

自然语言处理中知识引擎的构建受到两种看似截然不同的范式的影响:一种以结构为基础,另一种则由海量可用的非结构化数据驱动。结构化范式利用预定义的符号交互(例如知识图谱)作为先验,并设计模型来捕捉它们。相比之下,非结构化范式则专注于扩展Transformer架构,使其能够处理日益庞大的数据和模型规模,正如现代大型语言模型所见。尽管两者存在分歧,但本论文旨在建立连接这些范式的概念联系。两种互补的力量——结构化和解构化——在两种范式中都出现了:结构化组织可见的符号交互,而解构化则通过周期性的嵌入重置,提升模型的可塑性和对未知场景的泛化能力。这些联系构成了开发通用知识引擎的新方法,这些引擎能够支持透明、可控且自适应的智能系统。


论文题目:Structure and Destructure: Dual Forces in the Making of Knowledge Engines
类型:2025年博士论文
学校:University College London(英国伦敦大学学院)
下载链接:
链接: https://pan.baidu.com/s/1riTuMMEiX5eXyPmg5E7c2A?pwd=aweg
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
1.1 构建通用知识引擎
人类长期以来一直致力于探索智能:试图理解智能的起源,通过训练提升智能,减缓智能随时间的衰退,并最终在机器中复制智能。这项努力的驱动力在于,我们希望将我们与生俱来的认知能力扩展到时间和空间之外,从而更高效、更有效地利用我们的智力资源——就像工业革命改变了我们实现自动化和增强体能的能力一样。
智能的显著特征之一是其处理和管理关于现实知识的能力。作为智能的机能,人类心智可以充当一个通用知识引擎,能够从各种来源获取信息,通过抽象化进行整合,检索信息用于相关任务的推理,并根据不断变化的环境进行更新。这个知识引擎支持我们完成各种各样的任务,从日常活动(例如规划日常通勤、管理个人日程或烹饪美食)到复杂的决策(例如制定交易策略、解决政治冲突、诊断疾病或撰写博士论文)。
在开发人工智能 (AI) 时,尤其是以模拟人类智能为目标时,复制通用知识引擎至关重要。这些知识引擎可以作为当今许多最具影响力的数字基础设施的支柱,例如搜索引擎、推荐系统和对话代理(例如虚拟助手和聊天机器人),支持我们的日常数字活动,如图 1.1 所示。然而,构建通用知识引擎并非易事。事实上,它一直是一个复杂的课题,也是许多研究领域的焦点,涵盖自然语言处理、信息检索、数据挖掘、机器学习和认知科学等学科。从深层次上讲,一个核心挑战在于整合各种知识来源并实时更新它们。
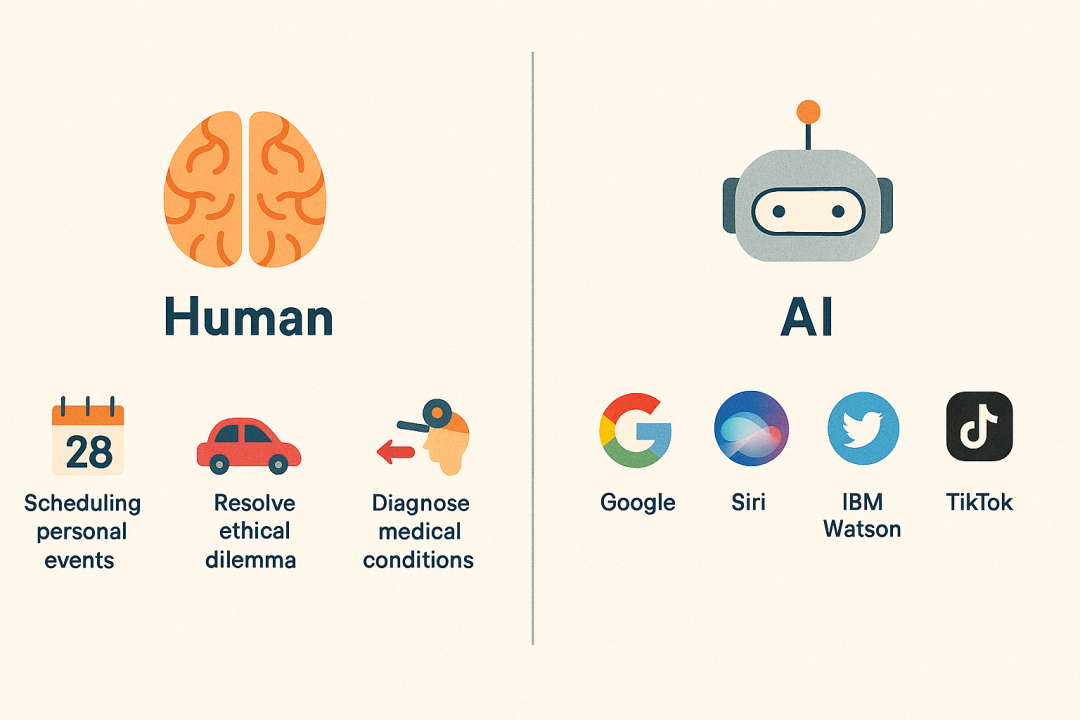
说明人类思维中的“知识引擎”如何促进各种人类活动,以及当前的数字知识引擎如何支持数字助理、社交媒体平台和推荐系统等应用。
为了更好地理解这一挑战,让我们考虑一个具体的例子:开发一个模仿人类医生的人工智能医生。我们可以先看看人类医生获取必要知识和技能的步骤。

我们可以看到,汤姆的思维如同一个知识引擎,将结构化知识源(例如药物相互作用)与非结构化洞察(例如整体症状评估记录)无缝融合,从而实现精准回忆,并指导明智的临床决策。另一方面,他与生俱来的好奇心,一种开放的思维方式,不断激发他完善、更新和扩展知识的动力,确保其知识与不断变化的医疗格局同步发展。同样,一个渴望模仿此类医疗专业知识的人工智能系统必须拥有一个知识引擎,能够利用结构化和非结构化资源来动态地获取、巩固、应用和更新知识。
本论文提出了一项科学探索,旨在理解为人工智能代理开发知识引擎的方法,以及如何将这些看似截然不同的方法统一到一个框架中,以创建能够适应未知环境的更通用的知识引擎。总体而言,构建通用知识引擎主要有两种范式:结构化范式和非结构化范式,详见1.2节。然而,仔细研究它们在训练和推理过程中的内部机制,以及它们在推广到新的、未知环境方面的共同局限性,就会发现这些方法之间的二分法有所减弱。这种融合为构建通用知识引擎提供了一条统一的、集成的途径。
本章的其余部分将概述这种统一和整合的动机和背景(1.2节)、研究目标和问题(1.3节)、方法论的简要概述(1.4节)以及论文结构的路线图(1.5节)。
1.2 二分法:结构化与非结构化
人类知识来源主要可以分为两种:结构化和非结构化。历史上,关于人工智能系统处理这两种知识形式的研究大多是各自独立的。
早期的人工智能浪潮以专家系统为特征,这种系统在 20 世纪 80 年代蓬勃发展 [HayesRoth et al., 1983]。专家系统主要依赖结构化知识来源,例如精心设计的知识图谱,用于明确实体之间的关系。相比之下,当代人工智能的发展越来越倾向于使用海量非结构化数据集(例如网络数据)作为构建最先进人工智能的基础。
在本文中,我们将这两种范式分别称为结构化范式和非结构化范式。我们注意到,从结构化数据到非结构化数据的转变并非二元划分,而是沿着一个相对结构化的光谱进行。例如,从语法角度来看,编码数据比自然语言数据更具半结构化特征;从概念组织角度来看,教科书数据比来自互联网的文本更具结构化和组织性。在承认这些中间形式的同时,本论文试图探讨典型的结构化和非结构化范式,如下所述。
1.2.1 构建知识引擎的结构化范式:以知识图谱为例
结构从根本上讲是关于不同部分如何相互关联以及如何组合以表征现实——无论是物理的还是虚拟的。这些结构对于人类组织和理解我们周围的世界至关重要。具体来说,我们的世界充满了物理结构,例如分子网络、蛋白质折叠模式和运输路线。从这个意义上讲,结构使我们能够有效地对物理世界的各种表现形式进行分类和支撑。另一方面,结构也可以是抽象的或虚拟的,例如社会互动、支配理性推理的规律或词语之间的层级关系。这些类型的结构帮助我们系统化对抽象概念和联系的理解。
在人工智能的发展史上,结构化知识源旨在以预定义的格式组织此类信息,例如知识图谱、数据库和其他关系结构 [Wang et al., 2017]。在这些格式中,符号按特定语法排列成固定长度的序列,每个位置都具有明确的角色。例如,在知识图谱中,知识三元组由三个部分组成:第一个位置通常表示主语(或头实体),第二个位置表示谓语(或关系),第三个位置对应于宾语(或尾实体)1。为了说明这一点,请考虑以下知识三元组的图表:
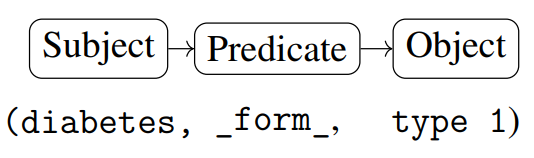
此图中的位置:
• 主语(或头部实体)是糖尿病。
• 谓语(或关系)是_form_。
• 宾语(或尾部实体)是类型 1。
这些知识三元组的集合构成了知识图谱。例如,图 1.2 中的图表展示了广泛使用的医疗保健知识图谱 SNOMED-CT 的一部分,该图谱在 [Donnelly, 2006] 中有详细介绍。
结构化范式围绕两个关键要素构建:数据格式和结构化表征学习。结构化知识通常以多维数组、稀疏图或三元组数据库等格式表示,这些格式能够明确描述关系,并能够分析传递性、反身性和反对称性等逻辑属性。在此背景下,表征学习侧重于将这些结构嵌入到模型计算中,例如使用因子分解模型 (FM) [Yang et al., 2016, Lacroix et al., 2018, Trouillon et al., 2016] 和消息传递图神经网络 (GNN) [Schlichtkrull et al., 2018, Vashishth et al., 2020, Zhu et al., 2021] 等方法。这些模型在大规模结构化知识库的自动化构建以及支持问答等下游任务方面都发挥着至关重要的作用。
基于结构化范式构建的知识引擎在需要可解释性、一致性和高效推理的应用中表现出色。例如,它们在充当世界模型方面发挥着核心作用,旨在全面地表征现实[LeCun,
2022]。知识图谱尤其被应用于各种领域,包括常识推理[Hwang et al.,2021]、数字孪生[Akroyd et al.2021]和基于文本的游戏[Ammanabrolu and Riedl,2021]。这些结构化模型也为一些最广泛的数字应用提供支持,例如:
• 知识库:专家系统(例如 IBM Watson Medical)的关键要素。
• 搜索引擎:支持 Google 搜索等工具。
• 推荐系统:支撑 YouTube 等平台。
• 社交媒体:增强 X.com 和 Instagram 等平台的功能。
• 智能助手:支持 Siri 等边缘设备上的智能系统。
1.2.2 构建知识引擎的非结构化范式:以预训练语言模型为例
最新一波人工智能浪潮,尤其是生成式人工智能,标志着向非结构化范式的重大转变,大型语言模型就是一个例证。这些模型吸收了大量非结构化文本,摆脱了传统上对结构化知识源的依赖。这种范式转变得益于 Transformer 架构,该架构证明了在大规模非结构化数据集上进行预训练可以生成基础表征 [Devlin 等人,2019 年,Radford 等人,2019 年,Brown 等人,2020 年]。
随着 Transformer 模型的出现,大多数算法的进步都集中在提高计算效率上,越来越强调扩展模型规模和数据集多样性,而不是数据或模型架构的结构复杂性 [Kaplan 等人,2020 年;Hernandez 等人,2021 年;Templeton 等人,2024 年]。由于成本高昂且复杂度高,准备结构化知识的重要性已经降低。相比之下,从网络上抓取各种非结构化数据的过程已成为一种更易于访问且可扩展的替代方案。
与结构化数据相比,非结构化数据以自由形式存在,其中符号在序列中的位置本身并不定义其角色。例如,在一个句子中,第一个词不一定是主语,最后一个词也不一定是宾语。这类知识通常被称为语料库、语料库或文本,通常表示为长度可变的序列。预训练大型语言模型的著名来源包括:
• Web 文本:最常用的 Web 数据集之一是 Common Crawl 自 2008 年以来构建的 PB 级 Web 数据存档 [Crawl, 2023]。其他类似的数据集包括 CC100 [Conneau 等人, 2020]、OpenWebText [Contributors, 2019] 和 RedPajama [Computer, 2023]。
• Web 代码数据:类似 Starcoder [Project, 2023] 的数据集,它从 GitHub 和 Stack Overflow 抓取代码库。
• 高质量参考资料:Semantic Scholar 的学术数据 PeS2o [Soldaini 和 Lo, 2023]、书籍数据古腾堡计划 [Hart 和志愿者, 1971–2024] 以及百科知识数据维基百科 [authors, 2024]。
非结构化范式促进了大规模语言模型的开发,这些模型可作为替代知识引擎。这些模型日益被认可为世界模型 [Petroni 等人,2019 年;Li 等人,2021a;Hernandez 等人,2023 年],在结构化数据稀疏或不可用的领域表现出色。通过处理非结构化数据,这些模型已被证明能够捕捉隐式关系和上下文,从而实现从回答问题到支持 ChatGPT 等对话式 AI 系统等广泛的功能。
1.2.3 两种范式的比较
结构化和非结构化的知识表示范式展现出截然不同的特征,如表 1.1 所示。因此,它们也各有优缺点,如表 1.2 所示。
结构化范式具有显著的效率优势。它允许重复使用结构化数据,无需为重复性任务从头计算解决方案。它还能提供稳定一致的计算结果,尤其适用于逻辑推理任务,例如知识图谱中的推理。尽管结构化范式具有这些优势,但它也面临灵活性方面的限制。具体而言,结构化范式可能存在限制,无法完全适应现实世界现象近乎无限的变化,并且容易出现条目缺失的情况。
非结构化范式则以其灵活性而著称。它可以表示和学习各种非结构化数据源,从而捕捉结构化系统可能遗漏的细微差别。非结构化范式对于需要生成能力的任务尤其有效,例如灵活地回答各种问题或根据给定的关键词生成卡通图像。然而,它们也存在一些明显的缺点:i)从非结构化数据中学习通常需要从头开始,计算成本很高。ii)模型生成可能难以控制,可能包含有偏见或有害的内容。iii)由于该范式中常用的端到端神经架构的黑箱特性,模型生成难以解释,模型内部机制甚至对开发人员来说也不太透明。
1.3 连接结构化和非结构化范式
尽管这两种范式之间存在明显的差异,但本论文旨在以一种机制化的方式将它们连接起来,从而为构建一个统一的框架铺平道路,该框架可用于构建能够在动态环境中服务于人工智能代理的通用知识引擎。
理论上,统一这两种范式将加深我们对其建模原理的理解,并可能揭示出可应用于结构化和非结构化知识表示的通用技术。实际上,这两种范式目前都难以推广到未知符号。例如,知识图谱嵌入模型在推广到新实体方面面临挑战,而预训练语言模型通常无法推广到未知语言。深入了解这两种范式背后的机制,使我们能够开发出解决泛化问题的新技术。
具体来说,本文将探讨以下问题:
1. 鉴于结构化范式和非结构化范式都旨在为人工智能代理构建知识引擎,它们之间存在哪些共通之处?例如,我们能否识别并利用在两种范式中都有效的共享技术或方法?
2. 如何使知识引擎更具通用性?例如,如何使两种范式中的模型更快地推广到未知环境?
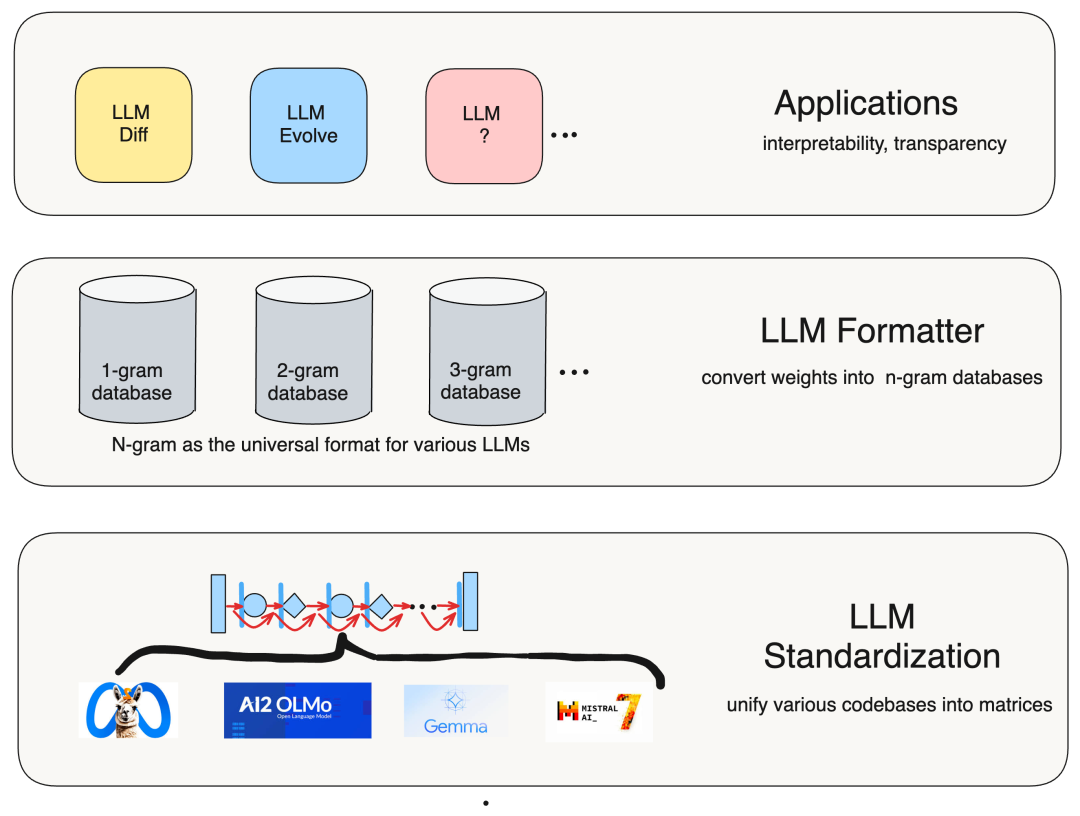
未发现的 n-gram 结构可以看作是相应大型语言模型的重新格式化。这些 n-gram 结构源于将 Transformer 计算分解为更小的单元,我们可以从中重新组合矩阵分解。识别出的语义结构可以支持应用程序的可解释性和透明度。
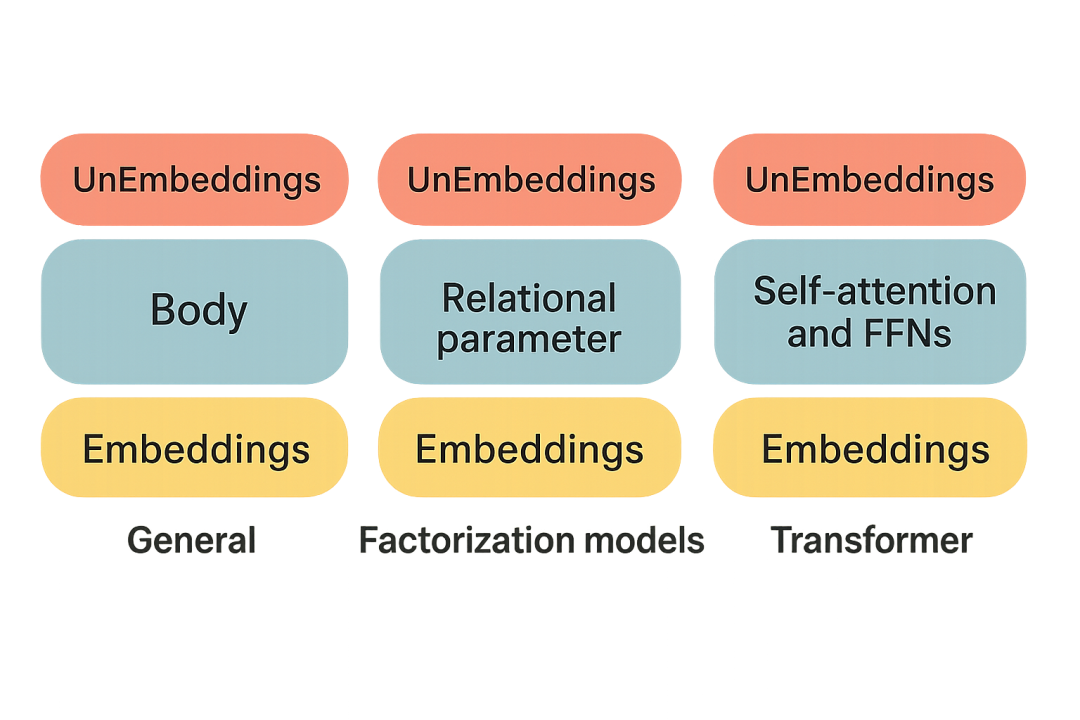
嵌入“三明治”结构是处理神经网络离散和有限输入的典型架构。例如,基于分解的知识图谱补全模型,以及用于文本序列补全的Transformer。
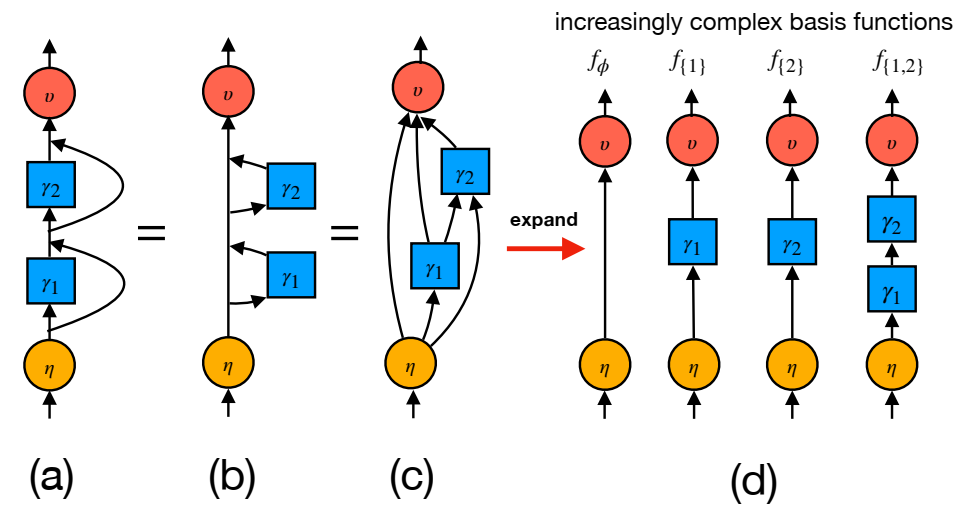
残差流的各种表达式,每种表达式都强调不同的方面。(a) 改编自 [He et al., 2016, Vaswani et al., 2017] 的可视化表达式,突出显示了身份捷径,它简化了非常深的模型的训练。(b) 改编自 [Elhage et al., 2021, nostalgebraist, 2021] 的可视化表达式,突出显示了写入残差流的更新,这些更新充当了通信通道。(c) 改编自 [Veit et al., 2016] 的可视化表达式,突出显示了所有残差链接的展开。(d) 可视化突出显示了我们在第 3.3.3 节中提出的分解,这些分解为有助于解释的独立输入到输出计算路径。对于线性残差网络,(a)-(d) 是等价的表达式。
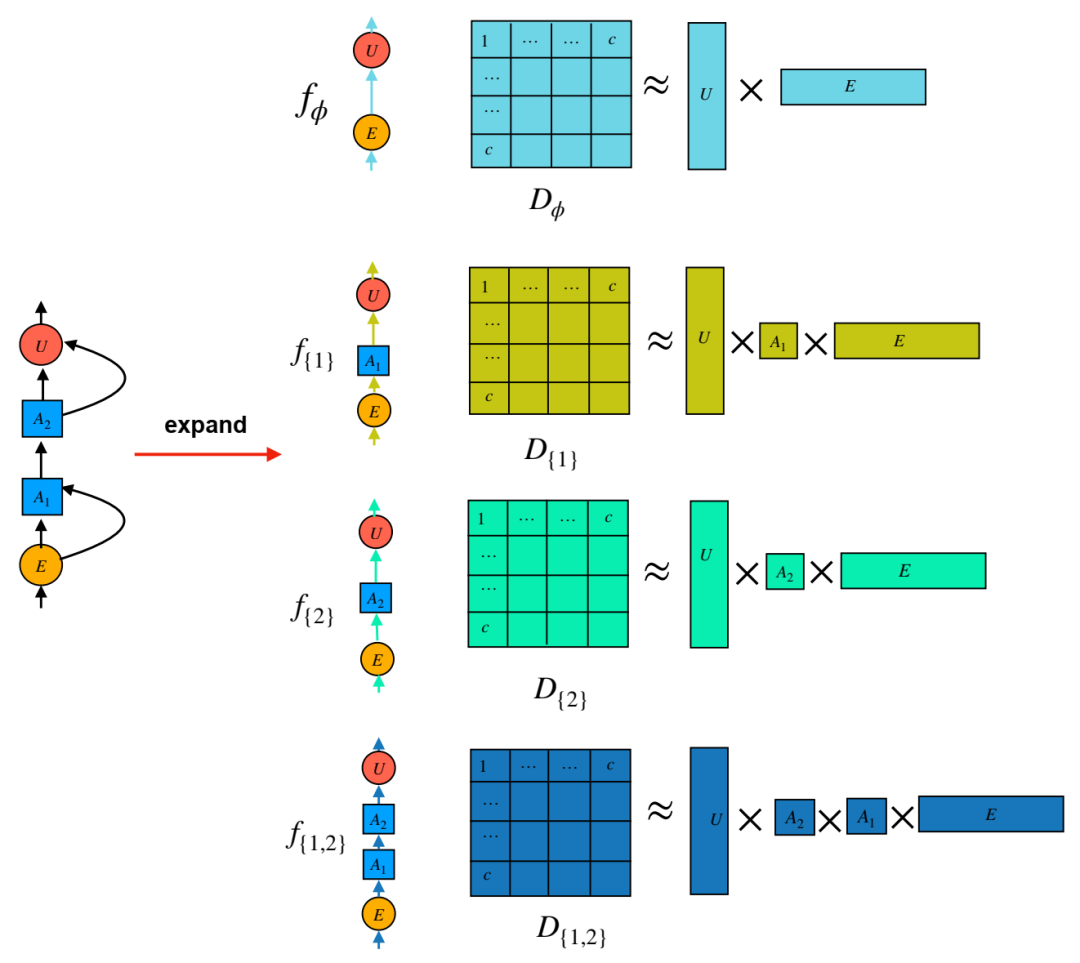
动画展示了在双层递归残差网络中,从每个扩展的输入输出路径 fS 中的嵌入分解模型导出二元组数据库 DS 的过程。例如,D{1} 由路径 f{1} 导出。这些二元组数据库在一定程度上可以描述其对应的路径。
语言建模目标优于嵌入封装模型,推动了结构化和非结构化学习范式的结构习得。
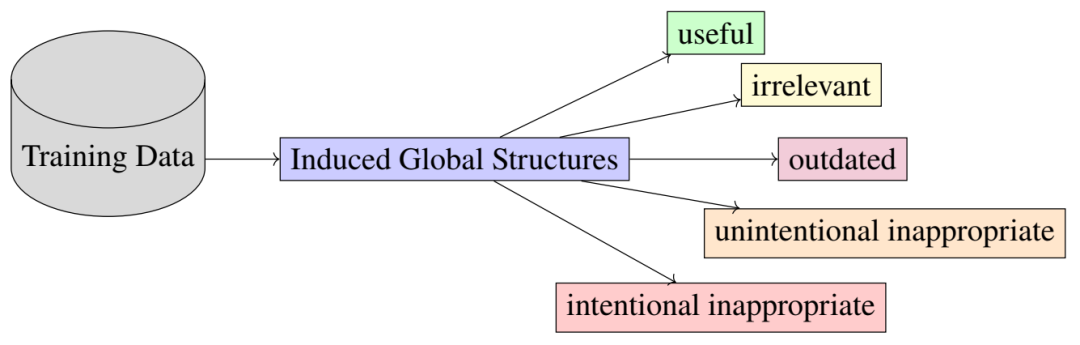
模型中编码的结构并非都具有积极作用。有些结构可能不相关、无意中不恰当、有意中不恰当,甚至已经过时。
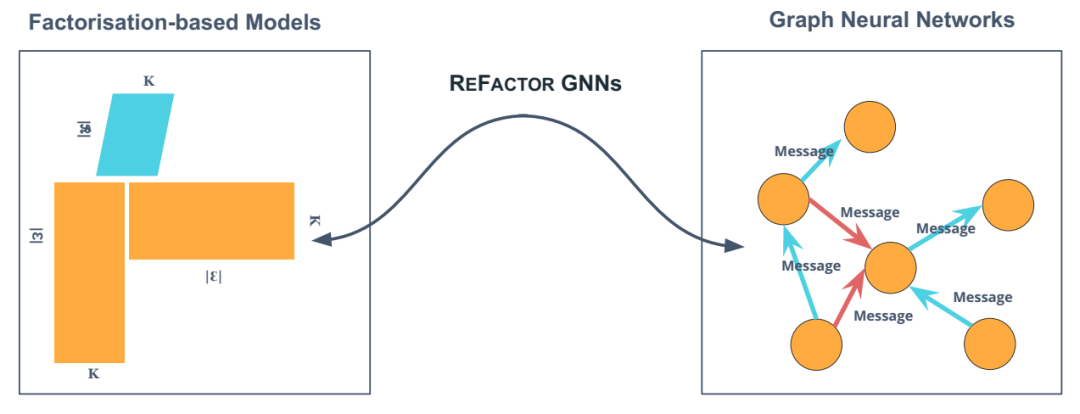
REFACTOR GNN 通过将实体嵌入上的梯度下降重新表述为消息传递轮次,桥接了基于分解的模型和图神经网络。
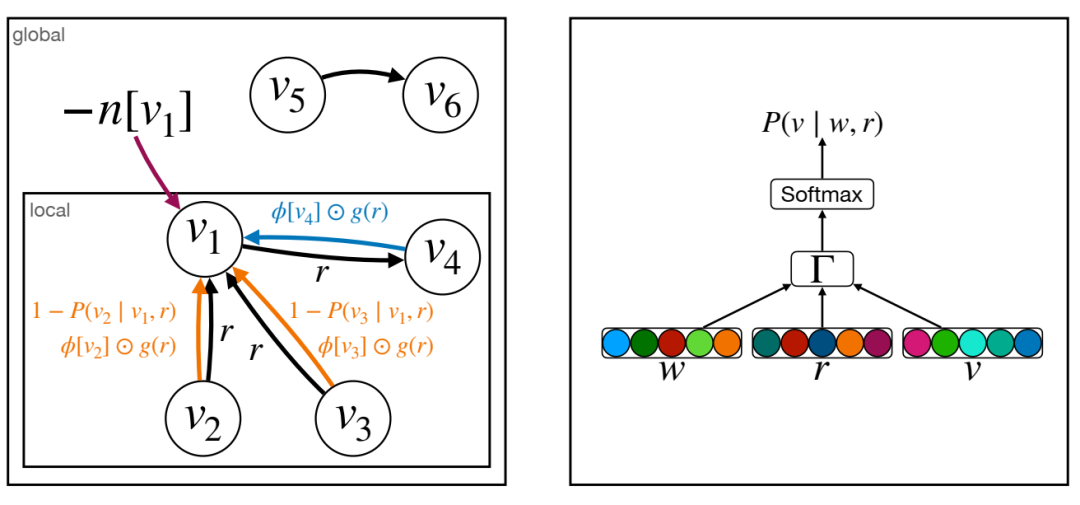
重构 GNN 架构。左图描述了来自局部邻域 f(v2, r1, v1)、(v3, r2, v1)、(v1, r3, v4)g(橙色和蓝色边,取决于边的关系类型)以及由配分函数(紫色箭头)引起的全局正则化项的消息;右图描述了计算 P(v j w, r) 的计算图,其中 v、w ∈ E 和 r ∈ R:w、r 和 v 的嵌入表示用于通过评分函数 Γ 对边 (w, r, v) 进行评分,然后通过 SoftMax 函数进行正则化。
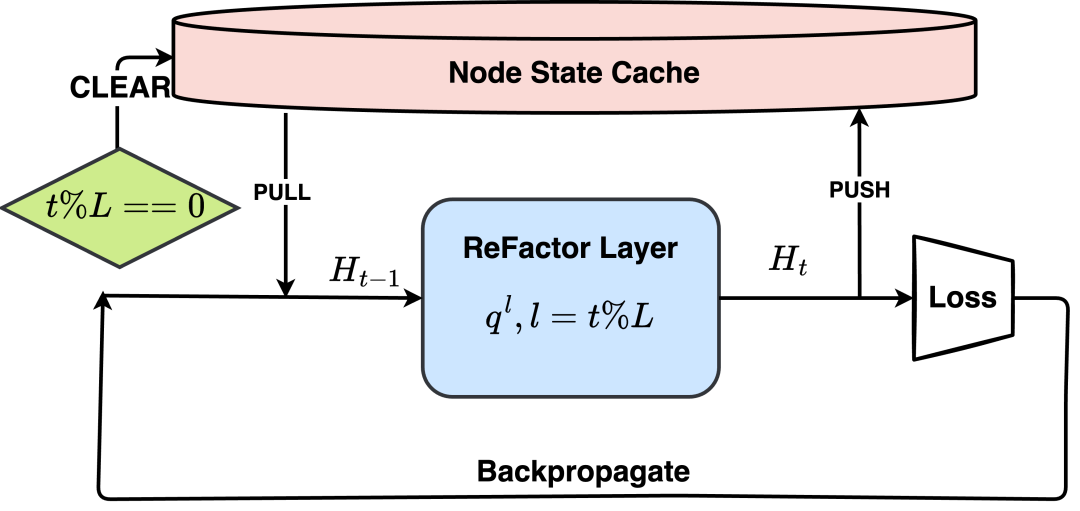
训练期间使用的外部节点状态缓存的说明。
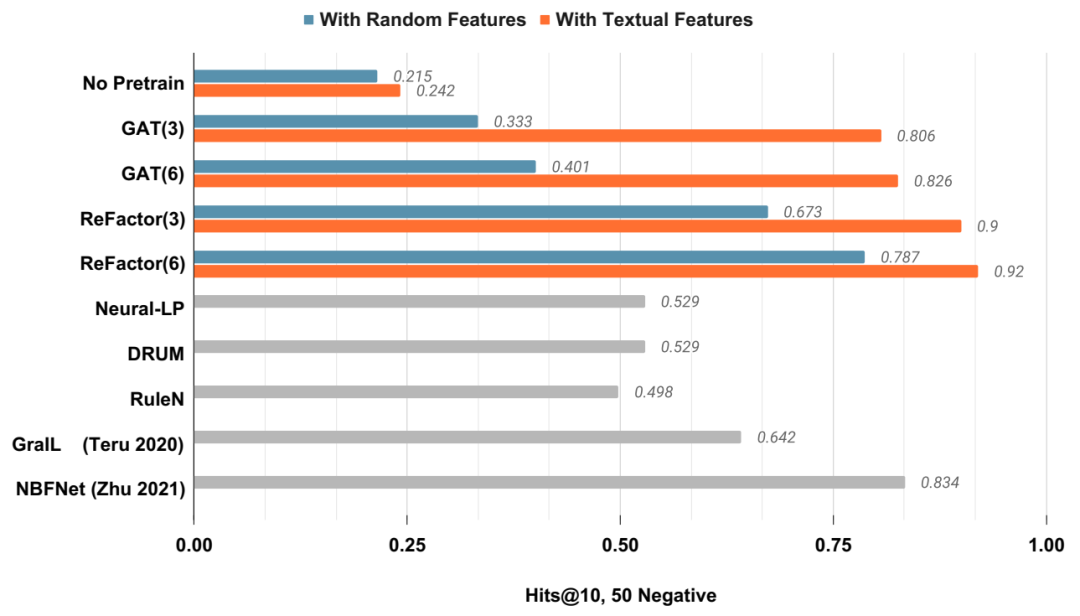
归纳性 KGC 性能,在知识图谱 FB15K237_v1 上训练,并在另一个知识图谱 FB15K237_v1_ind 上测试,其中实体是全新的。GraIL 和 NBFNet 的结果取自 Zhu 等人 [2021]。灰色条表示未设计用于纳入节点特征的方法。
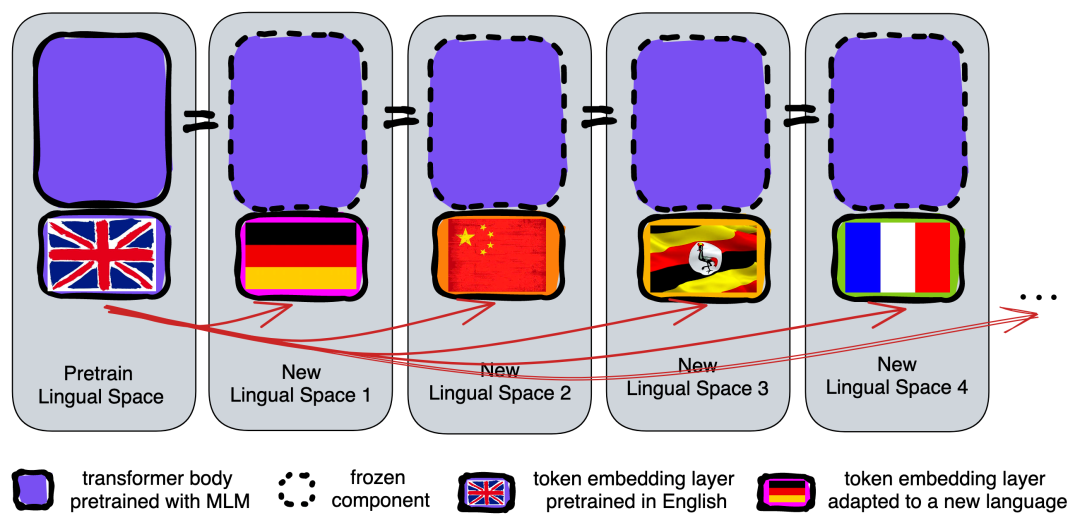
通过重新学习 token 嵌入进行重新布线:Transformer 主体(紫色部分)被“冻结”并重新用于新语言,但 token 嵌入会被重新学习以适应新语言。
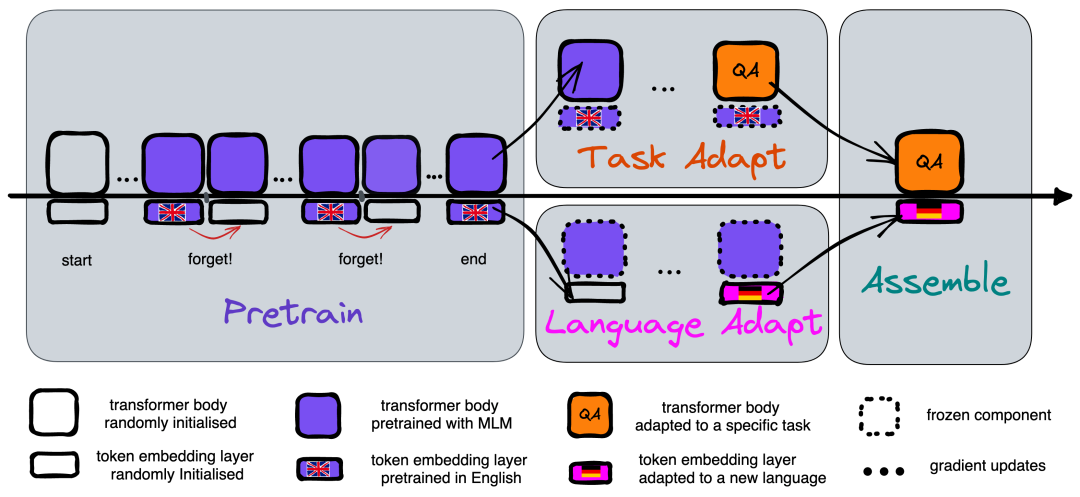
无监督零样本跨语言迁移。左图:在预训练阶段,我们比较了标准预训练和遗忘预训练,其中标记嵌入会定期主动遗忘,而 Transformer 主体则像标准预训练一样进行学习。中图:任务适应阶段和语言适应阶段,分别使用英语任务数据适应 Transformer 主体,并使用新语言的未标记数据适应标记嵌入。右图:组装阶段将适应后的主体和标记嵌入层重新组装成可用的 PLM。
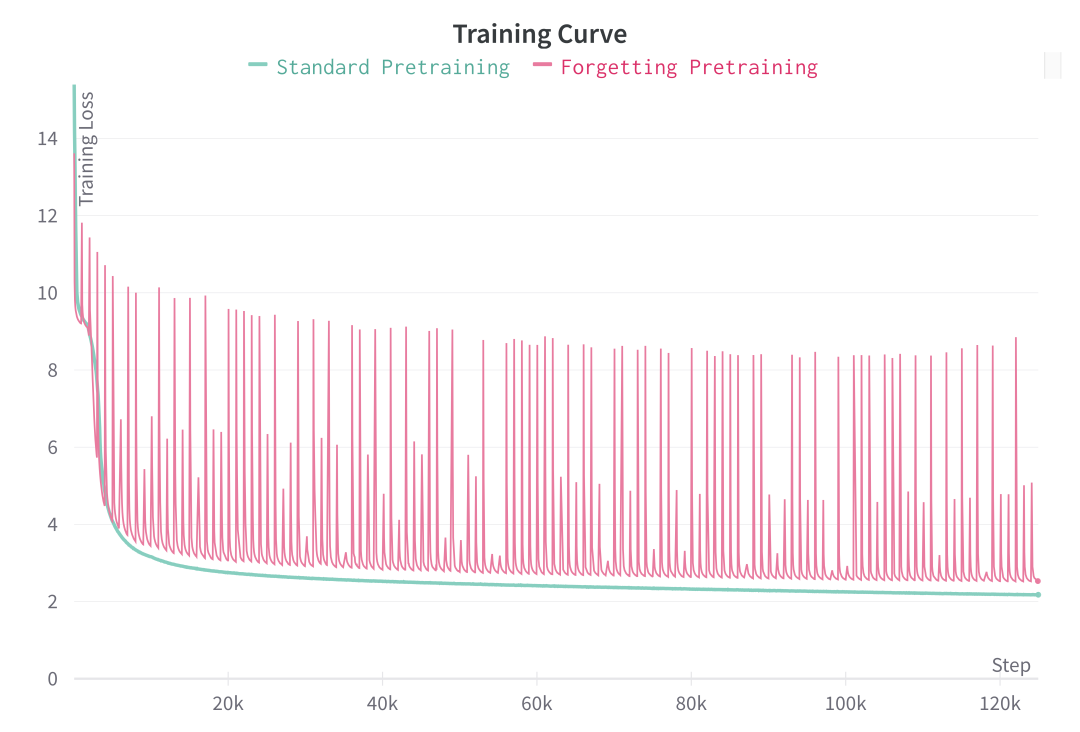
预训练遗忘损失和标准语言模型。遗忘机制将一种情景模式引入损失曲线:每次嵌入遗忘都会产生一个损失峰值,模型会从中学习恢复。通过这种遗忘-再学习的重复,模型会习惯从头开始学习新的嵌入。
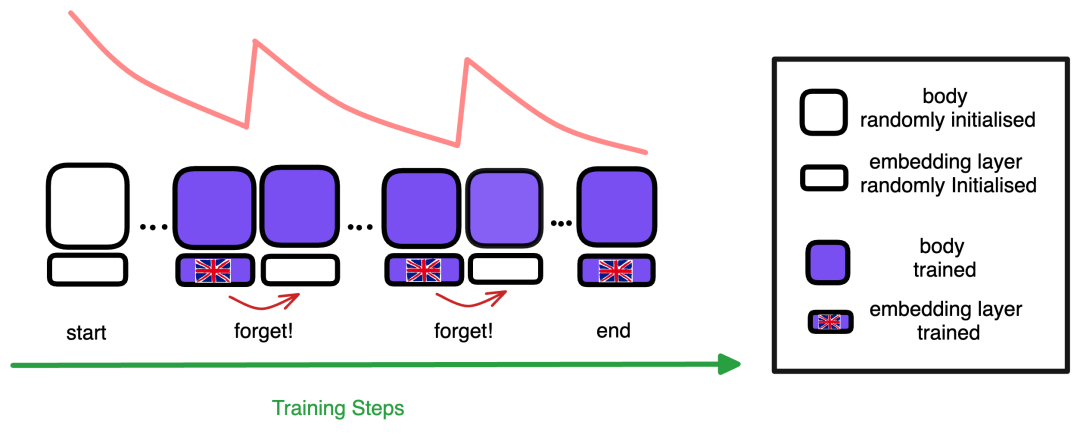
主动遗忘机制会在训练过程中定期重置嵌入层。粉色曲线表示损失的变化。每当发生遗忘时,损失曲线都会出现峰值,然后恢复到正常的下降趋势。
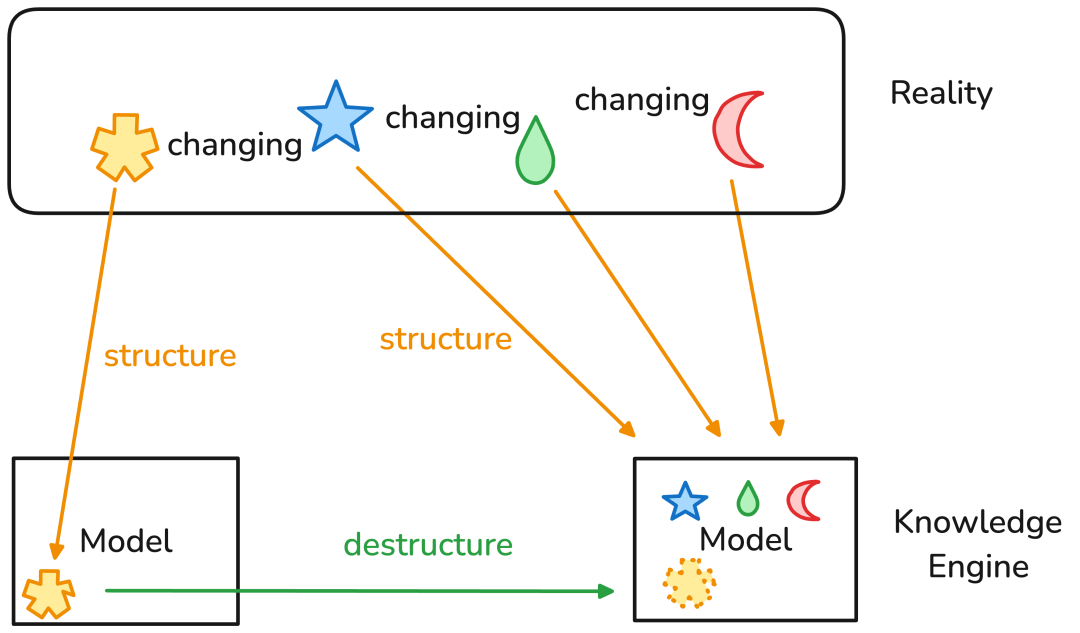
现实总是在变化。我们用不同的形状来表示观察到的现实结构。这些结构会随着时间的流逝而变化。为了忠实地捕捉现实,知识引擎,无论是在结构化范式还是非结构化范式中,都必须能够平衡结构化的力量和解构的力量,以便捕捉必要的结构,但又不被这些结构所束缚。









内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢