

赛题背景
本文分享赛题来自“中国石化第一届人工智能创新大赛”,大赛由中国石油化工集团有限公司主办,聚焦能源化工产业。赛题覆盖了产业链上中下游的不同任务,包括勘探开发、炼化生产、油品销售、智能营销和智能金融等关键支撑环节。
目前大赛全部10道赛题均已上线,开放数据集下载、提交评测,来自全国顶级高校、科研院所以及人工智能领域研发企业的学者、研究人员、技术开发者将共同参与赛事角逐,集智创新。
本次大赛设置了丰厚的大赛奖励,总奖金80万元人民币,其中每个赛道奖金8万元人民币,分设一等奖、二等奖、三等奖。此外,获奖团队还将获得组委会颁发的荣誉证书,有机会获得名企实习机会,作品孵化机会等,针对应用潜力大的优秀项目团队有机会获得额外激励。
大赛官网:https://aicup.sinopec.com/?source=bl03
赛题Baseline分享
Baseline代码下载:https://pan.baidu.com/s/1GYcrdGEE3H1cBgmtawgW7g?pwd=smv3
本期讲者从赛题介绍、评价指标、数据集解读以及解题思路(baseline代码讲解)四个方面进行分享。
一、赛题介绍
1.背景
地下石油并非储存在巨大的油湖中,而是分布于岩石的微小孔隙内。油田开发初期依赖地层自身的天然压力进行开采,但随着压力逐渐衰竭,油井产量会大幅下降。为维持产量,工程师采用水驱开发技术,即通过注水井向油层注水,以补充地压、驱赶原油。本次竞赛的数据就来自于一个进入水驱开发中后期的油藏,其动态调控的复杂性和重要性尤为突出。
水驱开发的核心挑战在于,水的流动性比油更好。若注采调控不当,注入水会沿高渗透通道直接流窜到生产井,形成无效水循环,大幅降低石油的最终采收率。因此,如何精确地协同调控多口注水井的注水量和生产井的产液量,以最大限度地驱替石油而非“水”本身,是决定油田开发经济效益的关键技术难题。
目前,注采参数的优化主要依赖工程师的经验和耗时的数值模拟,难以实时捕捉多口井之间的动态干扰。本次竞赛旨在探索一种新的解决方案:要求选手利用提供的油藏历史数据,构建人工智能模型,精准预测在给定的未来注采计划下,油井的含水率将如何变化,从而为油田的智能化决策提供支持。
2.竞赛任务
参赛选手需利用提供的油藏历史数据集,构建一个高精度的时空预测模型。具体任务是:依据油藏的静态地质数据和油井、水井动态数据。在给定各油井日度数据作为输入条件的前提下,精准预测出油井日度含水率(%)。

本赛题并非简单的建模问题,是在时间和空间上都是有一定的难度的。所以我们在构建模型的时候需要考虑到业务的背景。
二、评价指标
本次比赛将采用均方根误差 (Root Mean Squared Error, RMSE) 作为核心的、决定排名的唯一评价指标。
RMSE是衡量模型预测值与真实值之间差异的常用指标。对于本赛题,它将被用来计算所有测试井在所有测试月份的预测含水率与真实含水率之间的总体误差。
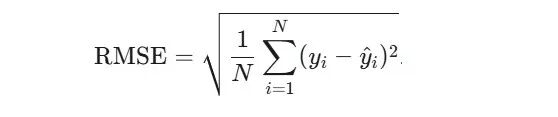
N: 是需要预测的总数据点数量,即 (测试的油井总数) × (测试的总月数)。
y_i : 是第 i 个数据点的真实含水率(%)。
y ^ {hat}_ i : 是参赛选手针对第 i 个数据点提交的预测含水率(%)。

三、数据集介绍
本次比赛数据集包含了多个文件,分别是静态数据和动态数据。静态数据是指:这部分数据在短期内不会发生变化的,比如说油井的具体的位置以及井与井之间的三维空间关系;在具体的位置和它的倾角以及方位角的关系;以及每口井在不同深度下的地质分层,以及历史的射孔作业记录等等,这些是短时间不会发生变化的。
在这部分的数据里面有一个比较特别的信息,对地质的分层有一个命名的体系。所以我们在对于这部分数据集做处理的时候,需要单独的对地质分层的数据这个字符串进行处理。静态数据虽然说短时间不会发生改变,但是在历史的射孔数据集中间也是存在不同的时间段的,所以可以被视为一种动态数据。
动态数据包含月度以及日度的油、水井的注水记录和一些参数的调整记录。动态数据分为两部分,一部分是训练集,一部分是验证集。

接下来我们直接观察下比赛的原始数据集,我们可以看到数据集包含了多个字段,这些字段分别对应特定的逻辑含义,可以在赛题的主页面(https://aicup.sinopec.com/competition/SINOPEC-03/)找到详细的介绍,另一方面也可以借助于一些专业资料或者大模型来看一看这些字段具体的含义。
数据集中包含了井号,也就是每口油、水井的编号,还有一些是特定的三维信息,以数值形式做呈现。还有生产层位,刚才我们提到的,它是石油行业以及地质行业中特定的带有逻辑的一串编码,我们需要去对它进行具体的解析。其次在数据集中也是包含了日期,我们可以看到对于训练集而言,包含了每口油、水井在某个生产层位的某一天的采集情况,以及含水率的记录。这是我们的数据集的大体情况。
通过上述的介绍,相信各位参赛选手对比赛进行有了一定的了解。接下来我们就来看一看这场比赛我们应该以什么样的思路去解决。
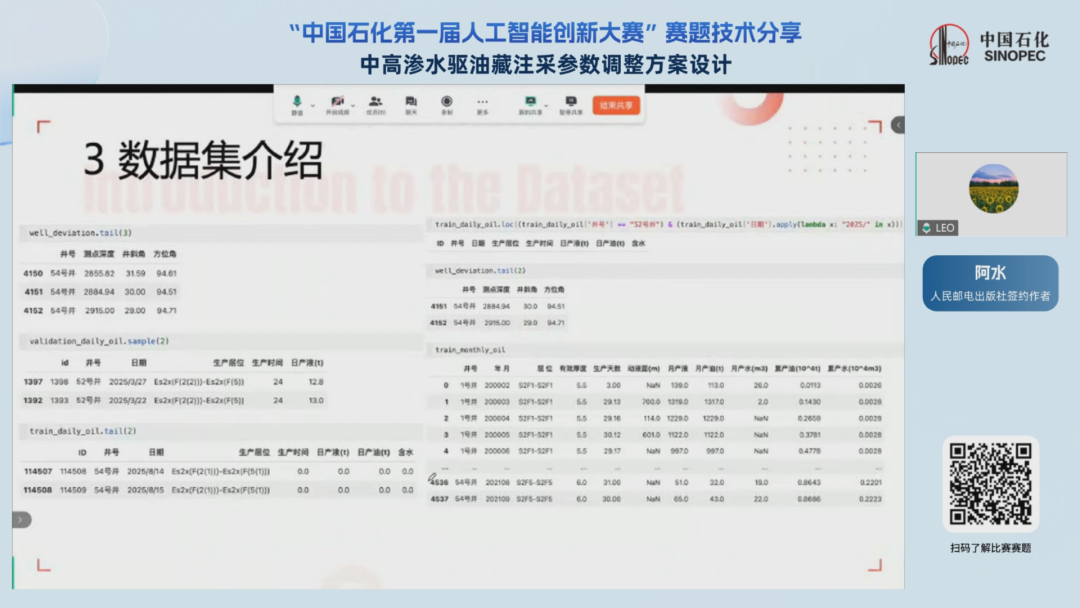
四、解题思路(Baseline代码详解)
我们先来看一下赛题的特点。首先本次赛题是一个比较典型的数据挖掘的题目,一方面原始数据以表格的形式进呈现,另一方面数据也都是都是比较规整的,这是赛题数据集的特点。
其次数据集中包含了两部分的关键因素,一个关于时间的,另一个是关于空间的信息。所以我们在建模的时候,如果想要做额外的特征工程,则需要从这两方面去进行考虑,这是第二个特点。
第三点是一些时间以及与时间相关的信息。如果我们仔细去观察数据集的话会发现赛题数据集是每口油、水井的的观测信息,也具备相关的射孔作业的信息。这意味着每口油、水井可能在不同的时间下,采用不同的流程去进行采集石油,或者说进行注水的操作,这意味着每口油水井自身的一些属性可能也会存在着一定的变化。
所以在建模时,我们需要去按照时间的维度,然后考虑对油、水井以及不同的层位做一个简单的、按照时间维度的排序。
此外比赛的数据集其实包含了很多关键信息。所有的数据集虽然是表格数据,并且以非常规整的形式进行存储,但是如果我们想要从原始数据集中间挖掘出一些关键的信息,则需要自己去写代码完成,然后挖掘出其中关键的特征,再进行建模。最后再进行机器学习建模的部分。
本次赛题仍然是一个典型的数据挖掘任务,所以我们仍然非常建议各位参赛选手可以用一些机器学习的模型进行建模,那么下面我们就开始赛题思路及代码的具体演示。
各位参赛选手如果已经配置好环境之后,就可以开始动手去写代码了。只需要有4GB 内存的CPU就可以参加本次比赛,不需要有额外的 GPU以及其他的硬件要求。
首先我们用Pandas读取一下比赛的数据集,可以看一看数据的一些基础信息。
import pandas as pdimport numpy as npfrom sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import mean_squared_errorfrom lightgbm import LGBMRegressorfrom sklearn.model_selection import cross_val_predictfrom sklearn.metrics import mean_absolute_errorwell_info = pd.read_csv("初赛发布/坐标_well_info.csv") # 井位坐标数据表well_info = well_info.rename({"井 号": "井号"}, axis=1)well_deviation = pd.read_csv("初赛发布/井斜_well_deviation.csv") # 井斜数据表well_perforation = pd.read_csv("初赛发布/射孔数据表_well_perforation.csv") # 射孔数据表train_monthly_oil = pd.read_csv("初赛发布/单井油井月度数据__monthly_oil.csv")train_monthly_water = pd.read_csv("初赛发布/单井水井月度数据_monthly_water.csv", encoding="gbk")train_daily_oil = pd.read_csv("初赛发布/单井油井日度数据train_daily_oil.csv")train_daily_water = pd.read_csv("初赛发布/单井水井日度数据_daily_water.csv")train_daily_water['日期'] = pd.to_datetime(train_daily_water['日期'])validation_daily_oil = pd.read_csv("初赛发布/单井油井日度待预测数据_validation_without_truth.csv")sample_submission = pd.read_csv("初赛发布/sample_submission.csv")# Print the first few rows of each dataframe to verify they have been loaded correctlyprint("Well Info:")print(well_info.head())print(well_info.columns, well_deviation.shape)print("\nWell Deviation:")print(well_deviation.head())print(well_deviation.columns, well_deviation.shape)print("\nWell Perforation:")print(well_perforation.head())print(well_perforation.columns, well_perforation.shape)print("\nMonthly Oil (Train):")print(train_monthly_oil.head())print(train_monthly_oil.columns, train_monthly_oil.shape)print("\nMonthly Water (Train):")print(train_monthly_water.head())print(train_monthly_water.columns, train_monthly_water.shape)print("\nDaily Oil (Train):")print(train_daily_oil.head())print(train_daily_oil.columns, train_daily_oil.shape)print("\nDaily Water (Train):")print(train_daily_water.head())print(train_daily_water.columns, train_daily_water.shape)print("\nDaily Oil (Validation):")print(validation_daily_oil.head())print(validation_daily_oil.columns, validation_daily_oil.shape)print("\nSample Submission:")print(sample_submission.head())print(sample_submission.columns, sample_submission.shape)

最上面展示的是静态数据,包括了井位的坐标,它和我们的本次比赛是紧密相关的,因为这个坐标其实已经是做了一个匿名的处理,可能和经纬度有一定的关联,但可能还是有差异。
坐标信息代表了每口井在地面上的精确的位置,也反映了每口井之间的相互的联系,因为油、水井之间的一个距离会最终影响到产油量。所以每口井之间的相互位置是一个非常重要的基础信息。通过坐标,我们可以换算出两口水井之间的距离和相对的范围。
其次是井斜数据,因为每口油井的方向可能不是垂直向下,可能会存在明显的三维轨迹,所以在第二个数据里面记录了倾斜和方位角的一些信息。
第三部分是射孔数据,这部分数据非常非常关键。我们在最终去做预测的时候实际上是对每一口井的层位去做一个建模。射孔是流入井的通道中在钢制套管上打的一些孔眼,它对应了不同的位置。这部分数据也包括了射孔的一些具体的层以及它的厚度等信息。同时射孔数据的起止时间也非常关键。

接下来是动态数据。这一部分包括了按照月度的日度的每口井在不同生产层位的具体的日产油、日产液以及含水率。从原始数据集中可以大致看到,我们最终去做建模的时候,其实是以每口井在不同的生产层位,对应的不同时间下的含水率。
所以这一部分包含了油水井在生产和注入过程中间各项指标随着时间的变化,并且需要与井号和生产层位关联在一起,因为不同的井号、不同生产层位对应的数据不一样。我们可以大致可以看出一个规律,随着时间的推移,井在生产层位中的含水率是逐步增加的,并且增加的频次不会特别大。
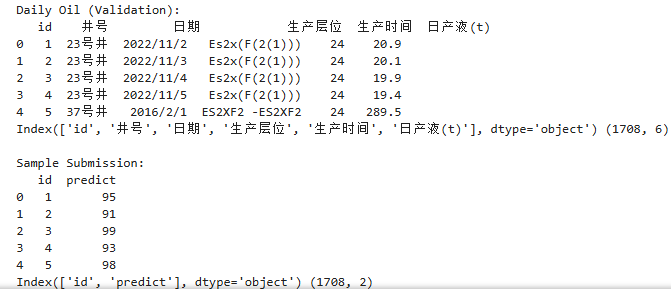
最终需要提交两列 ID和predict,ID是和验证集的数据表相关联的,也就是我们需要去提交的格式是某口井在某个生产层位下的某一天的含水率。
如果我们把日度数据的训练集和验证集一起打印出来,可以得到一个规律。
通过对比,对于训练集而言,每口井在不同层位的生产时间可能早于验证集,所以验证集的时间划分可能跟训练集在时间上存在交叉,因为每口井的观测时间是不一样的。所以赛题的时间信息是来自于日期,空间信息则来自于井号和生产的层位。所以时空信息在这些字段上面可以体现出来。

接下来我们挑选数据集中的某一口井的某一个层位做可视化处理,按照 x轴是时间,y轴是含水率以及日产油,如果我们把它汇聚在一起可以看到这两个曲线的整体趋势是相反的,大家可以猜一猜这两条曲线分别哪一条代表代表的是含水率,哪一条代表的是日产油?

上面的这条曲线代表的是它的含水率,下面的一条曲线代表的是日产油。因为在本赛题中石油开采过程是一个不断注水的过程,我们需要保证地下的压力足够让石油采集出来,所以在开采时会不断地注水或者是一些含水的泥浆进去。
在这个过程中随着时间的推移,某口油井在某个层位的含水率就会不断增加。也就是随着注入水的增加,对应能够采集的石油也就越少,总体上是这样的一个逻辑。所以从可视化的角度以及相关性的角度都可以得到类似的结论,含水率和日产油以及时间是负相关的。
接下来我们来看生产层位这一字段,中间的“-”代表采集是从其中一个层位到另一个层位。通过查阅一些资料我们可以了解到层位是与地质的一些信息相关联,比如代表地下岩层的年份、岩层的编号,即可以对应时间以及距离。
我们可以看到一些油井的开采位置可能在单一层位进行开采,也可能是在多层一起开采。所以生产层位的字段是一个复杂的字符串,对于这部分数据我们需要单独做处理。
我们可以去提取生产层位的大层位以及小层位以及开采的位置,以及开采的某一层到另一层位的距离信息,我们可以使用正则表达式提取这部分关键信息。
接下来我们就可以基于上述的一些发现去做一些建模了。首先我们在做建模的时候,一定要明确我们最终的样本,或者是我们预测的维度是什么。我们需要预测的样本是某口井,在某个层位,在某个时间的含水率,这是我们需要去做一个建模的最小样本的含义。
所以我们可以从多个角度去做特征工程,比说从井的角度,我们可以统计这口井的深度以及三维信息;我们从某一位的角度,可以从某一层去做特征提取;也可以从某个时间上面去统计它历史的含水率的变化。
所以在接下来的特征工程,我们也是按照这种思路,围绕着我们样本的含义去做特征工程。我们将这些特征合并完成之后就可以去进行训练和验证。
需要注意的是在本次比赛中,数据集样本数量比较少,在训练的时候可能整体的波动性比较大。
最终我们需要去预测1,708个样本,训练集大约是11万个样本。通过上述的特征工程,我们可以构建一个回归模型,在回归模型中用决策树去做预测,然后进行提交评测。总结来说本次赛题的基础思路是围绕样本的组成,从时间维度、空间维度去提取一些特征工程去做建模。
train_set = pd.merge(train_daily_oil, well_info, on = "井号", how="left")train_set["日期"] = pd.to_datetime(train_set["日期"])train_set["日期"] = train_set["日期"].dt.to_period('M')train_set["日期"] = train_set['日期'].dt.to_timestamp()well_deviation_agg = well_deviation.groupby("井号").agg({"测点深度": ["min", "max"],"井斜角": ["max", "nunique"],"方位角": ["max", "nunique"]})well_deviation_agg.columns = [x[0] + "_" + x[1] for x in well_deviation_agg.columns]well_deviation_agg = well_deviation_agg.reset_index()train_set = pd.merge(train_set, well_deviation_agg, on = ["井号"], how="left")train_daily_water_agg = train_daily_water.groupby(["井号", "日期"]).agg({'干压(Mpa)': ["min", "max", "sum"],'油压(Mpa)': ["min", "max", "sum"],'日配注(m3)': ["min", "max", "sum"],'日注水(m3)': ["min", "max", "sum"],})train_daily_water_agg.columns = [x[0] + "_" + x[1] for x in train_daily_water_agg.columns]train_daily_water_agg = train_daily_water_agg.reset_index()train_set = pd.merge(train_set, train_daily_water_agg, on = ["井号", "日期"], how="left")train_monthly_oil['年月'] = train_monthly_oil['年月'].astype(str)train_monthly_oil['年月'] = pd.to_datetime(train_monthly_oil['年月'], format='%Y%m')train_monthly_oil['日期'] = train_monthly_oil['年月'].dt.to_period('M')train_monthly_oil["日期"] = train_monthly_oil['日期'].dt.to_timestamp()train_set = pd.merge(train_set, train_monthly_oil, on = ["井号", "日期"], how="left")train_set = train_set.drop(["ID", "井号", "日期", "生产层位", "年月", "层位"], axis=1)test_set = pd.merge(validation_daily_oil, well_info, on = "井号", how="left")test_set["日期"] = pd.to_datetime(test_set["日期"])test_set["日期"] = test_set["日期"].dt.to_period('M')test_set["日期"] = test_set['日期'].dt.to_timestamp()test_set = pd.merge(test_set, well_deviation_agg, on = ["井号"], how="left")test_set = pd.merge(test_set, train_daily_water_agg, on = ["井号", "日期"], how="left")test_set = pd.merge(test_set, train_monthly_oil, on = ["井号", "日期"], how="left")test_set = test_set.drop(["id","井号", "日期", "生产层位", "年月", "层位", ], axis=1)pred = cross_val_predict(LGBMRegressor(), train_set.drop(['含水'], axis=1).fillna(0), train_set["含水"])mean_absolute_error(train_set["含水"].values, pred)model = LinearRegression()model.fit(train_set.drop(['含水', "日产油(t)"], axis=1).fillna(0), train_set["含水"])pred = model.predict(test_set.fillna(0)).astype(int)validation_daily_oil["predict"] = predvalidation_daily_oil[["id", "predict"]].to_csv("result.csv", index=None)
五、进阶思路
本次赛题仍然是一个数据挖掘的回归类型的赛题,baseline中没有做很多的特征工程,后续大家如果想去做一些改进,可以考虑围绕着空间和时间去增加更多的特征。
当然特征也需要考虑进行一些筛选,因为数据集本身是非常离散的,特征提取的维度可以从每口井和不同井之间的距离以及一些空间地理位置。
如果从可视化角度,可以看到某一口井的生产层位的含水率不会波动特别大,可能是逐步稳步上升的,所以我们在做特征工程的时候也可以考虑以某口井某个生产层为的历史含水率,直接去构建一个线性模型。也就是在做建模的时候仅利用含水率与时间做线性回归。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢