
DRUGONE
物理神经网络(PNNs)是一类利用模拟物理系统执行计算的神经网络。虽然目前仍主要局限于实验室的小规模展示,但PNNs有望在未来改变人工智能计算的方式。研究人员正在探索两大类训练方法:基于反向传播和无需反向传播的方法。尽管尚无方法能够在大规模模型中达到传统反向传播算法的性能,但多样化的训练技术正在迅速发展,并为PNNs如何实现高效、可扩展的人工智能提供了启示。

人工智能已在医疗、天气预测、材料设计等领域发挥重要作用,背后依赖于数字化GPU算力与庞大数据。然而,随着模型规模不断扩大,现有硬件的能耗、延迟和存储瓶颈日益突出。冯·诺依曼架构的内存—计算分离尤其成为限制。由此,基于光子学、模拟电子学等非传统计算平台的物理神经网络受到关注。PNNs利用物理系统的固有运算特性,可望突破数字硬件的能效限制,但其训练方式亟需重新思考,以适应物理硬件的约束。
结果
PNNs的类型与挑战
PNNs分为两类:同构PNNs通过严格硬件映射实现数学运算(如交叉阵列矩阵乘法);非同构PNNs则直接训练物理系统的转换过程。这种方式更灵活,但也使可扩展训练成为关键难题。PNNs潜在应用场景广泛,从大规模生成模型到本地推理和智能传感器,训练需求随场景差异很大,例如数据中心可耗费大量能量训练,而边缘设备必须快速适应且能耗极低。
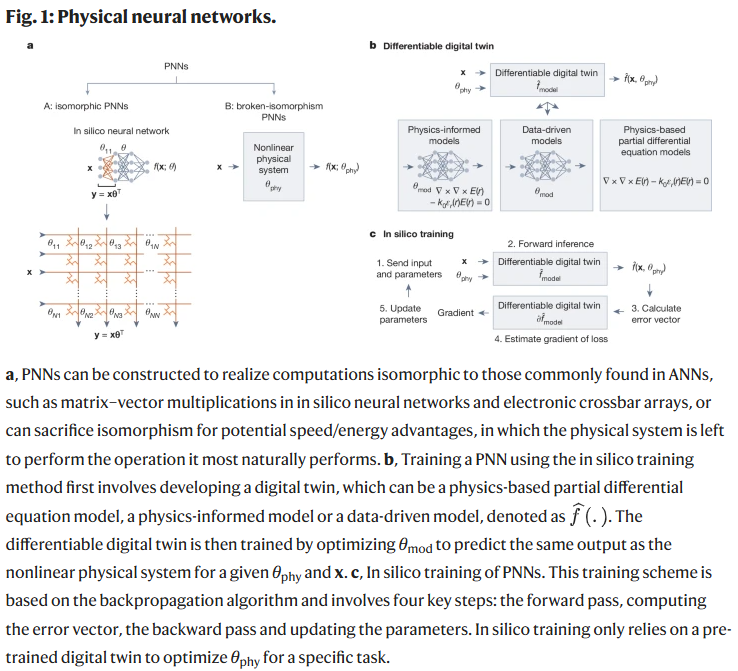
训练方法分类
数值孪生(in silico training):通过物理系统的“数字孪生体”进行训练。优点是可用传统反向传播,但存在“模拟—现实差距”,难以完全捕捉硬件的噪声、制造缺陷等复杂性。
物理感知反向传播(PAT):结合实验前向传播与数字模型的近似梯度,降低对精确模型的依赖,在光学、力学、电子学系统中均已展示有效性。
反馈对齐(FA/DFA):利用固定随机反馈传播误差信号,避免权重传输问题,兼具物理可行性和效率,但易出现性能下降。
局部学习(Local Learning, PhyLL等):每一层独立使用局部损失更新参数,消除全局梯度通信需求,已在声学、光学和微波PNNs中实验验证。
零阶与无梯度方法:包括有限差分、遗传算法、群体优化和强化学习,避免对模型的依赖,但优化速度慢,难以扩展。
基于物理动力学的梯度下降:利用物理过程本身完成梯度传播,包括波散射法、平衡传播(EP)、哈密顿回声反向传播(HEB)等,部分在光子学和忆阻器网络中已有原型实现。

大模型与可扩展性
研究人员特别讨论了PNNs在超大模型中的潜力。例如在光学硬件中,运算能耗随规模增加呈1/N衰减,理论上可比数字电子更高效。对于未来10^15参数级别的模型,若硬件架构合理,PNNs或可展现出比GPU/TPU数千倍甚至百万倍的能效优势。这为大语言模型等超大规模AI系统的推理与训练带来希望。
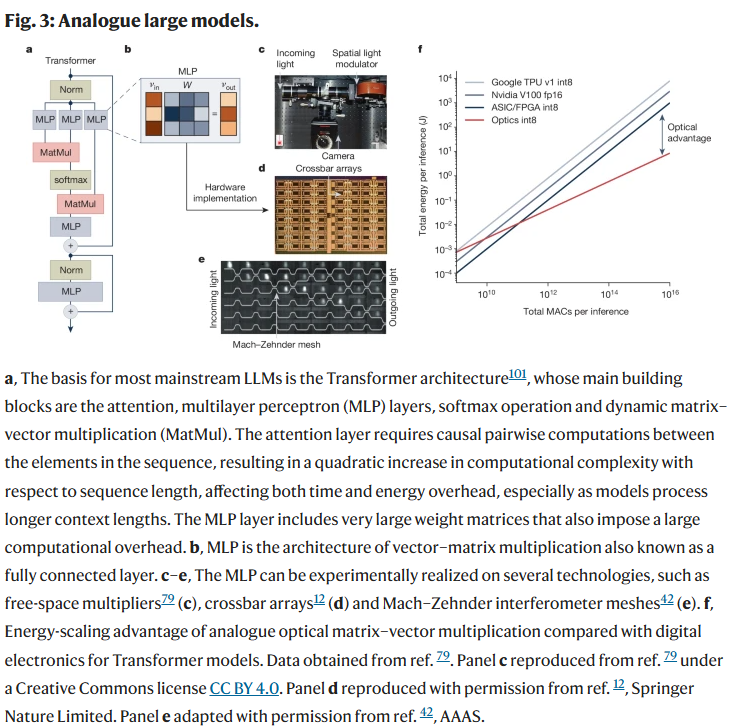
新兴平台
除了光学与模拟电子学,PNNs还扩展到量子、概率、光-物质耦合和混合平台。这些系统各具特点,例如量子PNNs在特定任务中可能超越经典模型,概率硬件擅长生成模型,光子Ising机利用光的并行性与无损传播实现优化计算。这种平台多样性表明PNNs的应用范围不仅局限于传统计算,还可拓展至智能传感与边缘计算。
讨论
PNNs的训练方法正快速演进,但尚无单一方法能同时满足高精度、高能效、强鲁棒性等要求。不同硬件和应用场景需要不同的权衡。例如,有的方法优化了能效却牺牲了训练速度,有的方法提升了精度却依赖昂贵的硬件建模。未来研究的关键在于:
明确不同训练方法的适用场景与权衡关系;
发展结合物理过程与数据驱动的混合策略,弥合“模拟—现实差距”;
构建面向极端可扩展性的硬件—软件协同设计。
研究人员预测,随着更通用、更高效、更鲁棒的训练方法不断涌现,PNNs将在能效上实现数千倍甚至更大幅度的优势,推动其走向实际与广泛应用。
整理 | DrugOne团队
参考资料
Momeni, A., Rahmani, B., Scellier, B. et al. Training of physical neural networks. Nature 645, 53–61 (2025).
https://doi.org/10.1038/s41586-025-09384-2

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢