

EMNLP 2025 (自然语言处理经验方法会议) 是自然语言处理 (NLP) 和人工智能领域的重要国际学术会议。该会议由ACL的SIGDAT小组主办,每年举办一次。EMNLP 2025 将于 2025 年11月5日 - 9日在中国苏州举办。
PKU-DAIR实验室的论文《Improving Low-Resource Sequence Labeling with Knowledge Fusion and Contextual Label Explanations》被EMNLP 2025 录用。
Improving Low-Resource Sequence Labeling with Knowledge Fusion and Contextual Label Explanations
作者:Peichao Lai, Jiaxin Gan, Feiyang Ye, Wentao Zhang, Fangcheng Fu, Yilei Wang, Bin Cui
Github链接:https://github.com/aleversn/KnowFREE
Background
问题背景与动机
序列标注(如命名实体识别NER)在低资源和特定领域场景下,尤其对于中文这类字符稠密的语言,一直是一个重大挑战。现有方法通常聚焦于增强模型理解能力或提升数据多样性,但在专业领域中,它们常常面临模型适用性不足和数据语义分布偏差的问题。例如,模型难以处理嵌套实体,并且数据增强方法容易引入与目标领域不符的噪声,从而影响性能。
核心挑战:模型局限性与数据分布偏差
现有方法主要面临两大瓶颈:
模型适用性有限:许多模型在处理字符稠密的语言时,难以灵活地融合多样的特征类型和标签结构,特别是在处理嵌套实体时能力不足。此外,复杂的特征集成流程增加了推理成本,限制了模型的实际部署。
标签分布的可变性:数据增强方法常因领域间的语义差异导致合成数据质量下降。不同领域对同一实体类型的定义和上下文可能存在差异,这会削弱模型的泛化能力。
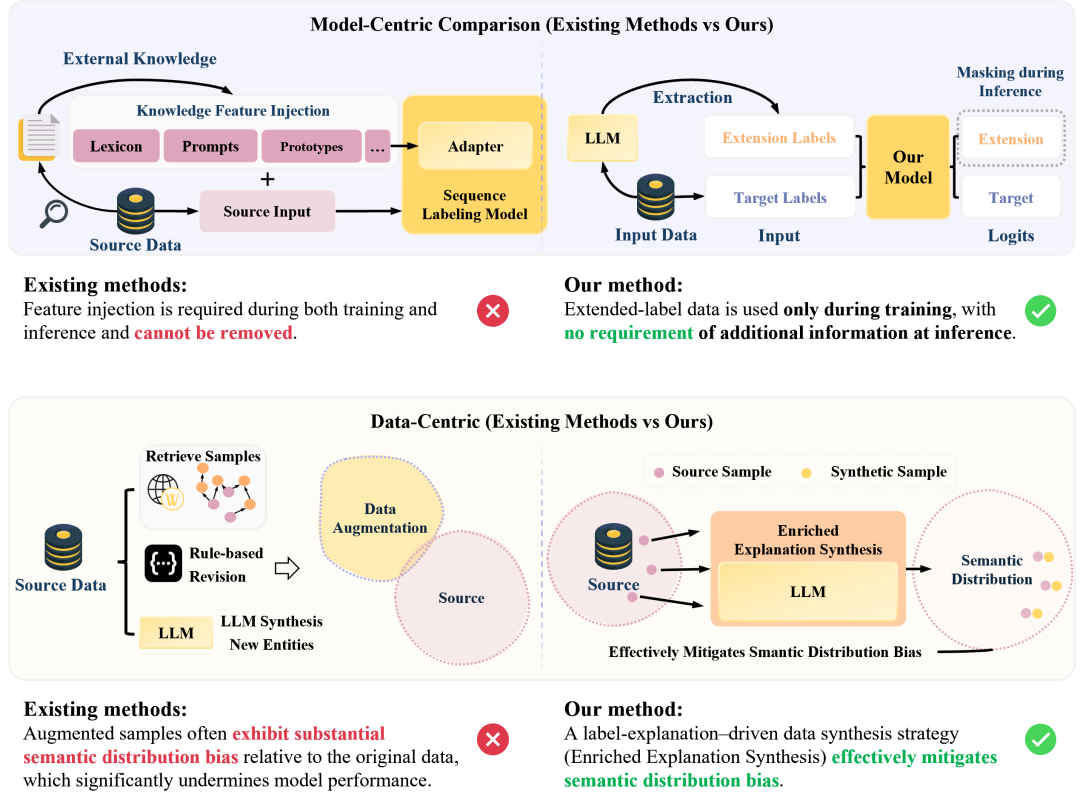
图1:与现有序列标注方法在模型侧和数据侧上的对比
为了解决这些挑战,本研究旨在开发一个统一的框架,既能解决模型结构的局限性,又能应对领域自适应的难题,核心思路是:
采用基于 span 的模型架构,突破传统序列标注限制:与传统的基于Token的序列标注方法(如BIO)不同,基于跨度(span-based)方法通过枚举和分类文本片段来识别实体。这种设计天然支持嵌套和不连续实体的识别,解决了传统方法在处理复杂实体结构时的局限性,从而更有效地利用文本中的非实体特征,提升了模型的结构适用性。
通过上下文解释合成,增强模型对领域知识的理解:利用大语言模型生成针对目标实体的丰富上下文解释,并以此为基础合成高质量的训练数据。这种方法不仅能扩充稀缺的标注数据,还能将领域知识隐式地注入到模型中,缓解数据分布偏差问题,让模型更深刻地理解特定领域内的实体语义。
本研究的主要贡献可以概括为:
1. 新方法: 提出了一个名为 KnowFREE 的 span-based 序列标注模型,它通过局部多头注意力机制有效融合多源标签特征,并原生支持嵌套实体的识别。
2. 新视角: 提出了一个结合LLM的知识增强工作流,通过上下文解释来合成高质量数据,有效缓解了低资源场景下的数据稀疏和语义偏差问题。
3. 高效推理: KnowFREE模型的一大优势是在推理过程中完全不依赖外部知识或复杂的特征工程,所有知识均在训练阶段被模型吸收,保证了部署的高效性。
实验证明,该方法在中英文等多语言的低资源序列标注任务上均取得了当前最佳性能,验证了其有效性和鲁棒性。
Framework
数据增强和模型训练流程
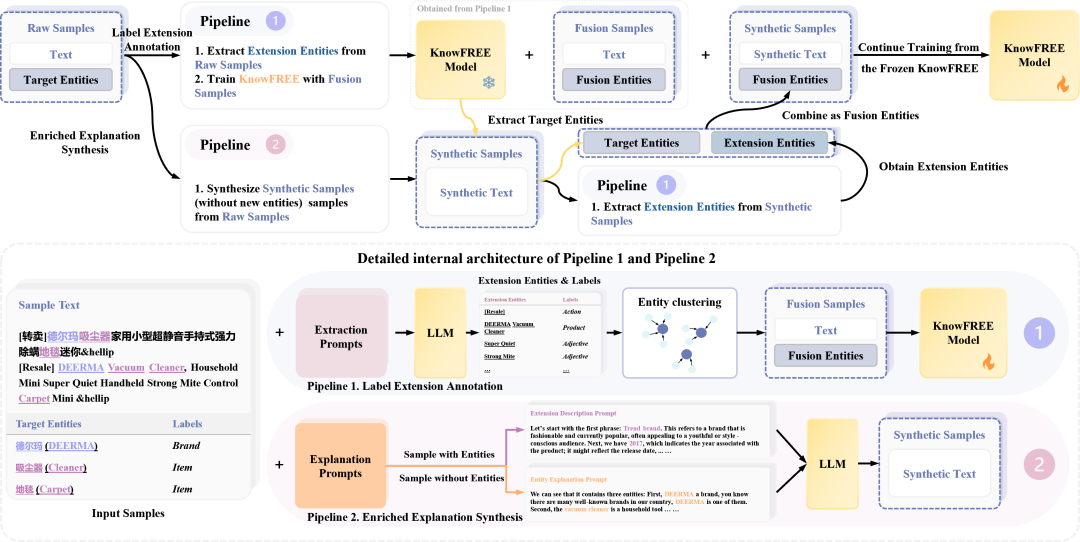
图2:整体框架图
如图所示,该框架通过两个核心功能模块(Pipeline 1 和 Pipeline 2)对数据进行处理,最后进行模型的二次训练,以达到最佳性能。
模块一:标签扩展标注 (Pipeline 1): 此模块旨在通过注入外部通用知识来丰富原始数据的特征。它利用LLM从原始样本中提取扩展实体(如通用实体类型)、词性 (POS) 和分词信息。为了保证标签的一致性并减少噪声,该模块还包含一个实体聚类和同义词标签合并的步骤。经过处理后,原始数据被扩充为包含多源标签的“融合样本”。这些样本随后被用于训练一个初始的KnowFREE模型,该模型因吸收了更丰富的特征而具备了更强的上下文理解能力。
模块二:丰富化解释合成 (Pipeline 2): 此模块主要解决低资源场景下训练样本绝对数量稀少的问题。为了最大化数据利用率并生成高质量的合成样本,该模块针对两种情况设计了不同的合成策略:(1)对于包含目标实体的样本:采用“实体解释提示词” (Entity Explanation Prompt),引导LLM根据样本中的实体及其上下文,生成对该实体具体含义的详细解释。这不仅扩充了文本内容,也深化了模型对实体在特定领域中语义的理解。(2)对于不包含目标实体的样本:采用“扩展描述提示词” (Extension Description Prompt),引导LLM从文本中抽取关键短语,并围绕这些短语进行解释和扩展。这样可以充分利用那些没有标注实体的句子,挖掘其中潜在的领域知识,增加数据的多样性。 通过这种差异化的合成方式,该模块能够生成与原数据语义分布高度一致的高质量新训练样本,为后续的模型训练提供了宝贵的增量数据。
最终训练流程: 在两个模块执行完毕后,整个流程进入最终的训练阶段:首先,使用由模块一训练出的初始KnowFREE模型,对模块二生成的“合成样本”进行自动标注,以获取高质量的伪标签。然后,将这些已标注的合成数据与原始的“融合样本”合并。最后,使用这个最终的数据集对KnowFREE模型进行二次训练,从而使其性能在低资源场景下得到进一步的提升。
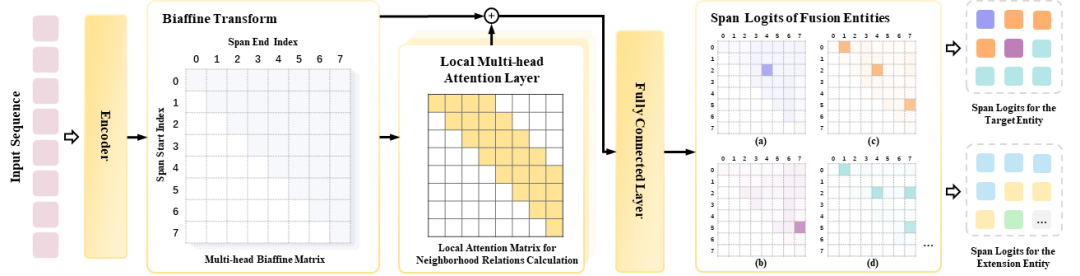
图3:KnowFREE模型的详细结构图
KnowFREE 模型:高效融合多标签知识
本研究提出的 KnowFREE 模型基于双仿射(Biaffine)架构,并做出了关键创新:
支持嵌套实体:span-based 的设计天然支持嵌套和不连续实体的识别。
局部多头注意力机制: 该模型引入了一个局部多头注意力层,用于增强span邻域特征之间的交互。这使得模型可以在训练阶段有效融合目标实体标签和引入的扩展标签(如词性、通用实体等)信息。
推理零额外开销: 最重要的是,KnowFREE模型在推理阶段不依赖任何外部知识。所有知识都在训练阶段被模型吸收,使得推理过程既高效又简洁。
Experiment
实 验
实验数据与场景配置
数据集: 本研究在多个中英文序列标注数据集上进行了实验,涵盖扁平NER (Weibo, Youku, CoNLL'03)、嵌套NER (CMeEE-v2)、分词 (PKU, MSR) 和词性标注 (UD) 等多种任务。
实验场景: 为了模拟低资源情况,实验分别进行了多样本 (Many-shot, 采样250/500/1000条) 和少样本 (Few-shot, k=5/10/15/20) 的测试。
基线模型: 本研究与包括BERT-CRF, FLAT, W²NER, DiFiNet 等在内的多种强基线模型进行了对比。
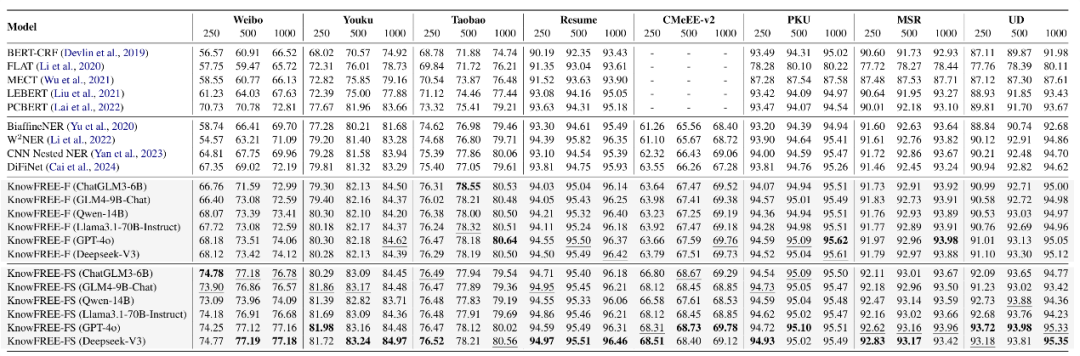
表1: 多样本(Many-shot)设定下的F1分数对比表格
多样本场景: 该方法在不同数据规模下均展现出卓越性能。结果显示,随着LLM模型规模的增大,数据增强带来的性能提升也越明显。但即便使用轻量级的ChatGLM3-6B,该框架依然超越了所有基线模型。特别是在250条样本的极低资源设定下,性能平均超出最强基线1.95%(在Weibo数据集上提升高达4.05%),证明了其在数据稀缺时的有效性。有趣的是,随着样本量增加(如超过500条),包含“丰富化解释合成”的KnowFREE-FS版本相比仅使用“标签扩展”的KnowFREE-F版本,优势逐渐缩小甚至持平。这表明数据合成策略在训练数据极度有限时效果最显著,而当数据相对充足时,其引入的噪声可能会抵消部分增益。
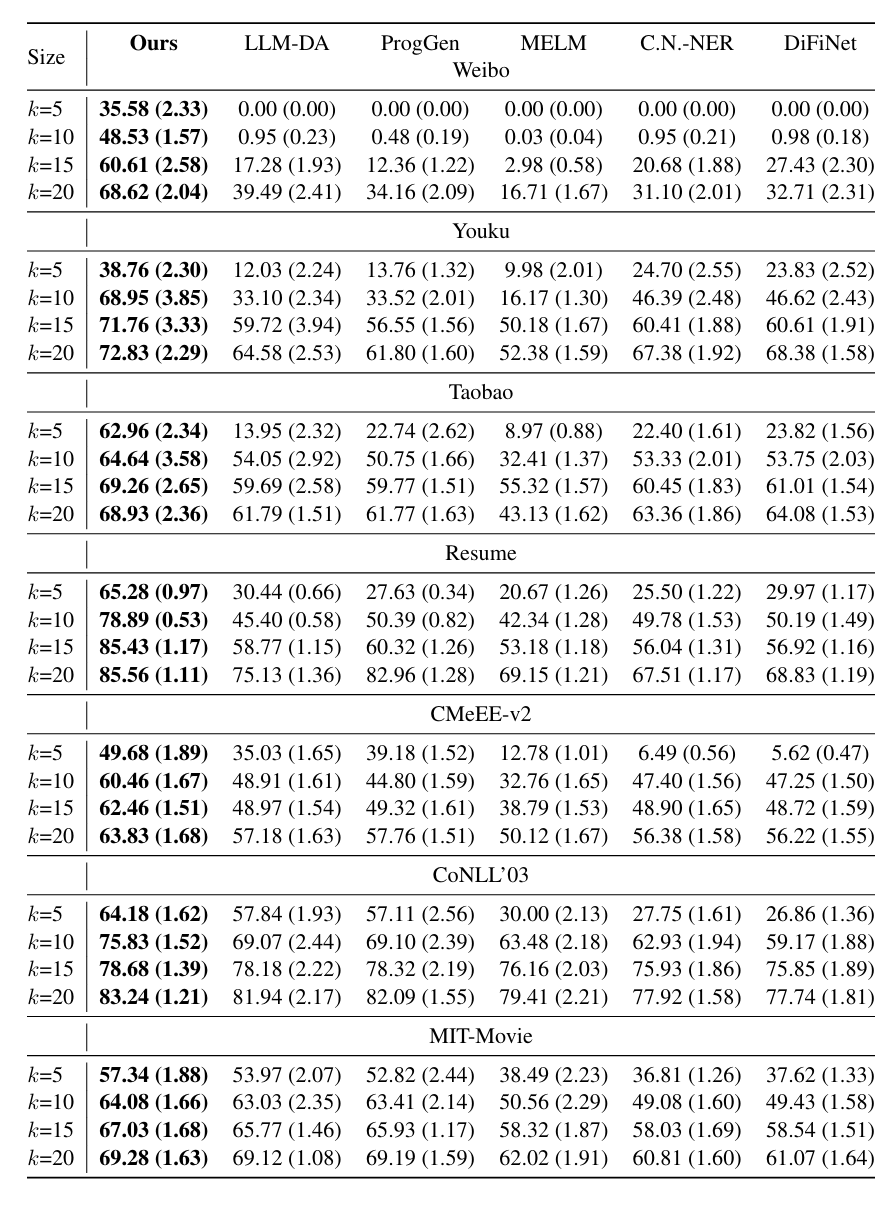
表2: 少样本(Few-shot)设定下的F1分数对比图
少样本场景: 在极低资源(k-shot)的设定下,该方法的优势更加显著。例如,在Weibo数据集k=5的极端情况下,其他方法几乎完全失效(F1接近于0),而本研究的方法F1值达到了35.58%。与其他基于LLM的数据增强方法(如LLM-DA)相比,本研究的“上下文解释合成”策略表现出更强的鲁棒性;前者在某些低资源场景下甚至会因引入噪声而导致性能下降,而本方法则能持续稳定地提升模型表现,极大缓解了数据稀疏性问题。
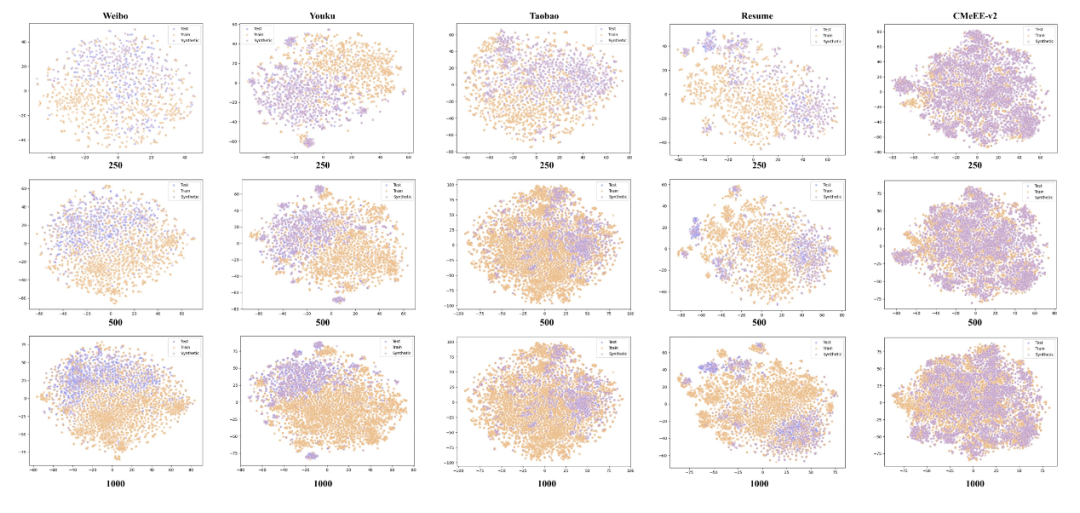
图4: t-SNE可视化样本分
可视化分析:为了直观理解数据增强的效果,本研究利用t-SNE对训练样本、测试样本以及合成样本的句子嵌入进行了可视化。分析显示:
在样本量较少时(如250条),原始训练数据在语义空间中的覆盖范围非常稀疏,与测试集的分布存在明显“断层”。而通过“上下文解释”合成的样本,能够精准地填补这些语义空白,从而显著提升模型的泛化能力。
随着样本量增加到1000条,原始数据的语义覆盖变得更全面。此时,在某些数据集上(如Youku、Taobao),合成数据与原始数据的分布开始出现轻微偏差,这可能是导致性能提升放缓甚至引入噪声的原因。
然而,在Weibo这类数据分布特别复杂的数据集上,即便有1000条样本,语义空间中仍存在未被覆盖的区域,因此合成数据依然能带来正面效果。这一发现深刻揭示了该数据增强策略的适用边界,并直观地解释了其在不同数据规模下性能表现差异的原因。
Conclusion
总 结
本研究提出了一个结合LLM知识增强和基于跨度的序列标注模型KnowFREE的新框架。通过标签扩展标注和丰富化解释合成两个阶段,该方法显著提升了模型在低资源、特定领域场景下的性能。KnowFREE模型通过创新的局部注意力机制,在不增加推理负担的前提下,高效地融合了多源知识。大量的实验证明了该方法的有效性和鲁棒性,为解决低资源序列标注问题提供了新的范式。
END
欢迎关注本公众号,帮助您更好地了解北京大学数据与智能实验室(PKU-DAIR),第一时间了解PKU-DAIR实验室的最新成果!
实验室简介
北京大学数据与智能实验室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR实验室)由北京大学计算机学院崔斌教授领导,长期从事数据库系统、大数据管理与分析、人工智能等领域的前沿研究,在理论和技术创新以及系统研发上取得多项成果,已在国际顶级学术会议和期刊发表学术论文200余篇,发布多个开源项目。课题组同学曾数十次获得包括CCF优博、ACM中国优博、北大优博、微软学者、苹果奖学金、谷歌奖学金等荣誉。PKU-DAIR实验室持续与工业界展开卓有成效的合作,与腾讯、阿里巴巴、苹果、微软、百度、快手、中兴通讯等多家知名企业开展项目合作和前沿探索,解决实际问题,进行科研成果的转化落地。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢