,以及§2.1中对常用解决方法的介绍。鉴于构建完美模拟器的难度,本论文将主要讨论已学习的模拟器,这是离线强化学习(§2.2中介绍)所关注的问题。推广到未见过场景的零样本方法必然与§2.1中介绍的传统技术不同,因此我们将在§2.3中对它们进行单独的回顾。
在第三章中,我们提出了保守的零样本强化学习方法,以解决现有方法在现实数据集上训练时存在的缺陷。我们首先揭示了最先进的零样本强化学习方法在低质量数据集上训练时的一个关键失效模式,即高估数据集中不存在的状态-动作对的值。利用离线强化学习文献中的正则化技术,我们使模型对这些状态-动作进行偏向,并证明这可以显著提高所有标准零样本强化学习基准测试的性能。本章基于以下文献:
Zero-Shot Reinforcement Learning from Low Quality Data. Scott Jeen, Tom Bewley, and Jonathan M. Cullen. In Advances in Neural Information Processing Systems 38, 2024 [164].
在第四章中,我们将使用记忆模型来增强零样本强化学习方法,以解决其在部分可观察问题设置中的缺陷。我们揭示了两种故障模式,我们称之为状态错误识别和任务错误识别。我们证明了,基于记忆的零样本强化学习方法能够解决状态和任务错误识别问题,因此,在状态、奖励或动态仅部分可观察的环境中,其性能优于无记忆方法。本章基于以下文献:
Zero-Shot Reinforcement Learning Under Partial Observability. Scott Jeen, Tom Bewley, and Jonathan M. Cullen. In Reinforcement Learning Conference 2, 2025 [165].
在第五章中,我们将探讨:在没有任何先验知识的情况下,是否有可能控制一个现实世界的系统。我们感兴趣的现实世界问题是高效排放的建筑控制,即在满足居住者舒适度限制的前提下,最大限度地减少任意建筑的能源使用相关排放。我们介绍了一种名为 PEARL(概率减排强化学习)的新方法,该方法无需任何先验知识,仅需 180 分钟的部署前数据收集,即可将建筑物排放量减少高达 30%。本章基于以下出版物:
Low Emission Building Control with Zero-Shot Reinforcement Learning. Scott Jeen, Alessandro Abate and Jonathan M. Cullen In AAAI Conference on Artificial Intelligence, 2023 [163].
博士期间完成的其他工作未收录于本论文中,如下:
Dynamics Generalisation with Behaviour Foundation Models. Scott Jeen and Jonathan M. Cullen. In RL Conference Workshop on Training Agents with Foundation Models, 2024 & RL Conference Workshop on RL Beyond Rewards, 2024 [166].
[paper] [slides] [poster]
Testing the domestic emission reduction potential of optimised building control alongside retrofit. Hannes Gauch, Scott Jeen, Jack Lynch and Andre Cabrera Serrenho.
第六章总结了我们的贡献及其局限性,并对我们的提案在未来的适用性进行了推测性讨论,以此作为论文的结论。
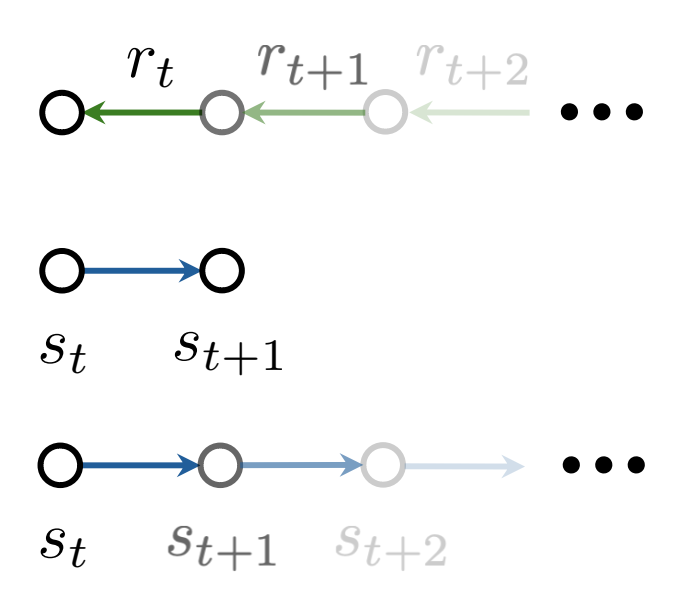
强化学习的三种范式。(上)无模型强化学习方法提取未来奖励rt、rt+1、rt+2、。 . . 转化为价值函数、策略或两者兼有(第2.1.4节)。(中)基于模型的一步强化学习方法通过模型预测状态转移st→st+1(第2.1.5节)。(底部)基于多步模型的强化学习方法提炼未来状态转移st, st+1, st+2, 。 . .转化为模型。
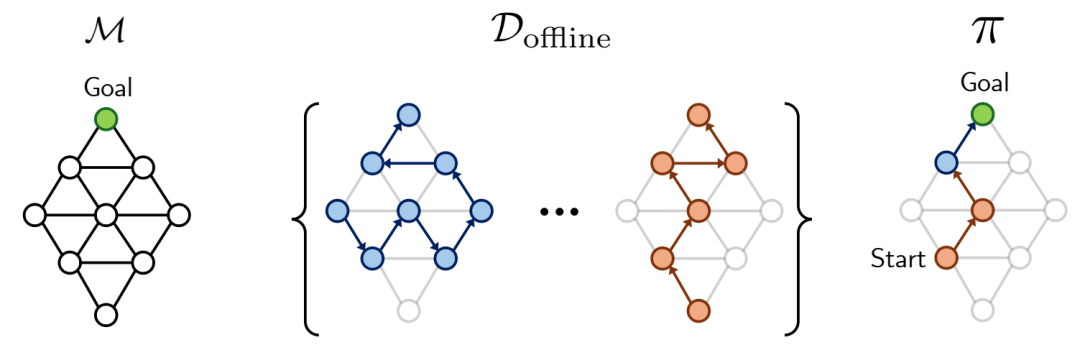
离线强化学习中的轨迹拼接。(左)一个图马尔可夫决策过程(MDP)M,其中任务是找到到达目标状态的最短路径。(中间)离线轨迹数据集Doffline可能并不包含该任务的最优轨迹。(右)策略π学习如何组合
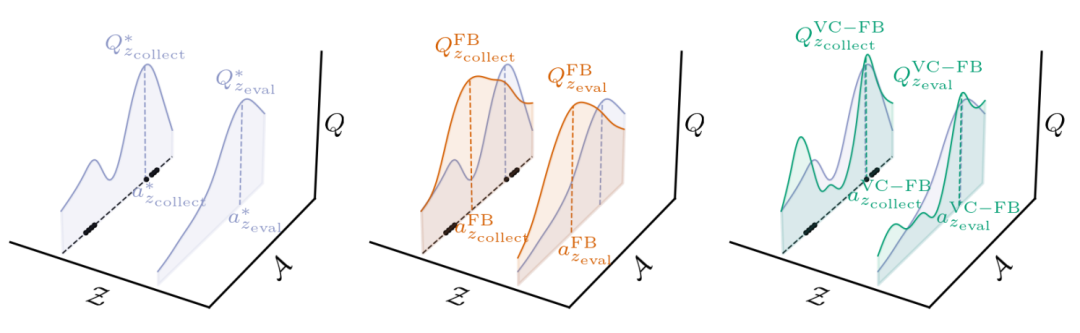
保守的零样本强化学习(左)零样本强化学习方法必须在一个数据集由针对任务zcollect进行优化的行为策略收集,但可推广到新任务任务zeval。对于给定的状态,这两个任务都有相关的最优值函数Q∗ zcollect和Q∗ zeval边缘状态。(中)现有方法,此处为前向-后向表示法(FB),对所有任务中不在数据集中的动作的价值估计过高。(右)价值保守前向-后向表示(VC-FB)会抑制不在数据集中的动作的值所有任务。黑点表示数据集中存在的状态-动作样本。
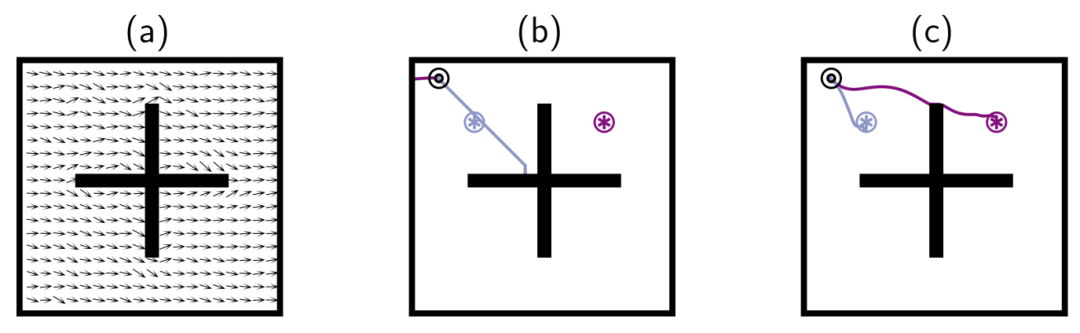
忽略分布外动作。智能体的任务是学习针对达到⊛和⊛的单独策略。(a)移除所有“左”动作的随机数据集;抖动表示每个状态区间中的平均动作方向。(b)100万步后的最佳前向滚动(FB)表现学习步骤。(c) 经过100万次学习步骤后的最佳VC-FB性能。FB估计过高OOD行动的价值,且无法完成任何一项任务;VC-FB则综合了必要的要素从数据集中获取信息,并完成这两项任务。
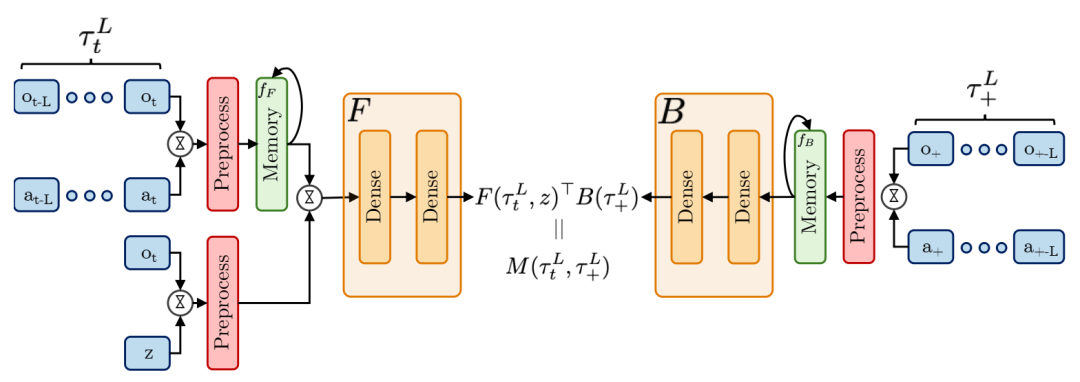
具有记忆功能的零样本强化学习(RL)方法。在基于反馈(FB)的情况下,前向模型F以及基于压缩轨迹的记忆模型输出的反向模型B条件关于观察和动作。根据标准的反馈(FB)理论,它们的点积可以预测Mπz(τtL, τ+L),从L长度轨迹τtL到L长度未来轨迹的后继测度τL+,由此可以推导出Q函数。附录C中的图C.1展示了无记忆性用于对比的FB(Facebook)。
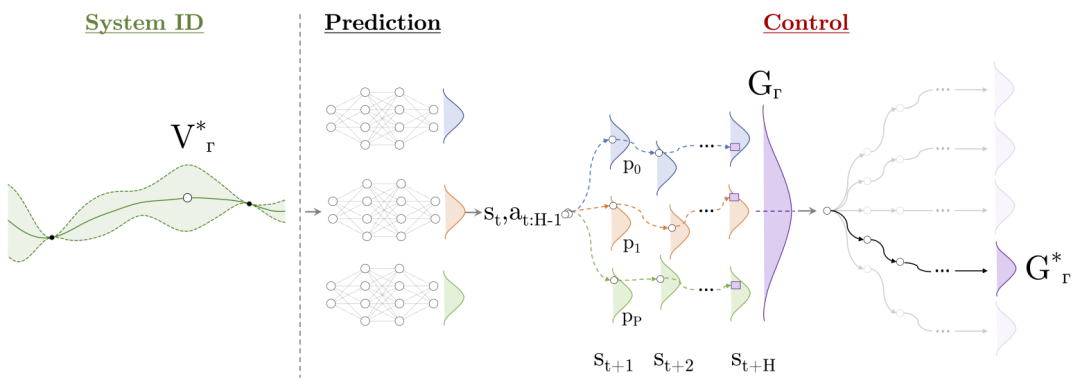
PEARL:概率排放减少强化学习系统ID:智能体采取行动探索具有最高预测方差的状态空间部分◦ = V ∗Γ 试图最大化信息增益。预测:系统动力学被建模使用概率深度神经网络集成。控制:轨迹采样用于预测在H-1时刻一个动作序列的未来奖励GΓ,并将其与其他许多序列进行比较找到具有最优回报G∗Γ的轨迹。

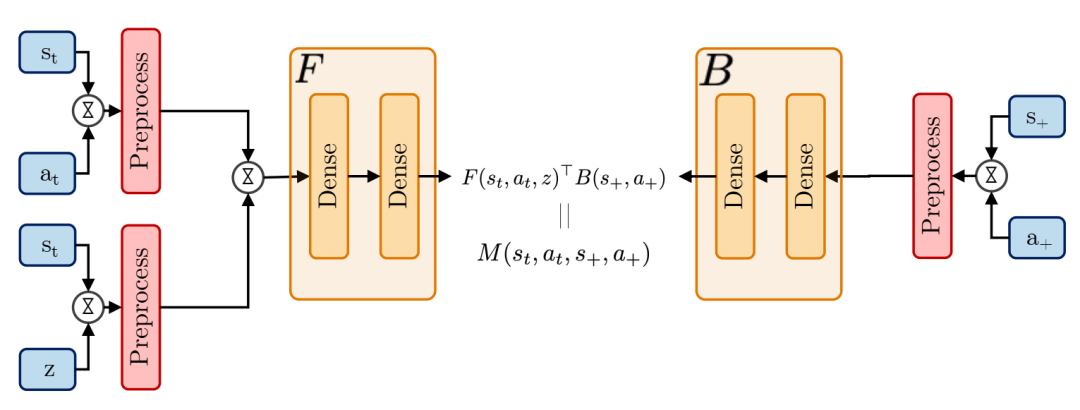
无记忆的零样本强化学习(RL)方法。在标准动作器中对FB进行优化批评者设置[183]。策略π在当前状态st的条件下选择一个动作,并且任务向量z。由USF ψ形成的Q函数在给定当前状态的情况下评估动作状态st和任务z。







内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢