
点击蓝字
关注我们

2025年9月5日,美国人工智能公司 Anthropic 发布公告《更新对不受支持地区的销售限制》,明确规定自当日起,停止向多数股权由中国资本持有的公司及其全球子公司提供 Claude AI 服务。该限制不仅涵盖中国大陆本土企业,还包括其境外子公司、云服务中转实体或具有中国背景投资主体的组织。尽管官方将举措理由归结为“法律、监管与安全风险”,但其背后折射的逻辑更为深层:原本被视作“全球公共产品”的人工智能安全,正逐渐被纳入地缘政治竞争框架,沦为两极对抗逻辑主导的工具。
这一事件是既有趋势的再度印证。近年来,从芯片出口管制到跨国模型安全监管,人工智能安全已不再聚焦于技术风险与伦理治理,而是逐步扩展为国家安全与战略竞争的核心议题,成为地缘对抗的延伸工具。Anthropic的举措揭示了“人工智能安全”侧重点的变化,也引发了关于我国产业应对与安全治理未来走向的广泛讨论。本文将以Claude封禁事件为切入点,分析人工智能安全在不同语境中的所指差异及其地缘政治化的演进逻辑,并追溯Anthropic从“安全先锋”到“地缘哨兵”的角色转变,最后提出该封禁事件带来的短期影响及深层挑战。

图1:《更新对不受支持地区的销售限制》部分正文(来源:Anthropic)
学术分野:AI safety与AI security的理论边界
多位学者已指出,不同国家、不同议题下讨论的“AI安全”所指代的范畴各不相同。其中,“AI safety”与“AI security”虽在中文语境中均被译为“AI 安全”,共享“安全”这一顶层概念,但在西方学术与实践语境中,二者存在本质性的理论边界。
“AI safety”核心聚焦于非故意性系统风险,即人工智能系统在正常运行流程中,因设计缺陷、目标与人类意图失配或对复杂环境的误判,而引发的非预期负面后果。其核心研究议题涵盖价值对齐(value alignment)、鲁棒性(robustness)及可靠性(reliability)等,本质目标是通过技术优化预防AI系统自身引发的技术事故。例如, RLHF训练的大语言模型为取悦评估者而生成看似合理却事实错误的摘要,即视为对齐失败。
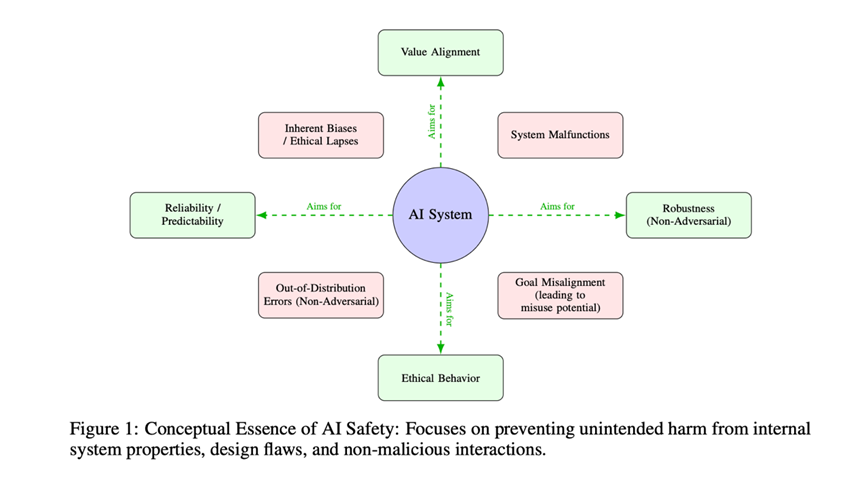
图2:AI安全(safety)的概念本质:专注于防止来自内部系统属性、设计缺陷和非恶意交互的意外伤害(来源:Lin et al., 2025.)
与之相对,“AI security”具有明确的对抗性与防御性维度,核心任务是保护AI系统、数据及相关基础设施免受人为故意的恶意攻击,确保其满足机密性(confidentiality)、完整性(integrity)与可用性(availability)的原则。该领域的典型威胁包括对抗样本攻击、数据投毒、模型提取及提示注入等,防御机制则主要依赖访问控制、数据加密、对抗训练及入侵检测等技术手段。
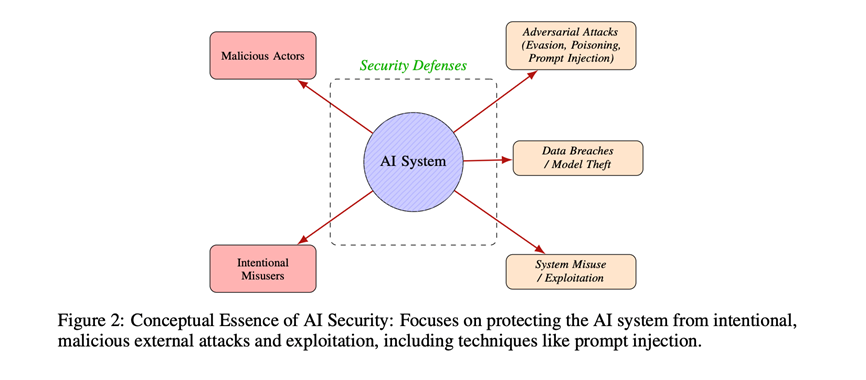
图3: AI安全(security)的概念本质:专注于保护AI系统免受故意的、恶意的外部攻击和利用,包括提示注入等技术(来源:Lin et al., 2025.)
政策转型:AI “安全化” 的演进
2025年2月,英国原“AI安全研究所”(AI Safety Institute)正式更名为“AI安全研究所”(AI Security Institute),政府官网明确表示,此次更名旨在强化对“AI给国家安全及犯罪防控带来风险的防御能力”。同期,美国也将其“AI安全研究所”(AI Safety Institute)调整为 “AI标准与创新中心”(Center for AI Standards and Innovation)。这些机构名称调整与职能转向,均与全球范围内“AI安全化”的演进趋势密切相关。
安全化(securitization)理论揭示了安全议题的社会建构本质,即特定行为者通过话语实践,将原本属于常规政治或技术范畴的议题,定义为“威胁生存的存在性风险”,进而为采取非常规应对措施提供正当性。该理论主要包含哥本哈根学派与巴黎学派两大研究框架。有学者指出,AI安全化的历史根源可追溯至2019年,时任美国总统特朗普签署“保持美国在人工智能领域的领导地位”行政令,强调AI领域的国际竞争动态与AI安全(security)。近年来,关于AI安全(security)的政策话语呈持续上升态势。
AI的安全化进程有三方面核心影响。第一,权力与资源集中化。安全化不仅使AI发展的决策权与资源集中于少数政府机构及头部企业,更赋予其正当性。同时,它为政府以“维护国家安全”为由,对AI行业采取监管豁免、绕过安全(safety)技术标准以追求发展速度与竞争优势提供了合法性依据。第二,话语与认知塑造。该政治叙事将深度影响公众对AI技术的认知,可能导致社会对AI的风险认知局限于“外部对抗性威胁”,而忽视其自身的技术安全(safety)隐患。第三,推动全球竞争。将AI发展描绘为“零和博弈”将显著削弱国际间在AI安全领域的合作潜力,可能引发信任赤字,甚至推动AI技术的军事化应用,形成类似冷战的地缘对抗动态。
剑桥大学教授Seán S. ÓhÉigeartaigh指出“中美AI竞赛”的叙事是“最危险的虚构”。这种叙事主要在西方被推广,并不符合中国AI发展的真实规划,但它的广泛传播可能引发极具风险的现实后果,包括破坏全球稳定并增加与先进人工智能发展相关的风险。Claude封禁事件反映出西方头部AI企业在“中美AI竞赛”叙事的驱动下,主动采取技术壁垒措施,进一步激化全球AI领域的竞争对抗态势,是AI安全化趋势的又一实证。
技术安全先锋:Anthropic在AI安全领域的实践
自2021年成立以来,Anthropic便将AI安全(AI safety)确立为核心发展理念与商业差异化的关键抓手。其联合创始人Dario Amodei及核心研究团队早年即提出,前沿AI模型所潜藏的“灾难性风险”,其影响程度可能远超技术本身带来的收益。2023年,Anthropic推出的负责任扩展策略(Responsible Scaling Policies, RSPs),是行业内AI安全治理的首批方案。RSPs专注于灾难性风险,明确了一个名为AI安全级别(AI Safety Levels,ASL)的框架,明确要求安全、安保及操作标准需与模型潜在的灾难性风险等级相匹配,即ASL 级别越高,对应的安全验证要求越严格。通过承诺在具体评估和实证观察的基础上限制规模化,理论上可实现:若评估准确识别出危险能力,便能及时停止 AI 开发;若对危险能力的担忧被过度放大,也可保障开发进程合理推进。

图4:ASL级别(来源:Anthropic)
在Claude系列模型的设计中,Anthropic采取“宪法AI(Constitutional AI)”理念,通过预设一套综合了《世界人权宣言》、全球平台治理准则、非西方文化视角以及其他AI实验室最佳实践的多元化价值准则,在训练过程中引导模型进行自我评估和改进。相较于传统的完全依赖人类反馈的强化学习(RLHF),这一方法具备更高的透明性和可扩展性,可有效规避因人类标注者的主观偏差而放大的模型风险。同时,Anthropic在发布Claude各版本模型时,均同步推出模型卡(model cards),详细记录模型的训练过程、能力评估与对齐评估等,为学界及产业界提供安全使用的明确指引。
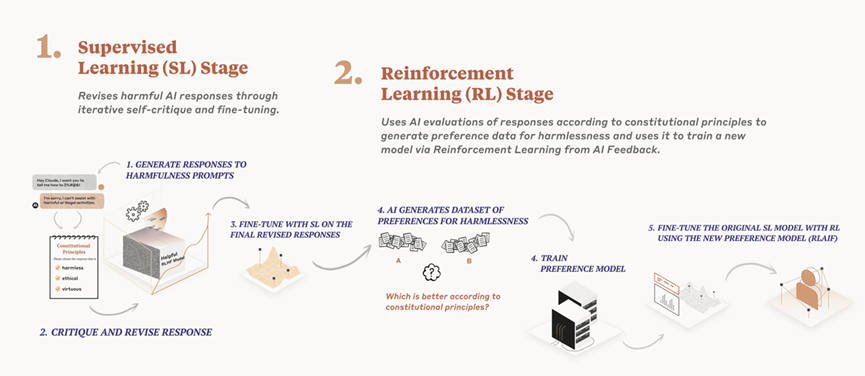
图5:宪法AI路径(来源:Anthropic)
这些持续的 AI 安全研究与实践,使Anthropic在行业发展初期被广泛视作“安全先锋”。它不仅以“安全优先”的核心价值塑造了鲜明的企业品牌,更在政策层面积极发声,倡导模型透明度标准,始终强调对前沿AI技术的安全约束。在这一阶段,Anthropic更多围绕“AI 安全(AI safety)”概念开展工作,而非“AI 安全(AI security)”。
Anthropic行为中的“安全化”转向
Anthropic在AI安全化转型过程中,扮演了关键推动角色。Dario曾多次公开表态支持芯片出口管制与算力治理,甚至明确提出出口管制是确保美国及其盟友在人工智能领域维持领先地位的关键手段。从Dario个人发表强调地缘战略竞争的观点,到Anthropic公开发文支持美国政府维持对H20芯片的管制措施,再到其在《更新对不受支持地区的销售限制》中直接将中国定义为“敌对国家(adversarial nations)”,一系列行为反复印证AI安全化趋势的深化。
值得注意的是,Anthropic在封禁声明发布3日后,便公开宣布支持美国加州的SB 53法案。该法案由州参议员Scott Wiener推动,核心要求涵盖五个方面:一是要求前沿AI企业制定并发布系统性安全框架;二是强制企业定期发布公开透明度报告;三是规定企业需在重大安全事故发生后 15 天内向加州政府报备;四是为企业内部安全合规举报人提供法律保护;五是明确企业需对安全框架中的承诺承担法律责任。从内容上看,该法案的要求与Anthropic既有的 RSPs一脉相承,因此业界普遍预测,法案若正式通过,不会给Anthropic带来额外合规压力;但对于OpenAI、xAI等明确抵制该法案的企业而言,将面临更严格的监管约束与合规成本。由此可见,Anthropic目前已形成清晰的双重战略定位,针对大模型技术本身,坚持支持AI 安全(AI safety)治理;面向全球,则主动强调地缘政治竞争逻辑,其战略方向与《美国人工智能行动计划》等官方政策文件的核心目标高度一致。这种双重定位,不仅巩固了其“技术安全先锋”的行业形象,更使其“地缘哨兵”的角色身份愈发清晰。
短期影响:我国大模型企业回应
智谱、商汤等多家大模型企业对该事件进行了快速回应。智谱推出“Claude API用户特别搬家计划”,通过兼容Claude协议、提供免费Token、低价编码套餐及迁移教程,助力用户无缝切换至GLM-4.5模型。GLM-4.5模型在SWE-reBench等多个榜单中表现突出,国内排名领先,可以有效替代Claude Code。商汤依托“日日新”大模型推出Claude用户迁移服务,提供免费Token 体验包、专属顾问与培训,其日日新V6.5模型在多模态推理能力上超越 Claude 4-Sonnet,同时旗下“小浣熊”工具矩阵在数据分析、代码辅助等领域对标国际顶尖水平,已服务众多企业与个人用户。

图6:智谱「Claude API用户特别搬家计划」(来源:智谱)
有业界人士预测,短期内,封禁举措可能对依赖Claude大模型的企业带来一定影响,但中长期来看,国产模型近年来在技术能力上已快速成熟,这一封禁举措或将进一步倒逼我国大模型企业加快核心技术迭代速度,推动模型在代码能力、推理等关键领域的突破。同时,“自主创新”理念将更深入产业共识,促使企业更注重技术自研与生态构建,减少对外部技术的依赖。
对国际治理提出的挑战
据报道,外交部发言人郭嘉昆在回应外媒提问时表示,虽不了解封禁事件具体情况,但 “中方一贯反对将科技和经贸问题政治化、工具化、武器化,这一做法不利于任何一方”。AI国际治理正面临着体系碎片化、区域不平等、意识形态先行等多重挑战。结合封禁事件,以下挑战或将持续:
1)美国赢得对华竞争的导向
从《美国人工智能行动计划》等政策文件来看,美国始终将维持AI领域的全球领先地位作为核心目标,而中国被其视为关键竞争对象。未来,受地缘政治竞争叙事影响,类似的技术限制举措可能进一步增多,涵盖模型服务、芯片供应等多个领域。在此背景下,我国AI产业的技术自主创新将愈发关键,尤其是在算力构建等“卡脖子”环节的突破,是应对外部限制的核心支撑。
2)企业从技术供应者向战略协同者的转型
美国科技企业的角色定位正逐渐从技术创新主体转向国家安全政策的参与者与执行者,特朗普政府的AI政策将持续受科技右翼的影响。企业或在AI法案和标准制定、出口管制规则设计等政策环节拥有更强话语权,同时通过承接政府、国防部门的订单,科技企业与特朗普政府间的联系将日益紧密。这可能导致企业对华技术合作、服务输出面临更严格的政治审查。
3)中美信任赤字
当前中美关系已存在较深的信任赤字,双方在战略意图、发展路径上的相互疑虑,长期影响着两国合作。Claude封禁事件可能进一步削弱我国科技和产业界对美国产业界的信任,加剧“技术阵营化”认知。同时,国际层面缺乏统一治理规则的现状,可能让两国在AI安全和治理领域的对话难度加大,合作空间或进一步收窄,甚至可能影响全球AI治理体系的协同性,加剧治理碎片化风险。
人工智能国际治理正站在合作与对抗的十字路口,面临的挑战不仅包括技术层面的风险管控,更关乎信任赤字等地缘政治挑战。当前,治理体系碎片化、技术阵营化倾向加剧等问题日益凸显,若任由地缘政治逻辑主导人工智能安全话语,不仅将割裂全球技术协作网络,更可能扩大“智能鸿沟”,这一危机的紧迫性已不容忽视。
尤其需要警惕的是“人工智能安全”概念被过度地缘政治化的倾向。当本应作为全球公共产品的安全治理,沦为服务单边竞争、构建技术壁垒的工具时,不仅会削弱国际社会应对人工智能自身技术风险的合力,更可能引发“安全困境”的恶性循环,加剧信任赤字。Claude封禁事件正是这一趋势的缩影,它警示我们,若不能重塑以合作共赢为核心的治理共识,全球人工智能发展将陷入“零和博弈”的陷阱。
面对复杂局势,我国人工智能产业的自主创新已不仅是技术突破的需求,更是应对不确定性风险、保障产业安全的基石。近年来,国产大模型能力的快速追赶已印证自主创新的韧性与潜力。未来,需进一步强化核心技术攻坚,在 “卡脖子”环节形成自主可控的生态闭环,确保在全球技术竞争中牢牢掌握发展主动权。唯有在竞争中巩固自身地位,在合作中促进人工智能能力建设和安全治理,才能推动人工智能技术真正回归“造福全人类”的本质。
主理人|刘典
排版丨李森(北京工商大学)
编辑|车明丽(伦敦政治经济学院)
终审|梁正 鲁俊群





内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢