

新智元报道
新智元报道
【新智元导读】从IBM中国研究院院长,IEEE女工程师协会北京分会创始主席,再到如今的智源研究院副院长兼总工程师,林咏华始终站在中国科技界的风口浪尖。智源和林咏华如今关注的具身智能,如火如荼的背后离不开他们的努力。为了帮大家寻找到下一代具身智能的突破口,林咏华为我们指出了关键所在:数据、评测、系统软件。而这三大要素,也是智源和林咏华为全球具身智能行业生态,贡献了关键性的中国力量。
一图看透全球大模型!新智元十周年钜献,2025 ASI前沿趋势报告37页首发
有没有发现,今年机器人突然就雨后春笋般冒出来了。
从特斯拉机器人街头卖爆米花,到国内机器人运动会,再到社交网络上的机器人恶作剧。

具身智能,猛地一下就闯入了人类的生活!
你甚至可以在街头看到有人遛「机器狗」,后边还跟着一个穿衣服的机器人。
具身智能为何突然井喷式发展?
机器人很多年就有了,比如像波士顿动力等,为何今年具身智能好像突然火了?
机器人技术的发展和这几年大模型AI突飞猛进的进化有关系吗?
具身智能也有像人类一样的「大小脑」结构吗?
这些问题的答案,在新智元十周年庆典上,智源研究院副院长兼总工程师林咏华为我们做出了系统性解读。
林咏华以《从大模型到具身智能——基础技术的新挑战(数据、评测、计算)》为题,献上了一场连接历史与未来的思想盛宴。

提起林咏华院长就不得不提她与新智元创始人杨静多年的友谊,她们也反映和代表了科技界的女性力量。

在2019年IEEE国际女工程师领导力峰会上,专家们一致呼吁:女性应更多参与AI和STEM领域,建立女性主导的开发者社区,推动「科技向善」,让未来智能世界更加多元与包容。
杨静在会上表示:女性天生具有较强的爱心与同理心,有利于科技逐步聚焦于「善」,让科技惠及更多的人。
林咏华女士曾是IBM中国研究院成立以来首位本土女性院长,亦是IEEE北京女性工程师委员会主席,长期不懈努力推动中国女性成为未来AI世界的奠基石。
加入智源研究院后,她一直耕耘在人工智能的系统技术、数据和评测研究,打造了从大模型创新到具身智能突破的创新基石。
从大模型到具身智能,什么技术决定了他们的发展?
加入智源后,林咏华负责了人工智能系统、数据、评测三大方向的研究,她把这三大方向定位为整个大模型和具身智能的基础技术。
现在的大模型训练,数据是关键,此前Meta不惜143亿美金重金也要买下数据标注公司Scale AI就是证明。
在数据上,智源研究院发布了全球最大的中英文高质量数据集CCI 4.0,连同其余上百个智源开源的数据集一同,成为了国家级的高质量中文训练数据的基石。

林咏华还透露,智源研究院现在刚完成新的一轮大模型评测。
并且,最重要的是智源的系统软件计算部分,已经支持了包括英伟达、寒武纪、华为等十多家芯片厂商的超过20款不同芯片。
智源可以说是AI领域的全能选手。
这一年,新智元也见证了他们在基础模型、具身智能、视觉模型上的突飞猛进。
比如单卡也能跑万帧的视觉模型Video-XL-2,速度、效果、长度全拉满。

智源的国产多模态图像生成模型OmniGen2开源一周狂揽2000星,外网爆火。
还有今年7月刚刚开源的全球最强具身智能大脑RoboBrain 2.0全面超越GPT-4o。不仅问鼎评测基准SOTA,还成功刷新跨本体多机协作技术范式!
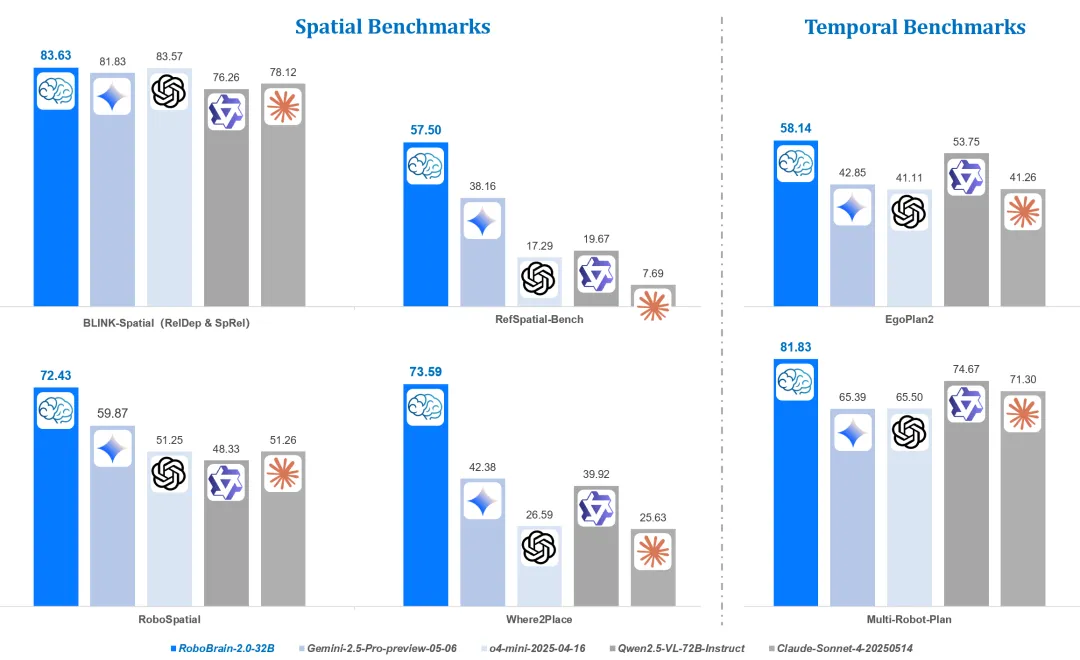
RoboBrain 2.0-32B在BLINK-Spatial、RoboSpatial、RefSpatial-Bench、Where2Place、EgoPlan2和Multi-Robot-Plan等空间与时间推理基准上均取得最佳表现

林咏华首先回顾一下过去十年机器人的发展历程。
十年间,大模型推动具身智能快速发展,从传统的控制算法,到Sim2Real模仿学习。
在Transformer架构出现后,迎来了VLM模型,现在终于来到硬件与AI深度融合的VLA模型。
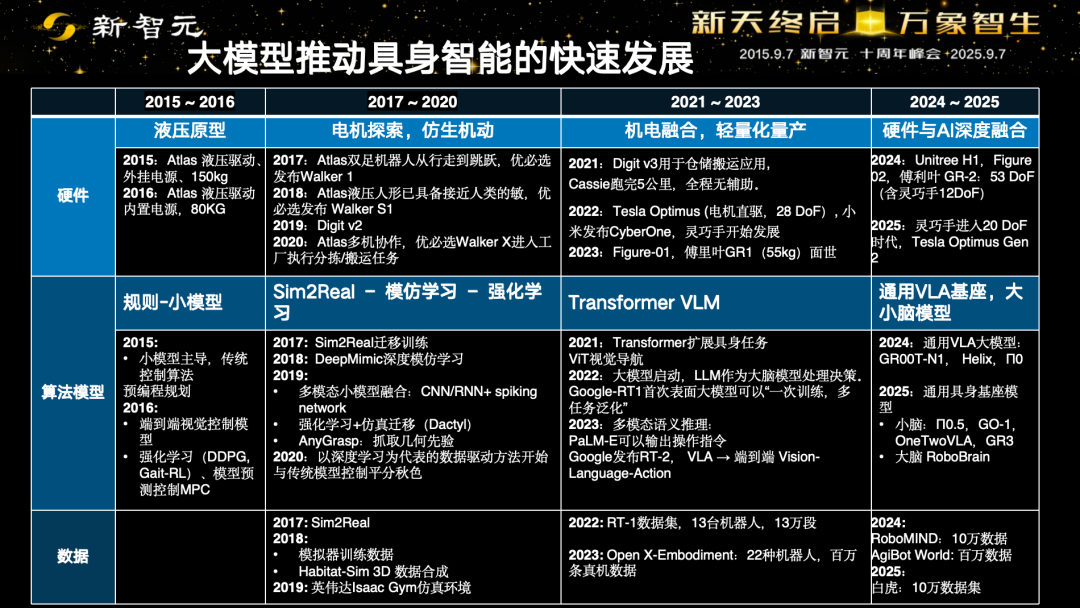

林咏华提到,数据领域,尤其在2017年-2022年,那时候大模型还没有发展起来,当时机器人领域的算法主要是强化学习、模仿学习。
但是从去年到现在,几个十万、百万具身智能训练数据集的出现,验证了大模型进入到具身智能。
当前,受制于端到端训练的复杂性、模型的参数量和实时控制等要求,很难用一个大模型来端到端完成具身智能从高层的世界理解到末端快速控制和响应。因此,智源提出大脑模型和小脑模型这种分层方式。
•机器人大脑:理解物理世界、理解人类意图、人-机和机-机交互、推理决策等
•机器人小脑:拆解指令、观察物理环境、调用工具及输出硬件控制等
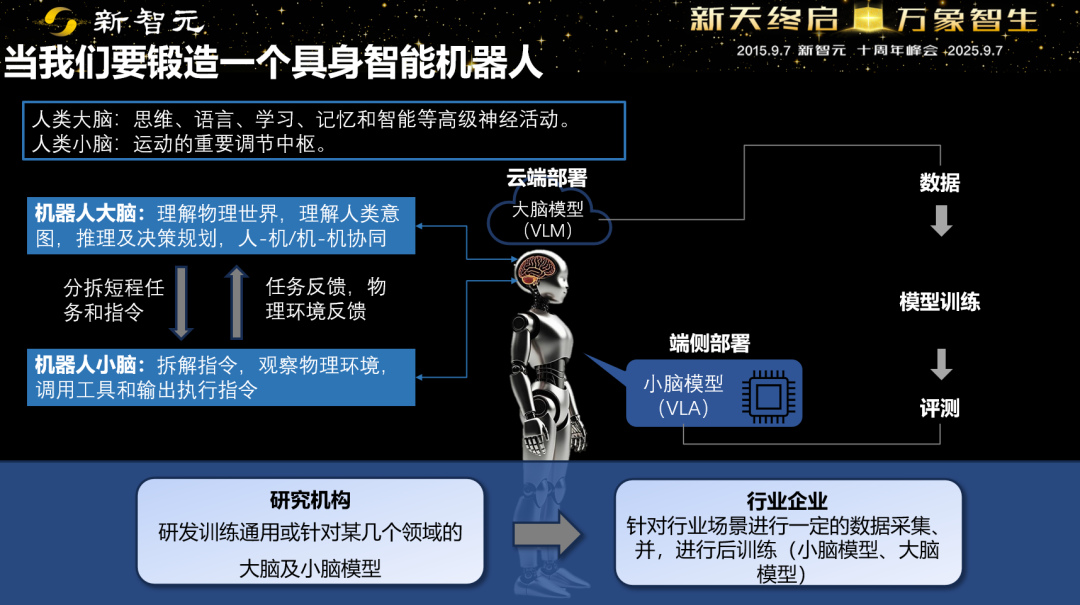
当前业界开始形成共识,并探索一种分工范式。科研机构研发训练通用领域、或针对几个领域的大脑模型和小脑模型,并开源出来;行业企业通过对特定场景和机器人本体硬件进行少量数据采集,基于通用小脑模型进行后训练,获得更高准确率的具身模型。
当前的大脑模型基本上是VLM语言视觉的多模态模型,大脑模型输出的是一个「规划」,而不是操控物理硬件的动作指令和参数。所以大脑模型可以沿用在大模型里面的训练范式,包括各种VLM模型的训练数据集,目前在HuggingFace上面,百万条视频、图片数据集类型已经挺多了。

可到了小脑模型(VLA:视觉语言动作模型),问题出现了,这方面的高质量、大规模数据十分匮乏。
林咏华说在训练小脑模型的时候,需要的是针对给定的指令和当下的环境信息(如摄像头采集数据),本体执行的一系列动作序列,包括各个硬件部件(如机械臂、末端夹爪等)的执行参数信息。
为什么真机数据对我们的小脑模型(VLA)很重要?
因为它控制了我们的机器人,指导它收取到一条命令,例如抓取杯子,如何通过多步骤的控制机器人双臂以及末端去抓取杯子。
林咏华说:到今年为止,HuggingFace上开源的百万级真机数据集也就两个。更别说灵巧手这类新型硬件的高质量数据,稀缺中的稀缺。

有两篇常被提及的工作能说明「泛化」的苗头: 与字节的GR3。
与字节的GR3。

论文地址:https://arxiv.org/pdf/2504.16054v1

论文地址:https://arxiv.org/pdf/2507.15493v1
二者思路都指向一点:先有一个通用水平不错的小脑(VLA)基座,再用少量真机做后训练,这样在新环境里还是能扛住一部分任务。
但光有这个还不足够解决一切问题:要想泛化能力更强大,数据量、硬件覆盖面、数据质量三个指标都得往上抬。
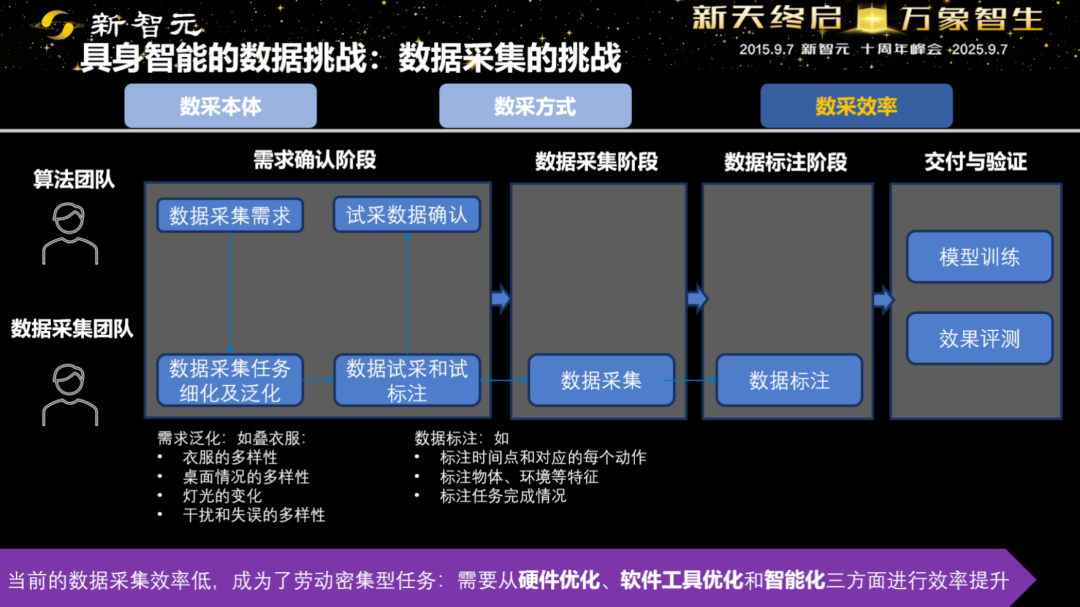
智源不只「要数据」,而是把「采-训-测」做成流水线:
•多源补齐:核心是真机遥操作,动捕、纯视频的「间接数据」做补充。

•效率增倍:从今年3月起,随着平台工具链的迭代,单人单日的采集产能明显抬升,成本下降,节奏加快。

智源今年下了很大力气搭建评测平台和场景、设计过程指标。
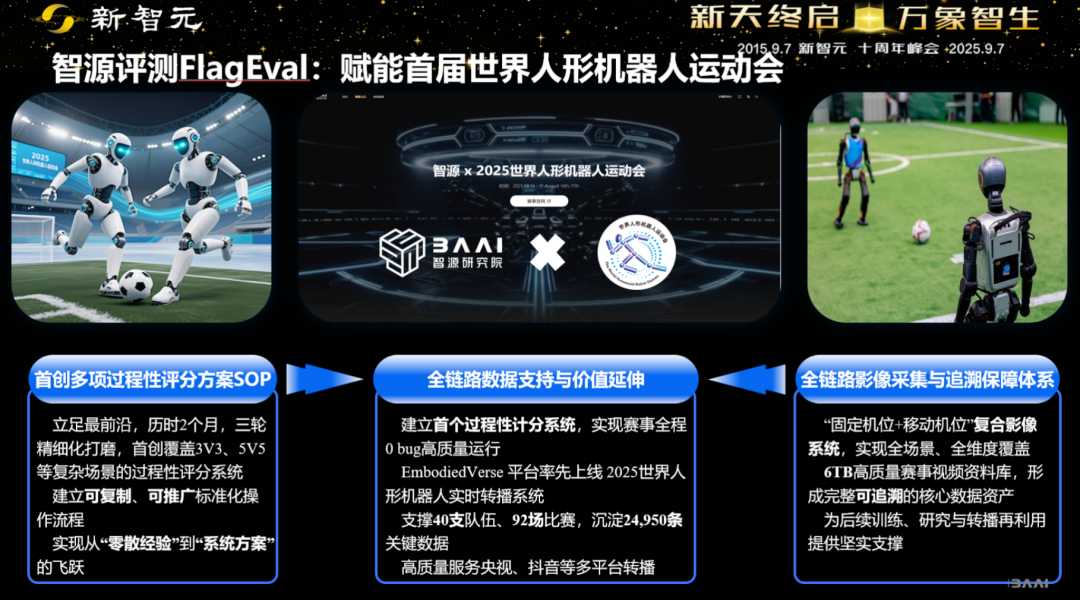
在世界人形机器人运动会的足球项目中,智源不是只看谁赢了球,而是把「感知—定位—规划—执行—恢复」拆成一串更细颗粒度的指标,更精确地指出模型「掉链子」的环节。
当前,各个团队的真机和真实环境的评测刚刚起步、尚未对齐,更无法统一。可以看到,今年上半年出来的一批VLA模型,几乎都只拿去年的当对照,在真机评测结果上是「各说各话」。
健壮性是机器人的重要特性:长链条任务中要稳,环境扰动下也要稳。那评测就不能只看一次漂亮的结果,而要看上百次、看在不同场景下能不能稳稳地做对。这恰恰需要过程指标,让改进有抓手。
在刚结束的世界人形机器人运动会里,智源在背后做了过程性评测的地基工程:不仅有最终比分,还有动作分解的量化指标与日志。

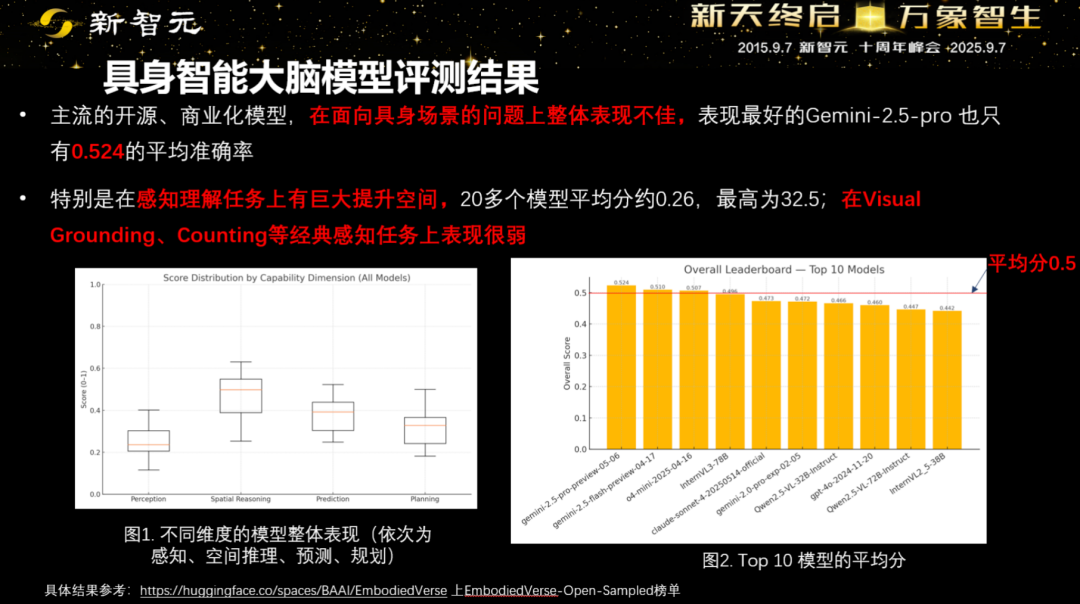
另一方面,智源在Hugging Face上提供了大脑模型的评测方法和结果,给业界分析了各种通用VLM模型与「大脑模型」所需要的物理世界感知理解能力的明显差距。差距在哪里,下一步的方向就应该在哪里。

一句话概括:不只要训得起,更要跑得起、迁得快。
现实世界里,云端和端侧用的芯片家族不同,国内外生态又百花齐放。
如果每换一次芯片都要推倒重来,具身智能永远跑不出规模效应。这就是FlagOS要解决的问题:面向多种AI芯片的统一开源栈,将「编译器-算子库-框架-通信库」一体打通,既统一抽象、又兼容差异,实现跨芯迁移与端到端优化。
智能的可复制性决定了边际成本。
统一栈就是把「一次适配、多处可用」变成现实,把研发精力从无休止的「环境折腾」里解放到算法与任务上。
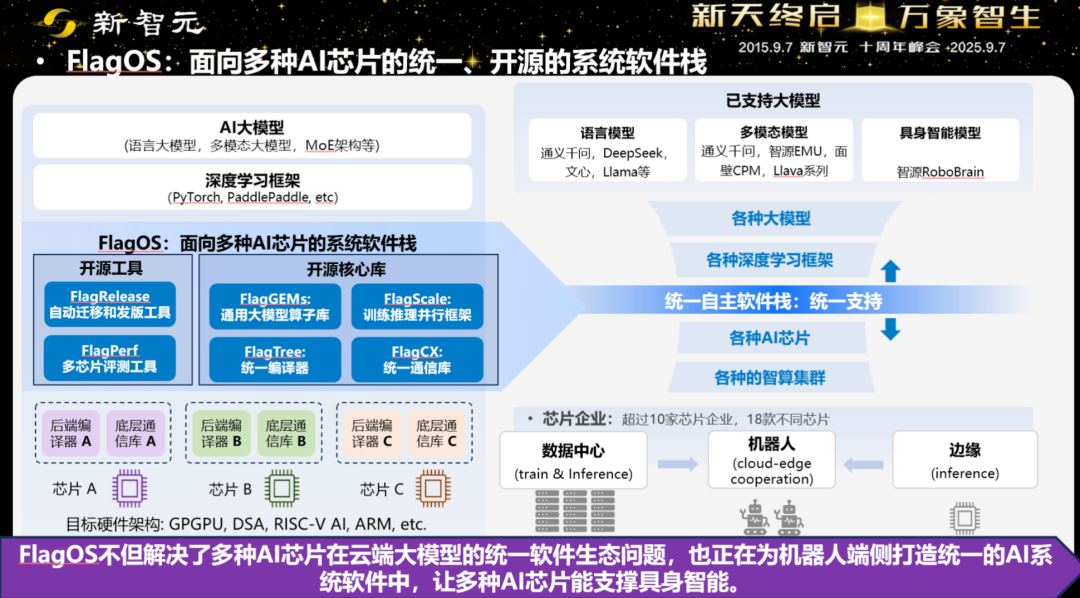
为此,智源研究院做了很多卓有成效的工作:
•跨芯迁移速度:大脑模型可以在一天内迁到一款与Orin pin-to-pin兼容的国产模组上,速度与指标都在线,这在过去几乎不可想象。
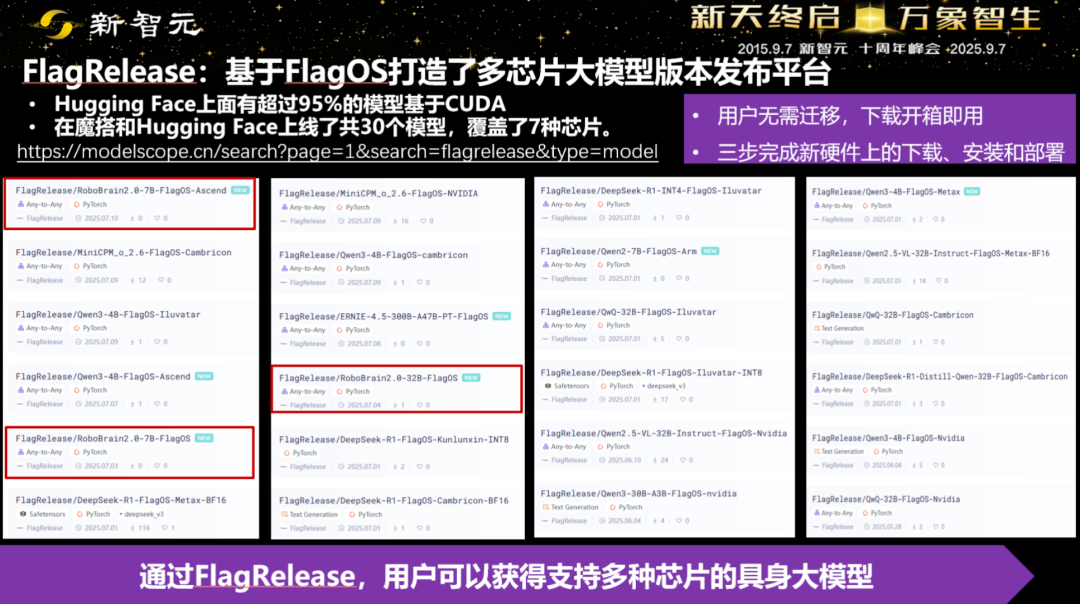
•开源可取用:在HuggingFace与魔搭上,基于FlagOS的模型列表已经涵盖英伟达、华为、寒武纪、乃至ARM等多种版本。像RoboBrain这样的具身大脑模型,能找到「开箱即用」的跨芯包。
•端云协同:模型在云上训、端上跑,跨芯部署与时延控制协同考虑,形成闭环。
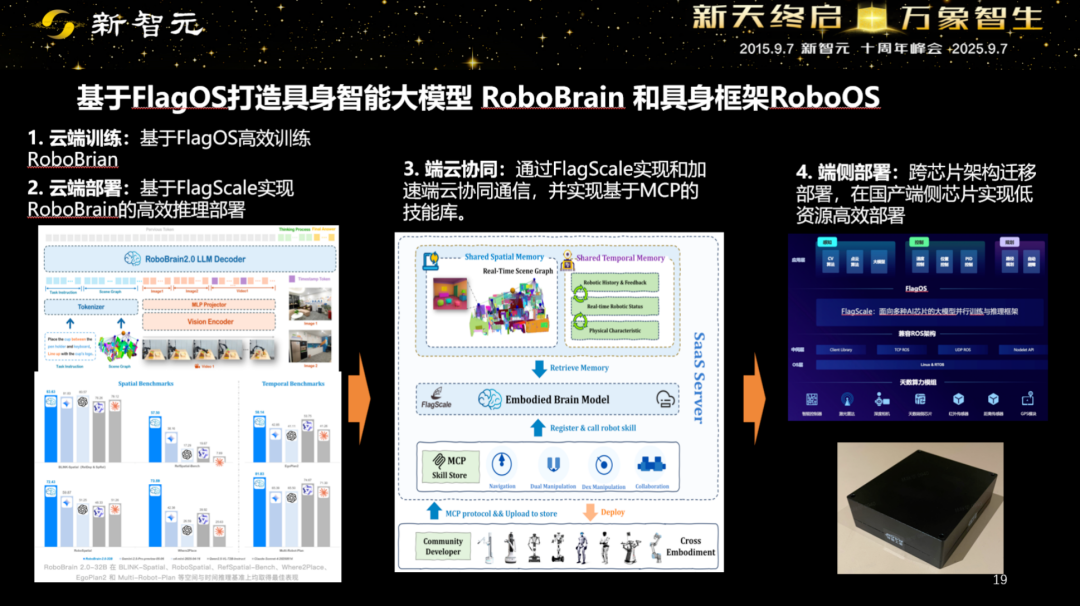
行业初步共识是分层范式:大脑模型负责理解与规划,小脑模型(VLA)负责把计划翻译成可执行的动作控制信号。
在这个范式下,研究机构更可能开源通用性更高的大脑/小脑基座,垂直行业基于这些基座做小样本后训练,落到具体场景。
智源的三件基础工作(数据-评测-系统软件)恰好卡在这个范式的关键节点。再加上电池与功耗这些工程制约,光模型强大还不够,因为这是一个系统。
谈落地前,下面这三条是关键:
•够聪明(复杂环境下连续任务稳定完成);
•够划算(效率与成本能打平、长期运行可控);
•能做人做不了或不愿做的事(危险、枯燥、极端)。
满足其中至少一条,才有望规模化进入行业与家庭。


林咏华在演讲中也提醒了我们:不少人都看过「机器人发疯」的视频。
一旦失控,你拔不了电源线(供电是电池)、也拽不掉网线(通信走Wi‑Fi/5G)。
这和工业机械臂旁边有个物理急停按钮完全不是一个难度等级。
具身的「危险边界」天然比纯软件更近现实世界一大步。
没有一套被产业验证的多级兜底,难谈「进千家万户」。

某种意义上,可控性是走向ASI的「入场券」。
越强的智能,越要可解释、可约束、可急停,这也是给未来多留条退路。

当下,大模型进入具身逐步成为共识,但必须分层(大脑/小脑),且需要更强的VLA通用基座+更广硬件覆盖+更高质量真机数据。
智源的路径正是顺着这条线往前推进,把「分层范式」所需的「数据-评测-系统软件」三环补全。
还有一个行业现实:仿真仍在探索阶段,能替代一部分,但很难替代「与世界的真实接触」。
越是抓握、摩擦、形变、重量这些细节,越不能指望仿真一步到位。
所以,接下来更像一场「耐力赛」:
把「真实世界的不确定性」不断拉进训练与评测闭环,把失败样本与极端工况当宝贝一样收集,然后再靠系统软件把结果搬到端上稳稳地跑。
大脑模型已发布,小脑模型还在不断探索和进步的路上;
采集效率提升、过程评测成形、跨芯生态铺开——这几件事串起来,就构成了智源的「具身底座」。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢